构建一个企业级分布式存储系统对于任何一个团队来说,都是一件极具挑战性的工作。不仅需要大量的理论基础,还需要有良好的工程能力。SmartX 在分布式存储领域已经投入 5 年的时间,积累了很多宝贵的实践经验。我们将通过一系列文章,向大家详细介绍 SmartX 如何构建分布式块存储产品。本文是第一部分,整理自 SmartX 联合创始人兼 CTO 张凯在 QCon 2018 大会上的演讲,着重介绍相关背景和元数据服务。

大家下午好,我今天跟大家分享的题目是『ZBS:SmartX 自研分布式块存储系统』。SmartX 是我们公司的名字,我本人是这个公司的联合创始人兼 CTO。ZBS 是 SmartX 研发的分布式块存储产品的名字。

我毕业于清华计算机系,毕业以后加入百度基础架构部工作了两年,主要从事分布式系统和大数据相关的工作。我本身也是开源社区的代码贡献者,参与的项目包括 Sheepdog 和 InfluxDB。其中 Sheepdog 是一个开源的分布式块存储项目,InfluxDB 是一个时序数据库(Time Series Database,TSDB)项目。2013 年我从百度离职,和清华的两个师兄一起创办了 SmartX 公司。

SmartX 于 2013 年成立,是一个以技术为主导的公司,目前主要专注于分布式存储及虚拟化这个两个领域。我们的产品均为自己研发,目前已经运行在数千台物理服务器上,存储了数十 PB 的数据。SmartX 跟国内主流的硬件服务商、云服务商都有合作,我们的产品已经服务了包括公有云、私有云以及金融业、制造业等核心领域的关键业务,其中也包括核心应用和核心数据库等应用场景。今天我将主要围绕分布式块存储进行介绍。

一般来说,我们根据存储的访问接口以及应用场景,把分布式存储分为三种类型,包括分布式块存储,分布式文件存储,和分布式对象存储。
