在2018年的Garnter技术成熟度曲线中,容器存储出现在了技术触发期,已经开始进入大众的视野。我相信,在未来的两年内,容器存储会随着Kubernetes的进一步成熟和商业化,其地位会越来越重要。如何在五花八门的存储产品中,选择适合自己的一款,将会是IT大佬们必须要面对的问题。本次分享将会从使用场景角度分析,如何评估容器存储方案。
从用户角度看,存储就是一块盘或者一个目录,用户不关心盘或者目录如何实现,用户要求非常“简单”,就是稳定,性能好。为了能够提供稳定可靠的存储产品,各个厂家推出了各种各样的存储技术和概念。为了能够让大家有一个整体认识,本文先介绍存储中的这些概念。
从存储介质角度,存储介质分为机械硬盘和固态硬盘(SSD)。机械硬盘泛指采用磁头寻址的磁盘设备,包括SATA硬盘和SAS硬盘。由于采用磁头寻址,机械硬盘性能一般,随机IOPS一般在200左右,顺序带宽在150MB/s左右。固态硬盘是指采用Flash/DRAM芯片+控制器组成的设备,根据协议的不同,又分为SATA SSD,SAS SSD,PCIe SSD和NVMe SSD。
从产品定义角度,存储分为本地存储(DAS),网络存储(NAS),存储局域网(SAN)和软件定义存储(SDS)四大类。
DAS就是本地盘,直接插到服务器上
NAS是指提供NFS协议的NAS设备,通常采用磁盘阵列+协议网关的方式
SAN跟NAS类似,提供SCSI/iSCSI协议,后端是磁盘阵列
SDS是一种泛指,包括分布式NAS(并行文件系统),ServerSAN等
从应用场景角度,存储分为文件存储(Posix/MPI),块存储(iSCSI/Qemu)和对象存储(S3/Swift)三大类。
Kubernetes是如何给存储定义和分类呢?Kubernetes中跟存储相关的概念有PersistentVolume (PV)和PersistentVolumeClaim(PVC),PV又分为静态PV和动态PV。静态PV方式如下:
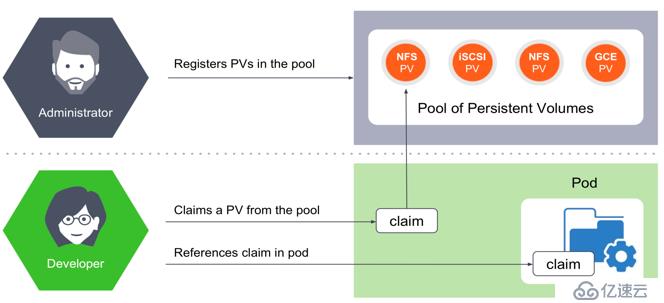
动态PV需要引入StorageClass的概念,使用方式如下:
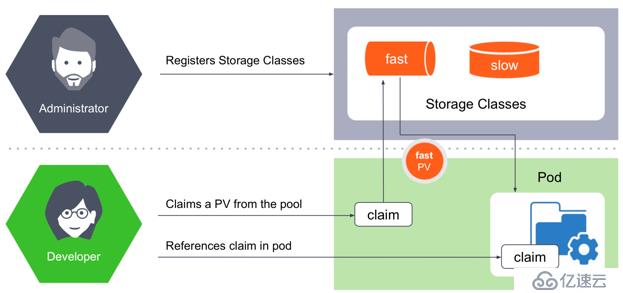
社区列举出PersistentVolume的in-tree Plugin,如下图所示。从图中可以看到,Kubernetes通过访问模式给存储分为三大类,RWO/ROX/RWX。这种分类将原有的存储概念混淆,其中包含存储协议,存储开源产品,存储商业产品,公有云存储产品等等。
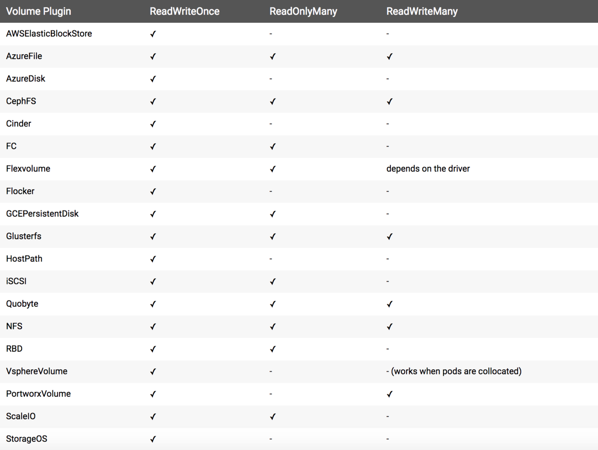
如何将Kubernetes中的分类和熟知的存储概念对应起来呢?本文选择将其和应用场景进行类比。
块存储通常只支持RWO,比如AWSElasticBlockStore,AzureDisk,有些产品能做到支持ROX,比如GCEPersistentDisk,RBD,ScaleIO等
文件存储(分布式文件系统)支持RWO/ROX/RWX三种模式,比如CephFS,GlusterFS和AzureFile
对象存储不需要PV/PVC来做资源抽象,应用可以直接访问和使用
这里不得不吐槽Kubernetes社区前期对存储层的抽象,一个字——乱,把开源项目和商业项目都纳入进来。现在社区已经意识到问题并设计了统一的存储接口层——Flexvolume/CSI。目前来看,CSI将会是Kubernetes的主流,做了完整的存储抽象层。
介绍完存储概念之后,选择哪种存储仍然悬而未决。这个时候,请问自己一个问题,业务是什么类型?选择合适的存储,一定要清楚自己的业务对存储的需求。本文整理了使用容器存储的场景及其特点。
配置
