иҜҘеҰӮдҪ•иҝӣиЎҢMySQLзҡ„зҙўеј•еҲҶзұ»
иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶д»Ӣз»ҚиҜҘеҰӮдҪ•иҝӣиЎҢMySQLзҡ„зҙўеј•еҲҶзұ»пјҢеҶ…е®№йқһеёёиҜҰз»ҶпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们еҸҜд»ҘеҸӮиҖғеҖҹйүҙпјҢеёҢжңӣеҜ№еӨ§е®¶иғҪжңүжүҖеё®еҠ©гҖӮ
MySQLзҡ„зҙўеј•еҲҶзұ»й—®йўҳдёҖзӣҙи®©дәәеӨҙз–јпјҢеҮ д№ҺжүҖжңүзҡ„иө„ж–ҷйғҪдјҡз»ҷдҪ еҲ—дёҖдёӘй•ҝй•ҝзҡ„жё…еҚ•пјҢз»ҷдҪ д»Ӣз»Қд»Җд№Ҳдё»й”®зҙўеј•гҖҒеҚ•еҖјзҙўеј•пјҢиҰҶзӣ–зҙўеј•пјҢиҮӘйҖӮеә”е“ҲеёҢзҙўеј•пјҢе…Ёж–Үзҙўеј•пјҢиҒҡз°Үзҙўеј•пјҢйқһиҒҡз°Үзҙўеј•зӯүвҖҰвҖҰз»ҷдәәзҡ„ж„ҹи§үе°ұжҳҜдә‘йҮҢйӣҫйҮҢпјҢеҘҪеғҸMySQLзҙўеј•зҡ„е®һзҺ°ж–№ејҸжңүеҫҲеӨҡз§ҚпјҢдҪҶжҳҜйғҪжІЎжңүдёҖдёӘжё…жҷ°зҡ„еҲҶзұ»гҖӮжүҖд»Ҙжң¬дәәе°қиҜ•жҖ»з»“дәҶдёҖдёӢеҰӮдҪ•з»ҷMySQLзҡ„зҙўеј•зұ»еһӢеҲҶзұ»пјҢдҫҝдәҺеӨ§е®¶и®°еҝҶпјҢз”ұдәҺMySQLдёӯж”ҜжҢҒеӨҡз§ҚеӯҳеӮЁеј•ж“ҺпјҢеңЁдёҚеҗҢзҡ„еӯҳеӮЁеј•ж“Һдёӯе®һзҺ°з•Ҙеҫ®жңүжүҖе·®и·қпјҢдёӢж–ҮдёӯеҰӮжһңжІЎжңүзү№ж®ҠеЈ°жҳҺпјҢй»ҳи®ӨжҢҮзҡ„йғҪжҳҜInnoDBеӯҳеӮЁеј•ж“ҺгҖӮ
зҙўеј•д»ҺдёҚеҗҢз»ҙеәҰеҲ’еҲҶеҸҜд»ҘжңүеҫҲеӨҡз§ҚеҗҚз§°пјҢдҪҶжҳҜйңҖиҰҒжҳҺзЎ®дёҖдёӘй—®йўҳвҖ”вҖ”зҙўеј•зҡ„жң¬иҙЁжҳҜдёҖз§Қж•°жҚ®з»“жһ„пјҢе…¶д»–зҙўеј•зҡ„еҲ’еҲҶеҲҷжҳҜй’ҲеҜ№е®һйҷ…еә”з”ЁиҖҢиЁҖгҖӮ