其中,分布式块存储的主要应用场景包括:
虚拟化:比如像 KVM,VMware,XenServer 等 Hypervisor,以及像 Openstack,AWS 等云平台。块存储在其中的角色是支撑虚拟机中的虚拟盘的存储。
数据库:比如 MySQL,Oracle 等。很多 DBA 都将数据库的数据盘运行在一个共享的块存储服务上,例如分布式块存储。此外也有很多客户直接把数据库运行在虚拟机中。
容器:容器最近几年在企业中使用越来越广泛。一般来说,容器中运行的应用都是无状态的,但在很多应用场景下,应用也会有数据持久化的需求。应用可以选择将数据持久化到数据库中,也可以选择将数据持久化到一个共享虚拟磁盘上。这个需求对应到 Kubernetes 中,就是 Persistent Volume 这个功能。

今天我将主要围绕 SmartX 如何打造分布式块存储进行介绍。SmartX 从 2013 年成立开始,到目前已经积累了 5 年左右的分布式块存储的研发经验,所以今天我们除了分享 SmartX 如何实现我们自己研发的分布式块存储 ZBS 以外,还会详细介绍我们在分布式块存储的研发过程中的一些思考和选择。此外也将介绍一下我们产品未来的规划。
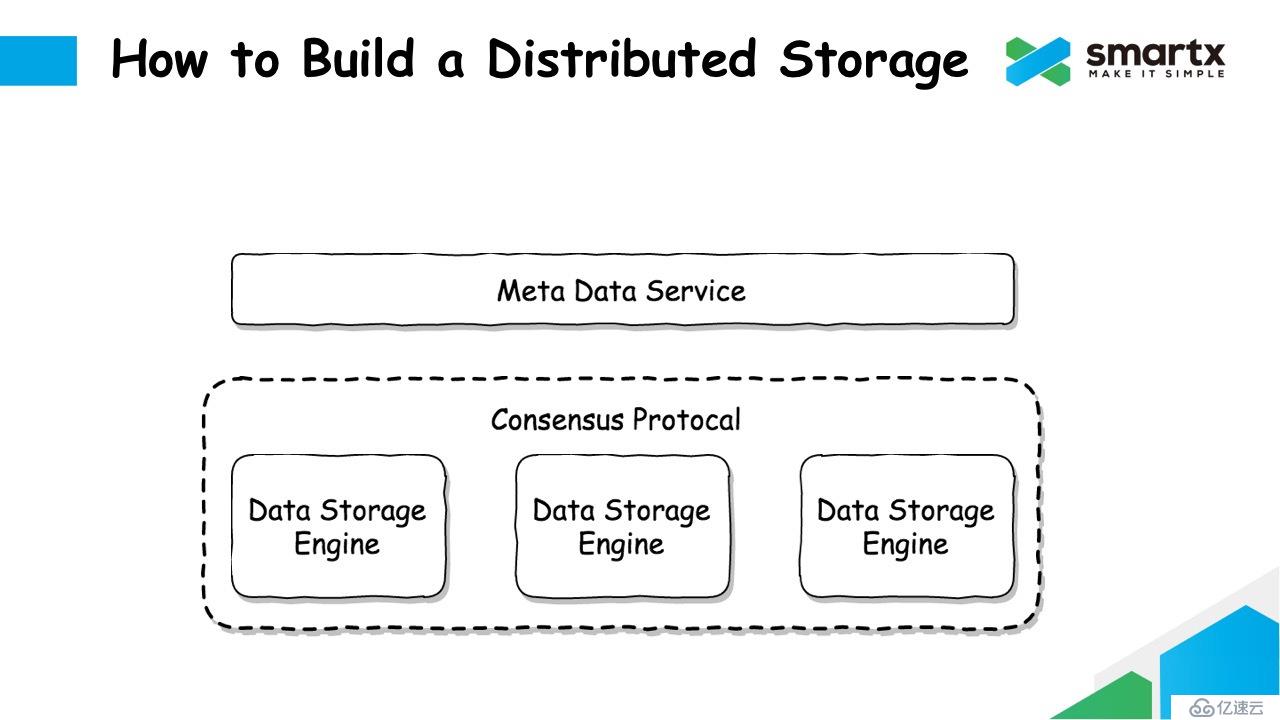
从广泛意义上讲,分布式存储中通常需要解决三个问题,分别是元数据服务,数据存储引擎,以及一致性协议。
其中,元数据服务提供的功能一般包括:集群成员管理,数据寻址,副本分配,负载均衡,心跳,垃圾回收等等。数据存储引擎负责解决数据在单机上存储,以及本地磁盘的管理,磁盘故障处理等等。每一个数据存储引擎之间是隔离的,在这些隔离的存储引擎之间,需要运行一个一致性协议,来保证对于数据的访问可以满足我们期望的一致性状态,例如强一致,弱一致,顺序一致,线性一致等等。我们根据不同的应用场景,选择一个适合的一致性协议,这个协议将负责数据在不同的节点之间的同步工作。