无论集群配置信息还是应用配置信息,其特点是并发访问,也就是前边提到的ROX/RWX,在不同集群或者不同节点,都能够访问同样的配置文件,分布式文件存储是最优选择。
日志
在容器场景中,日志是很重要的一部分内容,其特点是高吞吐,有可能会产生大量小文件。如果有日志分析场景,还会有大量并发读操作。分布式文件存储是最优选择。
应用(数据库/消息队列/大数据)
Kafka,MySQL,Cassandra,PostgreSQL,ElasticSearch,HDFS等应用,本身具备了存储数据的能力,对底层存储的要求就是高IOPS,低延迟。底层存储最好有数据冗余机制,上层应用就可以避免复杂的故障和恢复处理。以HDFS为例,当某个datanode节点掉线后,原有逻辑中,会选择启动新的datanode,触发恢复逻辑,完成数据副本补全,这段时间会比较长,而且对业务影响也比较大。如果底层存储有副本机制,HDFS集群就可以设置为单副本,datanode节点掉线后,启动新的datanode,挂载原有的pv,集群恢复正常,对业务的影响缩短为秒级。高性能分布式文件存储和高性能分布式块存储是最优选择。
备份
应用数据的备份或者数据库的备份,其特点是高吞吐,数据量大,低成本。文件存储和对象存储最优。
综合应用场景,高性能文件存储是最优选择。
市面上的存储产品种类繁多,但是对于容器场景,主要集中在4种方案:分布式文件存储,分布式块存储,Local-Disk和传统NAS。
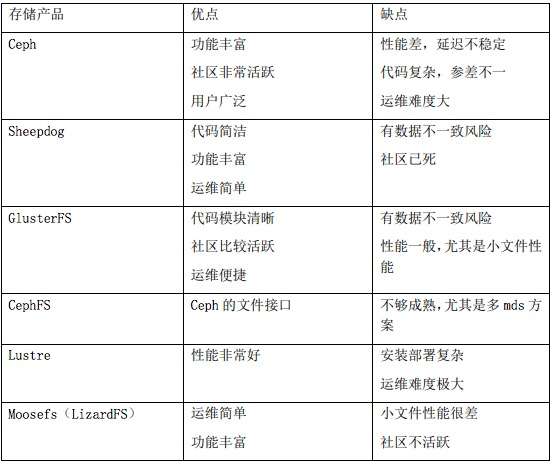
分布式块存储包括开源社区的Ceph,Sheepdog,商业产品中EMC的Scale IO,Vmware的vSAN等。分布式块存储不适合容器场景,关键问题是缺失RWX的特性。
分布式文件存储包括开源社区的Glusterfs,Cephfs,Lustre,Moosefs,Lizardfs,商业产品中EMC的isilon,IBM的GPFS等。分布式文件存储适合容器场景,但是性能问题比较突出,主要集中在GlusterFS,CephFS,MooseFS/LizardFS。
这里简单对比下开源项目的优缺点,仅供参考。
Local-Disk方案有明显的缺点,尤其是针对数据库,大数据类的应用。节点故障后,数据的恢复时间长,对业务影响范围广。
传统NAS也是一种文件存储,但是协议网关(机头)是性能瓶颈,传统NAS已经跟不上时代发展的潮流。
存储的核心需求是稳定,可靠,可用。无论是开源的存储项目还是商业的存储产品,评估方法具有普适性,本文会介绍常见的评估项和评估方法。
数据可靠性
数据可靠性是指数据不丢失的概率。通常情况下,存储产品会给出几个9的数据可靠性,或者给出最多允许故障盘/节点个数。评估方式就是暴力拔盘,比如说存储提供3副本策略,拔任意2块盘,只要数据不损坏,说明可靠性没问题。存储采用不同的数据冗余策略,提供的可靠性是不一样的。
数据可用性
数据可用性和数据可靠性很容易被混淆,可用性指的是数据是否在线。比如存储集群断电,这段时间数据是不在线,但是数据没有丢失,集群恢复正常后,数据可以正常访问。评估可用性的主要方式是拔服务器电源,再有查看存储的部署组件是否有单点故障的可能。
数据一致性
数据一致性是最难评估的一项,因为大部分场景用户不知道程序写了哪些数据,写到了哪里。该如何评估数据一致性呢?普通的测试工具可以采用fio开启crc校验选项,最好的测试工具就是数据库。如果发生了数据不一致的情况,数据库要么起不来,要么表数据不对。具体的测试用例还要细细斟酌。
存储性能
存储的性能测试很有讲究,块存储和文件存储的侧重点也不一样。
块存储
fio/iozone是两个典型的测试工具,重点测试IOPS,延迟和带宽。以fio为例,测试命令如下:
fio -filename=/dev/sdc -iodepth=${iodepth} -direct=1 -bs=${bs} -size=100% --rw=${iotype} -thread -time_based -runtime=600 -ioengine=${ioengine} -group_reporting -name=fioTest关注几个主要参数:iodepth,bs,rw和ioengine。
测试IOPS,iodepth=32/64/128,bs=4k/8k,rw=randread/randwrite,ioengine=libaio
测试延迟,iodepth=1,bs=4k/8k,rw=randread/randwrite,ioengine=sync
测试带宽,iodepth=32/64/128,bs=512k/1m,rw=read/write,ioengine=libaio
文件存储
fio/vdbench/mdtest是测试文件系统常用的工具,fio/vdbench用来评估IOPS,延迟和带宽,mdtest评估文件系统元数据性能。以fio和mdtest为例,测试命令如下:
fio -filename=/mnt/yrfs/fio.test -iodepth=1 -direct=1 -bs=${bs} -size=500G --rw=${iotype} -numjobs=${numjobs} -time_based -runtime=600 -ioengine=sync -group_reporting -name=fioTest与块存储的测试参数有一个很大区别,就是ioengine都是用的sync,用numjobs替换iodepth。
测试IOPS,bs=4k/8k,rw=randread/randwrite,numjobs=32/64
测试延迟,bs=4k/8k,rw=randread/randwrite,numjobs=1
测试带宽,bs=512k/1m,rw=read/write,numjobs=32/64
mdtest是专门针对文件系统元数据性能的测试工具,主要测试指标是creation和stat,需要采用mpirun并发测试:
mpirun --allow-run-as-root -mca btl_openib_allow_ib 1 -host yanrong-node0:${slots},yanrong-node1:${slots},yanrong-node2:${slots} -np ${num_procs} mdtest -C -T -d /mnt/yrfs/mdtest -i 1 -I ${files_per_dir} -z 2 -b 8 -L -F -r -u存储性能测试不仅仅测试集群正常场景下的指标,还要包含其他场景:
存储容量在70%以上或者文件数量上亿的性能指标
节点/磁盘故障后的性能指标
扩容过程时的性能指标
容器存储功能
除了存储的核心功能(高可靠/高可用/高性能),对于容器存储,还需要几个额外的功能保证生产环境的稳定可用。
Flexvolume/CSI接口的支持,动态/静态PV的支持
存储配额。对于Kubernetes的管理员来说,存储的配额是必须的,否则存储的使用空间会处于不可控状态
服务质量(QoS)。如果没有QoS,存储管理员只能期望存储提供其他监控指标,以保证在集群超负荷时,找出罪魁祸首
Kubernetes持久化存储方案的重点在存储和容器支持上。因此首要考虑存储的核心功能和容器的场景支持。综合本文所述,将选择项按优先级列举:
存储的三大核心,高可靠,高可用和高性能
业务场景,选择分布式文件存储
扩展性,存储能横向扩展,应对业务增长需求
可运维性,存储的运维难度不亚于存储的开发,选择运维便捷存储产品
成本
Q:你好,我们公司采用GlusterFS存储,挂载三块盘,现在遇到高并发写小文件(4KB)吞吐量上不去(5MB/S),请问有什么比较好的监控工具或方法么?谢谢!
