作者 | 黄子毅(紫益) 阿里前端技术专家
导读:前端开发者是最早享受到 “Serverless” 好处的群体,因为浏览器就是一个开箱即用、甚至无需为计算付费的环境!Serverless 把前端开发体验带入了后端,利用 FaaS 与 BaaS 打造一套开箱即用的后端开发环境。本文作者将从前端角度出发,为你讲述 Serverless 带来的收益及挑战。
Serverless 是一种 “无服务器架构”,让用户无需关心程序运行环境、资源及数量,只要将精力 Focus 到业务逻辑上的技术。
现在公司已经实现 DevOps 化,正在向 Serverless 迈进,而为什么前端×××erless?
对业务前端同学:
对一个自由开发者:
前端框架总是带入后端思维,而 Serverless 则是把前端思维带入了后端运维。
前端开发者其实是最早享受到 “Serverless” 好处的群体。他们不需要拥有自己的服务,甚至不需要自己的浏览器,就可以让自己的 JS 代码均匀、负载均衡的运行在每一个用户的电脑中。
而每个用户的浏览器,就像现在最时髦、最成熟的 Serverless 集群,从远程加载 JS 代码开始冷启动,甚至在冷启动上也是卓越领先的:利用 JIT 加速让代码实现毫秒级别的冷启动。不仅如此,浏览器还实现了 BaaS 服务的完美环境,我们可以调用任何函数获取用户的 Cookie、环境信息、本地数据库服务,而无需关心用户用的是什么电脑,连接了怎样的网络,甚至硬盘的大小。
这就是 Serverless 理念。通过 FaaS(函数即服务)与 BaaS(后台即服务)企图在服务端制造前端开发者习以为常的开发环境,所以前端开发者应该更能理解 Serverless 带来的好处。
FaaS(函数即服务) + BaaS(后台即服务) 可以称为一个完整的 Serverless 的实现。除此之外,还有 PaaS(平台即服务)的概念。而通常平台环境都通过容器技术实现,最终都为了达到 NoOps(无人运维),或者至少 DevOps(开发&运维)。
简单介绍一下这几个名词,防止大家被绕晕:
函数即服务,每一个函数都是一个服务,函数可以由任何语言编写,除此之外不需要关心任何运维细节,比如:计算资源、弹性扩容,而且可以按量计费,且支持事件驱动。业界大云厂商都支持 FaaS,各自都有一套工作台、或者可视化工作流来管理这些函数。
后端及服务,就是集成了许多中间件技术,可以无视环境调用服务,比如数据即服务(数据库服务),缓存服务等。虽然下面还有很多 XAAS,但组成 Serverless 概念的只有 FaaS + BaaS。
平台即服务,用户只要上传源代码就可以自动持续集成并享受高可用服务,如果速度足够快,可以认为是类似 Serverless。但随着以 Docker 为代表的容器技术兴起,以容器为粒度的 PaaS 部署逐渐成为主流,是最常用的应用部署方式。比如中间件、数据库、操作系统等。
数据即服务,将数据采集、治理、聚合、服务打包起来提供出去。DaaS 服务可以应用 Serverless 的架构。
基础设施即服务,比如计算机存储、网络、服务器等基建设施以服务的方式提供。
软件即服务,比如 ERP、CRM、邮箱服务等,以软件为粒度提供服务。
容器就是隔离了物理环境的虚拟程序执行环境,而且环境可被描述、迁移,比较热门的容器技术是 Docker。<br />随着容器数量增多,就出现了管理容器集群的技术,比较有名的容器编排平台是 Kubernetes。容器技术是 Serverless 架构实现的一种选择,也是实现的基础。
就是无人运维,比较理想主义,也许要借助 AI 的能力才能实现完全无人运维。
无人运维不代表 Serverless,Serverless 可能也需要人运维(至少现在),只是开发者不再需要关心环境。
笔者觉得可以理解为 “开发即运维”,毕竟出了事情,开发要被问责,而一个成熟的 DevOps 体系可以让更多的开发者承担 OP 的职责,或者与 OP 更密切的合作。
回到 Serverless,未来后端开发的体验可能与前端相似:不需要关心代码运行在哪台服务器(浏览器)、无需关心服务器环境(浏览器版本)、不用担心负载均衡(前端从未担心过)、中间件服务随时调用(LocalStorage、Service Worker)。
