ESXIдё»жңәзҙ«еұҸеҲҶжһҗж–№жі•жҳҜд»Җд№Ҳ
иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶д»Ӣз»ҚESXIдё»жңәзҙ«еұҸеҲҶжһҗж–№жі•жҳҜд»Җд№ҲпјҢеҶ…е®№йқһеёёиҜҰз»ҶпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们еҸҜд»ҘеҸӮиҖғеҖҹйүҙпјҢеёҢжңӣеҜ№еӨ§е®¶иғҪжңүжүҖеё®еҠ©гҖӮ
дёҖпјҡжҰӮиҝ°
зӣёдҝЎVMwareзҡ„е·ҘзЁӢеёҲеҜ№зҙ«еұҸдёҚдјҡйҷҢз”ҹпјҢзҙ«еұҸжӯ»жңәпјҲPSoDsпјҢ Purple Screen of DeathпјүжҳҜеҸ‘з”ҹеңЁESXIдёҠзҡ„дёҖз§Қж•…йҡңпјҢзұ»дјјдәҺеҫ®иҪҜWindowsж“ҚдҪңзі»з»ҹзҡ„и“қеұҸгҖӮзҙ«еұҸжғ…еҶөйҖҡеёёжҳҜз”ұдәҺ硬件е’ҢиҪҜ件故йҡңеҜјиҮҙзҡ„пјҢжҜ”еҰӮиҪҜ件bugгҖҒCPUгҖҒеҶ…еӯҳжі„йңІзӯүеҺҹеӣ гҖӮеҪ“еҸ‘з”ҹзҙ«еұҸж•…йҡңж—¶ж•ҙдёӘESXIдё»жңәдјҡзӘҒ然еҙ©жәғпјҢеҪ“зҙ«еұҸж•…йҡңеҸ‘з”ҹеҗҺз®ЎзҗҶе‘ҳиғҪеҒҡзҡ„еҸӘжңүи®°еҪ•зҙ«еұҸдҝЎжҒҜд»ҘеҸҠйҮҚеҗҜдё»жңәпјҢд№ҹе°ұжҳҜиҜҙESXIдё»жңәдёҠйқўзҡ„иҷҡжӢҹжңәе°ҶдјҡеҸ—еҲ°еҪұе“ҚпјӣеҰӮжһңжңүHAжңәеҲ¶зҡ„иҜқеҲҷдјҡиҝҒ移еҲ°е…¶д»–еҸҜз”Ёзҡ„ESXIдё»жңәгҖӮ
еҪ“еҸ‘зҺ°ESXIдё»жңәеҮәзҺ°зҙ«еұҸзҺ°зҠ¶ж—¶з¬¬дёҖж—¶й—ҙеә”иҜҘе°Ҷзҙ«еұҸзҡ„дҝЎжҒҜи®°еҪ•дёӢжқҘпјҢз®ҖеҚ•зҡ„еҠһжі•е°ұжҳҜе°ҶеҪ“еүҚзҡ„еұҸ幕дҝЎжҒҜжҲӘеӣҫжҲ–иҖ…жӢҚз…§дёӢжқҘпјҢеӣ дёәйҮҢйқўеҢ…жӢ¬еҫҲеӨҡйҮҚиҰҒзҡ„дҝЎжҒҜпјӣеңЁйҮҢйқўеҸҜд»ҘжҳҫзӨәе’ҢдәҶи§ЈеҲ°ESXIзүҲжң¬е’ҢbuildеҸ·гҖҒејӮеёёзұ»еһӢгҖҒеҜ„еӯҳеҷЁиҪ¬еӮЁпјҲregister dumpпјүгҖҒеҙ©жәғж—¶жҜҸдёӘCPUжӯЈеңЁи·‘д»Җд№ҲгҖҒеӣһжәҜиҝҪиёӘпјҲback-traceпјүгҖҒжңҚеҠЎеҷЁиҝҗиЎҢж—¶й—ҙгҖҒй”ҷиҜҜж—Ҙеҝ—гҖҒеҶ…еӯҳ硬件дҝЎжҒҜзӯүгҖӮеҪ“е°ҶESXIдё»жңәйҮҚеҗҜеҗҺпјҢиҝҳеҸҜд»ҘйҖҡиҝҮESXIдё»жңәзҡ„/rootжҲ–иҖ…//var/core/иҺ·еҸ–vmkernel-zdumpж–Ү件пјҢеҪ“еҸ‘з”ҹзҙ«еұҸеҗҺдјҡжңүдёҖдёӘд»Ҙvmkernel-zdumpејҖеӨҙпјҲе‘ҪеҗҚпјүзҡ„ж–Ү件пјҢеҸҜд»Ҙе°ҶиҜҘж–Ү件жҸҗдәӨз»ҷVMwareзҡ„жҠҖжңҜж”ҜжҢҒеё®еҠ©иҝӣиЎҢж•…йҡңеҲҶжһҗпјӣеҗҢж—¶д№ҹеҸҜд»ҘйўқеҖҹеҠ©йҖҡиҝҮvmkdumpе·Ҙе…·жҸҗеҸ– VMkernelж—Ҙеҝ—дҝЎжҒҜгҖҒеҜ»жүҫдёҺPSoDsжңүе…ізҡ„зәҝзҙўпјҢд»ҺиҖҢеҲӨж–ӯPSoDsеҸ‘з”ҹзҡ„еҺҹеӣ гҖӮе…ідәҺжҸҗеҸ–е’ҢиҜҶеҲ«vmkernel-zdumpжҹҘйҳ…е®ҳж–№KBпјҡhttps://kb.vmware.com/s/article/1006796?lang=zh_CN