有了这三部分,我们基本上就掌握了一个分布式存储的核心。不同的分布式存储系统之间的区别,基本也都来自于这三个方面的选择不同。
接下来我会分别从这三个方面介绍一下我们在做 ZBS 系统设计的时候是怎样思考的,以及最终决定采用哪种类型的技术和实现方法。

首先我们来介绍一下元数据服务。我们先来谈谈我们对元数据服务的需求。
所谓元数据就是『数据的数据』,比如说数据放在什么位置,集群中有哪些服务器,等等。如果元数据丢失了,或者元数据服务无法正常工作,那么整个集群的数据都无法被访问了。
由于元数据的重要性,所以对元数据的第一个需求就是可靠性。元数据必须是保存多份的,同时元数据服务还需要提供 Failover 的能力。
第二个需求就是高性能。尽管我们可以对 IO 路径进行优化,使得大部分 IO 请求都不需要访问元数据服务,但永远都有一些 IO 请求还是需要修改元数据,比如数据分配等等。为避免元数据操作成为系统性能的瓶颈,元数据操作的响应时间必须足够短。同时由于分布式系统的集群规模在不断的扩大,对于元数据服务的并发能力也有一定的要求。
最后一个需求是轻量级。由于我们产品大部分使用场景是私有部署,也就是我们的产品是部署在客户的数据中心的,且由客户自己运维,而非我们的运维人员运维。这个场景和很多互联网公司自己来运维自己的产品是完全不同的场景。所以对于 ZBS 来说,我们更强调整个系统,尤其是元数据服务的轻量级,以及易运维的能力。我们期望元数据服务可以轻量级到可以把元数据服务和数据服务混合部署在一起。同时我们希望大部分的运维操作都可以由程序自动完成,或用户只需要在界面上进行简单的操作就可以完成。如果大家了解 HDFS 的话,HDFS 中的元数据服务的模块叫做 Namenode,这是一个非常重量级的模块。Namenode 需要被独立部署在一台物理服务器上,且对硬件的要求非常高,且非常不易于运维,无论是升级还是主备切换,都是非常重的操作,非常容易因操作问题而引发故障。
