这篇文章给大家分享的是有关Python3爬虫中使用PyMySQL操作MySQL数据库的方法的内容。小编觉得挺实用的,因此分享给大家做个参考。一起跟随小编过来看看吧。
在Python 2中,连接MySQL的库大多是使用MySQLdb,但是此库的官方并不支持Python 3,所以这里推荐使用的库是PyMySQL。
使用PyMySQL操作MySQL数据库的方法。
1. 准备工作
在开始之前,请确保已经安装好了MySQL数据库并保证它能正常运行,而且需要安装好PyMySQL库。如果没有安装,可以参考第1章。
2. 连接数据库
这里,首先尝试连接一下数据库。假设当前的MySQL运行在本地,用户名为root,密码为123456,运行端口为3306。这里利用PyMySQL先连接MySQL,然后创建一个新的数据库,名字叫作spiders,代码如下:
import pymysql
db = pymysql.connect(host='localhost',user='root', password='123456', port=3306)
cursor = db.cursor()
cursor.execute('SELECT VERSION()')
data = cursor.fetchone()
print('Database version:', data)
cursor.execute("CREATE DATABASE spiders DEFAULT CHARACTER SET utf8")
db.close()运行结果如下:
Database version: ('5.6.22',)这里通过PyMySQL的connect()方法声明一个MySQL连接对象db,此时需要传入MySQL运行的host(即IP)。由于MySQL在本地运行,所以传入的是localhost。如果MySQL在远程运行,则传入其公网IP地址。后续的参数user即用户名,password即密码,port即端口(默认为3306)。
连接成功后,需要再调用cursor()方法获得MySQL的操作游标,利用游标来执行SQL语句。这里我们执行了两句SQL,直接用execute()方法执行即可。第一句SQL用于获得MySQL的当前版本,然后调用fetchone()方法获得第一条数据,也就得到了版本号。第二句SQL执行创建数据库的操作,数据库名叫作spiders,默认编码为UTF-8。由于该语句不是查询语句,所以直接执行后就成功创建了数据库spiders。接着,再利用这个数据库进行后续的操作。
3. 创建表
一般来说,创建数据库的操作只需要执行一次就好了。当然,我们也可以手动创建数据库。以后,我们的操作都在spiders数据库上执行。
创建数据库后,在连接时需要额外指定一个参数db。
接下来,新创建一个数据表students,此时执行创建表的SQL语句即可。这里指定3个字段,结构如表5-1所示。

创建该表的示例代码如下:
import pymysql
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')
cursor = db.cursor()
sql = 'CREATE TABLE IF NOT EXISTS students (id VARCHAR(255) NOT NULL, name VARCHAR(255) NOT NULL, age INT NOT NULL,
PRIMARY KEY (id))'
cursor.execute(sql)
db.close()运行之后,我们便创建了一个名为students的数据表。
当然,为了演示,这里只指定了最简单的几个字段。实际上,在爬虫过程中,我们会根据爬取结果设计特定的字段。
4. 插入数据
下一步就是向数据库中插入数据了。例如,这里爬取了一个学生信息,学号为20120001,名字为Bob,年龄为20,那么如何将该条数据插入数据库呢?示例代码如下:
import pymysql
id = '20120001'
user = 'Bob'
age = 20
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')
cursor = db.cursor()
sql = 'INSERT INTO students(id, name, age) values(%s, %s, %s)'
try:
cursor.execute(sql, (id, user, age))
db.commit()
except:
db.rollback()
db.close()这里首先构造了一个SQL语句,其Value值没有用字符串拼接的方式来构造,如:
sql = 'INSERT INTO students(id, name, age) values(' + id + ', ' + name + ', ' + age + ')'这样的写法烦琐而且不直观,所以我们选择直接用格式化符%s来实现。有几个Value写几个%s,我们只需要在execute()方法的第一个参数传入该SQL语句,Value值用统一的元组传过来就好了。这样的写法既可以避免字符串拼接的麻烦,又可以避免引号冲突的问题。
之后值得注意的是,需要执行db对象的commit()方法才可实现数据插入,这个方法才是真正将语句提交到数据库执行的方法。对于数据插入、更新、删除操作,都需要调用该方法才能生效。
接下来,我们加了一层异常处理。如果执行失败,则调用rollback()执行数据回滚,相当于什么都没有发生过。
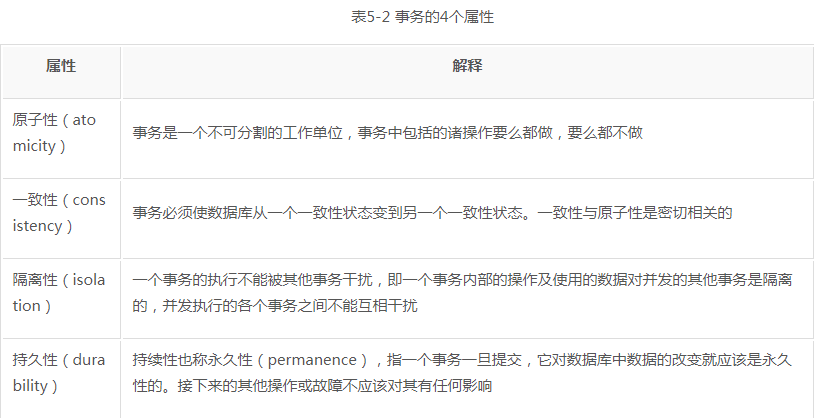