дәҢпјҡзҗҶи§Јзҙ«еұҸдҝЎжҒҜ
йҖҡиҝҮзҙ«еұҸеҗҺеұҸ幕дҝЎжҒҜйғҪеҸҜд»ҘиҺ·еҸ–еҲ°еҫҲеӨҡе…ій”®дҝЎжҒҜпјҢз®ЎзҗҶе‘ҳеҸҜд»Ҙеҝ«йҖҹзҡ„еҖҹеҠ©иҝҷдәӣдҝЎжҒҜиҝӣиЎҢж•…йҡңе®ҡдҪҚе’ҢжҺ’жҹҘгҖӮй”ҷиҜҜдјҡжҳҫзӨәеңЁзҙ«иүІиҜҠж–ӯеұҸ幕дёӯгҖӮзҙ«иүІиҜҠж–ӯеұҸ幕еӨ§иҮҙеҰӮдёӢжүҖзӨәпјҡ
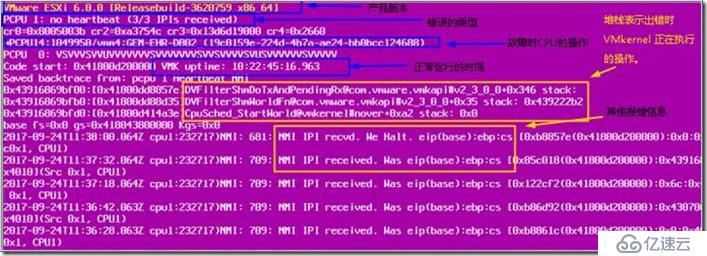
йҖҡиҝҮд»ҘдёҠеҶ…е®№еҸҜд»ҘжҹҘзңӢеҲ°еҮ дёӘе…ій”®дҝЎжҒҜ
В· дә§е“Ғе’ҢеҶ…йғЁзүҲжң¬пјҡ
VMware ESX Server [Releasebuild-3620759
зҙ«иүІиҜҠж–ӯеұҸ幕дёӯзҡ„жӯӨйғЁеҲҶиЎЁзӨәеҮәй”ҷзҡ„дә§е“Ғе’ҢеҶ…йғЁзүҲжң¬гҖӮеңЁжң¬зӨәдҫӢдёӯпјҢдә§е“ҒжҳҜESXIпјҢзүҲжң¬еҸ·жҳҜ3620759пјҢд№ҹе°ұжҳҜESXI 6.0 U2
В· й”ҷиҜҜж¶ҲжҒҜпјҡ
PCPU 1 locked up.Failed to ack TLB invalidate
зҙ«иүІиҜҠж–ӯеұҸ幕зҡ„жӯӨйғЁеҲҶиЎЁзӨәжҠҘе‘Ҡзҡ„й”ҷиҜҜж¶ҲжҒҜгҖӮеҸӘиғҪжҠҘе‘Ҡжңүйҷҗж•°йҮҸзҡ„й”ҷиҜҜж¶ҲжҒҜгҖӮжң¬ж–ҮзЁҚеҗҺдјҡи®Ёи®әиҝҷдәӣй”ҷиҜҜж¶ҲжҒҜгҖӮ
В· CPU еҜ„еӯҳеҷЁпјҡ
frame=0x3a37d98 ip=0x625e94 cr2=0x0 cr3=0x40c66000 cr4=0x16c
es=0xffffffff ds=0xffffffff fs=0xffffffff gs=0xffffffff
eax=0xffffffff ebx=0xffffffff ecx=0xffffffff edx=0xffffffff
ebp=0x3a37ef4 esi=0xffffffff edi=0xffffffff err=-1 eflags=0xffffffff
еҮәй”ҷж—¶пјҢиҝҷдәӣеҖјеӯҳеӮЁеңЁзү©зҗҶ CPU еҜ„еӯҳеҷЁдёӯгҖӮиҝҷдәӣеҜ„еӯҳеҷЁдёӯзҡ„дҝЎжҒҜеҚғе·®дёҮеҲ«пјҢе…·дҪ“еҸ–еҶідәҺеҮәзҺ°зҡ„ VMkernel й”ҷиҜҜ
В· зү©зҗҶ CPUпјҡ
*0:1037/helper1-4 1:1107/vmm0:Fagi 2:1121/vmware-vm 3:1122/mks:Franc
зҙ«иүІиҜҠж–ӯеұҸ幕зҡ„жӯӨйғЁеҲҶиЎЁзӨә VMkernel еҮәй”ҷжңҹй—ҙиҝҗиЎҢжҢҮд»Өзҡ„зү©зҗҶ CPUгҖӮеңЁжң¬зӨәдҫӢдёӯпјҢ0 ж—Ғиҫ№зҡ„ * иЎЁзӨәеҸ‘з”ҹж•…йҡңж—¶зү©зҗҶ CPU 0 жӯЈеңЁиҝҗиЎҢж“ҚдҪңгҖӮж–°зүҲжң¬ ESX дёҚеҶҚдҪҝз”Ё *пјҢиҖҢжҳҜдҪҝз”ЁеүҚзјҖеӯ—жҜҚ CPUгҖӮдҫӢеҰӮпјҢеҰӮжһңж–°зүҲжң¬ VMware ESX еҗҢж ·еҮәзҺ°дёҠиҝ°й”ҷиҜҜпјҢеҲҷеҗҢдёҖиЎҢдјҡжҳҫзӨәдёәпјҡ