дёҖгҖҒж №жҚ®еә•еұӮж•°жҚ®з»“жһ„еҲ’еҲҶ
зҙўеј•жҳҜжҸҗй«ҳжҹҘиҜўж•ҲзҺҮзҡ„ж•°жҚ®з»“жһ„пјҢиҖҢиғҪеӨҹжҸҗй«ҳжҹҘиҜўж•ҲзҺҮзҡ„ж•°жҚ®з»“жһ„жңүеҫҲеӨҡпјҢеҰӮдәҢеҸүжҗңзҙўж ‘пјҢзәўй»‘ж ‘пјҢи·іиЎЁпјҢе“ҲеёҢиЎЁпјҲж•ЈеҲ—иЎЁпјүзӯүпјҢиҖҢMySQLдёӯз”ЁеҲ°дәҶB+Treeе’Ңж•ЈеҲ—иЎЁпјҲHashиЎЁпјүдҪңдёәзҙўеј•зҡ„еә•еұӮж•°жҚ®з»“жһ„(е…¶е®һд№ҹз”ЁеҲ°дәҶи·іиЎЁе®һзҺ°е…Ёж–Үзҙўеј•пјҢдҪҶиҝҷдёҚжҳҜйҮҚиҰҒиҖғзӮ№пјҢжүҖд»ҘеҸҜд»ҘеҝҪз•Ҙ)гҖӮ
1. hashзҙўеј•
MySQL并没жңүжҳҫејҸж”ҜжҢҒHashзҙўеј•пјҢиҖҢжҳҜдҪңдёәеҶ…йғЁзҡ„дёҖз§ҚдјҳеҢ–гҖӮе…·дҪ“еңЁInnodbеӯҳеӮЁеј•ж“ҺйҮҢпјҢдјҡзӣ‘жҺ§еҜ№иЎЁдёҠдәҢзә§зҙўеј•зҡ„жҹҘжүҫпјҢеҰӮжһңеҸ‘зҺ°жҹҗдәҢзә§зҙўеј•иў«йў‘з№Ғи®ҝй—®пјҢдәҢзә§зҙўеј•жҲҗдёәзғӯж•°жҚ®пјҢе°ұдёәд№Ӣе»әз«Ӣhashзҙўеј•гҖӮеӣ жӯӨпјҢеңЁMySQLзҡ„InnodbйҮҢпјҢеҜ№дәҺзғӯзӮ№зҡ„ж•°жҚ®дјҡиҮӘеҠЁз”ҹжҲҗHashзҙўеј•гҖӮиҝҷз§Қhashзҙўеј•пјҢж №жҚ®е…¶дҪҝз”Ёзҡ„еңәжҷҜзү№зӮ№пјҢд№ҹеҸ«иҮӘйҖӮеә”Hashзҙўеј•гҖӮ
2. B+ж ‘зҙўеј•
иҝҷдёӘжҳҜMySQLзҙўеј•зҡ„еҹәжң¬е®һзҺ°ж–№ејҸгҖӮйҷӨдәҶе…Ёж–Үзҙўеј•гҖҒhashзҙўеј•пјҢInnodbгҖҒMyISAMзҡ„зҙўеј•йғҪжҳҜйҖҡиҝҮB+ж ‘е®һзҺ°зҡ„гҖӮ