以上就是我们对元数据服务的需求。接下来我们来看一下具体有哪些方法可以构造一个元数据服务。

谈到存储数据,尤其是存储结构化的数据,我们第一个想到的就是关系型数据库,例如 MySQL,以及一些成熟的 KV 存储引擎,例如 LevelDB,RocksDB 等。但这种类型的存储最大的问题就是无法提供可靠的数据保护和 Failover 能力。LevelDB 和 RocksDB 虽然非常轻量级,但都只能把数据保存在单机上。而尽管 MySQL 也提供一些主备方案,但我们认为 MySQL 的主备方案是一个太过笨重的方案,且缺乏简易的自动化运维方案,所以并不是一个十分好的选择。
其次,我们来看一下一些分布式数据库,例如 MongoDB 和 Cassandra。这两种分布式数据库都可以解决数据保护和提供 Failover 机制。但是他们都不提供 ACID 机制,所以在上层实现时会比较麻烦,需要额外的工作量。其次就是这些分布式数据库在运维上也相对复杂,不是很易于自动化运维。

也有一种选择是基于 Paxos 或者 Raft 协议自己实现一个框架。但这样实现的代价非常大,对于一个创业公司不是一个很划算的选择。并且我们创业的时间是 2013 年,当时 Raft 也只是刚刚提出。
第四种是选择 Zookeeper。Zookeeper 基于 ZAB 协议,可以提供一个稳定可靠地分布式存储服务。但 Zookeeper 的最大的问题是能够存储的数据容量非常有限。为了提高访问速度,Zookeeper 把存储的所有数据都缓存在内存中,所以这种方案导致元数据服务所能支撑的数据规模严重受限于服务器的内存容量,使得元数据服务无法做到轻量级,也无法和数据服务混合部署在一起。