CPU0:1037/helper1-4 cpu1:1107/vmm0:Fagi cpu2:1121/vmware-vm cpu3:1122/mks:FrancгҖӮ
зҙ«иүІиҜҠж–ӯеұҸ幕зҡ„жӯӨйғЁеҲҶиҝҳжҸҸиҝ°дәҶеҮәй”ҷж—¶ CPU дёҠиҝҗиЎҢзҡ„зҺҜеўғпјҲиҝӣзЁӢпјүгҖӮеңЁдёҠиҝ°зӨәдҫӢдёӯпјҢз”ЁжҲ·зҺҜеўғжӯЈеңЁиҝҗиЎҢ helper1-4гҖӮ
жіЁж„ҸпјҡиҝӣзЁӢеҗҚз§°еҸҜиғҪе·ІжҲӘж–ӯгҖӮ
В· е Ҷж Ҳи·ҹиёӘпјҡ
0x3a37ef4:[0x625e94]Panic+0x17 stack: 0x833ab4, 0x3a37f10, 0x3a37f48
0x3a37f04:[0x625e94]Panic+0x17 stack: 0x833ab4, 0x1, 0x14a03a0
0x3a37f48:[0x64bfa4]TLBDoInvalidate+0x38f stack: 0x3a37f54, 0x40, 0x2
0x3a37f70:[0x66da4d]XMapForceFlush+0x64 stack: 0x0, 0x4d3a, 0x0
0x3a37fac:[0x652b8b]helpFunc+0x2d2 stack: 0x1, 0x14a4580, 0x0
0x3a37ffc:[0x750902]CpuSched_StartWorld+0x109 stack: 0x0, 0x0, 0x0
0x3a38000:[0x0]blk_dev+0xfd76461f stack: 0x0, 0x0, 0x0
е Ҷж ҲиЎЁзӨәеҮәй”ҷж—¶ VMkernel жӯЈеңЁжү§иЎҢзҡ„ж“ҚдҪңгҖӮеңЁжң¬зӨәдҫӢдёӯпјҢVMkernel жӯЈеңЁе°қиҜ•жё…йҷӨеҶ…еӯҳйЎөиЎЁ (TLB)гҖӮжӯӨдҝЎжҒҜжҳҜдёҖдёӘйҮҚиҰҒе·Ҙе…·пјҢжңүеҠ©дәҺйҖҡиҝҮиҜ„дј°еҮәй”ҷж—¶еҶ…ж ёжүҖжү§иЎҢзҡ„ж“ҚдҪңжқҘиҜҠж–ӯзҙ«иүІеұҸ幕й”ҷиҜҜгҖӮ
В· жӯЈеёёиҝҗиЎҢж—¶й—ҙпјҡ
VMK uptime: 7:05:43:45.014 TSC: 1751259712918392
жӯӨйғЁеҲҶиЎЁзӨәиҮӘдёҠж¬ЎеҗҜеҠЁд»ҘжқҘжңҚеҠЎеҷЁиҝҗиЎҢзҡ„ж—¶й—ҙгҖӮеңЁжң¬зӨәдҫӢдёӯпјҢESXI дё»жңәе·ІиҝҗиЎҢдәҶ 7 еӨ© 5 е°Ҹж—¶ 43 еҲҶ 45.014 з§’гҖӮTSC еҖјжҳҜжңҚеҠЎеҷЁеҗҜеҠЁд№ӢеҗҺз»ҸиҝҮзҡ„ CPU ж—¶й’ҹйў‘зҺҮеҫӘзҺҜж¬Ўж•°гҖӮ
В· ж ёеҝғиҪ¬еӮЁпјҡ
Starting coredump to disk Starting coredump to disk Dumping using slot 1 of 1...using slot 1 of 1... log
зҙ«иүІиҜҠж–ӯеұҸ幕зҡ„жӯӨйғЁеҲҶиЎЁзӨәжӯЈеӨҚеҲ¶еҲ° vmkcore еҲҶеҢәзҡ„ VMkernel еҶ…еӯҳеҶ…е®№гҖӮ
дёүпјҡйҖҡиҝҮй”ҷиҜҜдҝЎжҒҜе®ҡдҪҚж•…йҡң
