小编给大家分享一下Python爬虫中流程框架和常用模块是什么,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
一、简单爬虫架构
首先学习爬虫之前呢,要知道爬虫的一个基本架构,也就是写代码得有层次结构吧?不然挤牙膏么?
爬虫调度器 -> URL管理器 -> 网页下载器() -> 网页解析器() -> 价值数据
其中最重要地方,莫过于三君子-管理,下载,解析器。
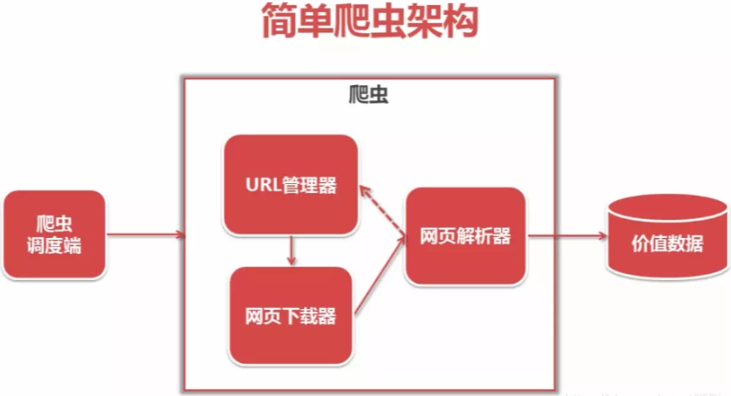
这就是个初代版本的简单爬虫架构,一个基本的架构。
二、运行流程
实际上对于一些有开发基础的人来看,这个东西已经一目了然了,具体内容我不说了。
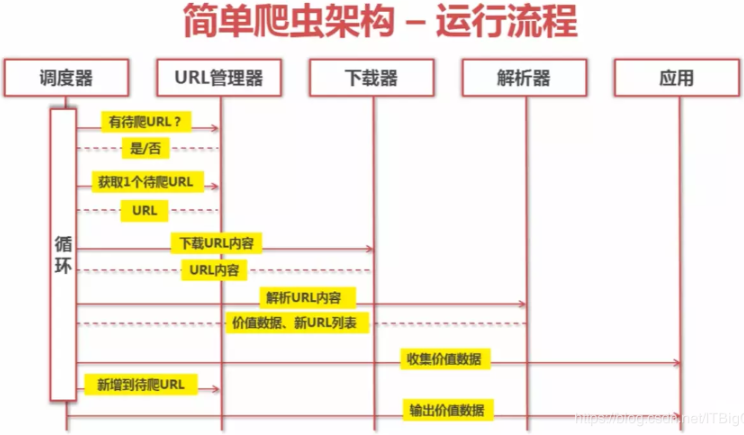
具体过程:(细品,你细品~)
1、调度器询问URL管理器,是否有待爬URL?URL管理器返回是/否?