最后还有一种方式是基于 Distributed Hash Table(DHT)的方法。这种方法的好处元数据中不需要保存数据副本的位置,而是根据一致性哈希的方式计算出来,这样就极大地降低了元数据服务的存储压力和访问压力。但使用 DHT 存在的问题,就丧失了对数据副本位置的控制权,在实际生产环境中,非常容易造成集群中的产生数据不均衡的现象。同时在运维过程中,如果遇到需要添加节点,移除节点,添加磁盘,移除磁盘的情况,由于哈希环会发生变化,一部分数据需要重新分布,会在集群中产生不必要的数据迁移,而且数据量往往非常大。而这种于运维操作在一个比较大规模的环境中几乎每天都会发生。大规模的数据迁移很容易影响到线上的业务的性能,所以 DHT 使得运维操作变得非常麻烦。
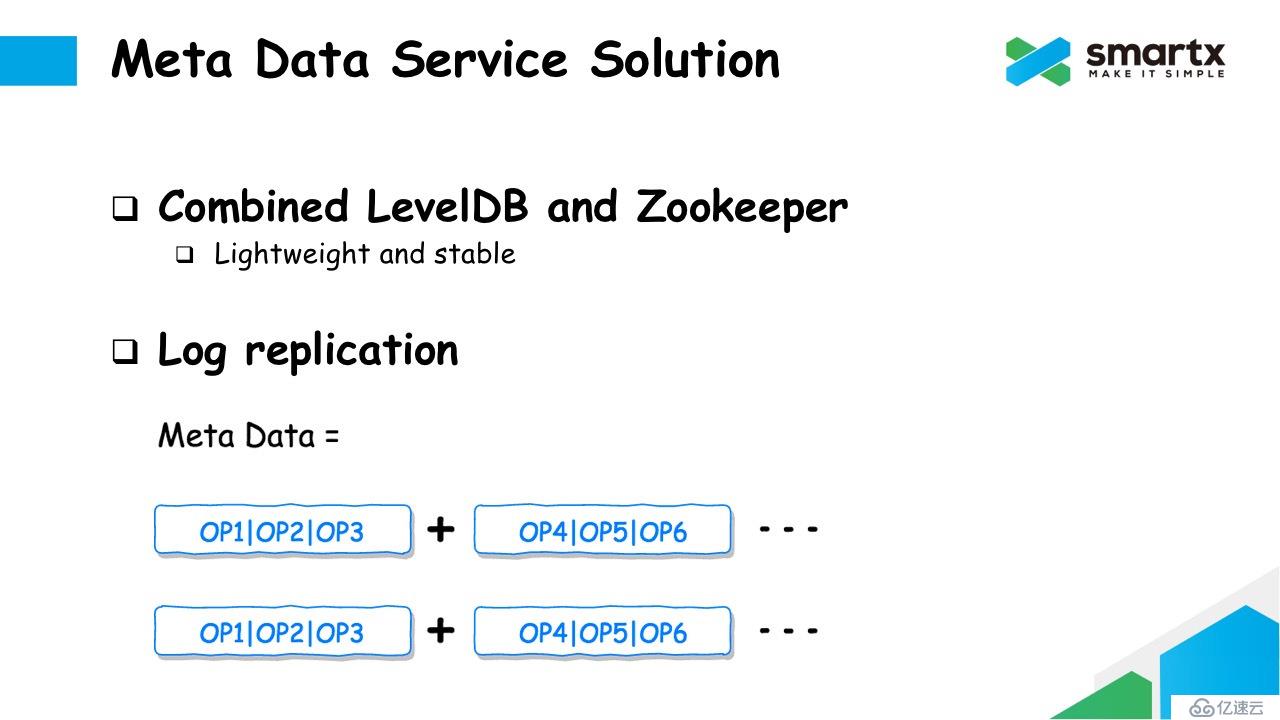
以上介绍的方法都存在各种各样的问题,并不能直接使用。最终 ZBS 选择了使用 LevelDB(也可以替换成 RocksDB) 和 Zookeeper 结合的方式,解决元数据服务的问题。首先,这两个服务相对来说都非常轻量级;其次 LevelDB 和 Zookeeper 使用在生产中也非常稳定。
我们采用了一种叫做 Log Replication 的机制,可以同时发挥 LevelDB 和 Zookeeper 的优点,同时避开他们自身的问题。
这里我们简单的介绍一下 Log Replication。简单来说,我们可以把数据或者状态看作是一组对数据操作的历史集合,而每一个操作都可以通过被序列化成 Log 记录下来。如果我们可以拿到所有 的 Log,并按照 Log 里面记录的操作重复一遍,那么我们就可以完整的恢复数据的状态。任何一个拥有 Log 的程序都可以通过重放 Log 的方式恢复数据。如果我们对 Log 进行复制,实际上也就相当于对数据进行了复制。这就是 Log Replication 最基本的想法。