前端同学对 Serverless 应该尤为激动。就拿笔者亲身经历举例吧。
笔者非常迷恋养成类 Game ,养成 Game 最常见的就是资源建造、收集,或者挂机时计算资源的读秒规则。笔者在开发 Game 的时候,最初是将客户端代码与服务端代码完全分成两套实现的:
// ... UI 部分,画出一个倒计时伐木场建造进度条
const currentTime = await requestBuildingProcess();
const leftTime = new Date().getTime() - currentTime;
// ... 继续倒计时读条
// 读条完毕后,每小时木头产量 + 100,更新到客户端计时器
store.woodIncrement += 100;为了 Game 体验,用户可以在不刷新浏览器的情况下,看到伐木场建造进度的读条,以及“嘭”一下建造完毕,并且发现每秒钟多获得了 100 点木材!但是当伐木场建造完成前、完成时、完成后的任意时间点刷新浏览器,都要保持逻辑的统一,而且数据需要在后端离线计算。 此时就要写后端代码了:
// 每次登陆时,校验当前登陆
const currentTime = new Date().getTime()
// 获取伐木场当前状态
if ( /* 建造中 */) {
// 返回给客户端当前时间
const leftTime = building.startTime - currentTime
res.body = leftTime
} else {
// 建造完毕
store.woodIncrement += 100
}很快,建筑的种类多了起来,不同的状态、等级产量都不同,前后端分开维护成本会越来越大,我们需要做配置同步。
为了做前后端配置同步,可以将配置单独托管起来前后端共用,比如新建一个配置文件,专门存储 Game 信息:
export const buildings = {
wood: {
name: "..",
maxLevel: 100,
increamentPerLevel: 50,
initIncreament: 100
}
/* .. and so on .. */
};这虽然复用了配置,但前后端都有一些共同的逻辑可以复用,比如根据建筑建造时间判断建筑状态,判断 N 秒后建筑的产量等等。 而 Serverless 带来了进一步优化的空间。
试想一下,可以在服务器以函数粒度执行代码,我们可以这样抽象 Game 逻辑:
// 根据建筑建造时间判断建筑状态
export const getBuildingStatusByTime = (instanceId: number, time: number) => {
/**/
};
// 判断建筑生产量
export const getBuildingProduction = (instanceId: number, lastTime: number) => {
const status = getBuildingStatusByTime(instanceId, new Date().getTime());
switch (status) {
case "building":
return 0;
case "finished":
// 根据 (当前时间 - 上次打开时间)* 每秒产量得到总产量
return; /**/
}
};
// 前端 UI 层,每隔一秒调用一次 getBuildingProduction 函数,及时更新生产数据
// 前端入口函数
export const frontendMain = () => {
/**/
};
// 后端 根据每次打开时间,调用一次 getBuildingProduction 函数并入库
// 后端入口函数
export const backendMain = () => {
/**/
};利用 PaaS 服务,将前后端逻辑写在一起,将 getBuildingProduction 函数片段上传至 FaaS 服务,这样就可以同时共享前后端逻辑了!
在文件夹视图下,可以做如下结构规划:
.