дәҢгҖҒж №жҚ®зҙўеј•еӯ—ж®өдёӘж•°еҲ’еҲҶ
дёәдәҶиғҪеә”еҜ№дёҚеҗҢзҡ„ж•°жҚ®жЈҖзҙўйңҖжұӮпјҢзҙўеј•ж—ўеҸҜд»Ҙд»…еҢ…еҗ«дёҖдёӘеӯ—ж®өпјҢд№ҹеҸҜд»ҘеҗҢж—¶еҢ…еҗ«еӨҡдёӘеӯ—ж®өгҖӮеҚ•дёӘеӯ—ж®өз»„жҲҗзҡ„зҙўеј•еҸҜд»Ҙз§°дёәеҚ•еҖјзҙўеј•пјҢеҗҰеҲҷз§°д№ӢдёәеӨҚеҗҲзҙўеј•пјҢд№ҹз§°дёәз»„еҗҲзҙўеј•жҲ–еӨҡеҖјзҙўеј•гҖӮ
иҝҷдёӘеҫҲеҘҪзҗҶи§ЈпјҢеҒҮеҰӮжҲ‘们жңүдёҖеј иЎЁпјҢжңүдёүдёӘеұһжҖ§пјҢеҲҶеҲ«жҳҜ idпјҢage е’Ң name гҖӮеҒҮеҰӮеңЁidдёҠе»әз«Ӣзҙўеј•пјҢйӮЈиҝҷе°ұжҳҜеҚ•еҖјзҙўеј•пјӣеҰӮжһңеңЁ name е’Ң age дёҠе»әз«Ӣзҙўеј•пјҢйӮЈиҝҷе°ұжҳҜеӨҚеҗҲзҙўеј•гҖӮ
еӨҚеҗҲзҙўеј•зҡ„зҙўеј•зҡ„ж•°жҚ®йЎәеәҸи·ҹеӯ—ж®өзҡ„йЎәеәҸзӣёе…іпјҢеҢ…еҗ«еӨҡдёӘеҖјзҡ„зҙўеј•дёӯпјҢеҰӮжһңеҪ“еүҚйқўеӯ—ж®өзҡ„еҖјйҮҚеӨҚж—¶пјҢе°ҶдјҡжҢүз…§е…¶еҗҺйқўзҡ„еҖјиҝӣиЎҢжҺ’еәҸгҖӮ
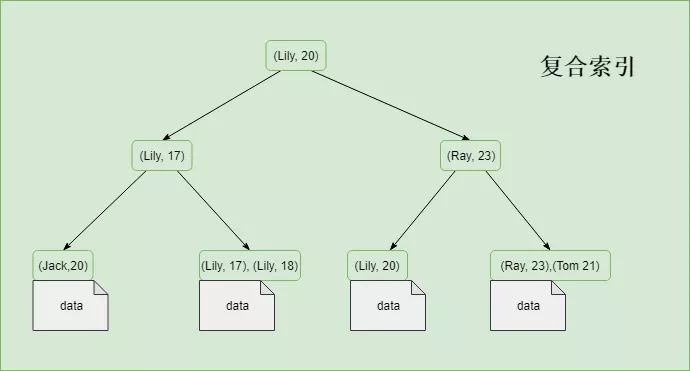
дҪҝз”ЁиҰҶзӣ–зҙўеј•зҡ„еүҚжҸҗжҳҜеӯ—ж®өй•ҝеәҰжҜ”иҫғзҹӯпјҢеҜ№дәҺеҖјй•ҝеәҰиҫғй•ҝзҡ„еӯ—ж®өеҲҷдёҚйҖӮеҗҲдҪҝз”ЁиҰҶзӣ–зҙўеј•пјҢеҺҹеӣ жңүеҫҲеӨҡпјҢжҜ”еҰӮзҙўеј•дёҖиҲ¬еӯҳеӮЁеңЁеҶ…еӯҳдёӯпјҢеҰӮжһңеҚ з”Ёз©әй—ҙиҫғеӨ§пјҢеҲҷеҸҜиғҪдјҡд»ҺзЈҒзӣҳдёӯеҠ иҪҪпјҢеҪұе“ҚжҖ§иғҪгҖӮ
дёүгҖҒж №жҚ®жҳҜеҗҰжҳҜеңЁдё»й”®дёҠе»әз«Ӣзҡ„зҙўеј•иҝӣиЎҢеҲ’еҲҶ
1. дё»й”®зҙўеј•
