这篇文章将为大家详细讲解有关大量删除导致MySQL慢查的示例分析,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
一、背景
监控上收到了大量慢查的告警,业务也反馈查询很慢,随即打开电脑确认慢查的原因。
二、现象描述
通过平台的慢查分析之后,我们发现慢查有以下特征:
慢查的表名都是 sbtest1,没有其他的表;
大部分的慢查都是查表最新的数据,例如 select * from sbtest1 limit 1;
rows examined 为 1,没有扫描大量的数据。
三、问题分析
通对慢查的大致分析,SQL 本身没有发现问题。那么是不是主机或者网络等有问题呢?
经过对网络和主机磁盘的 IO 等的分析,负载均正常,没有丢包的现象。
回到数据库本身,慢查还在,确认下慢查到底是慢在哪里。
当慢查在执行的时候,大部分的都是表现在 Sending data 的状态,我们通过 profiling 去确认下慢查的时间分布:
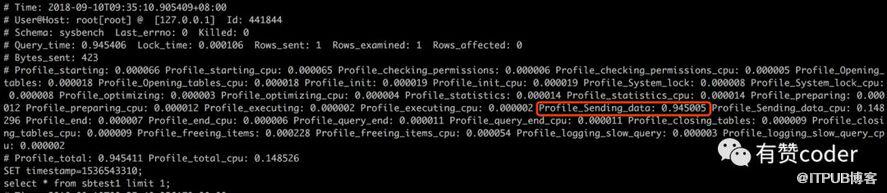
从图中,我们可以看到 sending data 耗费的时间为 0.945 秒,基本占据了 SQL 执行时间的99%。
那么 sending data 是什么意思呢,我们从官方文档里面了解下。
The thread is reading and processing rows for a SELECT statement, and sending data to the client. Because operations occurring during this state tend to perform large amounts of disk access (reads), it is often the longest-running state over the lifetime of a given query.
Sending data 表示在读取以及处理行数据以及发送数据到客户端,由于数据只有一行,且当时网络确认正常,那么时间就是耗费在读取和处理 select 的数据。
那为啥只取 limit 1,而且没有 where 条件的 SQL 执行扫描一行数据会这么慢呢?
打开监控,看看有没有啥指标异常。
我们注意到数据库的 History list length 这个指标一直在升高,达到了几万。慢查的执行时间是随着 History list length 升高而变的更慢。当 History list length 一直居高不下的时候,说明了有大量的 UNDO 没有被 purge。由于当前数据库的隔壁级别是 RR,开始比较早的事务,如果还没提交,就需要通过 UNDO 去构建对应版本历史时,保证数据库的可重复读(跟 MVCC 有关)。
既然 History list length 那么高,可能是有历史事务出现异常没有提交,也有可能是一致性快照的备份。可以通过 information_schema.innodb_trx 表去确认对应的事务信息。经过查询,的确发现一个事务执行了4个小时左右,没有提交,且不是备份用户。手动将该线程执行 kill 操作,慢查消失。
3.1 聊一下 MVCC
MySQL InnoDB 支持 MVCC 多版本,可以在普通的 SELECT 时不加锁。利用多版本读取指定版本的行记录,降低加锁的次数,能极大提高数据库的并发读写能力。
Innodb 在事务的某个时刻记录下 MySQL 所有的活跃事务列表,保存到 read view 里面。在之后的查询中,通过比较记录的事务ID和 read view 里面的事务列表,判断记录是否可见。
3.1.1 Innodb 行记录