дёҠйқўд»Ӣз»ҚдәҶеҰӮдҪ•жҹҘзңӢе’ҢзҗҶи§Јзҙ«еұҸзҡ„еұҸ幕дҝЎжҒҜпјҢе…¶дёӯжҜ”иҫғе…ій”®зҡ„е°ұжҳҜе…ідәҺй”ҷиҜҜдҝЎжҒҜзҡ„еӯ—ж®өпјҢжҺҘдёӢжқҘжҲ‘们еҸҜд»ҘйҖҡиҝҮзҙ«иүІеұҸ幕з”ҹжҲҗзҡ„ VMkernel й”ҷиҜҜж¶ҲжҒҜеҸҜз”ЁдәҺзЎ®е®ҡй—®йўҳеҺҹеӣ гҖӮдёҚиҝҮпјҢдә§з”ҹзҡ„й”ҷиҜҜж¶ҲжҒҜж•°жҳҜжңүйҷҗзҡ„гҖӮд»ҘдёӢжҳҜе·ІзҹҘзҡ„ VMkernel й”ҷиҜҜж¶ҲжҒҜеҲ—иЎЁгҖӮ
l зұ»еһӢпјҡжҺ§еҲ¶еҸ°иӯҰе‘Ҡ
й”ҷиҜҜзӨәдҫӢпјҡCOS Error: Oops
жҸҸиҝ°пјҡESX дё»жңәеҮәзҺ°ж•…йҡң并еңЁеҮәзҺ°жңҚеҠЎжҺ§еҲ¶еҸ°иӯҰе‘Ҡж—¶жҳҫзӨәзҙ«иүІеұҸ幕гҖӮдёҺеӨ§еӨҡж•°зҙ«иүІеұҸ幕й”ҷиҜҜдёҚеҗҢзҡ„жҳҜпјҢиҜҘй”ҷиҜҜ并йқһз”ұ VMkernel и§ҰеҸ‘гҖӮзӣёеҸҚпјҢе®ғз”ұжңҚеҠЎжҺ§еҲ¶еҸ°и§ҰеҸ‘пјҢ并еҸ‘з”ҹеңЁ Linux зә§еҲ«гҖӮиҝҷдәӣзҙ«иүІеұҸ幕й”ҷиҜҜеҢ…еҗ«жқҘиҮӘ Linux еҶ…ж ёзҡ„е…¶д»–дҝЎжҒҜгҖӮжңүе…іжҺ§еҲ¶еҸ°иӯҰе‘Ҡзҡ„иҜҰз»ҶдҝЎжҒҜпјҢиҜ·еҸӮи§Ғ Understanding an "Oops" purple diagnostic screen (1006802)гҖӮ
l зұ»еһӢпјҡжЈҖжөӢдҝЎеҸ·дёўеӨұ
й”ҷиҜҜзӨәдҫӢпјҡLost Heartbeat
жҸҸиҝ°пјҡESX VMkernel е’ҢжңҚеҠЎжҺ§еҲ¶еҸ° Linux еҶ…ж ёеҗҢж—¶еңЁ ESX дёҠиҝҗиЎҢгҖӮжңҚеҠЎжҺ§еҲ¶еҸ° Linux еҶ…ж ёдјҡиҝҗиЎҢдёҖдёӘз§°дёә vmnixhbd зҡ„иҝӣзЁӢпјҢеҸӘиҰҒ VMkernel иғҪеӨҹеҲҶй…Қе’ҢйҮҠж”ҫеҶ…еӯҳйЎөпјҢиҜҘиҝӣзЁӢдҫҝдјҡеҗ‘ VMkernel еҸ‘йҖҒжЈҖжөӢдҝЎеҸ·гҖӮеҰӮжһңеңЁ 30 еҲҶй’ҹи¶…ж—¶ж—¶й—ҙд№ӢеүҚжңӘ收еҲ°жЈҖжөӢдҝЎеҸ·пјҢVMkernel дјҡи§ҰеҸ‘ COS дёҘйҮҚй”ҷиҜҜд»ҘеҸҠиЎЁжҳҺжЈҖжөӢдҝЎеҸ·дёўеӨұзҡ„зҙ«иүІиҜҠж–ӯеұҸ幕гҖӮжңүе…іжЈҖжөӢдҝЎеҸ·дёўеӨұзҡ„иҜҰз»ҶдҝЎжҒҜпјҢиҜ·еҸӮи§Ғ Understanding a "Lost Heartbeat" purple diagnostic screen (1009525)гҖӮ
l зұ»еһӢпјҡж–ӯиЁҖ
й”ҷиҜҜзӨәдҫӢпјҡASSERT bora/vmkernel/main/pframe_int.h:527
жҸҸиҝ°пјҡж–ӯиЁҖй”ҷиҜҜеұһдәҺиҪҜ件й”ҷиҜҜпјҢеӣ дёәе®ғ们йғҪдёҺзЁӢеәҸжүҖеҹәдәҺзҡ„еҒҮи®ҫжқЎд»¶жңүе…ігҖӮжӯӨзұ»еһӢзҡ„зҙ«иүІеұҸ幕й”ҷиҜҜдё»иҰҒжҳҜз”ұиҪҜ件й”ҷиҜҜеҜјиҮҙзҡ„гҖӮжңүе…іж–ӯиЁҖй”ҷиҜҜж¶ҲжҒҜзҡ„иҜҰз»ҶдҝЎжҒҜпјҢиҜ·еҸӮи§Ғ Understanding ASSERT and NOT_IMPLEMENTED purple diagnostic screens (1019956)гҖӮ