2、如果是,调度器会从URL管理器中取出一个待爬URL;
3、调度器将URL传给下载器,下载网页内容后返回给调度器;
4、调度器再将返回的网页内容发送到解析器,解析URL内容,解析完成后返回有价值的数据和新的URL;
5、一方面,调度器将数据传递给应用进行数据的收集;另一方面,会将新的URL补充进URL管理器,若有URL管理器中含有新的URL,则重复上述步骤,直到爬取完所有的URL
6、最后,调度器会调动应用的方法,将价值数据输出到需要的格式。
三、URL管理器和实现方法
定义:管理带抓取URL集合和已抓取URL集合,
作用:防止重复抓取、防止循环抓取
URL管理器功能:
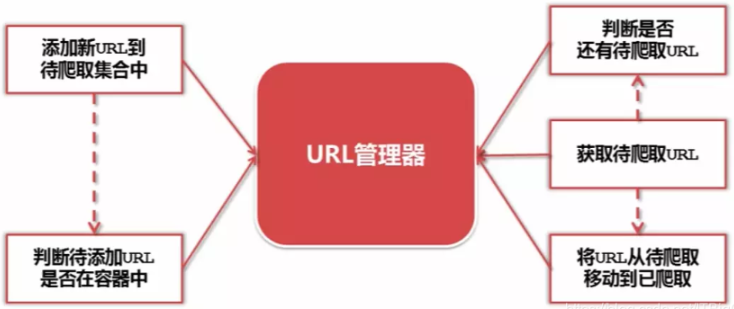
支持的功能
添加新URL到待爬取集合中
判断待添加的URL是否在容器中
判断是否还有带待爬取URL
获取待爬取URL
将URL从待爬取移动到已爬取
实现方式
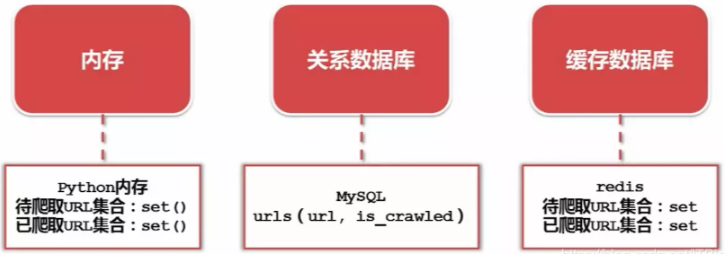
1、适合个人的:内存(计算机或服务器内存)
2、小型企业或个人:关系数据库(永久存储或内存不够用,如 MySQL)
3、大型互联网公司:缓存数据库(高性能,如支持 set() 的 redis)
四、网页下载器和urllib2模块
将互联网上URL对应的网页下载到本地的工具。
作用:网页下载器类似于浏览器,会将互联网对应的网页以HTML的形式下载到本地,存储成本地文件或内存字符串,然后进行后续的分析。
Python的网页下载器种类
urllib / urllib2 (Python官方提供的基础模块)
requests(第三方插件,提供更为强大的功能)
(注意:python 3.x 以上版本把urllib2 和 urllib 整合到一起。所以引入模块变成一个,只有 import urllib,以后你在python2中看到的urllib2在python3中用urllib.request替换~ )
举例:
#py2 import urllib2 response = urllib2.urlopen(url) # 报错NameError: name 'urllib2' is not defined,要改为 # py3 import urllib.request response = urllib.request.urlopen(url)
个人觉得Urllib库不好用,requests库更好用。
urllib2抓取网页的三种方法(以后用requests)
当然,虽然urllib2用的要少一些了,但是还是要了解一下的
方法1:给定url,使用urllib 模块的urlopen方法获取网页内容
举例:
这里我用的python3.x版本的urllib库。
get请求:发送一个GET请求到指定的页面,然后返回HTTP的响应。
from urllib import request
print('第一种方法get请求')
url = 'http://www.baidu.com'
# 直接请求
response = request.urlopen(url)
# 获取状态码,如果是200表示成功
print(response.status)
# 读取网页内容
print(response.read().decode('utf-8')因为read获取到的byte编码,改为decode(‘utf-8’)。
方法2:添加data,http header
模拟浏览器发送GET请求,就需要使用Request对象,通过往Request对象添加HTTP头,我们就可以把请求伪装成浏览器进行访问:
User-Agent 有些 Server 或 Proxy 会检查该值,用来判断是否是浏览器发起的 Request .Content-Type
在使用 REST 接口时,Server 会检查该值,用来确定 HTTP Body 中的内容该怎样解析。
添加头信息举例:
import urllib2
print "第二种方法"
from urllib import request
req = request.Request('http://www.baidu.com')
