oracle btreeзҙўеј•жҰӮиҝ°
д»ҠеӨ©з ”究дёӢoracleзҡ„btreeзҙўеј•пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« дҪ дјҡдәҶи§ЈеҲ°пјҢoracle btreeзҙўеј•йғҪжңүе“ӘеҮ з§Қзұ»еһӢгҖҒoracle btreeзҙўеј•зҡ„е®һзҺ°еҺҹзҗҶпјҢoracleйҖҡиҝҮbtreeзҙўеј•жЈҖзҙўж•°жҚ®зҡ„иҝҮзЁӢгҖҒд»ҘеҸҠb*treeзҙўеј•зҡ„йҷҗеҲ¶пјҢ并且oracleе’Ң
mysqlзҡ„btreeзҙўеј•зҡ„еҢәеҲ«гҖӮ
дёҖпјҡoracleдёӯ btreeзҙўеј•зҡ„еӯҗзұ»еһӢ:
b*treeзҙўеј•жҳҜoracleд№ғиҮіеӨ§йғЁеҲҶе…¶д»–ж•°жҚ®еә“дёӯжңҖеёёз”Ёзҡ„зҙўеј•пјҢb*treeзҡ„жһ„йҖ зұ»дјјдәҺдәҢеҸүж ‘пјҢдҪҶжҳҜиҝҷйҮҢзҡ„вҖңBвҖқдёҚд»ЈиЎЁдәҢеҸүпјҲbinaryпјүпјҢиҖҢд»ЈиЎЁе№іиЎЎпјҲbalanced),b*treeзҙўеј•жңүд»ҘдёӢеӯҗзұ»еһӢпјҡ
1пјүзҙўеј•з»„з»ҮиЎЁпјҲindex organized table): зҙўеј•з»„з»ҮиЎЁд»ҘB*ж ‘з»“жһ„еӯҳеӮЁпјҢжҲ‘们зҹҘйҒ“oracleй»ҳи®Өзҡ„иЎЁжҳҜжҳҜе ҶиЎЁпјҢе ҶиЎЁжҳҜд»ҘдёҖз§Қж— з»„з»Үзҡ„ж–№ејҸеӯҳеӮЁзҡ„пјҲеҸӘиҰҒжңүеҸҜз”Ёзҡ„з©әй—ҙпјҢе°ұеҸҜд»Ҙж”ҫж•°жҚ®пјүпјҢиҖҢIOTдёҺд№ӢдёҚеҗҢпјҢIOTдёӯзҡ„ж•°жҚ®жҢүзқҖдё»й”®зҡ„йЎәеәҸеӯҳеӮЁе’ҢжҺ’еәҸзҡ„пјҢеҜ№дәҺеә”з”ЁжқҘиҜҙпјҢIOTиЎЁзҺ°еҫ—е’Ң常规зҡ„е ҶиЎЁе№¶ж— еҢәеҲ«пјҢйңҖиҰҒдҪҝз”ЁsqlжқҘжӯЈзЎ®зҡ„жқҘи®ҝй—®IOT, IOTеҜ№дҝЎжҒҜиҺ·еҸ–гҖҒз©әй—ҙзі»з»ҹе’ҢOLAPеә”з”ЁжңҖдёәжңүз”ЁпјҢз®ҖеҚ•зҡ„жҰӮиҝ°иө·жқҘпјҡзҙўеј•з»„з»ҮиЎЁ----зҙўеј•е°ұжҳҜж•°жҚ®пјҢж•°жҚ®е°ұжҳҜзҙўеј•пјҢеӣ дёәж•°жҚ®е°ұжҳҜжҢүзқҖB*ж ‘з»“жһ„еӯҳеӮЁзҡ„гҖӮ
