机器学习处于优势地位。特别是在模式识别方面,机器学习是首选方法。其应用的有形示例包括欺诈检测,图像识别,预测性维护和列车延迟预测系统。在日常机器学习(ML)和寻求部署所获得的知识的过程中,我们通常会遇到这三个主要问题(但不是唯一的问题)。
数据质量 - 来自多个时间范围内的多个来源的数据可能难以整理成干净且连贯的数据集,这些数据集将从机器学习中获得最大收益。典型问题包括数据丢失,数据值不一致,自相关等。
<< 下载数据质量权威指南 >>
业务相关性 - 虽然支持机器学习革命的许多技术进展比以往任何时候都更快,但是今天的许多应用程序都没有考虑到商业价值。
操作模型 - 一旦模型经历了构建和调整周期,将机器学习过程的结果部署到更广泛的业务中至关重要。这是一个难以跨越的桥梁,因为预测建模人员通常不是IT解决方案专家,反之亦然。
机器学习背后还有一整套算法工具箱,每个算法都可以使用所谓的超参数进行调整,以获得更高的精度。例如,对于流行的k-最近邻算法,k指的是我们想要考虑的邻居的数量。在神经网络中,这将涵盖网络的整个架构。
数据科学家今天所做的一项关键任务是为给定问题找到正确的算法并正确地“设置”它。但实际上,任务范围要大得多。数据科学家必须了解问题的业务视角,解决数据情况,适当准备数据并获得有助于评估的模型。这通常是遵循跨行业标准数据挖掘过程(CRISP-DM)的循环过程[1]。
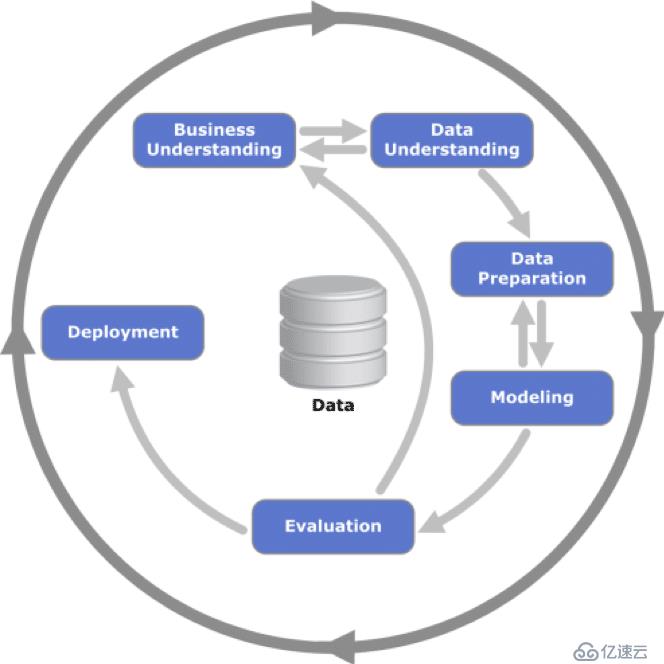
相应地,机器学习领域的项目很复杂,需要多个人在一系列领域(商业,IT,数据科学)获得资格的时间。此外,通常不清楚结果将是什么:因此,在这个意义上,这样的项目是有风险的。
直到今天,数据科学项目无法实现自动化。但是,有些情况下,项目的某些步骤可以自动化:这就是自动机器学习(AutoML)概念背后的原因。例如,AutoML可以帮助选择算法。数据科学家通常比较几个算法对问题的结果,并在考虑一系列因素(例如质量,复杂性/持续时间,鲁棒性)的情况下选择一个算法。在某些情况下可以自动化的另一个方面是超参数的设置:许多算法可以通过参数及其相对于特定问题优化的质量来调整。
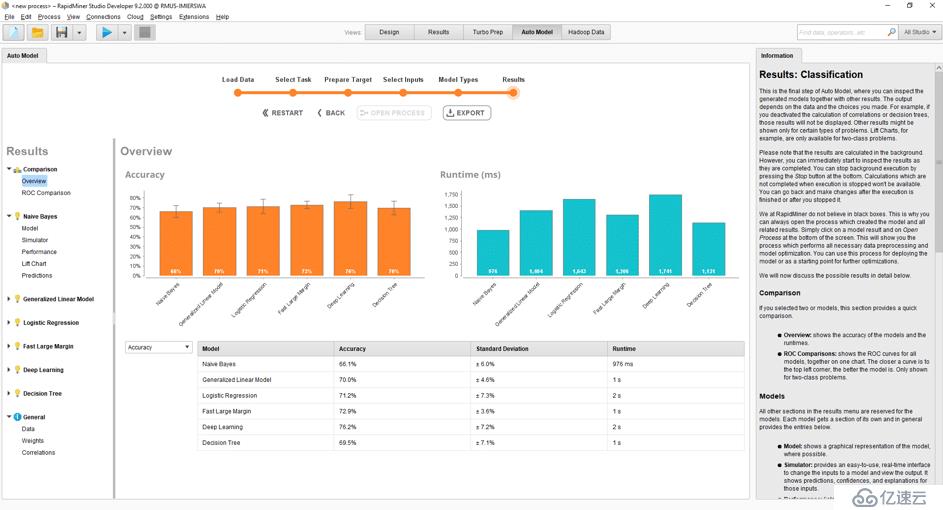
AutoML是一种资源,可以加速那些部件或单个步骤自动化的数据科学项目,从而提高生产力。例如,AutoML在算法评估中非常有用。因此,许多库和工具都采用AutoML作为补充功能。值得注意的例子包括auto-sklearn(在Python社区中)或DataRobot,它专门研究AutoML。以下示例摘自RapidMiner,显示了如何使用助手比较不同的算法,并快速找到针对特定问题的最佳算法[2]:
尽管如此,AutoML不应该被理解为一种万能的解决方案,能够完全自动化数据科学项目并且不需要数据科学家。从这个意义上说,不幸的是,它不是圣杯。
与其他专业领域一样,自动化首先是繁琐的技术任务,其中高技能专业人员否则会花费大部分时间系统地尝试某些参数集,然后比较结果 - 这项工作最好留给机器。
剩下的是人类仍然需要解决的大量挑战。这首先要了解实际问题本身,并涵盖从数据工程到部署的各种各样的,非常耗时的任务。AutoML是一个很有用的工具,但它还不是圣杯。
更多:(http://www.o9qh.com)
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





