这篇文章将为大家详细讲解有关python如何实现爬取中国前20大学排名案例,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
一、中国大学排名爬虫案例的步骤如下:
步骤1:从网络上获取大学排名网页内容 getHTMLText()
步骤2:提取网页内容中信息到合适的数据结构 fillUnivList()
步骤3:利用数据结构展示并输出结果 printUnivList()

实例代码
import requests
import bs4
from bs4 import BeautifulSoup
def getHTMLText(url):
'''从网络上获取大学排名网页内容'''
try:
r = requests.get(url, timeout=30)
# #如果状态不是200,就会引发HTTPError异常
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
'''提取网页内容中信息到合适的数据结构'''
soup = BeautifulSoup(html, "html.parser")
# 查找html中tbody标签的所有<tr>子标签
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
# tds[0].string 是排名,tds[1].string 是学校名称,tds[3].string 是学校的总分
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
''' 打印前 num 名的大学'''
# {1:{3}^10} 中的 {3} 代表取第三个参数
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","学校名称","总分",chr(12288))) # chr(12288) 代表中文空格
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288))) # chr(12288) 代表中文空格
def main():
uinfo = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'
html = getHTMLText(url)# 获取大学排名网页内容
fillUnivList(uinfo, html)#提取网页内容中信息
printUnivList(uinfo, 20) #输出结果
main()结果如下
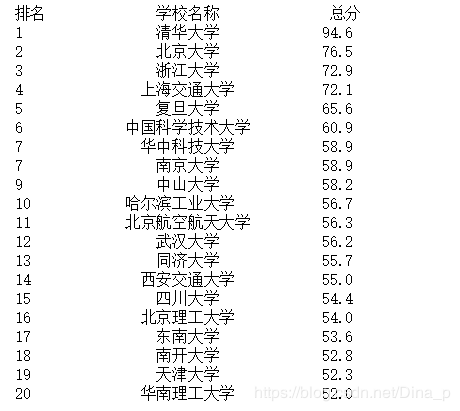
关于python如何实现爬取中国前20大学排名案例就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