MySQLдёӯжҳҜж №жҚ®дё»й”®жқҘз»„з»Үж•°жҚ®зҡ„пјҢжүҖд»ҘжҜҸеј иЎЁйғҪеҝ…йЎ»жңүдё»й”®зҙўеј•пјҢдё»й”®зҙўеј•еҸӘиғҪжңүдёҖдёӘпјҢдёҚиғҪдёәnullеҗҢж—¶еҝ…йЎ»дҝқиҜҒе”ҜдёҖжҖ§гҖӮе»әиЎЁж—¶еҰӮжһңжІЎжңүжҢҮе®ҡдё»й”®зҙўеј•пјҢеҲҷдјҡиҮӘеҠЁз”ҹжҲҗдёҖдёӘйҡҗи—Ҹзҡ„еӯ—ж®өдҪңдёәдё»й”®зҙўеј•гҖӮ
2. иҫ…еҠ©зҙўеј•
еҰӮжһңдёҚжҳҜдё»й”®зҙўеј•пјҢеҲҷе°ұеҸҜд»Ҙз§°д№Ӣдёәйқһдё»й”®зҙўеј•пјҢеҸҲеҸҜд»Ҙз§°д№Ӣдёәиҫ…еҠ©зҙўеј•жҲ–иҖ…дәҢзә§зҙўеј•гҖӮдё»й”®зҙўеј•зҡ„еҸ¶еӯҗиҠӮзӮ№еӯҳеӮЁдәҶе®Ңж•ҙзҡ„ж•°жҚ®иЎҢпјҢиҖҢйқһдё»й”®зҙўеј•зҡ„еҸ¶еӯҗиҠӮзӮ№еӯҳеӮЁзҡ„еҲҷжҳҜдё»й”®зҙўеј•еҖјпјҢйҖҡиҝҮйқһдё»й”®зҙўеј•жҹҘиҜўж•°жҚ®ж—¶пјҢдјҡе…ҲжҹҘжүҫеҲ°дё»й”®зҙўеј•пјҢ然еҗҺеҶҚеҲ°дё»й”®зҙўеј•дёҠеҺ»жҹҘжүҫеҜ№еә”зҡ„ж•°жҚ®гҖӮ
еңЁиҝҷйҮҢеҒҮи®ҫжҲ‘们жңүеј иЎЁuserпјҢе…·жңүдёүеҲ—пјҡIDпјҢageпјҢnameпјҢcreate_timeпјҢidжҳҜдё»й”®пјҢпјҲageпјҢcreate_time,пјҢnameпјүе»әз«Ӣиҫ…еҠ©зҙўеј•гҖӮжү§иЎҢеҰӮдёӢsqlиҜӯеҸҘпјҡ
select name from user where age>2 order by create_time descгҖӮ
жӯЈеёёзҡ„иҜқпјҢжҹҘиҜўеҲҶдёӨжӯҘпјҡ
1.жҢүз…§иҫ…еҠ©зҙўеј•пјҢжҹҘжүҫеҲ°и®°еҪ•зҡ„дё»й”®пјҢ
2.жҢүз…§дё»й”®дё»й”®зҙўеј•йҮҢжҹҘжүҫи®°еҪ•пјҢиҝ”еӣһnameгҖӮ