2пјүb*treeиҒҡз°Үзҙўеј•пјҲB*tree cluster index):еҹәдәҺиҒҡз°Үй”®пјҲеҰӮ age=27пјүпјҢеңЁдј з»ҹзҡ„btreeзҙўеј•дёӯпјҢй”®йғҪжҢҮеҗ‘дёҖиЎҢпјҢиҖҢB*ж ‘иҒҡз°ҮдёҚеҗҢпјҢдёҖдёӘиҒҡз°Үй”®дјҡжҢҮеҗ‘дёҖдёӘеқ—пјҢе…¶дёӯеҢ…еҗ«дёҺиҝҷдёӘиҒҡз°Үй”®зӣёе…ізҡ„еӨҡиЎҢпјҢ
3)йҷҚеәҸзҙўеј•пјҡе…Ғи®ёж•°жҚ®еңЁзҙўеј•з»“жһ„дёӯжҢүвҖңд»ҺеӨ§еҲ°е°ҸвҖқзҡ„йЎәеәҸпјҲйҷҚеәҸпјүжҺ’еәҸпјҢиҖҢдёҚжҳҜвҖңд»Һе°ҸеҲ°еӨ§зҡ„йЎәеәҸпјҲеҚҮеәҸпјүжҺ’еәҸпјҢеҪ“дҪ жҹҘиҜўж•°жҚ®зҡ„ж—¶еҖҷпјҢжңҖеҗҺжҺ’еәҸoder by A desc,B ascзҡ„ж—¶еҖҷпјҢеҲӣе»әйҷҚеәҸзҙўеј•е°ұиғҪйҒҝе…ҚеҒҡжҳӮиҙөзҡ„жҺ’еәҸпјҲsort order by пјүж“ҚдҪңпјҢеҰӮдёӢиҜӯеҸҘеҲӣе»әпјҡ
SQL>create index idex_name on table_name(A desc,B asc);
4)еҸҚеҗ‘й”®зҙўеј•пјҲreverse key index):иҝҷд№ҹжҳҜ btreeзҙўеј•пјҢеҸӘдёҚиҝҮй”®зҡ„еӯ—иҠӮдјҡвҖңеҸҚиҪ¬вҖқпјҢеҲ©з”ЁеҸҚеҗ‘й”®зҙўеј•пјҢеҰӮжһңзҙўеј•дёӯеЎ«е……зҡ„жҳҜйҖ’еўһзҡ„еҖјпјҢзҙўеј•жқЎзӣ®еңЁзҙўеј•дёӯеҸҜд»Ҙеҫ—еҲ°жӣҙеқҮеҢҖзҡ„еҲҶеёғпјӣдё»иҰҒжҳҜи§ЈеҶівҖңеҸідҫ§вҖқзҙўеј•еҸ¶еӯҗеқ—зҡ„з«һдәүпјҢжҜ”еҰӮеңЁдёҖдёӘoracle RACзҡ„зҺҜеўғдёӯпјҢжҹҗдәӣеҲ—з”ЁдёҖдёӘеәҸеҲ—еҖјжҲ–иҖ…ж—¶й—ҙжҲіеЎ«е……пјҢиҝҷдәӣеҲ—дёҠе»әз«Ӣзҙўеј•е°ұеұһдәҺвҖңеҸідҫ§вҖқзҙўеј•пјҢд№ҹе°ұжҳҜж•°жҚ®еҲҶеёғзҡ„зӣёеҜ№жҜ”иҫғйӣҶдёӯгҖӮдҪҝз”ЁеҸҚеҗ‘зҙўеј•жңҖеӨ§зҡ„дјҳзӮ№иҺ«иҝҮдәҺйҷҚдҪҺзҙўеј•еҸ¶еӯҗеқ—зҡ„дәүз”ЁпјҢеҮҸе°‘зҙўеј•зғӯзӮ№еқ—пјҢжҸҗй«ҳзі»з»ҹжҖ§иғҪгҖӮ
1.еҸҚеҗ‘зҙўеј•еә”з”ЁеңәеҗҲ