├── client # 前端入口
├── server # 后端入口
├── common # 共享工具函数,可以包含 80% 的通用 Game 逻辑也许有人会问:前后端共享代码不止有 Serverless 才能做到。
的确如此,如果代码抽象足够好,有成熟的工程方案支持,是可以将一份代码分别导出到浏览器与服务器的。但 Serverless 基于函数粒度功能更契合前后端复用代码的理念,它的出现可能会推动更广泛的前后端代码复用,这虽然不是新发明,但足够称为一个伟大的改变。
<a name="6"></a>
传统 ECS 服务器在租赁时,CentOS 与 AliyunOS 的环境选择就足够让人烦恼。对个人开发者而言,我们要搭建一个完整的持续集成服务是很困难的,而且面临的选择很多,让人眼花缭乱:
Serverless 解决了这个问题,因为我们要上传的只是一个代码片段,不再需要面对服务器、系统环境、资源等环境问题,外部服务也有封装好的 BaaS 体系支持。
实际上在 Serverless 出来之前,就有许多后端团队利用 FaaS 理念简化开发流程。
为了减少写后端业务逻辑时,环境、部署问题的干扰,许多团队会将业务逻辑抽象成一个个区块(Block),对应到代码片段或 Blockly,这些区块可以独立维护、发布,最后将这些代码片段注入到主程序中,或动态加载。如果习惯了这种开发方式,那也更容易接受 Serverless。
站在后台角度,事情就变得比较复杂了。相对于提供简单的服务器和容器,现在要对用户屏蔽执行环境,将服务做得更厚。
笔者通过一些文章了解到,Serverless 的推行还面临着如下一些挑战:
所幸的是,这些问题都已经在积极处理中,而且不少有了已经落地的解决方案。
Serverless 给后台带来的好处远比面临的挑战多:
笔者在公司负责一个大型 BI 分析平台建设,BI 分析平台的底层能力之一就是可视化搭建。
那么可视化搭建能力该如何开放呢?现在比较容易做到的是组件开放,毕竟前端可以与后端设计相对解耦,利用 AMD 加载体系也比较成熟。
现在遇到的一个挑战就是后端能力开放,因为当对取数能力有定制要求时,可能需要定制后端数据处理的逻辑。目前能做到的是利用 maven3、jdk7 搭建本地开发环境测试,如果想上线,还需要后端同学的协助。
如果后端搭建一个特有的 Serverless BaaS 服务,那么就可以像前端组件一样进行线上 Coding、调试,甚至灰度发布进行预发测试。现在前端云端开发已经有了不少成熟的探索,Serverless 可以统一前后端代码在云端开发的体验,而不需要关心环境。
看了一些 Serverless 应用架构图,发现大部分业务都可以套用这样一张架构图:
cdn.com/bc941ec5ce067007e555c3d22d40631ec6ca86d9.png">
Serverless 带来的收益与挑战并存,本文站在前端角度聊一聊。
收益一:前端更 Focus 在前端体验技术,而不需要具备太多应用管理知识。