req.add_header('User-Agent', 'Mozilla/6.0')
response = request.urlopen(req)
# 获取状态码,如果是200表示成功
print(response.status)
# 读取网页内容
print(response.read().decode('utf-8'))方法3:添加特殊情景的处理器
模拟浏览器发送POST请求。
需要登录才能访问的网页,要添加cookie的处理。使用HTTPCookieProcessor;
需要代理才能访问的网页使用ProxyHandler;
需要HTTPS加密访问的网站使用HTTPSHandler;
有些URL存在相互自动跳转的关系使用HTTPRedirectHandler进行处理。
图示:
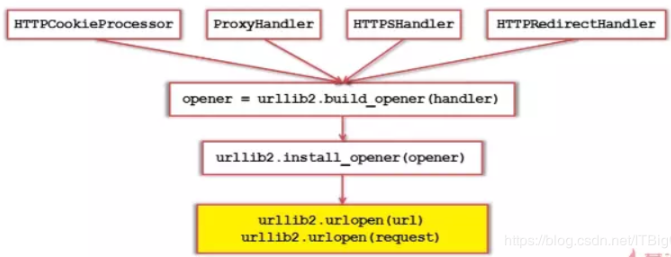
HTTPCookieProcessor的使用:
cookie中保存中我们常见的登录信息,有时候爬取网站需要携带cookie信息访问,这里用到了http.cookijar,用于获取cookie以及存储cookie,同时cookie可以写入到文件中保存,一般有两种方式http.cookiejar.MozillaCookieJar和http.cookiejar.LWPCookieJar()。
举例:
import urllib2, cookielib
print "第三种方法"
# 创建cookie容器
cj = cookielib.CookieJar()
# 创建1个opener
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
# 给urllib2安装opener
urllib2.install_opener(opener)
# 使用带有cookie的urllib2访问网页
response = urllib2.urlopen('http://www.baidu.com/')上面都是对urllib2模块来写的,但是实战中往往用requests,这个放到后面文章来说。
注意: python3用cookielib 模块改名为 http.cookiejar,带cookie的打印出来必须用opener.open(req).read().decode(‘utf-8’)来发送的请求才会带上cookie,如果用urllib.request.urlopen()是不带cookie的。
ProxyHandler代理的使用:
网站它会检测某一段时间某个IP 的访问次数,如果访问次数过多,它会禁止你的访问,所以这个时候需要通过设置代理来爬取数据
import urllib.request
url = 'http://www.baidu.com'
proxy_handler = urllib.request.ProxyHandler({
#代理服务器IP地址
'http': 'http://111.13.100.91:80',
'https': 'https://111.13.100.91:443'
})
opener = urllib.request.build_opener(proxy_handler)
response = opener.open(url)
# 获取状态码,如果是200表示成功
print(response.status)
# 读取网页内容
print(response.read().decode('utf-8'))四、网页解析器和使用
网页解析器从HTML网页字符串中提取出价值数据和新URL对象
Python网页解析器种类
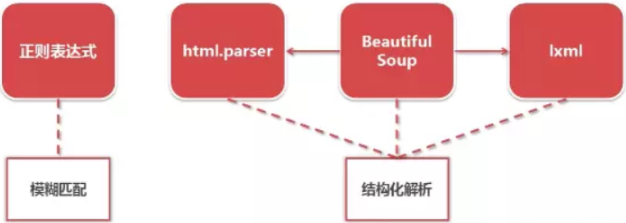
正则表达式(re模糊匹配)
html.parser (Python自带)
BeautifulSoup (第三方插件)
lxml (第三方解析器)
后面三种是以结构化解析的方式进行解析DOM(Document Object Model)树,
【也就是按照html的节点路径一级一级来解析的。】
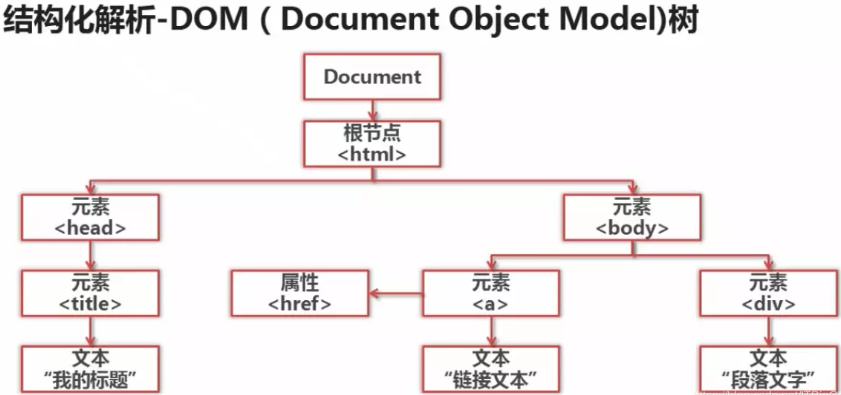
下面挨个介绍一下最常用的两个。
常用的BeautifulSoup介绍!!!