1пјүеҸ‘зҺ°зҙўеј•еҸ¶еқ—жҲҗдёәзғӯзӮ№еқ—ж—¶дҪҝз”Ё
йҖҡеёёпјҢдҪҝз”Ёж•°жҚ®ж—¶пјҲеёёи§ҒдәҺжү№йҮҸжҸ’е…Ҙж“ҚдҪңпјүйғҪжҜ”иҫғйӣҶдёӯеңЁдёҖдёӘиҝһз»ӯзҡ„ж•°жҚ®иҢғеӣҙеҶ…пјҢйӮЈд№ҲеңЁдҪҝз”ЁжӯЈеёёзҡ„зҙўеј•ж—¶е°ұеҫҲе®№жҳ“еҸ‘з”ҹзҙўеј•еҸ¶еӯҗеқ—иҝҮзғӯзҡ„зҺ°иұЎпјҢдёҘйҮҚж—¶е°ҶдјҡеҜјиҮҙзі»з»ҹжҖ§иғҪдёӢйҷҚгҖӮ
2пјүеңЁRACзҺҜеўғдёӯдҪҝз”Ё
еҪ“RACзҺҜеўғдёӯеҮ дёӘиҠӮзӮ№и®ҝй—®ж•°жҚ®зҡ„зү№зӮ№жҳҜйӣҶдёӯе’ҢеҜҶйӣҶпјҢзҙўеј•зғӯзӮ№еқ—еҸ‘з”ҹзҡ„еҮ зҺҮе°ұдјҡеҫҲй«ҳгҖӮеҰӮжһңзі»з»ҹеҜ№иҢғеӣҙжЈҖзҙўиҰҒжұӮдёҚжҳҜеҫҲй«ҳзҡ„жғ…еҶөдёӢеҸҜд»ҘиҖғиҷ‘дҪҝз”ЁеҸҚеҗ‘зҙўеј•жҠҖжңҜжқҘжҸҗй«ҳзі»з»ҹзҡ„жҖ§иғҪгҖӮеӣ жӯӨиҜҘжҠҖжңҜеӨҡи§ҒдәҺRACзҺҜеўғпјҢе®ғеҸҜд»Ҙжҳҫи‘—зҡ„йҷҚдҪҺзҙўеј•еқ—зҡ„дәүз”ЁгҖӮ
2.дҪҝз”ЁеҸҚеҗ‘зҙўеј•зҡ„зјәзӮ№
з”ұдәҺеҸҚеҗ‘зҙўеј•з»“жһ„иҮӘиә«зҡ„зү№зӮ№пјҢеҰӮжһңзі»з»ҹдёӯз»ҸеёёдҪҝз”ЁиҢғеӣҙжү«жҸҸиҝӣиЎҢиҜ»еҸ–ж•°жҚ®зҡ„иҜқпјҲдҫӢеҰӮеңЁwhereеӯҗеҸҘдёӯдҪҝз”ЁвҖңbetween andвҖқиҜӯеҸҘжҲ–жҜ”иҫғиҝҗз®—з¬ҰвҖң>вҖқвҖң<вҖқзӯүпјүпјҢйӮЈд№ҲеҸҚеҗ‘зҙўеј•е°ҶдёҚйҖӮз”ЁпјҢеӣ дёәжӯӨж—¶дјҡеҮәзҺ°еӨ§йҮҸзҡ„е…ЁиЎЁжү«жҸҸзҡ„зҺ°иұЎпјҢеҸҚиҖҢдјҡйҷҚдҪҺзі»з»ҹзҡ„жҖ§иғҪгҖӮ
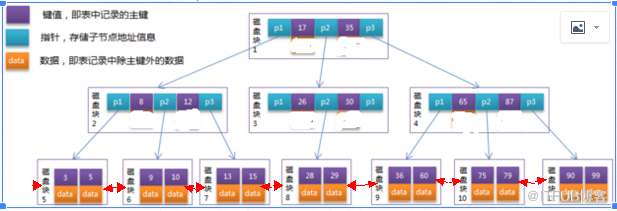
дәҢпјҡoracleдёӯBTreeзҙўеј•зҡ„е®һзҺ°еҺҹзҗҶпјҡдёҖдёӘз»Ҹе…ёзҡ„BTreeзҙўеј•зҡ„з»“жһ„еҰӮдёӢеӣҫпјҡ