最近看了很多前端前辈写的总结文,最大的体会就是回忆 “前端在这几年到底起到了什么作用”。我们往往会夸大自己的存在感,其实前端存在的意义就是解决人机交互问题,大部分场景下,都是一种锦上添花的作用,而不是必须。
回忆你最自豪的工作经历,可能是掌握了 Node 应用的运维知识、前端工程体系建设、研发效能优化、标准规范制定等,但真正对业务起效的部分,恰恰是你觉得写得最不值得一提的业务代码。前端花了太多的时间在周边技术上,而减少了很多对业务、交互的思考。
即便是大公司,也难以招到既熟练使用 Nodejs,又具备丰富运维知识的人,同时还要求他前端技术精湛,对业务理解深刻,鱼和熊掌几乎不可兼得。
Serverless 可以有效解决这个问题,前端同学只需要会写 JS 代码而无需掌握任何运维知识,就可以快速实现自己的整套想法。
诚然,了解服务端知识是有必要的,但站在合理分工的角度,前端就应该 focus 在前端技术上。前端的核心竞争力或者带来的业务价值,并不会随着了解多一些运维知识而得到补充,相反,这会吞噬掉我们本可以带来更多业务价值的时间。
语言的进化、浏览器的进化、服务器的进化,都是从复杂到简单,底层到封装的过程,而 Serverless 是后端 + 运维作为一个整体的进一步封装的过程。
收益二:逻辑编排带来的代码高度复用、可维护,拓展 云+端 的能力。
云+端 是前端开发的下个形态,提供强大的云编码能力,或者通过插件将端打造为类似云的开发环境。其最大好处就是屏蔽前端开发环境细节,理念与 Serverless 类似。
之前有不少团队尝试过利用 GraphQL 让接口 “更有弹性”,而 Serverless 则是更彻底的方案。
我自己的团队就尝试过 GraphQL 方案,但由于业务非常复杂,难以用标准的模型描述所有场景的需求,因此不适合使用 GraphQL。恰恰是一套基于 Blockly 的可视化后端开发平台坚持了下来,而且取得了惊人的开发提效。这套 Blockly 通用化抽象后几乎可以由 Serverless 来代替。所以 Serverless 可以解决复杂场景下后端研发提效的问题。
Serverless 在融合了云端开发后,就可以通过逻辑编排进一步可视化调整函数执行顺序、依赖关系。
笔者之前在百度广告数据处理团队使用过这种平台计算离线日志,每个 MapReduce 计算节点经过可视化后,就可以轻松看出故障时哪个节点在阻塞,还可以看到最长执行链路,并为每个节点重新分配执行权重。即便逻辑编排不能解决开发的所有痛点,但在某个具体业务场景下一定可以大有作为。
挑战一:Serverless 可以完全取消前端转后端的门槛?
前端同学写 Node 代码最容易犯的毛病就是内存溢出。
浏览器 + Tab 天然是一个用完即关的场景,UI 组件与逻辑创建与销毁也非常频繁,因此前端同学很少,也不太需要关心 GC 问题。而 GC 在后端开发场景中是一个早已养成的习惯,因此 Nodejs 程序缓存溢出是大家×××
