XpathеҰӮдҪ•жҸҗеҸ–HTMLж•°жҚ®
д»ҠеӨ©е°ұи·ҹеӨ§е®¶иҒҠиҒҠжңүе…іXpathеҰӮдҪ•жҸҗеҸ–HTMLж•°жҚ®пјҢеҸҜиғҪеҫҲеӨҡдәәйғҪдёҚеӨӘдәҶи§ЈпјҢдёәдәҶи®©еӨ§е®¶жӣҙеҠ дәҶи§ЈпјҢе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеёҢжңӣеӨ§е®¶ж №жҚ®иҝҷзҜҮж–Үз« еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
1.з®Җд»Ӣ
XPathжҳҜдёҖй—ЁеңЁ XML ж–ҮжЎЈдёӯжҹҘжүҫдҝЎжҒҜзҡ„иҜӯиЁҖгҖӮXPath з”ЁдәҺеңЁ XML ж–ҮжЎЈдёӯйҖҡиҝҮе…ғзҙ е’ҢеұһжҖ§иҝӣиЎҢеҜјиҲӘгҖӮ
зӣёжҜ”дәҺBeautifulSoupпјҢXpathеңЁжҸҗеҸ–ж•°жҚ®ж—¶дјҡжӣҙеҠ зҡ„ж–№дҫҝгҖӮ
2. е®үиЈ…
еңЁPythonдёӯеҫҲеӨҡеә“йғҪжңүжҸҗдҫӣXpathзҡ„еҠҹиғҪпјҢдҪҶжҳҜжңҖеҹәжң¬зҡ„иҝҳжҳҜlxmlиҝҷдёӘеә“пјҢж•ҲзҺҮжңҖй«ҳгҖӮеңЁд№ӢеүҚBeautifulSoupз« иҠӮдёӯжҲ‘们д№ҹд»Ӣз»ҚеҲ°дәҶlxmlжҳҜеҰӮдҪ•е®үиЈ…зҡ„гҖӮ
pip install lxml
3. иҜӯжі•
XPath дҪҝз”Ёи·Ҝеҫ„иЎЁиҫҫејҸеңЁ XML ж–ҮжЎЈдёӯйҖүеҸ–иҠӮзӮ№гҖӮиҠӮзӮ№жҳҜйҖҡиҝҮжІҝзқҖи·Ҝеҫ„жҲ–иҖ… step жқҘйҖүеҸ–зҡ„гҖӮ
жҲ‘们е°Ҷз”Ёд»ҘдёӢзҡ„HTMLж–ҮжЎЈжқҘиҝӣиЎҢжј”зӨәпјҡ
html_doc = '''<html><head></head><body>
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore></body></html>'''
еҜје…ҘиҜӯеҸҘпјҢ并з”ҹжҲҗHTMLзҡ„DOMж ‘пјҡ
from lxml import etree
page = etree.HTML(html_doc)
3.1. и·Ҝеҫ„жҹҘжүҫ
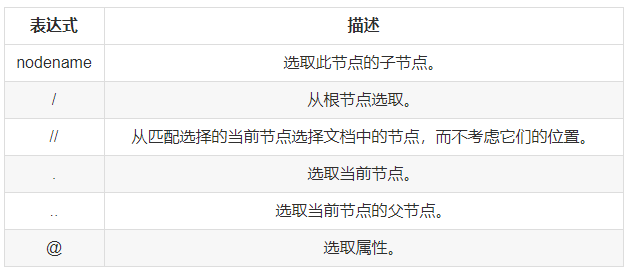
жҹҘжүҫеҪ“еүҚиҠӮзӮ№зҡ„еӯҗиҠӮзӮ№
In [1]: page.xpath('head')
Out[1]: [<Element head at 0x111c74c48>]д»Һж №иҠӮзӮ№иҝӣиЎҢжҹҘжүҫ
In [2]: page.xpath('/html')
Out[2]: [<Element html at 0x11208be88>]д»Һж•ҙдёӘж–ҮжЎЈдёӯжүҖжңүиҠӮзӮ№жҹҘжүҫ
In [3]: page.xpath('//book')
Out[3]:
[<Element book at 0x1128c02c8>, <Element book at 0x111c74108>, <Element book at 0x111fd2288>, <Element book at
0x1128da348>]йҖүеҸ–еҪ“еүҚиҠӮзӮ№зҡ„зҲ¶иҠӮзӮ№
In [4]: page.xpath('//book')[0].xpath('..')