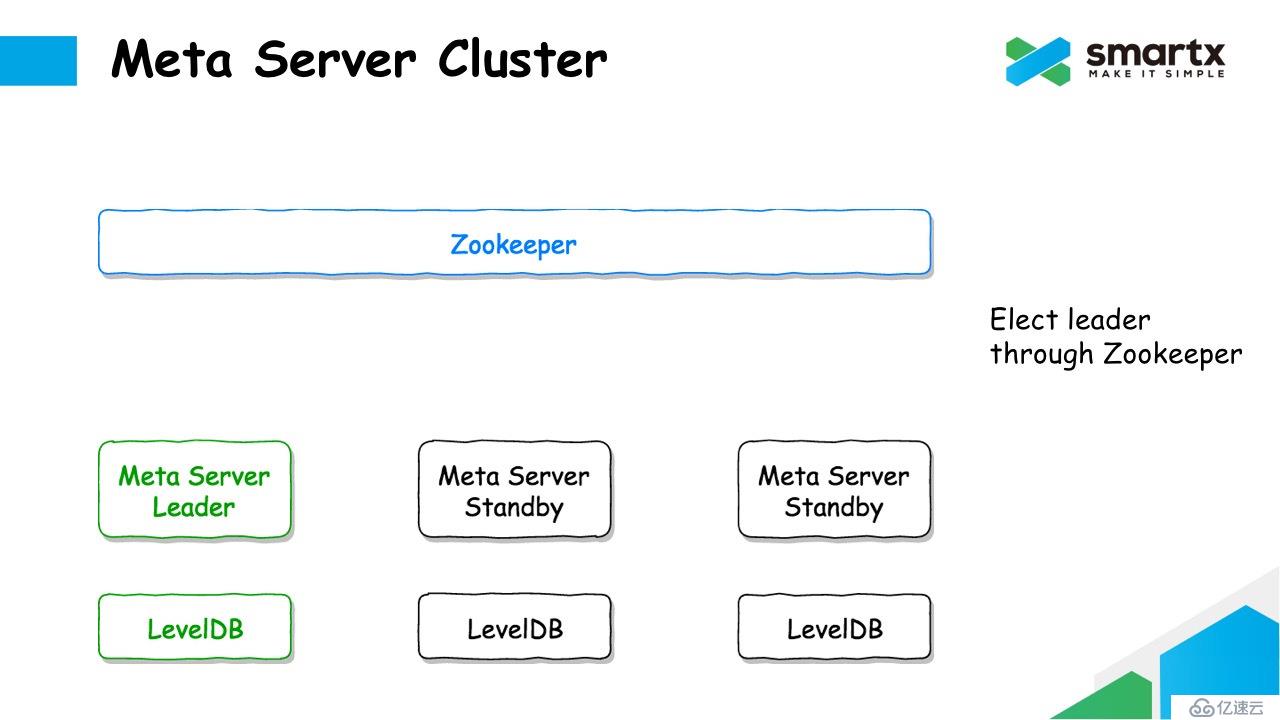
我们具体来看一下 ZBS 是如何利用 Zookeeper + LevelDB 完成 Log Replication 操作的。首先,集群中有很多个 Meta Server,每个 Server 本地运行了一个 LevelDB 数据库。Meta Server 通过 Zookeeper 进行选主,选出一个 Leader 节点对外响应元数据请求,其他的 Meta Server 则进入Standby 状态。
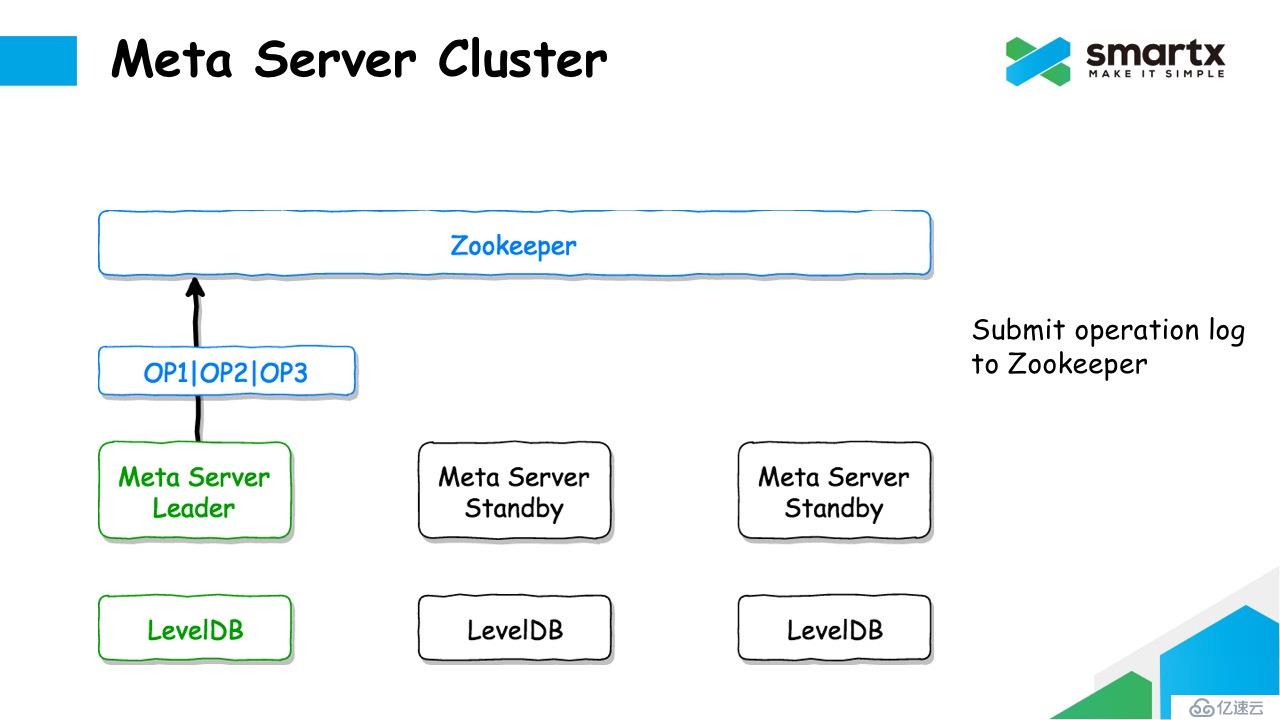
当 Leader 节点接收到元数据的更新操作后,会将这个操作序列化成一组操作日志,并将这组日志写入 Zookeeper。由于 Zookeeper 是多副本的,所以一旦 Log 数据写入 Zookeeper,也就意味着 Log 数据是安全的了。同时这个过程也完成了对 Log 的复制。
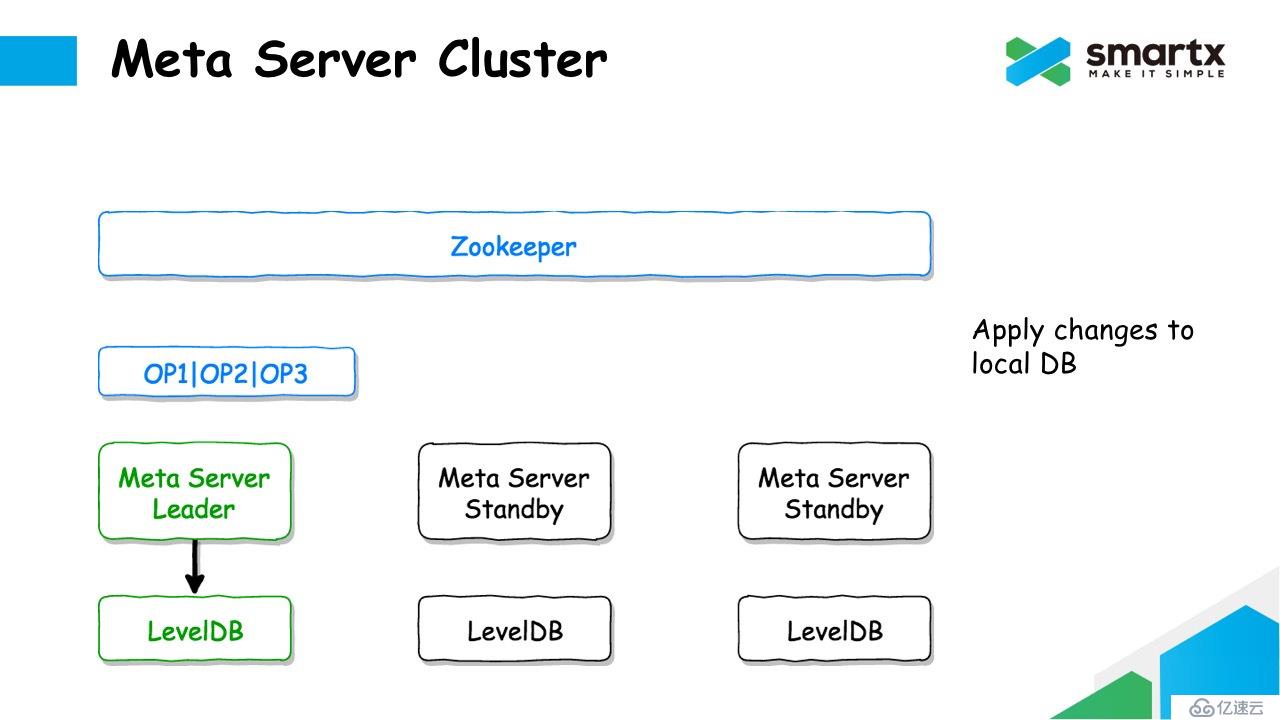
当日志提交成功后,Meta Server 就可以将对元数据的修改同时提交到本地的 LevelDB 中。这里 LevelDB 中存储的是一份全量的数据,而不需要以 Log 的形式存储。
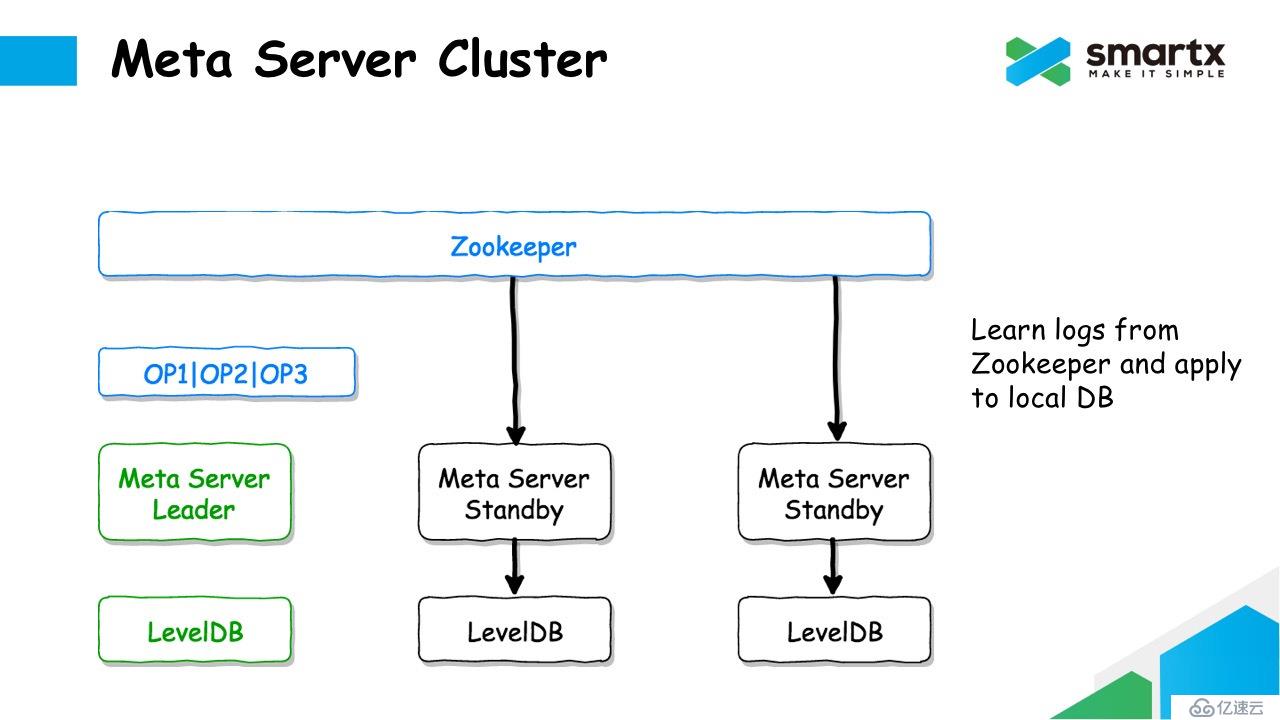
对于非 Leader 的 Meta Server 节点,会异步的从 Zookeeper 中拉取 Log,并将通过反序列化,将 Log 转换成对元数据的操作,再将这些修改操作提交到本地的 LevelDB 中。这样就能保证每一个 Meta Server 都可以保存一个完整的元数据。