Serverless 应用是动态加载,长时间不用就会释放的,因此一般来说不需要太担心 GC 的问题,就算内存溢出,在内存被占满前可能已经进程被释放,或者被监测到异常强制 Kill 掉。
但毕竟 FaaS 函数的加载与释放完全是由云端控制的,一个常用的函数长时间不卸载也是有可能的,因此 FaaS 函数还是要注意控制副作用。
所以 Serverless 虽然抹平了运维环境,但服务端基本知识还需要了解,必须意识到代码跑在前端还是后端。
挑战二:性能问题
Serverless 的冷启动会导致性能问题,而让业务方主动关心程序的执行频率或者性能要求,再开启预热服务又重新将研发拖入了运维的深渊中。
即便是业界最成熟的亚马逊 Serverless 云服务,也无法做到业务完全不关心调用频率,就可以轻松应付秒杀场景。
因此目前 Serverless 可能更适合结合合适的场景使用,而不是任何应用都强行套用 Serverless。
虽然可以通过定期运行 FaaS 服务来保证程序一直 Online,但笔者认为这还是违背了 Serverless 的理念。
挑战三:如何保证代码可迁移性
有一张很经典的 Serverless 定位描述图:
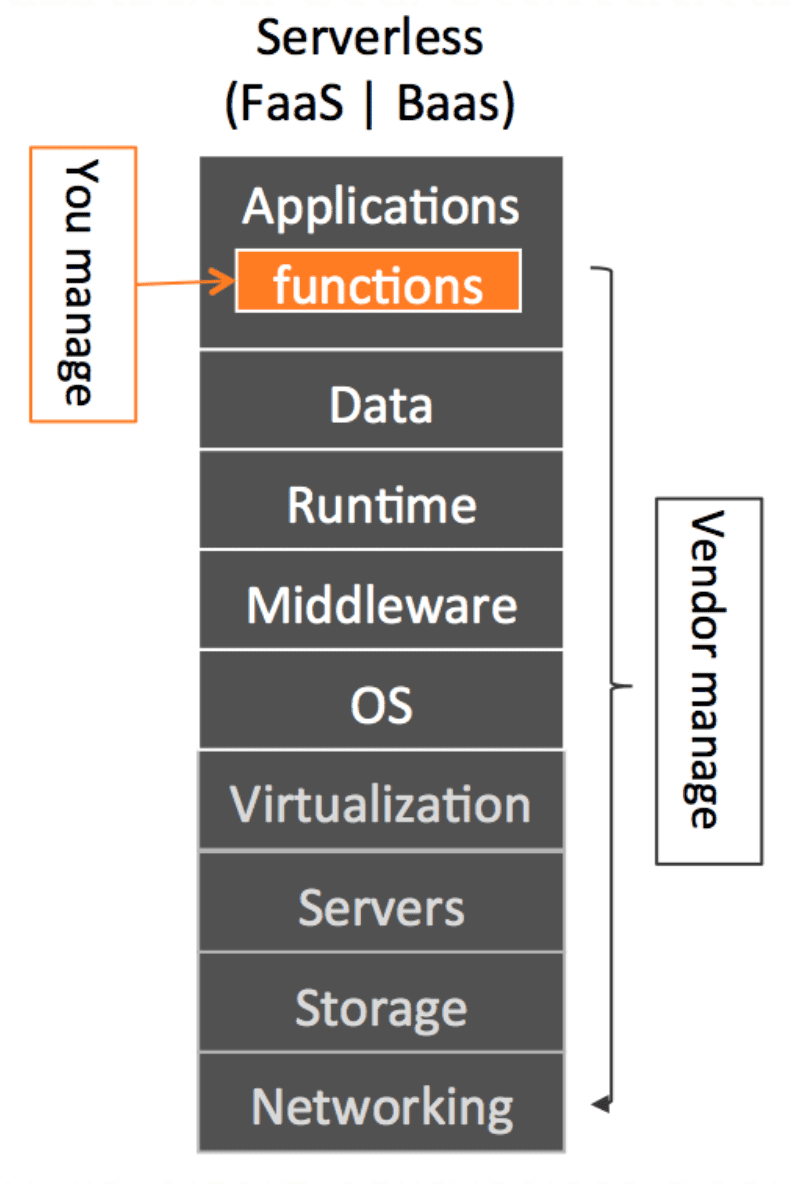
网络、存储、服务、虚拟家、操作系统、中间件、运行时、数据都不需要关心了,甚至连应用层都只需要关心其中函数部分,而不需要关心其他比如启动、销毁部分。
前面总拿这点当优势,但也可以反过来认为是个劣势。 当你的代码完全依赖某个公有云环境后,你就失去了整体环境的掌控力,甚至代码都只能在特定的云平台才能运行。
不同云平台提供的 BaaS 服务规范可能不同,FaaS 的入口、执行方式也可能不同,想要采用多云部署就必须克服这个问题。
现在许多 Serverless 平台都在考虑做标准化,但同时也有一些自下而上的工具库抹平一些差异,比如 Serverless Framework 等。
而我们写 FaaS 函数时,也尽量将与平台绑定的入口函数写得轻一些,将真正的入口放在通用的比如 main 函数中。
Serverless 的价值远大于挑战,其理念可以切实解决许多研发效能问题。
但目前 Serverless 发展阶段仍处于早期,国内的 Serverless 也处于尝试阶段,而且执行环境存在诸多限制,也就是并没有完全实现 Serverless 的美好理念,因此如果什么都往上套一定会踩坑。
可能在 3-5 年后,这些坑会被填平,那么你是选择加入填坑大军,还是选一个合适的场景使用 Serverless 呢?
“ 阿里巴巴云×××icloudnative×××erverless、容器、Service Mesh等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发×××
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