дҪҶе®һйҷ…дёҠпјҢжҲ‘们еҸҜд»ҘзңӢеҲ°пјҢиҫ…еҠ©зҙўеј•иҠӮзӮ№жҳҜжҢүз…§ageпјҢcreate_timeпјҢnameе»әз«Ӣзҡ„пјҢзҙўеј•дҝЎжҒҜйҮҢе®Ңе…ЁеҢ…еҗ«жҲ‘们жүҖиҰҒзҡ„дҝЎжҒҜпјҢеҰӮжһңиғҪд»Һиҫ…еҠ©зҙўеј•йҮҢиҝ”еӣһnameдҝЎжҒҜпјҢеҲҷ第дәҢжӯҘжҳҜе®Ңе…ЁжІЎжңүеҝ…иҰҒзҡ„пјҢеҸҜд»ҘжһҒеӨ§жҸҗеҚҮжҹҘиҜўйҖҹеәҰгҖӮ
жҢүз…§иҝҷз§ҚжҖқжғіInnodbйҮҢй’ҲеҜ№дҪҝз”Ёиҫ…еҠ©зҙўеј•зҡ„жҹҘиҜўеңәжҷҜеҒҡдәҶдјҳеҢ–пјҢеҸ«иҰҶзӣ–зҙўеј•пјҲеңЁиҝҷйҮҢе°ҸеЈ°еҗҗж§ҪдёҖдёӢпјҢдёҚзҹҘйҒ“дёҡз•Ңиө·иҝҷз§ҚеҗҚиҜҚе№ІеҳӣпјҢеӨӘе®№жҳ“еј•иө·жӯ§д№үдәҶпјҢеҸ«дёӘзҙўеј•иҰҶзӣ–жҹҘиҜўдёҚжҳҜжӣҙеҘҪеҗ—пјүгҖӮ
еӣӣгҖҒж №жҚ®ж•°жҚ®дёҺзҙўеј•зҡ„еӯҳеӮЁе…іиҒ”жҖ§еҲ’еҲҶ
ж №жҚ®ж•°жҚ®дёҺзҙўеј•зҡ„еӯҳеӮЁе…іиҒ”жҖ§пјҢеҸҜд»ҘеҲҶдёәиҒҡз°Үзҙўеј•е’ҢйқһиҒҡз°Үзҙўеј•пјҲд№ҹеҸ«иҒҡйӣҶзҙўеј•е’ҢйқһиҒҡйӣҶзҙўеј•пјүгҖӮиҒҡз°Үзҙўеј•д№ҹеҸ«з°Үзұ»зҙўеј•пјҢжҳҜдёҖз§ҚеҜ№зЈҒзӣҳдёҠе®һйҷ…ж•°жҚ®йҮҚж–°з»„з»Үд»ҘжҢүжҢҮе®ҡзҡ„дёҖдёӘжҲ–еӨҡдёӘеҲ—зҡ„еҖјжҺ’еәҸгҖӮж•ҙдёӘз®ҖжҙҒзҡ„иҜҙжі•пјҢиҝҷдҝ©зҡ„еҢәеҲ«е°ұжҳҜзҙўеј•зҡ„еӯҳеӮЁйЎәеәҸе’Ңж•°жҚ®зҡ„еӯҳеӮЁйЎәеәҸжҳҜеҗҰжҳҜе…ізі»зҡ„пјҢжңүе…іе°ұжҳҜиҒҡз°Үзҙўеј•пјҢж— е…іе°ұжҳҜйқһиҒҡз°Үзҙўеј•гҖӮе…·дҪ“е®һзҺ°ж–№ејҸж №жҚ®зҙўеј•зҡ„ж•°жҚ®з»“жһ„дёҚеҗҢдјҡжңүжүҖдёҚеҗҢгҖӮдёӢйқўд»ҘB+ж ‘е®һзҺ°зҡ„зҙўеј•дёәдҫӢпјҢдёҫдҫӢжқҘиҜҙжҳҺиҒҡз°Үзҙўеј•е’ҢйқһиҒҡз°Үзҙўеј•гҖӮ
