这篇文章主要介绍“怎么理解并掌握RAC”,在日常操作中,相信很多人在怎么理解并掌握RAC问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”怎么理解并掌握RAC”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
理解redo共享了和redo单个sequence里面的scn不连续,就会明白为什么RAC到RAC的恢复或RAC到单机的恢复,一般都是recover到某个thread的某个scn或sequnce就可以了
数据库是否RAC就是看参数cluster_database
RAC区别于单机的一个就是多了一个GRD(global resource directory)内存区以及附属的多个后台进程和部分数据库文件,GRD里记录的是每一个数据块在集群间的分布图,它位于每一个实例的SGA的shared pool中,但是每个实例都是部分GRD,所有实例的GRD汇总在一起就是一个完整的GRD。该区域用来存储同一个数据库在不同节点上的分布,即多个实例在并发操作一个数据块时,将该数据块存储在各自实例的GRD内存区中。
GRD可以想像为一张大分区表,每个实例都是分区表中的分区。
GRD Master:每个被调入内存的对象,包括表,索引,cluster等,都会被分配一个master实例。
GRD Master本身也是一张表:(V$GCSHVMASTER_INFO、V$GCSPFMASTER_INFO、V$HVMASTER_INFO)
objectmaster_instance_id
T11
T22
T31
idx_t12
...
每个实例只会维护该实例所master的那些资源的GRD记录。
比如实例1里记录的GRD的数据就是T1,T3等的GRD的记录。
obj#file#block#instance.....
T110020002
T110014561
T2....
每个实例都有一份完全一样的拷贝的GRD Master表。
这个master表记录的是数据库对象,不是数据库的某行某块
RAC实例访问的形象理解1:比如 master表记录中没有关于数据库对象表1的记录
实例1去访问表1的某行对应的块,发现master表中没有表1,也就是表1从来没有访问过,这样数据库就在master表中记录表1的master为实例1
RAC实例访问的形象理解2:比如 master表记录的数据库对象表1的maser是实例2
实例1去访问表1的某行对应的块,实例1去访问实例2,实例2发现这个块不在GRD中,就告诉实例1这个块不在SGA中,实例2让实例1去走IO访问磁盘
实例1去访问表1的某行对应的块,实例1去访问实例2,实例2发现这个块在GRD中并且就在自己的SGA上,实例2把这个块的副本发送给实例1
实例1去访问表1的某行对应的块,实例1去访问实例2,实例2发现这个块在GRD中并且在实例3上,实例2告诉实例1这个块在实例3上,并且实例2让实例3把这个块的副本发送给实例1
2 way和3 way是指要跳几个节点
只有两节点的RAC不可能出现gc current 3-way,两节点,某个数据块不在自己这里就在对方那里
本节点去访问resource MASTER节点
2-way: resource MASTER 和 cached 节点在同一个节点。
3 way: 就是多一个节点 ,resource MASTER 和 cached 节点不是同一个节点
RAC提高性能的理解:负载不足导致sql执行很慢时,多个实例可以分摊负载(CPU、内存),负载不是性能瓶颈的情况下,RAC无法提高具体的sql的执行效率,相反实例越多,具体的单个SQL的性能越差。
实例越多性能越差的理解:比如10个节点,实例A要访问100个块,其中10个块在节点1,10个块在节点2.。。10个块在节点10,这样100个块,就要访问1次master,master再告诉块具体在哪个节点,这些节点再把块推送到实例A,这样就需要1次实例到master的访问+10次master到各个节点的访问+10次各个节点推送块到节点A,总计11次的访问+10次的GC块传输
RAC 的本质是一个数据库,运行在多台计算机上的数据库,它通过 Distributed Lock Management(DLM:分布式锁管理器) 来解决并发问题。因为RAC的资源是共享的,为了保证数据的一致性,就需要使用DLM来协调实例间对资源的竞争访问。RAC 的DLM 就叫作 Cache Fusion(内存融合)。
Cache Fusion是通过高速的Private Interconnect,在实例间进行数据块传递,它是RAC 最核心的工作机制,它把所有实例的SGA虚拟成一个大的SGA区,从而使得多个节点SGA对用户透明。每当不同的实例请求相同的数据块时,这个数据块就通过Private Interconnect 在实例间进行传递。以避免首先将块推送到磁盘,然后再重新读入其他实例的缓存中这样一种低效的实现方式。当一个块被读入RAC环境中某个实例的缓存时,该块会被赋予一个锁资源(与行级锁不同),以确保其他实例知道该块正在被使用。之后,如果另一个实例请求该块的一个副本,而该块已经处于前一个实例的缓存内,那么该块会通过Private Interconnect直接被传递到另一个实例的SGA。如果内存中的块已经被改变,但改变尚未提交,那么将会传递一个CR副本。这就意味着只要可能,数据块无需写回磁盘即可在各实例的缓存之间移动,从而避免了同步多实例的缓存所花费的额外I/O。这样对用户而言cache fusion就把多个实例的数据库缓冲区虚拟成一个数据库缓冲区,它实现了SGA对用户透明。很明显,不同的实例缓存的数据可以是不同的,也就是在一个实例要访问特定块之前,而它又从未访问过这个块,那么它要么从其他实例cache fusion过来,或者从磁盘中读入。整个Cache Fusion 有两个服务组成:GCS 和GES。 GCS 负责数据库在实例间的传递,GES 负责锁管理。Cache Fusion要解决的首要问题就是:数据块拷贝在集群节点间的状态分布图,这是通过GRD 实现的。