bs4主要使用find()方法和find_all()方法来搜索文档。
find()用来搜索单一数据,find_all()用来搜索多个数据。
它是Python第三方库,用于从HTML或XML中提取数据
官网:https://www.crummy.com/software/BeautifulSoup/
中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
需要安装和测试:
方法一,在cmd窗口中:
安装:pip install beautifulsoup4 测试:import bs4
方法2:在pycharm中:File–settings–Project Interpreter–添加beautifulsoup4(简写bs4)
语法:
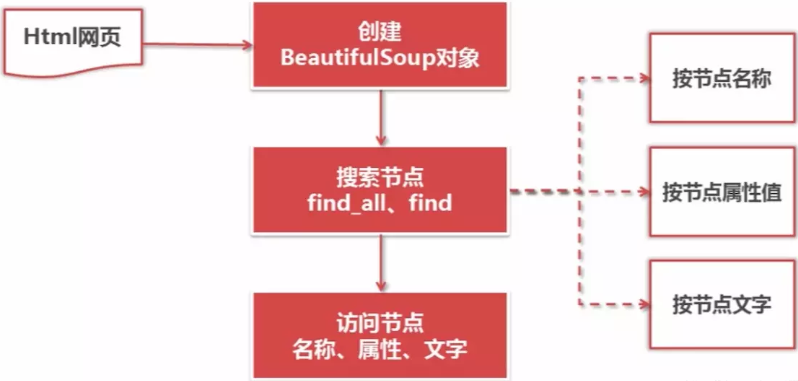
举个例子:
from bs4 import BeautifulSoup
# 根据HTML网页字符串创建BeautifulSoup对象
soup = BeautifulSoup(html_doc, 'html.parser', from_encoding='utf-8')
# 搜索节点 查找所有标签为a的节点
soup.find_all('a')
# 查找所有标签为a,连接符合/view/123.html形式的节点
soup.find_all('a', href='/view/123.html')
soup.find_all('a', href=re.compile(r'/view/\d+\.html'))
# 查找所有标签为div,class为abc,文字为Python的节点
soup.find_all('div', class_='abc', string='Python')访问节点信息
# 举例节点:<a href='1.html'>Python</a> # 获取查找到的节点的标签名称 node.name # 获取查找到的a节点的href属性 node['href'] # 获取查找到的a节点的链接文字 node.get_text()
上面就是bs4在解析模块的相关使用,更多方式查看官方文档即可。
常用的lxml介绍
Xpath是一门在XML文档中查找信息的语言。Xpath可用来在XML文档中对元素和属性进行遍历。Xpath是W3C XSLT标准的主要元素,并且XQuery和XPointer都构建于XPath表达之上。
安装:
pip install lxml
语法:
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
在使用 xpath之前,先导入 etree类,对原始的 html页面进行处理获得一个_Element对象。

举个例子:
#导入 etree类
from lxml import etree
# html文本
html = '''<div class="container">
<div class="row">
<div class="col">
<div class="card">
<div class="card-content">
<a href="#123333" class="box">
好麻烦哟!!!~~~
</a>
</div>
</div>
</div>
</div>
</div>'''
#对 html文本进行处理 获得一个_Element对象
dom = etree.HTML(html)
#获取 a标签下的文本
a_text = dom.xpath('//div/div/div/div/div/a/text()')
print(a_text)我们通过 etree.HTML( )来生成一个_Element对象,etree.HTML() 会将传入的文本处理成一个 html文档节点。这样就能保证我们总是能获得一个包含文档节点的_Element对象。
以上是Python爬虫中流程框架和常用模块是什么的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