前面提到,由于 Zookeeper 存储数据的容量受限于内存容量。为了避免 Zookeeper 消耗过多内存,我们对 Zookeeper 中的 Log 定期执行清理。只要 Log 已经被所有的 Meta Server 同步完, Zookeeper 中保存的 Log 就可以被删除了,以节省空间。通常我们在 Zookeeper 上只保存 1GB 的 Log,已经足够支撑元数据服务。

Failover 的逻辑也非常简单。如果 Leader 节点发生故障,其他还存活的的 Meta Server 通过 Zookeeper 再重新进行一次选主,选出一个新的 Meta Leader。这个新的 Leader 将首先从 Zookeeper 上同步所有还未消耗的日志,并在提交到本地的 LevelDB 中,然后就可以对外提供元数据服务了。
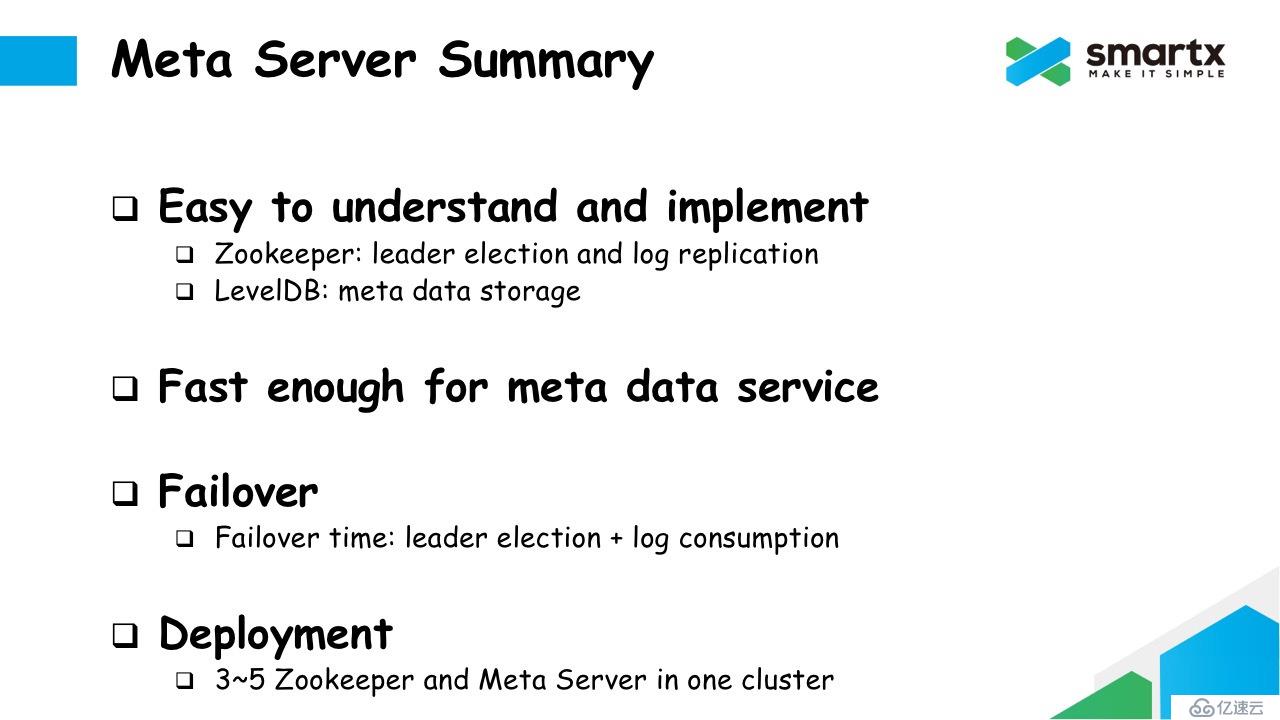
现在我们总结一下 ZBS 中元数据服务实现的特点。
首先,这个原理非常容易理解,而且实现起来非常简单。由 Zookeeper 负责选主和 Log Replication,由 LevelDB 负责本地元数据的存储。背后的逻辑就是尽可能的将逻辑进行拆分,并尽可能的复用已有项目的实现。
其次,速度足够快。Zookeeper 和 LevelDB 本身的性能都不错,而且在生产中,我们将 Zookeeper 和 LevelDB 运行在 SSD 上。在实际测试中,对于单次元数据的修改都是在毫秒级完成。在并发的场景下,我们可以对元数据修改的日志做 Batch,以提高并发能力。
此外,这种方式支持 Failover,而且 Failover 的速度也非常快。Failover 的时间就是选主再加上 Log 同步的时间,可以做到秒级恢复元数据服务。