A:GlusterFS本身对小文件就很不友好,GlusterFS是针对备份场景设计的,不建议用在小文件场景,如果可以的话,要么程序做优化进行小文件合并,要么选用高性能的分布式文件存储,建议看看Lustre或者YRCloudFile。
Q:我们用的是Ceph分布式存储,目前有一个场景是客户视频存储,而对于持续的写入小文件存在丢帧的现象,经过我们系统级别和底层文件系统调优,加上Ceph参数的设置,勉强性能得改善,但是数据量上来性能会如何也不得而知道了(经过客户裸盘测试,前面用软RAID方式性能还是可以)请问在这方面你有什么建议么?谢谢!我们客户是在特殊的场景下,属于特定机型,而且是5400的sata盘!rbd块存储!还有一个现象就是磁盘利用率不均,这也是影响性能的一个人原因,即便我们在调pg数,也会有这个问题。在额外请教一个问题,bcache可以用内存做缓存么?FlushCache相比,这两个哪个会更好一点?
A:您用的是CephFS还是rbdc因为Ceph在性能上缺失做的还不够,有很多队列,导致延迟很不稳定,这个时候,只能忍了,不过还是建议用Bcache做一层缓存,可以有效缓解性能问题。Crush算法虽然比一致性hash要好很多,但是因为没有元数据,还是很难控制磁盘热点问题。FlushCache已经没有人维护了,Bcache还有团队在维护,所以如果自己没有能力,就选用Bcache。
Q:我看您推荐分布式文件存储,文件系统能满足数据库应用的需求吗?块存储会不会好一些?
A:首先,我推荐的是高性能分布式文件系统。数据库一般对延迟都比较敏感,普通的万兆网络+HDD肯定不行,需要采用SSD,一般能将延迟稳定在毫秒以内,通常能够满足要求。如果对延迟有特别要求,可以采用NVMe + RoCE的方案,即使在大压力下,延迟也能稳定在300微秒以内。
Q:请问为什么说块存储不支持RWX?RWX就是指多个节点同时挂载同一块块设备并同时读写吗?很多FC存储都可以做到。
A:传统的SAN要支持RWX,需要ALUA机制,而且这是块级别的多读写,如果要再加上文件系统,是没办法做到的,这需要分布式文件系统来做文件元数据信息同步。
Q:传统SAN支持对同一数据块的并行读写,很多AA阵列都不是用ALUA的,而是多条路径同时有IO,当然要用到多路径软件。相反用ALUA的不是AA阵列。
A:AA阵列解决的是高可用问题,对同一个lun的并发读写,需要trunk级的锁去保证数据一致性,性能不好。
Q:很多传统商业存储,包括块存储,也都做了CSI相关的插件,是不是如果在容器里跑一些性能要求高的业务,这些商业的块存储比文件存储合适?
A:生产环境中,我强烈建议选用商业存储。至于块存储还是文件存储,要看您的业务场景。首选是商业的文件存储。
Q:请问现在的Kubernetes环境下,海量小文件RWX场景,有什么相对比较好的开源分布式存储解决方案么?
A:开源的分布式文件存储项目中,没有能解决海量小文件的,我在文中已经将主流开源文件系统都分析了一遍,在设计之初,都是针对备份场景或者HPC领域。
Q:请问,为什么说Ceph性能不好,有依据吗?
A:直接用数据说话,我们用NVMe + Ceph + Bluestore测试出来的,延迟在毫秒级以上,而且很不稳定,我们用YRCloudFile + NVMe + RoCE,延迟能50微秒左右,差了几十倍。
Q:Lustre没接触过,性能好吗,和Ceph有对比过吗?
A:网上有很多Lustre的性能指标,在同样的配置下,性能绝对要比Ceph好,不过Lustre全部都是内核态的,容器场景没办法用,而且按照部署以及运维难度非常大。Lustre在超算用的比较广泛。
Q:Lustre只能靠本地磁盘阵列来保证数据冗余么?
A:Lustre本身不提供冗余机制,都是靠本地阵列的,不过EC好像已经在开发计划中了。
Q:(对于小公司)如果不选用商业存储,那么推荐哪款开源实现作为生产存储(可靠,高性能)。我们之前试了NFS发现速度不稳定?
A:国内还是有很多创业公司,也不贵的。存储不像其他项目,存储经不起折腾,一定要用稳定可靠的,Ceph/GlusterFS做了这么久,大家在采购的时候,还是会依托于某家商业公司来做,自己生产环境用开源项目,风险太大了。
以上内容根据2019年1月10日晚微信群分享内容整理。分享人张文涛,北京焱融科技存储架构师,负责容器存储产品的架构设计和研发。
关于焱融云
焱融云是一家以软件定义存储技术为核心竞争力的高新技术企业,在分布式存储等关键技术上拥有自主知识产权,是高性能分布式存储解决方案的行业领导者。针对各行业业务特性,打造个性化行业解决方案,提供一站式的产品与服务。焱融云系列产品已服务于金融、政府、制造业、互联网等行业的众多客户。了解更多焱融科技信息,请访问官网http://www.yanrongyun.com。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