l зұ»еһӢпјҡжңӘжү§иЎҢ
й”ҷиҜҜзӨәдҫӢпјҡ
NOT_IMPLEMENTED /build/mts/release/bora-84374/bora/vmkernel/main/util.c:83
жҸҸиҝ°пјҡд»Јз ҒйҒҮеҲ°и¶…еҮәи®ҫи®ЎеӨ„зҗҶиҢғеӣҙзҡ„жғ…еҪўж—¶дјҡеҮәзҺ°жңӘжү§иЎҢй”ҷиҜҜж¶ҲжҒҜгҖӮжңүе…іиҜҰз»ҶдҝЎжҒҜпјҢиҜ·еҸӮи§Ғ Understanding ASSERT and NOT_IMPLEMENTED purple diagnostic screens (1019956)гҖӮ
l зұ»еһӢпјҡиҪ¬ж•°е·Іи¶…еҮә/еҸҜиғҪеҮәзҺ°жӯ»й”Ғ
й”ҷиҜҜзӨәдҫӢпјҡSpin count exceeded (iplLock) - possible deadlock
жҸҸиҝ°пјҡзәҝзЁӢе°қиҜ•еңЁд»Јз Ғе…ій”®йғЁеҲҶжү§иЎҢж—¶пјҢVMware ESX дё»жңәеҸҜиғҪеңЁзҙ«иүІиҜҠж–ӯеұҸ幕дёҠжҠҘе‘ҠиҪ¬ж•°е·Іи¶…еҮәдё”еҸҜиғҪеҮәзҺ°жӯ»й”ҒгҖӮз”ұдәҺзәҝзЁӢжӯЈе°қиҜ•иҝӣе…Ҙе…ій”®йғЁеҲҶпјҢеӣ жӯӨпјҢе®ғйңҖиҰҒжү§иЎҢиҮӘж—Ӣй”Ғж“ҚдҪңпјҢд»Ҙдҫҝе…ҲиҪ®иҜўдә’ж–Ҙй”ҒпјҢ然еҗҺеҶҚжү§иЎҢд»Јз ҒгҖӮзәҝзЁӢеңЁжү§иЎҢиҮӘж—Ӣй”Ғж“ҚдҪңжңҹй—ҙдјҡ继з»ӯиҪ®иҜўдә’ж–Ҙй”ҒпјҢдҪҶжҳҜпјҢдә’ж–Ҙй”ҒиҪ®иҜўж¬Ўж•°еӯҳеңЁдёҖе®ҡйҷҗеҲ¶гҖӮжңүе…іиҪ¬ж•°е·Іи¶…еҮәй”ҷиҜҜзҡ„иҜҰз»ҶдҝЎжҒҜпјҢиҜ·еҸӮи§Ғ Understanding a "Spin count exceeded" purple diagnostic screen (1020105)гҖӮ
l зұ»еһӢпјҡж— жі•зЎ®и®Ө TLB жҳҜеҗҰеӨұж•Ҳ
й”ҷиҜҜзӨәдҫӢпјҡPCPU 1 locked up.Failed to ack TLB invalidate.
жҸҸиҝ°пјҡзү©зҗҶ CPU еңЁе°қиҜ•жё…йҷӨеҶ…еӯҳйЎөиЎЁж—¶еҮәзҺ°ж•…йҡңгҖӮжңүе…іиҜҰз»ҶдҝЎжҒҜпјҢиҜ·еҸӮи§Ғ Understanding a Failed to ack TLB invalidate purple diagnostic screen (1020214)гҖӮ
зҙ«иүІиҜҠж–ӯеұҸ幕иҝҳдјҡд»ҘејӮеёёзҡ„еҪўејҸеҮәзҺ°гҖӮејӮеёёеӨ„зҗҶзЁӢеәҸжҳҜдёҖз§Қи®Ўз®—жңә硬件жңәеҲ¶пјҢж—ЁеңЁеӨ„зҗҶжӯЈеёёжү§иЎҢжөҒпјҲйҷӨйӣ¶гҖҒйЎөйқўй”ҷиҜҜзӯүпјүеҸ‘з”ҹеҸҳеҠЁзҡ„жҹҗдәӣжғ…еҪўгҖӮиҜҘеӨ„зҗҶзЁӢеәҸе№¶ж— и·ҹиёӘжңәеҲ¶пјҢеӣ жӯӨжӮЁйңҖиҰҒйҖҡиҝҮж—Ҙеҝ—и®°еҪ•зЎ®е®ҡеӨ„зҗҶзЁӢеәҸжҳҜеҗҰеҮәзҺ°й—®йўҳпјҲжҲ–йҖҡиҝҮеҚ•жӯҘи°ғиҜ•пјүгҖӮд»ҘдёӢжҳҜеёёи§ҒејӮеёёеҲ—иЎЁпјҡ