最后说一下部署。在线上部署的时候,我们通常部署 3 个或 5 个 Zookeeper 服务的实例以及至少 3 个 Meta Server 服务的实例,以满足元数据可靠性的要求。元数据服务对资源消耗都非常小,可以做到和其他服务混合部署。

以上是一些基本的原理,我们再来看一下 ZBS 内部的对于元数据服务的具体实现。
我们将上述的 Log Replication 逻辑封装在了一个 Log Replication Engine 中,其中包含了选主、向 Zookeeper 提交 Log、向 LevelDB 同步数据等操作,进一步简化开发复杂度。
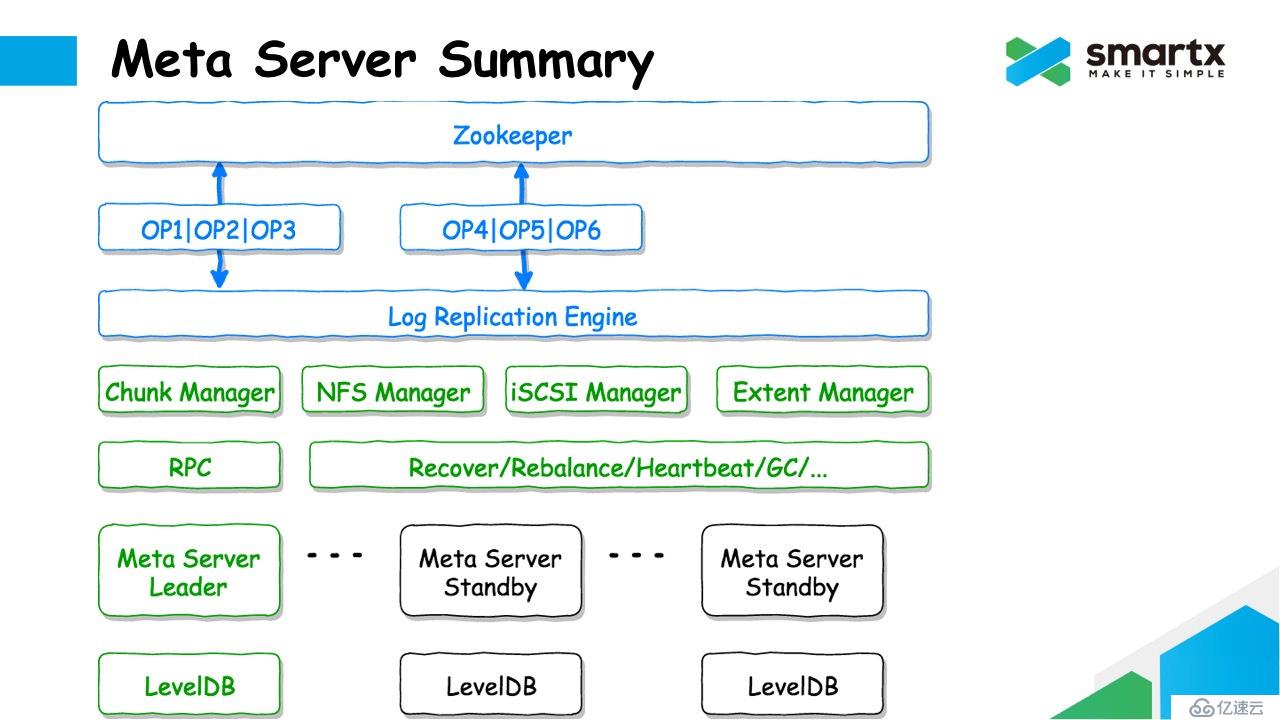
在 Log Replication Engine 的基础之上,我们实现了整个 Meta Sever 的逻辑,其中包含了 Chunk Manager,NFS Manger,iSCSI Manager,Extent Manager 等等很多管理模块,他们都可以通过 Log Replication Engine,管理特定部分的元数据。RPC 模块是 Meta Server 对外暴露的接口,负责接收外部的命令,并转发给对应的 Manager。例如创建/删除文件,创建/删除虚拟卷等等。此外,Meta Server 中还包含了一个非常复杂的调度器模块,里面包含了各种复杂的分配策略,恢复策略,负载均衡策略,以及心跳,垃圾回收等功能。
以上就是关于 SmartX 超融合系统中 SMTX 分布式块存储元数据服务部分的介绍。
了解更多信息可访问 SmartX 官网:https://www.smartx.com
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