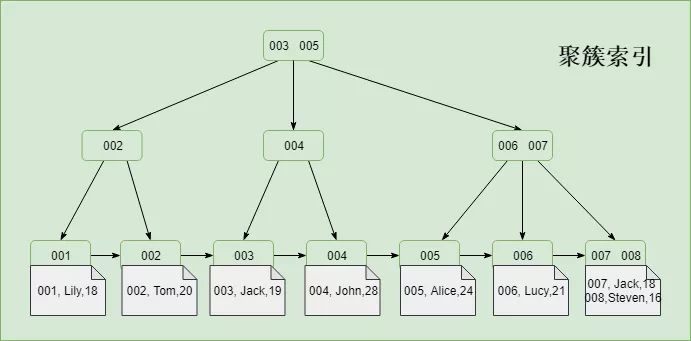
1. иҒҡз°Үзҙўеј•
Innodbзҡ„дё»й”®зҙўеј•пјҢйқһеҸ¶еӯҗиҠӮзӮ№еӯҳеӮЁзҡ„жҳҜзҙўеј•жҢҮй’ҲпјҢеҸ¶еӯҗиҠӮзӮ№еӯҳеӮЁзҡ„жҳҜж—ўжңүзҙўеј•д№ҹжңүж•°жҚ®пјҢжҳҜе…ёеһӢзҡ„иҒҡз°Үзҙўеј•пјҲиҝҷйҮҢеҸҜд»ҘеҸ‘зҺ°пјҢзҙўеј•е’Ңж•°жҚ®зҡ„еӯҳеӮЁйЎәеәҸжҳҜејәзӣёе…ізҡ„гҖӮеӣ жӯӨжҳҜе…ёеһӢзҡ„иҒҡз°Үзҙўеј•пјүпјҢеҰӮеӣҫпјҡ
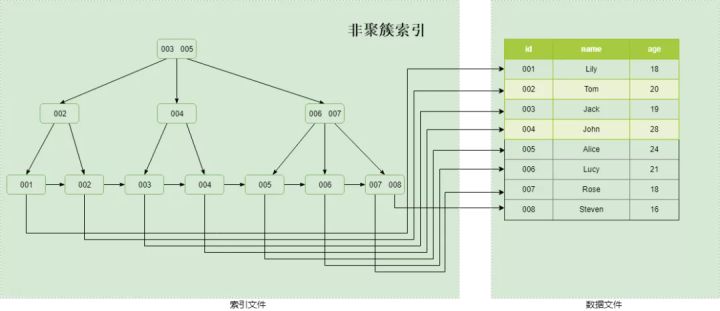
2. йқһиҒҡз°Үзҙўеј•
MyISAMдёӯзҙўеј•е’Ңж•°жҚ®ж–Ү件еҲҶејҖеӯҳеӮЁпјҢB+Treeзҡ„еҸ¶еӯҗиҠӮзӮ№еӯҳеӮЁзҡ„жҳҜж•°жҚ®еӯҳж”ҫзҡ„ең°еқҖпјҢиҖҢдёҚжҳҜе…·дҪ“зҡ„ж•°жҚ®пјҢжҳҜе…ёеһӢзҡ„йқһиҒҡз°Үзҙўеј•пјӣжҚўиЁҖд№ӢпјҢж•°жҚ®еҸҜд»ҘеңЁзЈҒзӣҳдёҠйҡҸдҫҝжүҫең°ж–№еӯҳпјҢзҙўеј•д№ҹеҸҜд»ҘеңЁзЈҒзӣҳдёҠйҡҸдҫҝжүҫең°ж–№еӯҳпјҢеҸӘиҰҒеҸ¶еӯҗиҠӮзӮ№и®°еҪ•еҜ№дәҶж•°жҚ®еӯҳж”ҫең°еқҖе°ұиЎҢгҖӮеӣ жӯӨпјҢзҙўеј•еӯҳеӮЁйЎәеәҸе’Ңж•°жҚ®еӯҳеӮЁе…ізі»жҜ«ж— е…іиҒ”пјҢжҳҜе…ёеһӢзҡ„йқһиҒҡз°Үзҙўеј•пјҢеҸҰеӨ–InndobйҮҢзҡ„иҫ…еҠ©зҙўеј•д№ҹжҳҜйқһиҒҡз°Үзҙўеј•гҖӮ
дә”гҖҒе…¶д»–еҲҶзұ»
1. е”ҜдёҖзҙўеј•
