今天上班的时候,突然收到集群很多容器调度失败的告警,大致如下;

看到大量容器调度失败,里面查了下管理平台,看看这个时间段内有没有哪个业务发布,果然发现有一个转码服务(CPU消耗性)的业务在这个时间点发布了一批任务。但这批任务发布为什么会导致出现一堆任务调度失败呢?
紧接着我们抽查了几个告警的容器,发现这些容器状态都处于proeempted (抢占)状态,原因只能是有更高优先级的pod调度到这台node节点,把上面原有的pod 排挤走。但是刚刚发布的这个业务并没有设置容器调度优先级,为什么会比其他容器优先级高呢?
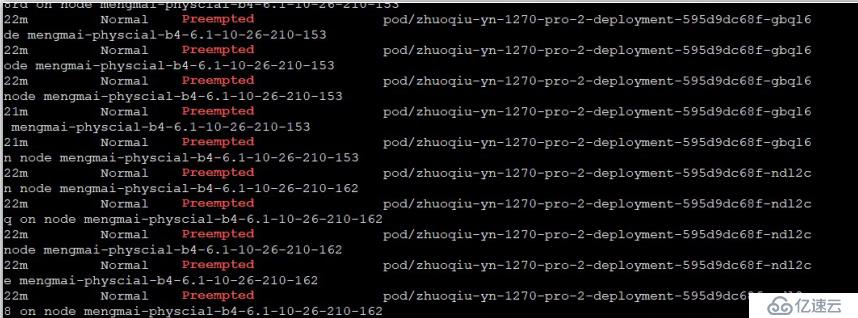
经排查是因为同事在管理平台上调整了容器默认优先级,由原来的默认低优先级修改成高优先级,具体背景是这样:
前几天有业务反馈他们的业务跑着跑着突然容器挂掉了,最后发现是因为调度了高优先级容器过去导致原本低优先级pod被排挤走。业务方同事觉得这个策略不靠谱,如果大家上来都选择最高优先级,那所有人优先级都一样了,他们建议默认策略改成最高优先级,允许业务按需将优先级调低,优先级低的容器在最后做成本分摊的时候适当打折,于是容器组同事将管理平台上面的容器调度默认优先级修改为最高优先级。
同事将PriotityClasses 中highest-priority 的 globalDefault 设置成了true,也就是说默认所有新调度的容器都将是最高优先级。
查看 PriorityClasses 配置
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: highest-priority
value: 400
globalDefault: true
官网上关于priorityClass 做了以下解释
The globalDefault field indicates that the value of this PriorityClass should be used for Pods without a priorityClassName. Only one PriorityClass with globalDefault set to true can exist in the system. If there is no PriorityClass with globalDefault set, the priority of Pods with no priorityClassName is zero.
PriorityClass 还有两个可选的字段:globalDefault 和 description。globalDefault 表示 PriorityClass 的值应该给那些没有设置 PriorityClassName 的 Pod 使用。整个系统只能存在一个 globalDefault 设置为 true 的 PriorityClass。如果没有任何 globalDefault 为 true 的 PriorityClass 存在,那么,那些没有设置 PriorityClassName 的 Pod 的优先级将为 0。
注意
1、If you upgrade your existing cluster and enable this feature, the priority of your existing Pods is effectively zero.
如果您升级已经存在的集群环境,并且启用了该功能,那么,那些已经存在系统里面的 Pod 的优先级将会设置为 0。
2、Addition of a PriorityClass with globalDefault set to true does not change the priorities of existing Pods. The value of such a PriorityClass is used only for Pods created after the PriorityClass is added.
将一个 PriorityClass 的 globalDefault 设置为 true,不会改变系统中已经存在的 Pod 的优先级。也就是说,PriorityClass 的值只能用于在 PriorityClass 添加之后创建的那些 Pod 当中。
也就是说priorityClass 中的globalDefault 设为true的话,只针对后续发布的Pod生效,已发布的Pod优先级仍为0
今天早上遇到的问题是集群中一台机器宕机,然后上面所有的pod 都重新调度到其他机器,这些重新调度的Pod拥有最高优先级,当这批容器调度到其他node节点后就会把该节点上面原有的低优先级Pod排挤走。然后这些被排挤走的Pod 又拥有最高优先级调度到其他node节点,又把另外一台节点上面的Pod挤走,最终造成整个集群雪崩(全部容器重启了一遍)。
总结:
1、将 priorityClass 中 globalDefault 设置为false 并通过前端默认设置最高优先级
在Pod中指定默认优先级而不是通过globalDefault指定
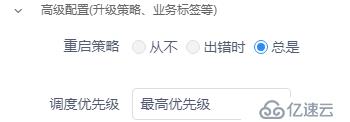
2、关注集群资源使用情况,资源不足时应及时扩容,至少保证集群中挂掉2,3台node节点后,上面承载的容器能够漂移到其他剩下的node节点上。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