Out[4]: [<Element bookstore at 0x1128c0ac8>]йҖүеҸ–еұһжҖ§
In [5]: page.xpath('//book')[0].xpath('@category')
Out[5]: ['COOKING']3.2. иҠӮзӮ№жҹҘжүҫ

nodename[1]
йҖүеҸ–第дёҖдёӘе…ғзҙ гҖӮ
nodename[last()]
йҖүеҸ–жңҖеҗҺдёҖдёӘе…ғзҙ гҖӮ
nodename[last()-1]
йҖүеҸ–еҖ’数第дәҢдёӘе…ғзҙ гҖӮ
nodename[position()<3]
йҖүеҸ–еүҚдёӨдёӘеӯҗе…ғзҙ гҖӮ
nodename[@lang]
йҖүеҸ–жӢҘжңүеҗҚдёә lang зҡ„еұһжҖ§зҡ„е…ғзҙ гҖӮ
nodename[@lang='eng']
йҖүеҸ–жӢҘжңүlangеұһжҖ§пјҢдё”еҖјдёә eng зҡ„е…ғзҙ гҖӮ
йҖүеҸ–第дәҢдёӘbookе…ғзҙ
In [1]: page.xpath('//book[2]/@category')
Out[1]: ['CHILDREN']йҖүеҸ–еҖ’数第дёүдёӘbookе…ғзҙ
In [2]: page.xpath('//book[last()-2]/@category')
Out[2]: ['CHILDREN']йҖүеҸ–第дәҢдёӘе…ғзҙ ејҖе§Ӣзҡ„жүҖжңүе…ғзҙ
In [3]: page.xpath('//book[position() > 1]/@category')
Out[3]: ['CHILDREN', 'WEB', 'WEB']йҖүеҸ–categoryеұһжҖ§дёәWEBзҡ„зҡ„е…ғзҙ
In [4]: page.xpath('//book[@category="WEB"]/@category')
Out[4]: ['WEB', 'WEB']3.3. жңӘзҹҘиҠӮзӮ№

еҢ№й…Қ第дёҖдёӘbookе…ғзҙ дёӢзҡ„жүҖжңүе…ғзҙ
In [1]: page.xpath('//book[1]/*')
Out[1]:
[<Element title at 0x111f76788>,
<Element author at 0x111f76188>,
<Element year at 0x1128c1a88>,
<Element price at 0x1128c1cc8>]3.4. иҺ·еҸ–иҠӮзӮ№дёӯзҡ„ж–Үжң¬
з”Ёtext()иҺ·еҸ–жҹҗдёӘиҠӮзӮ№дёӢзҡ„ж–Үжң¬
In [1]: page.xpath('//book[1]/author/text()')
Out[1]: ['Giada De Laurentiis']еҰӮжһңиҝҷдёӘиҠӮзӮ№дёӢжңүеӨҡдёӘж–Үжң¬пјҢеҲҷеҸӘиғҪеҸ–еҲ°дёҖж®өгҖӮ
з”Ёstring()иҺ·еҸ–жҹҗдёӘиҠӮзӮ№дёӢжүҖжңүзҡ„ж–Үжң¬
In [2]: page.xpath('string(//book[1])')
Out[2]: '\n Everyday Italian\n Giada De Laurentiis\n3.5. йҖүеҸ–еӨҡдёӘи·Ҝеҫ„
йҖҡиҝҮеңЁи·Ҝеҫ„иЎЁиҫҫејҸдёӯдҪҝз”ЁвҖң|вҖқиҝҗз®—з¬ҰпјҢжӮЁеҸҜд»ҘйҖүеҸ–иӢҘе№ІдёӘи·Ҝеҫ„гҖӮ
In [1]: page.xpath('//book[1]/title/text() | //book[1]/author/text()')
Out[1]: ['Everyday Italian', 'Giada De Laurentiis']зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们еҜ№XpathеҰӮдҪ•жҸҗеҸ–HTMLж•°жҚ®жңүиҝӣдёҖжӯҘзҡ„дәҶи§Јеҗ—пјҹеҰӮжһңиҝҳжғідәҶи§ЈжӣҙеӨҡзҹҘиҜҶжҲ–иҖ…зӣёе…іеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеӨ§е®¶зҡ„ж”ҜжҢҒгҖӮ