在 Innodb 的行结构中,还存在三个系统列,分别是 DATA_ROW_ID、DATA_TRX_ID、DATA_ROLL_PTR。
DATA_ROW_ID: 如果表没有显示定义主键,则采用 MySQL 自己生成的 ROW_ID,为 48-bit,否则表示的是用户自定义的主键值;
DATA_TRX_ID:表示这条记录的事务 ID。如果是二级索引,只在 page 里面保存 trx_id;
DATA_ROLL_PTR: 指向对应的回滚段的指针。
3.1.2 read view
read view 是在 SQL 语句执行之前申请的,其中 RC 隔离级别是每个 SELECT 都会申请,RR 隔离级别的 read view 是事务开始之后的第一个 SQL 申请,之后事务内的其他 SQL 都使用该 read view。
read view 中有三个变量需要重点关注:
low_limit_id:表示的是创建 read view 那一刻活跃的事务列表的最大的事务 ID;
up_limit_id:表示的是创建 read view 那一刻活跃的事务列表的最小的事务 ID;
trx_ids:表示的创建 read view 那一刻所有的活跃事务列表。
3.1.3 判断记录可见
当记录的 DATA_TRX_ID 小于 read vew 的 up_limit_id,说明该记录在创建 read view 之前就已经提交,记录可见;
如果记录的 DATA_TRX_ID 和事务创建者的 TRX_ID 一样,记录可见;
当记录的 DATA_TRX_ID 大于 read view 的 up_limit_id,说明该记录在创建 read view 之后进行的新建事务修改提交的,记录不可见;
在 RR 隔离级别,如果 A 事务在 B 事务创建 read view 之前开始的,那么 B 事务里面的 SQL 是不能看到 A 事务执行的修改的。因此还有一条规则:如果记录对应的 DATA_TRX_ID 在 read view 的 trx_ids 里面,那么该记录也是不可见的。
3.1.4 DATA_ROLL_PTR
UNDO 日志是 MVCC 的重要组成部分,当一条数据被修改时,UNDO 日志里面保存了记录的历史版本。当事务需要查询记录的历史版本时,可以通过 UNDO 日志构建特定版本的数据。
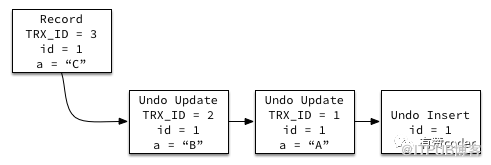
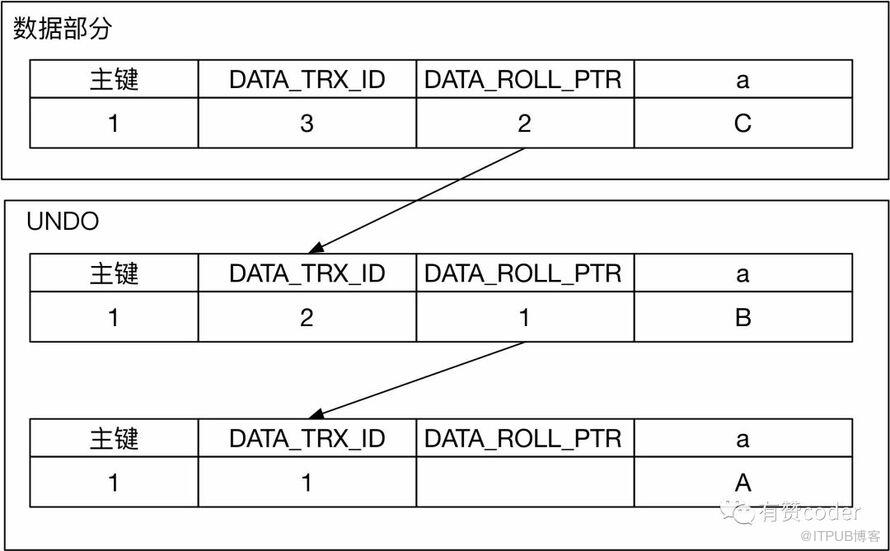
每条行记录上面都有一个指针 DATA_ROLL_PTR,指向最近的 UNDO 记录。同时每条 UNDO 记录包含一个指向前一个 UNDO 记录的指针,这样就构成了一条记录的所有 UNDO 历史的链表。当 UNDO 的记录还存在,那么对应的记录的历史版本就能被构建出来。
当记录对应的版本通过 DATA_TRX_ID 比对发现不可见时,通过系统列 DATA_ROLL_PTR,找到对应的回滚段记录,继续通过上述判断记录可见的规则,进行判断,如果记录依旧不可见,继续通过回滚段查找之前的版本,直到找到对应可见的版本。
3.2 慢查问题复现
经过和业务方沟通,得知该表每天都有定时任务,会删除历史数据。大致了解到整个过程后,我们搭建模拟环境进行测试。
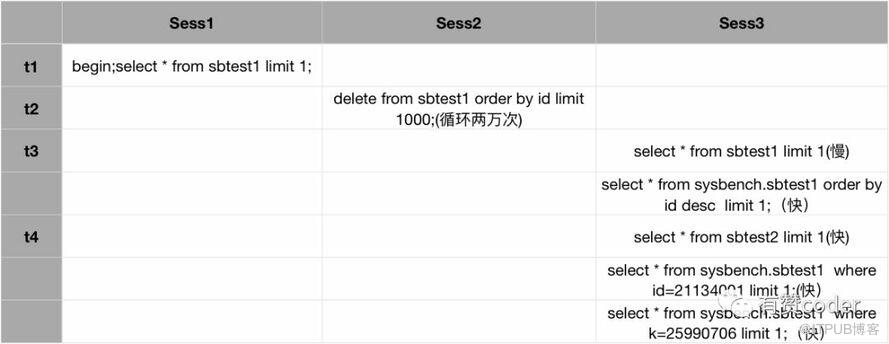
测试分为三个 session,其中 Sess1 执行长事务,没有提交。Sess2 对表的历史数据做清理,清理了 2000 万的数据。此时在 Sess3 执行查询,快慢情况如上图所示。select * from sbtest1 limit 1 跟预期表现一样,为很慢。但是 select * from sbtest1 order by id desc limit 1 执行很快,这是为什么呢?
