本篇内容介绍了“怎么理解Oracle集群因子”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
集群因子(ClusteringFactor)是如果通过一个索引扫描一张表,需要访问的表的数据块的数量。衡量通过索引扫描,通过ROWID 回表的时候,物理读有多大。
集群因子是索引与它所基于的表相比较而得出的有序性度量,它用于检查在索引访问之后执行的表查找的成本(将集群因子与选择性相乘即可得到该操作的成本)。集群因子记录在扫描索引时将读取的块数量。
如果使用的索引具有较大的集群因子,则必须访问更多的表数据块才可以获得每个索引块中的行(因为邻近行位于不同的块中)。
如果集群因子接近于表中的块数量,则表示索引适当排序;但是,如果集群因子接近于表中的行数量,则表示索引没有适当排序
(1) 扫描一个索引;
(2) 比较某行的ROWID和前一行的ROWID,如果这两个ROWID不属于同一个数据块,那么ClusteringFactor增加1;
(3) 整个索引扫描完毕后,就得到了该索引的ClusteringFactor。
如果ClusteringFactor接近于表存储的块数,说明这张表是按照索引字段的顺序存储的。
如果集群因子接近于行的数量,那说明这张表不是按索引字段顺序存储的。
在计算索引访问成本时,集群因子十分有用。Clustering Factor乘以选择性参数(selectivity)就是访问索引的开销。
如果这个统计数据不能反映出索引的真实情况,那么可能会造成优化器错误地选择执行计划。另外,如果某张表上的大多数访问是按照某个索引做索引扫描,那么将该表的数据按照索引字段的顺序重新组织,可以提高该表的访问性能。
集群因子对执行范围扫描的SQL语句产生影响,如果集群因子接近数据块数量,满足查询要求的数据块的数量就可以少很多,这样也增加了数据块已经存在于内存中的可能性。相对于数据块数量大很多的集群因子,基于索引列的范围查询需要扫描更多的数据块。
我们知道可以通过dbms_rowid.rowid_block_number(rowid)找到记录对应的block 号。索引中记录了rowid,因此oracle 就可以根据索引中的rowid来判断记录是否是在同一个block 中。
举个例子,比如说索引中有a,b,c,d,e五个记录,首先比较a,b 是否在同一个block,如果不在同一个block 那么Clustering Factor +1,然后继续比较b,c 同理,如果b,c 不在同一个block,那么Clustering Factor+1,这样一直进行下去,直到比较了所有的记录。
根据算法我们就可以知道clustering factor 的值介于block 数和表行数之间。如果clustering factor 接近block 数,说明表的存储和索引存储排序接近,也就是说表中的记录很有序,这样在做index range scan 的时候能,读取少量的data block 就能得到我们想要的数据,代价比较小。如果clustering factor 接近表记录数,说明表的存储和索引排序差异很大,在做index range scan 的时候,会额外读取多个block,因为表记录分散,代价较高。
Clustering_factor列是user_indexes,dba_indexes视图中的一列,该列反应了数据相对已索引的列是否显得有序。
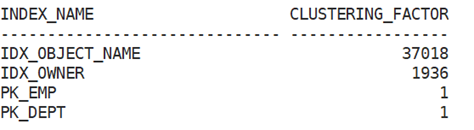 SQL> select index_name,CLUSTERING_FACTOR from user_indexes;
SQL> select index_name,CLUSTERING_FACTOR from user_indexes;
实验参考
https://blog.csdn.net/zhaoyangjian724/article/details/71082379
“怎么理解Oracle集群因子”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