l зұ»еһӢпјҡејӮеёё 13пјҲдёҖиҲ¬дҝқжҠӨй”ҷиҜҜпјү
й”ҷиҜҜзӨәдҫӢпјҡ#GP Exception(13) in world 4130:helper13-0 @ 0x41803399e303
жҸҸиҝ°пјҡеңЁд»ҘдёӢд»»дёҖжғ…еҶөдёӢйғҪдјҡеҮәзҺ°дёҖиҲ¬дҝқжҠӨй”ҷиҜҜпјҲејӮеёё 13пјүпјҡжӯЈеңЁиҜ·жұӮзҡ„йЎөйқўдёҚеұһдәҺиҜ·жұӮиҜҘйЎөзҡ„зЁӢеәҸпјҲжңӘжҳ е°„еҲ°зЁӢеәҸеҶ…еӯҳдёӯпјүпјҢжҲ–иҖ…зЁӢеәҸж— жқғеңЁйЎөйқўдёҠжү§иЎҢиҜ»еҸ–жҲ–еҶҷе…Ҙж“ҚдҪңгҖӮжңүе…іејӮеёё 13 жҲ–йЎөйқўй”ҷиҜҜзҡ„иҜҰз»ҶдҝЎжҒҜпјҢиҜ·еҸӮи§Ғ Understanding Exception 13 and Exception 14 purple diagnostic screen events (1020181)гҖӮ
l зұ»еһӢпјҡејӮеёё 14пјҲйЎөйқўй”ҷиҜҜпјү
й”ҷиҜҜзӨәдҫӢпјҡ#PF Exception type 14 in world 136:helper0-0 @ 0x4a8e6e
жҸҸиҝ°пјҡжӯЈеңЁиҜ·жұӮзҡ„йЎөйқўжңӘжҲҗеҠҹеҠ иҪҪеҲ°еҶ…еӯҳж—¶еҮәзҺ°йЎөйқўй”ҷиҜҜпјҲејӮеёё 14пјүгҖӮжңүе…іејӮеёё 14 жҲ–йЎөйқўй”ҷиҜҜзҡ„иҜҰз»ҶдҝЎжҒҜпјҢиҜ·еҸӮи§Ғ Understanding Exception 13 and Exception 14 purple diagnostic screen events (1020181)гҖӮ
l зұ»еһӢпјҡејӮеёё 18пјҲи®Ўз®—жңәжЈҖжҹҘејӮеёёпјү
й”ҷиҜҜзӨәдҫӢпјҡMachine Check Exception: Unable to continue
й”ҷиҜҜзӨәдҫӢпјҡHardware (Machine) Error
жҸҸиҝ°пјҡи®Ўз®—жңәжЈҖжҹҘејӮеёё (MCE) з”ұ硬件з”ҹжҲҗ并йҖҡиҝҮдё»жңәиҝӣиЎҢжҠҘе‘ҠгҖӮеҮәзҺ° MCE дәӢ件时пјҢиҜ·е’ЁиҜўжӮЁзҡ„硬件дҫӣеә”е•ҶгҖӮйҖҡиҝҮиҜ„дј°жҳҫзӨәзҡ„дҝЎжҒҜпјҢеҸҜд»ҘзЎ®е®ҡжҠҘе‘Ҡй”ҷиҜҜзҡ„еҚ•дёӘ组件гҖӮжңүе…і MCE зҡ„иҜҰз»ҶдҝЎжҒҜпјҢиҜ·еҸӮи§Ғ Decoding Machine Check Exception (MCE) output after a purple screen error (1005184)гҖӮ
еӣӣпјҡеҲҶжһҗеҗҢдёҖдё»жңәзҡ„еӨҡдёӘй”ҷиҜҜ
еҗҢдёҖESXIдё»жңәдёҠеҮәеҸҜиғҪзҺ°еӨҡдёӘзҙ«иүІиҜҠж–ӯеұҸ幕时пјҢеҸҜд»ҘдҪҝз”ЁеӨҡдёӘзҙ«иүІиҜҠж–ӯеұҸ幕зӨәдҫӢзЎ®е®ҡй—®йўҳдёҺ硬件иҝҳжҳҜдёҺиҪҜ件жңүе…ігҖӮдёәжӯӨпјҢиҜ·зЎ®е®ҡзҙ«иүІиҜҠж–ӯеұҸ幕зҡ„д»ҘдёӢйғЁеҲҶжҳҜеҗҰеӯҳеңЁдёҖдәӣжЁЎејҸпјҡ
