Python内置模块collections是什么?很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
collections模块
Python内置模块,在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1、namedtuple: 生成可以使用名字来访问元素内容的tuple。
2、deque: 双端队列,可以快速的从头或尾追加和删除元素。
3、Counter: 计数器,主要用来计数。
4、OrderedDict: 有序字典。
5、defaultdict: 带有默认值的字典。
namedtuple:命名元组
我们知道元组是不可被修改的容器,如元组(10,2),单从这个元组的元素来看,我们不知道这个元组的元素到底表示的是什么。它可以表示一对普通数字,亦可以表示一个坐标轴的两个坐标,还可以表示10的2次幂等,为了解决这个问题namedtuple应运而生。下面是基础示例:
我们假设(10,2)是一个坐标:
from collections import namedtuple
# 创建命名元组对象命名,并指定元组长度
point = namedtuple("point",["x","y"])
# 创建命名元组
tuple_1 = point(10,2)
# 以x,y的形式打印元素
print(tuple_1.x,tuple_1.y)打印内容如下
10 2
下面以计算长方体体积为例:
from collections import namedtuple
# 创建命名元组对象命名,并指定元组长度
Cuboid = namedtuple("Cuboid",["len","width","height"])
# 创建命名元组
tuple_1 = Cuboid(10,8,6)
# 对比两种打印方式我们就可以看出
# 第一种明显比第二种打印方式更容易理解
print(tuple_1.len * tuple_1.width * tuple_1.height)
print(tuple_1[0] * tuple_1[1] * tuple_1[2])打印内容如下
480 480
由上面的示例可以知道有时候利用命名元组引用元素的时候,我们可以更容易理解元素所表示的是什么。这样对代码的理解会更好。
deque:双端队列
deque与列表类似都是线性存储,但是队列只支持在队列的头部和尾部追加和删除元素,属于列表的特殊版。在插入元素和删除元素的效率上比列表更快。因为列表不仅可以在头部和尾部追加和删除元素,还可以在任意位置追加和删除元素。每当列表删除一个非头部和尾部元素的时候,列表就要重新进行排序以保证列表的线性存储。如下图所示:
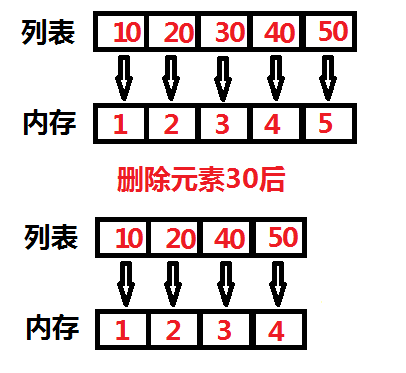
由上图我们知道元素30对应的内存地址是3,删除元素30后,为保证列表的线性,元素40和元素50内存地址都向前移了一位,元素40的内存地址由原来的4变成3,元素50的内存地址由原来的5变成4。如果把列表的第一个元素删除了,后面的整个列表都会依次向前补齐位置。而双端队列不会,无论是删除队列的头还是尾队列的整体不会进行补位的操作。
from collections import deque
deque_list = deque([1,2,3,4])
deque_list.appendleft("a") # 向头部追加元素
deque_list.append("z") # 向尾部追加元素
print("追加后的数据是:",deque_list)
deque_list.pop() # 删除尾部元素
deque_list.popleft() # 删除头部元素
print("删除后的数据是:",deque_list)打印内容如下
追加后的数据是: deque(['a', 1, 2, 3, 4, 'z']) 删除后的数据是: deque([1, 2, 3, 4])
OrderedDict:有序字典,有序字典是按照键插入顺序进行排列的(Python3.X的字典是按着键插入顺序进行排序的,Python2.X的字典键是按照ASCII表的顺序进行排序。)
如下:Python2.7中进行测试。
dict_1 = {}
dict_1["z"] = 1
dict_1["c"] = 3
dict_1["a"] = 2
dict_od = OrderedDict() # 有序字典
dict_od["z"] = 1
dict_od["c"] = 3
dict_od["a"] = 2
print(dict_1)
print(dict_od) # 打印有序字典打印内容如下
{'a': 2, 'c': 3, 'z': 1}
OrderedDict([('z', 1), ('c', 3), ('a', 2)])defaultdict:默认字典,我感觉这个还是有些用的。
1、如果默认字典的键不存在,不会报错。
2、在定义默认字典时可以指定值的类型。
示例:将列表中大于3的元素保存到字典的“a”键中,将小于3的元素保存到字典的“b”键中。
如下:使用普通字典的方法。
list_1 = [1,2,3,4,5,6]
dict_1 = {}
for i in list_1:
if i > 3:
if "a" in dict_1:
dict_1["a"].append(i)
else:
dict_1["a"] = [i]
else:
if "b" in dict_1:
dict_1["b"].append(i)
else:
dict_1["b"] = [i]
print(dict_1)打印内容如下
{'b': [1, 2, 3], 'a': [4, 5, 6]}如下:使用默认字典的方法。
from collections import defaultdict
list_1 = [1,2,3,4,5,6]
dict_d = defaultdict(list) # 定义默认字典
for i in list_1:
if i > 3:
dict_d["a"].append(i)
else:
dict_d["b"].append(i)
print(dict_d)
# 打印内容如下
defaultdict(<class 'list'>, {'b': [1, 2, 3], 'a': [4, 5, 6]})对比两个代码段可以发现使用默认字典的方式代码更加简洁,结构更加清晰明了。
Counter:统计可迭代对象中每个元素出现的次数。
from collections import Counter
list_1 = ["a","b","a",1,2,3,1]
print(Counter(list_1))
# 打印内容如下
Counter({'a': 2, 1: 2, 'b': 1, 2: 1, 3: 1})看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