这里涉及事务的问题。事务机制可以确保数据的一致性,也就是这件事要么发生了,要么没有发生。比如插入一条数据,不会存在插入一半的情况,要么全部插入,要么都不插入,这就是事务的原子性。另外,事务还有3个属性——一致性、隔离性和持久性。这4个属性通常称为ACID特性,具体如表5-2所示。
插入、更新和删除操作都是对数据库进行更改的操作,而更改操作都必须为一个事务,所以这些操作的标准写法就是:
try:
cursor.execute(sql)
db.commit()
except:
db.rollback()这样便可以保证数据的一致性。这里的commit()和rollback()方法就为事务的实现提供了支持。
上面数据插入的操作是通过构造SQL语句实现的,但是很明显,这有一个极其不方便的地方,比如突然增加了性别字段gender,此时SQL语句就需要改成:
INSERT INTO students(id, name, age, gender) values(%s, %s, %s, %s)相应的元组参数则需要改成:
(id, name, age, gender)这显然不是我们想要的。在很多情况下,我们要达到的效果是插入方法无需改动,做成一个通用方法,只需要传入一个动态变化的字典就好了。比如,构造这样一个字典:
{
'id': '20120001',
'name': 'Bob',
'age': 20
}然后SQL语句会根据字典动态构造,元组也动态构造,这样才能实现通用的插入方法。所以,这里我们需要改写一下插入方法:
data = {
'id': '20120001',
'name': 'Bob',
'age': 20
}
table = 'students'
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql = 'INSERT INTO {table}({keys}) VALUES ({values})'.format(table=table, keys=keys, values=values)
try:
if cursor.execute(sql, tuple(data.values())):
print('Successful')
db.commit()
except:
print('Failed')
db.rollback()
db.close()这里我们传入的数据是字典,并将其定义为data变量。表名也定义成变量table。接下来,就需要构造一个动态的SQL语句了。
首先,需要构造插入的字段id、name和age。这里只需要将data的键名拿过来,然后用逗号分隔即可。所以', '.join(data.keys())的结果就是id, name, age,然后需要构造多个%s当作占位符,有几个字段构造几个即可。比如,这里有三个字段,就需要构造%s, %s, %s。这里首先定义了长度为1的数组['%s'],然后用乘法将其扩充为['%s', '%s', '%s'],再调用join()方法,最终变成%s, %s, %s。最后,我们再利用字符串的format()方法将表名、字段名和占位符构造出来。最终的SQL语句就被动态构造成了:
INSERT INTO students(id, name, age) VALUES (%s, %s, %s)
最后,为execute()方法的第一个参数传入sql变量,第二个参数传入data的键值构造的元组,就可以成功插入数据了。
如此以来,我们便实现了传入一个字典来插入数据的方法,不需要再去修改SQL语句和插入操作了。
5. 更新数据
数据更新操作实际上也是执行SQL语句,最简单的方式就是构造一个SQL语句,然后执行:
sql = 'UPDATE students SET age = %s WHERE name = %s'
try:
cursor.execute(sql, (25, 'Bob'))
db.commit()
except:
db.rollback()
db.close()这里同样用占位符的方式构造SQL,然后执行execute()方法,传入元组形式的参数,同样执行commit()方法执行操作。如果要做简单的数据更新的话,完全可以使用此方法。
但是在实际的数据抓取过程中,大部分情况下需要插入数据,但是我们关心的是会不会出现重复数据,如果出现了,我们希望更新数据而不是重复保存一次。另外,就像前面所说的动态构造SQL的问题,所以这里可以再实现一种去重的方法,如果数据存在,则更新数据;如果数据不存在,则插入数据。另外,这种做法支持灵活的字典传值。示例如下:
data = {
'id': '20120001',
'name': 'Bob',
'age': 21
}
table = 'students'
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql = 'INSERT INTO {table}({keys}) VALUES ({values}) ON DUPLICATE KEY UPDATE'.format(table=table, keys=keys,
values=values)
update = ','.join([" {key} = %s".format(key=key) for key in data])
sql += update
try:
if cursor.execute(sql, tuple(data.values())*2):
print('Successful')
db.commit()
except:
print('Failed')
db.rollback()
db.close()这里构造的SQL语句其实是插入语句,但是我们在后面加了ON DUPLICATE KEY UPDATE。这行代码的意思是如果主键已经存在,就执行更新操作。比如,我们传入的数据id仍然为20120001,但是年龄有所变化,由20变成了21,此时这条数据不会被插入,而是直接更新id为20120001的数据。完整的SQL构造出来是这样的:
INSERT INTO students(id, name, age) VALUES (%s, %s, %s) ON DUPLICATE KEY UPDATE id = %s, name = %s, age = %s
这里就变成了6个%s。所以在后面的execute()方法的第二个参数元组就需要乘以2变成原来的2倍。
如此一来,我们就可以实现主键不存在便插入数据,存在则更新数据的功能了。
6. 删除数据
删除操作相对简单,直接使用DELETE语句即可,只是需要指定要删除的目标表名和删除条件,而且仍然需要使用db的commit()方法才能生效。示例如下:
table = 'students'
condition = 'age > 20'
sql = 'DELETE FROM {table} WHERE {condition}'.format(table=table, condition=condition)
try:
cursor.execute(sql)
db.commit()
except:
db.rollback()
db.close()因为删除条件有多种多样,运算符有大于、小于、等于、LIKE等,条件连接符有AND、OR等,所以不再继续构造复杂的判断条件。这里直接将条件当作字符串来传递,以实现删除操作。
7. 查询数据
说完插入、修改和删除等操作,还剩下非常重要的一个操作,那就是查询。查询会用到SELECT语句,示例如下:
sql = 'SELECT * FROM students WHERE age >= 20'
try:
cursor.execute(sql)
print('Count:', cursor.rowcount)
one = cursor.fetchone()
print('One:', one)
results = cursor.fetchall()
print('Results:', results)
print('Results Type:', type(results))
for row in results:
print(row)
except:
print('Error')运行结果如下:
Count: 4
One: ('20120001', 'Bob', 25)
Results: (('20120011', 'Mary', 21), ('20120012', 'Mike', 20), ('20120013', 'James', 22))
Results Type: <class 'tuple'>
('20120011', 'Mary', 21)
('20120012', 'Mike', 20)
('20120013', 'James', 22)这里我们构造了一条SQL语句,将年龄20岁及以上的学生查询出来,然后将其传给execute()方法。注意,这里不再需要db的commit()方法。接着,调用cursor的rowcount属性获取查询结果的条数,当前示例中是4条。
然后我们调用了fetchone()方法,这个方法可以获取结果的第一条数据,返回结果是元组形式,元组的元素顺序跟字段一一对应,即第一个元素就是第一个字段id,第二个元素就是第二个字段name,以此类推。随后,我们又调用了fetchall()方法,它可以得到结果的所有数据。然后将其结果和类型打印出来,它是二重元组,每个元素都是一条记录,我们将其遍历输出出来。
但是这里需要注意一个问题,这里显示的是3条数据而不是4条,fetchall()方法不是获取所有数据吗?这是因为它的内部实现有一个偏移指针用来指向查询结果,最开始偏移指针指向第一条数据,取一次之后,指针偏移到下一条数据,这样再取的话,就会取到下一条数据了。我们最初调用了一次fetchone()方法,这样结果的偏移指针就指向下一条数据,fetchall()方法返回的是偏移指针指向的数据一直到结束的所有数据,所以该方法获取的结果就只剩3个了。
此外,我们还可以用while循环加fetchone()方法来获取所有数据,而不是用fetchall()全部一起获取出来。fetchall()会将结果以元组形式全部返回,如果数据量很大,那么占用的开销会非常高。因此,推荐使用如下方法来逐条取数据:
sql = 'SELECT * FROM students WHERE age >= 20'
try:
cursor.execute(sql)
print('Count:', cursor.rowcount)
row = cursor.fetchone()
while row:
print('Row:', row)
row = cursor.fetchone()
except:
print('Error')这样每循环一次,指针就会偏移一条数据,随用随取,简单高效。
感谢各位的阅读!关于Python3爬虫中使用PyMySQL操作MySQL数据库的方法就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到吧!
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