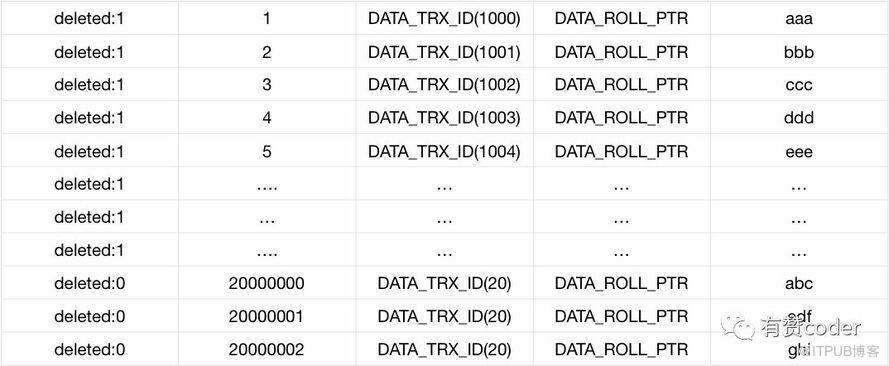
上图为主键的记录格式,在每条主键记录的前面有个删除标志位,然后是主键 ID,事务 ID,回滚段指针,最后是行记录。
当记录被执行删除的时候,MySQL 只是将记录标记为已删除,同时更新 DATA_TRX_ID 为自己删除会话的事务 ID,并没有将记录真正删除。当被删除的记录不再被其他事务需要的时候,会被 purge 线程删除。purge 线程负责清理这些真正被删除的记录以及不再需要的 UNDO 日志。
回到慢查本身,我们来看看慢查的执行过程。
SQL 为 select * from sbtest1 limit1。
通过主键,扫描到 ID=1 的记录,根据 MVCC 比对,发现自己的事务 ID 大于记录的 DATA_TRX_ID,匹配可见规则 1,记录可见;
由于 ID=1 已经被标记为 DELETED,删除记录可见;
由于表数据还没有全部扫描完成,未满足 limit 1,继续扫描下一条记录;
扫描到 ID=2 的记录,根据 MVCC 比对,发现自己的事务 ID 大于记录的 DATA_TRX_ID,匹配可见规则 1,记录可见;
由于 ID=2 已经被标记为 DELETED,删除记录可见;
由于表数据还没有全部扫描完成,未满足 limit 1,继续扫描下一条记录;
重复 4-6 步骤,直到满足找到一条记录,或者全表扫描完成。
由于被删除的记录有 2000 万,Innodb 需要扫描 2000 万的记录,才能找到符合条件的第一条记录,然后返回到 MySQL 的 Server 层。
当 SQL 为 select * from sbtest1 order by id desc limit1。
由于删除的是老数据,当从 ID 最大的方向开始扫描时,通过 MVCC 判断可见,然后判断记录是否被标记为删除的时候,记录没有被删除,因此就可以快速返回到 Server 层,SQL 执行效率就会很高。
关于“大量删除导致MySQL慢查的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