要发挥Cache Fusion的作用,要有一个前提条件,那就是互联网络的速度要比访问磁盘的速度要快!否则,没有引入Cache Fusion的意义。
GCS/GES
Global Cache Service全局缓存服务(GCS):要和Cache Fusion结合在一起来理解。全局缓存要涉及到数据块。全局缓存服务负责维护该全局缓冲存储区内的缓存一致性,确保一个实例在任何时刻想修改一个数据块时,都可获得一个全局锁资源,从而避免另一个实例同时修改该块的可能性。进行修改的实例将拥有块的当前版本(包括已提交的和未提交的事物)以及块的前象 (post image)。如果另一个实例也请求该块,那么全局缓存服务要负责跟踪拥有该块的实例、拥有块的版本是什么,以及块处于何种模式。GCS对应进程LMSn(processes global cache fusion requests)
Global Enqueue Service全局队列服务(GES):主要负责维护字典缓存和库缓存内的一致性。字典缓存是实例的SGA内所存储的对数据字典信息的缓存,用于高速访问。由于该字典信息 存储在内存中,因而在某个节点上对字典进行的修改(如DDL)必须立即被传播至所有节点上的字典缓存。GES负责处理上述情况,并消除实例间出现的差异。 处于同样的原因,为了分析影响这些对象的SQL语句,数据库内对象上的库缓存锁会被去掉。这些锁必须在实例间进行维护,而全局队列服务必须确保请求访问相 同对象的多个实例间不会出现死锁。GES对应进程LMON(issues heartbeates and performs recovery)
RAC的一些等待事件
gc buffer busy
即global cache buffer busy,产生的原因和单实例的 buffer busy waits 类似,就是一个时间点节点a的实例向节点b请求block的等待。主要是修改操作引起,而非读引起。
11g开始gc buffer busy分为gc buffer busy acquire和gc buffer busy release。
产生原因:热块,低效sql(越多的数据块请求到buffer cache 中,那么越可能造成别的会话等待。)数据交叉访问(RAC数据库,同一数据在不同数据库实例上被请求访问)所以RAC建议不同的应用功能在不同的数据库实例上被访问
gc buffer busy acquire是当session#1尝试请求访问远程实例(remote instance) buffer,但是在session#1之前已经有相同实例上另外一个session#2请求访问了相同的buffer,并且没有完成,那么session#1等待gc buffer busy acquire。
gc buffer busy release是在session#1之前已经有远程实例的session#2请求访问了相同的buffer,并且没有完成,那么session#1等待gc buffer busy release。
gcs log flush sync
GCS日志刷新同步
flush 是Oracle为了保证Instance Recovery实例恢复机制,而要求每一个current block在本地节点local instance被修改后(modify/update) 必须要将该current block相关的redo 写入到logfile 后(要求LGWR必须完成写入后才能返回),才能由LMS进程传输给其他节点使用。
The cause of this wait event 'gcs log flush sync' is mainly - Redo log IO performance.
RAC使用分布锁管理(DLM)机制对并发进行检测,用一个例子说明DLM作用
(1) 一个2节点的RAC
(2) 节点1想要修改数据1
(3) 节点1向DLM请求,DLM发现数据1还没有被任何节点使用,DLM就授权给节点1;并且DLM登记节点1对数据1的使用
(4) 节点2也想修改数据1
(5) 节点2向DLM请求,DLM发现数据1被节点1使用,DLM就会请求节点1“先给节点2用吧”,节点1接到请求后释放其对数据1的占用,节点2能够操作数据1
(6) DLM记录这个过程
需要强调的是DLM负责的是节点间的协调,而节点内的协调不是DLM负责,继续上面这个例子
(1) 现在节点2的进程1修改数据1
(2) 节点2的进程2也想修改数据1
(3) 节点2仍然请求DLM,DLM发现节点2现在已经有权限,无须授权
(4) 进程2对DLM的请求被通过,但是进程2是否能够修改数据1,还需要进一步检查
(5) 通过传统的锁模式,比如“行级锁”,进程2发现数据1正被进程1修改,所以进程2只能等待
所以学习RAC就是学习DLM,也就是Cache Fusion(内存融合)了
RAC集群实现并发机制过程:
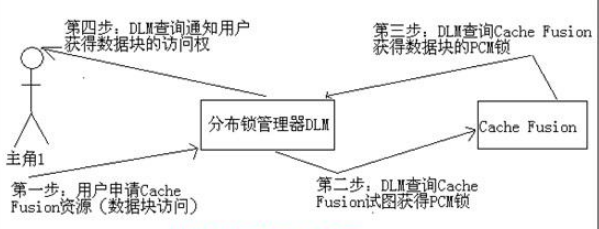
到此,关于“怎么理解并掌握RAC”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