йЎҫеҗҚжҖқд№үпјҢдёҚе…Ғи®ёе…·жңүзҙўеј•еҖјзӣёеҗҢзҡ„иЎҢпјҢд»ҺиҖҢзҰҒжӯўйҮҚеӨҚзҡ„зҙўеј•жҲ–й”®еҖјгҖӮзі»з»ҹеңЁеҲӣе»әиҜҘзҙўеј•ж—¶жЈҖжҹҘжҳҜеҗҰжңүйҮҚеӨҚзҡ„й”®еҖјпјҢ并еңЁжҜҸж¬ЎдҪҝз”Ё INSERT жҲ– UPDATE иҜӯеҸҘж·»еҠ ж•°жҚ®ж—¶иҝӣиЎҢжЈҖжҹҘпјҢ еҰӮжһңжңүйҮҚеӨҚзҡ„еҖјпјҢеҲҷдјҡж“ҚдҪңеӨұиҙҘпјҢжҠӣеҮәејӮеёёгҖӮ
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢдё»й”®зҙўеј•дёҖе®ҡжҳҜе”ҜдёҖзҙўеј•пјҢиҖҢе”ҜдёҖзҙўеј•дёҚдёҖе®ҡжҳҜдё»й”®зҙўеј•гҖӮе”ҜдёҖзҙўеј•еҸҜд»ҘзҗҶи§Јдёәд»…д»…жҳҜе°Ҷзҙўеј•и®ҫзҪ®дёҖдёӘе”ҜдёҖжҖ§зҡ„еұһжҖ§гҖӮ
2. е…Ёж–Үзҙўеј•
еңЁMySQL 5.6зүҲжң¬д»ҘеүҚ,еҸӘжңүMyISAMеӯҳеӮЁеј•ж“Һж”ҜжҢҒе…Ёж–Үеј•ж“ҺгҖӮеңЁ5.6зүҲжң¬дёӯ,InnoDBеҠ е…ҘдәҶеҜ№е…Ёж–Үзҙўеј•зҡ„ж”ҜжҢҒ,дҪҶжҳҜдёҚж”ҜжҢҒдёӯж–Үе…Ёж–Үзҙўеј•.еңЁ5.7.6зүҲжң¬,MySQLеҶ…зҪ®дәҶngramе…Ёж–Үи§ЈжһҗеҷЁ,з”ЁжқҘж”ҜжҢҒдәҡжҙІиҜӯз§Қзҡ„еҲҶиҜҚгҖӮдё»иҰҒз”ЁжқҘеҲ©з”Ёе…ій”®иҜҚжҹҘиҜўж–Үжң¬пјҢдёҚжҳҜMySQLзҡ„дё»иҰҒйқўеҗ‘еңәжҷҜпјҢдҪҝз”Ёиҫғе°‘пјҢиҝҷйҮҢе°ұдёҚеұ•ејҖи®Ёи®әдәҶгҖӮ
е…ӯгҖҒжҖ»з»“
жңҖеҗҺжҖ»з»“дёҖеј и„‘еӣҫж–№дҫҝи®°еҝҶпјҡ
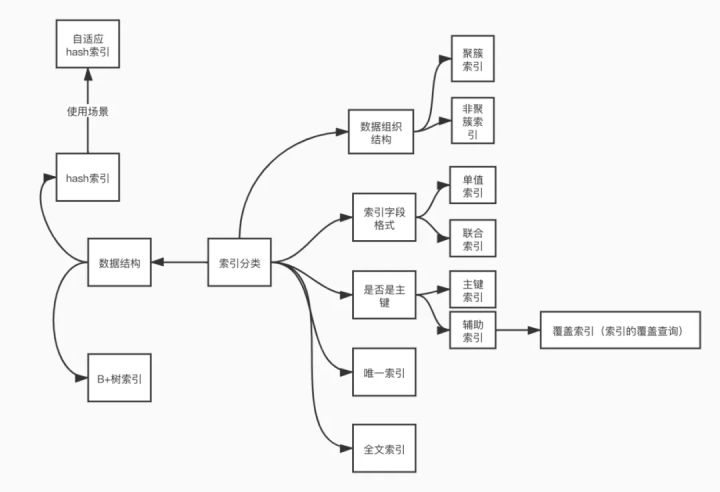
е…ідәҺиҜҘеҰӮдҪ•иҝӣиЎҢMySQLзҡ„зҙўеј•еҲҶзұ»е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





