这篇文章主要介绍了Python3爬虫利器中Scrapyd的安装方法是什么,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获。下面让小编带着大家一起了解一下。
Scrapyd是一个用于部署和运行Scrapy项目的工具,有了它,你可以将写好的Scrapy项目上传到云主机并通过API来控制它的运行。
既然是Scrapy项目部署,基本上都使用Linux主机,所以本节的安装是针对于Linux主机的。
1. 相关链接
GitHub:https://github.com/scrapy/scrapyd
PyPI:https://pypi.python.org/pypi/scrapyd
官方文档:https://scrapyd.readthedocs.io
2. pip安装
这里推荐使用pip安装,命令如下:
pip3 install scrapyd
3. 配置
安装完毕之后,需要新建一个配置文件/etc/scrapyd/scrapyd.conf,Scrapyd在运行的时候会读取此配置文件。
在Scrapyd 1.2版本之后,不会自动创建该文件,需要我们自行添加。
首先,执行如下命令新建文件:
sudo mkdir /etc/scrapyd sudo vi /etc/scrapyd/scrapyd.conf
接着写入如下内容:
[scrapyd] eggs_dir = eggs logs_dir = logs items_dir = jobs_to_keep = 5 dbs_dir = dbs max_proc = 0 max_proc_per_cpu = 10 finished_to_keep = 100 poll_interval = 5.0 bind_address = 0.0.0.0 http_port = 6800 debug = off runner = scrapyd.runner application = scrapyd.app.application launcher = scrapyd.launcher.Launcher webroot = scrapyd.website.Root [services] schedule.json = scrapyd.webservice.Schedule cancel.json = scrapyd.webservice.Cancel addversion.json = scrapyd.webservice.AddVersion listprojects.json = scrapyd.webservice.ListProjects listversions.json = scrapyd.webservice.ListVersions listspiders.json = scrapyd.webservice.ListSpiders delproject.json = scrapyd.webservice.DeleteProject delversion.json = scrapyd.webservice.DeleteVersion listjobs.json = scrapyd.webservice.ListJobs daemonstatus.json = scrapyd.webservice.DaemonStatus
配置文件的内容可以参见官方文档https://scrapyd.readthedocs.io/en/stable/config.html#example-configuration-file。这里的配置文件有所修改,其中之一是max_proc_per_cpu官方默认为4,即一台主机每个CPU最多运行4个Scrapy任务,在此提高为10。另外一个是bind_address,默认为本地127.0.0.1,在此修改为0.0.0.0,以使外网可以访问。
4. 后台运行
Scrapyd是一个纯Python项目,这里可以直接调用它来运行。为了使程序一直在后台运行,Linux和Mac可以使用如下命令:
(scrapyd > /dev/null &)
这样Scrapyd就会在后台持续运行了,控制台输出直接忽略。当然,如果想记录输出日志,可以修改输出目标,如:
(scrapyd > ~/scrapyd.log &)
此时会将Scrapyd的运行结果输出到~/scrapyd.log文件中。
当然也可以使用screen、tmux、supervisor等工具来实现进程守护。
运行之后,便可以在浏览器的6800端口访问Web UI了,从中可以看到当前Scrapyd的运行任务、日志等内容,如图1-85所示。
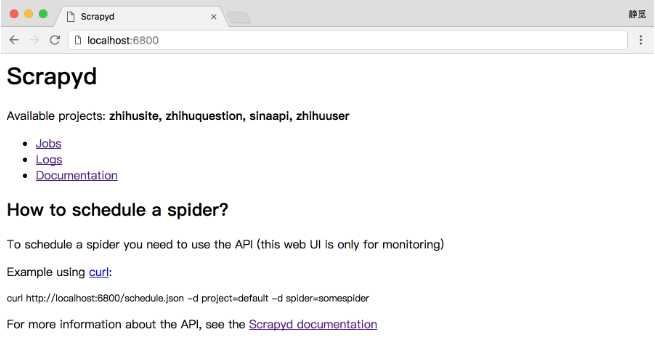
图1-85 Scrapyd首页
当然,运行Scrapyd更佳的方式是使用Supervisor守护进程,如果感兴趣,可以参考:http://supervisord.org/。
另外,Scrapyd也支持Docker,后面我们会介绍Scrapyd Docker镜像的制作和运行方法。
5. 访问认证
配置完成后,Scrapyd和它的接口都是可以公开访问的。如果想配置访问认证的话,可以借助于Nginx做反向代理,这里需要先安装Nginx服务器。
在此以Ubuntu为例进行说明,安装命令如下:
sudo apt-get install nginx
然后修改Nginx的配置文件nginx.conf,增加如下配置:
http {
server {
listen 6801;
location / {
proxy_pass http://127.0.0.1:6800/;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/conf.d/.htpasswd;
}
}
}这里使用的用户名和密码配置放置在/etc/nginx/conf.d目录下,我们需要使用htpasswd命令创建。例如,创建一个用户名为admin的文件,命令如下:
htpasswd -c .htpasswd admin
接着就会提示我们输入密码,输入两次之后,就会生成密码文件。此时查看这个文件的内容:
cat .htpasswd admin:5ZBxQr0rCqwbc
配置完成后,重启一下Nginx服务,运行如下命令:
sudo nginx -s reload
这样就成功配置了Scrapyd的访问认证了。
感谢你能够认真阅读完这篇文章,希望小编分享Python3爬虫利器中Scrapyd的安装方法是什么内容对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,遇到问题就找亿速云,详细的解决方法等着你来学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