l й”ҷиҜҜж¶ҲжҒҜе’Ңе Ҷж Ҳи·ҹиёӘпјҡ
еҰӮжһңеӨҡдёӘ vmkernel й”ҷиҜҜдёӯзҡ„й”ҷиҜҜж¶ҲжҒҜе’Ңе Ҷж ҲеҸҳеҢ–еҫҲеӨ§пјҢеҲҷиЎЁжҳҺеҗҢдёҖй”ҷиҜҜ并дёҚжҖ»жҳҜиҪҜ件йҖ жҲҗзҡ„гҖӮе°Ҫз®ЎдёҚжҳҜеҚҒеҲҶзЎ®еҮҝпјҢдҪҶиҝҷеҫҲеҸҜиғҪж„Ҹе‘ізқҖ硬件问йўҳгҖӮ
еҰӮжһңеӨҡдёӘ vmkernel дёӯзҡ„й”ҷиҜҜж¶ҲжҒҜе’Ңе Ҷж Ҳе§Ӣз»ҲзӣёеҗҢпјҢеҲҷиЎЁжҳҺеҗҢдёҖй”ҷиҜҜйғҪжҳҜз”ұиҪҜ件йҖ жҲҗзҡ„гҖӮе°Ҫз®ЎдёҚжҳҜеҚҒеҲҶзЎ®еҮҝпјҢдҪҶиҝҷеҫҲеҸҜиғҪж„Ҹе‘ізқҖиҪҜ件问йўҳгҖӮжңүе…іеҮәзҺ°зҡ„й”ҷиҜҜж¶ҲжҒҜзҡ„иҜҰз»ҶдҝЎжҒҜпјҢиҜ·еҸӮи§ҒдёҠиҝ°зү№е®ҡй”ҷиҜҜж¶ҲжҒҜйғЁеҲҶгҖӮ
l зү©зҗҶ CPUпјҡ
еҰӮжһңеӨҡдёӘ vmkernel й”ҷиҜҜдёӯзҡ„зү©зҗҶ CPU еҖје§Ӣз»ҲзӣёеҗҢпјҢеҲҷиЎЁжҳҺиҪҜ件жҖ»жҳҜеңЁеҗҢдёҖдёӘзү©зҗҶ CPU дёҠеҮәзҺ°й”ҷиҜҜгҖӮе°Ҫз®ЎдёҚжҳҜеҚҒеҲҶзЎ®еҮҝпјҢдҪҶиҝҷеҫҲеҸҜиғҪж„Ҹе‘ізқҖ CPU й—®йўҳгҖӮжңүе…іиҜҰз»ҶдҝЎжҒҜпјҢиҜ·еҸӮи§Ғ KB1003560
l зҺҜеўғпјҡ
еҰӮжһңеӨҡдёӘ vmkernel й”ҷиҜҜдёӯзҡ„зҺҜеўғеҖје§Ӣз»ҲзӣёеҗҢпјҢеҲҷиЎЁжҳҺ vmkernel д»ҺеҗҢдёҖзҺҜеўғжҺҘ收жҢҮд»Өж—¶еҮәзҺ°й”ҷиҜҜгҖӮе°Ҫз®ЎдёҚжҳҜеҚҒеҲҶзЎ®еҮҝпјҢдҪҶиҝҷеҫҲеҸҜиғҪж„Ҹе‘ізқҖеҸ‘йҖҒжҢҮд»Өзҡ„зҺҜеўғеҸҜиғҪи§ҰеҸ‘дәҶ VMkernel й”ҷиҜҜгҖӮ
дә”пјҡејӮеёёеҲ—иЎЁеҸӮиҖғ
ејӮеёёзұ»еһӢ 0 #DEпјҡйҷӨжі•й”ҷиҜҜпјҲDivide Errorпјү
ејӮеёёзұ»еһӢ 1 #DBпјҡи°ғиҜ•ејӮеёё
ејӮеёёзұ»еһӢ 2 NMIпјҡдёҚеҸҜеұҸи”Ҫдёӯж–ӯ
ејӮеёёзұ»еһӢ 3 #BPпјҡж–ӯзӮ№ејӮеёё
ејӮеёёзұ»еһӢ 4 #OFпјҡжәўеҮәпјҲINTO жҢҮд»Өпјү
ејӮеёёзұ»еһӢ 5 #BRпјҡз•ҢйҷҗжЈҖжҹҘпјҲBOUND жҢҮд»Өпјү
ејӮеёёзұ»еһӢ 6 #UDпјҡOpcode ж— ж•Ҳ
ејӮеёёзұ»еһӢ 7 #NMпјҡеҚҸеӨ„зҗҶеҷЁдёҚеҸҜз”Ё
ејӮеёёзұ»еһӢ 8 #DFпјҡеҸҢйҮҚж•…йҡң
ејӮеёёзұ»еһӢ 10 #TSпјҡTSS ж— ж•Ҳ
ејӮеёёзұ»еһӢ 11 #NPпјҡеҲҶж®өдёҚеӯҳеңЁ
ејӮеёёзұ»еһӢ 12 #SSпјҡе Ҷж ҲеҲҶж®өй”ҷиҜҜ
ејӮеёёзұ»еһӢ 13 #GPпјҡдёҖиҲ¬дҝқжҠӨй”ҷиҜҜ
ејӮеёёзұ»еһӢ 14 #PFпјҡйЎөйқўй”ҷиҜҜ
ејӮеёёзұ»еһӢ16 #MFпјҡеҚҸеӨ„зҗҶеҷЁй”ҷиҜҜ
ејӮеёёзұ»еһӢ 17 #ACпјҡеҜ№йҪҗжЈҖжҹҘ
ејӮеёёзұ»еһӢ 18 #MCпјҡи®Ўз®—жңәжЈҖжҹҘејӮеёё
ејӮеёёзұ»еһӢ 19 #XFпјҡSIMD жө®зӮ№ејӮеёё
ејӮеёёзұ»еһӢ 20-31пјҡйў„з•ҷ
ејӮеёёзұ»еһӢ 32-255пјҡз”ЁжҲ·е®ҡд№үпјҲж—¶й’ҹи°ғеәҰзЁӢеәҸпјү
е…ӯпјҡзӨәдҫӢ
еңЁе®һйҷ…зҺҜеўғдёӯйҒҮеҲ°иҝҮд»ҘдёӢжҸҗзӨәзҡ„зҙ«еұҸжғ…еҶөпјҢйҖҡиҝҮеұҸ幕дёӯзҡ„дҝЎжҒҜеҸҜд»ҘиҺ·зҹҘд»ҘдёӢеҮ зӮ№дҝЎжҒҜпјҢж•…йҡңзҡ„ESXIдё»жңәжҳҜesxi 6.0 U2(build 3620759)пјҢиҜҘдё»жңәиҮӘдёҠж¬ЎејҖжңәжқҘжӯЈеёёиҝҗиЎҢдәҶ35:18:32:21д№ҹе°ұжҳҜ35еӨ©18е°Ҹж—¶32еҲҶгҖӮ
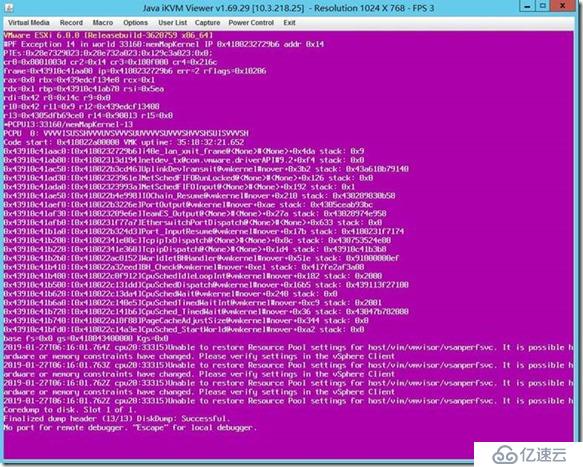
еҗҢж—¶е…ідәҺиҜҘзҙ«еұҸзҡ„е…ій”®д»Јз ҒдҝЎжҒҜжҳҜPF Exception 14 in world 33168:memMapKernal ж №жҚ®иҜҘе…ій”®д»Јз ҒдҝЎжҒҜеҸҜд»ҘеңЁVMwareзҡ„KBеә“дёӯжҹҘеҲ°д»ҘдёӢ
https://kb.vmware.com/s/article/1020181?lang=zh_CN#q=esxi%E7%B4%AB%E5%B1%8F
https://kb.vmware.com/s/article/2071752?lang=zh_CN#q=esxi%E7%B4%AB%E5%B1%8F
ж №жҚ®KBд»Ӣз»ҚпјҢдҝЎжҒҜеҸҜиғҪеҰӮдёӢпјҡ
еҰӮжһңиҰҒиҜ·жұӮзҡ„йЎөйқўжңӘжҲҗеҠҹиҪҪе…ҘеҶ…еӯҳпјҢеҲҷдјҡеҮәзҺ°йЎөйқўй”ҷиҜҜпјҲејӮеёё 14пјүгҖӮеӯҳеңЁжӯЈеёёзҠ¶жҖҒе’ҢйқһжӯЈеёёзҠ¶жҖҒдёӨз§ҚйЎөйқўй”ҷиҜҜпјҡ
жӯЈеёёзҠ¶жҖҒйЎөйқўй”ҷиҜҜдјҡеҜјиҮҙйЎөйқўд»ҺдәӨжҚўеҶ…еӯҳиҪҪе…Ҙзү©зҗҶеҶ…еӯҳгҖӮиҝҷж ·дҫҝе…Ғи®ёзЁӢеәҸеңЁж•°жҚ®жӯЈзЎ®иҪҪе…Ҙзү©зҗҶеҶ…еӯҳеҗҺ继з»ӯжү§иЎҢгҖӮ
еҰӮжһңйЎөйқўжңӘиҪҪе…ҘеҶ…еӯҳпјҢ并且ж“ҚдҪңзі»з»ҹж— жі•е°ҶйЎөйқўд»ҺдәӨжҚўеҶ…еӯҳиҪҪе…Ҙзү©зҗҶеҶ…еӯҳпјҢеҲҷдјҡеҮәзҺ°йқһжӯЈеёёзҠ¶жҖҒйЎөйқўй”ҷиҜҜгҖӮ
еҶҚй…ҚеҗҲеҗҺйқўзҡ„MemMapKernalеӯ—ж®өеӨ§жҰӮеҸҜд»ҘеҲӨж–ӯжң¬ж¬Ўзҡ„зҙ«еұҸжғіиұЎжҳҜз”ұESXIдё»жңәдёӯзҡ„еҶ…еӯҳејӮеёёеҜјиҮҙзҡ„пјҢеҸҜиғҪжҳҜеҶ…еӯҳиҪҪе…ҘжҲ–еҶ…еӯҳжәўеҮәпјҢд№ҹжңүеҸҜиғҪжҳҜеңЁжң¬зӨәдҫӢдёӯзҡ„Horizon ViewдёӯиҷҡжӢҹеҶ…еӯҳе…ұдә«жңәеҲ¶еҜјиҮҙзҡ„зі»з»ҹзҙ«еұҸж•…йҡңгҖӮ
е…ідәҺESXIдё»жңәзҙ«еұҸеҲҶжһҗж–№жі•жҳҜд»Җд№Ҳе°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