жҜҸдёӘиҠӮзӮ№еҚ з”ЁдёҖдёӘзЈҒзӣҳеқ—зҡ„зЈҒзӣҳз©әй—ҙпјҢдёҖдёӘиҠӮзӮ№дёҠжңүnдёӘеҚҮеәҸжҺ’еәҸзҡ„е…ій”®еӯ—е’ҢпјҲn+1)дёӘжҢҮеҗ‘еӯҗж ‘ж №иҠӮзӮ№зҡ„жҢҮй’ҲпјҲдёҠеӣҫдёӯе…ій”®еӯ—дёә51,101,151.гҖӮгҖӮгҖӮгҖӮпјҢ然еҗҺ0еҲ°50 еҜ№еә”дёҖдёӘжҢҮй’ҲпјҢ51еҲ°100еҜ№еә”дёҖдёӘжҢҮй’ҲпјүпјҢиҝҷдёӘжҢҮй’ҲеӯҳеӮЁзҡ„жҳҜеӯҗиҠӮзӮ№жүҖеңЁзЈҒзӣҳеқ—зҡ„ең°еқҖпјҲжіЁж„ҸиҝҷйҮҢзҡ„nжҳҜеҲӣе»әзҙўеј•зҡ„ж—¶еҖҷпјҢж №жҚ®ж•°жҚ®йҮҸи®Ўз®—еҮәжқҘзҡ„пјҢеҰӮжһңж•°жҚ®йҮҸеӨӘеӨ§дәҶпјҢдёүеұӮзҡ„еҸҜиғҪе°ұж»Ўи¶ідёҚдәҶпјҢе°ұйңҖиҰҒеӣӣеұӮзҡ„B+treeпјү,然еҗҺnдёӘе…ій”®еӯ—еҲ’еҲҶжҲҗпјҲn+1)дёӘиҢғеӣҙеҹҹпјҢ然еҗҺжҜҸдёӘиҢғеӣҙеҹҹеҜ№еә”дёҖдёӘжҢҮй’ҲпјҢжқҘжҢҮеҗ‘еӯҗиҠӮзӮ№пјҢеӯҗиҠӮзӮ№еҸҲд»Һж–°ж №жҚ®е…ій”®еӯ—еҶҚж¬ЎеҲ’еҲҶпјҢ然еҗҺжҢҮй’ҲжҢҮеҗ‘еҸ¶еӯҗиҠӮзӮ№пјҢ并且жүҖжңүзҡ„еҸ¶еӯҗиҠӮзӮ№йғҪеңЁж ‘зҡ„еҗҢдёҖеұӮдёҠпјҢиҝҷиҜҙжҳҺжүҖжңүзҡ„д»Һзҙўеј•ж №иҠӮзӮ№еҲ°еҸ¶еӯҗиҠӮзӮ№зҡ„йҒҚеҺҶйғҪдјҡи®ҝй—®еҗҢж ·ж•°зӣ®зҡ„еқ—пјҢд№ҹе°ұжҳҜиҜҙдјҡжү§иЎҢеҗҢж ·ж•°зӣ®зҡ„I/O,жҚўиЁҖд№Ӣзҙўеј•жҳҜй«ҳеәҰе№іиЎЎзҡ„пјҢ
дёҠеӣҫе°ұжҳҜ 0...50еҜ№еә”дёҖдёӘжҢҮй’ҲпјҢжҢҮеҗ‘дёҖдёӘеӯҗиҠӮзӮ№пјӣ51...100еҜ№еә”дёҖдёӘжҢҮй’ҲпјҢжҢҮеҗ‘еҸҰдёҖдёӘеӯҗиҠӮзӮ№пјҢ然еҗҺеӯҗиҠӮзӮ№еҸҲж №жҚ®е…ій”®еӯ—еҲ’еҲҶеҢәеҹҹпјҢ并з”ұжҢҮй’ҲжҢҮеҗ‘еҸ¶еӯҗз»“зӮ№пјҢеҖјеҫ—жіЁж„Ҹзҡ„жҳҜoracle B*ж ‘зҙўеј•еӯҳж•°жҚ®зҡ„жҳҜеҸ¶еӯҗиҠӮзӮ№пјҲжҲ–иҖ…еҸ«еҸ¶еӯҗеқ—пјүпјӣеӯҳзҡ„жҳҜзҙўеј•й”®еҖјпјҲжҲ–иҖ…еҸ«зҙўеј•зҡ„еҲ—еҖј)е’ҢдёҖдёӘrowid(жҢҮеҗ‘жүҖзҙўеј•зҡ„иЎҢзҡ„дёҖдёӘжҢҮй’ҲжҲ–иҖ…иҜҙеҸ«зү©зҗҶдҪҚзҪ®пјүпјҢ然еҗҺеҰӮдёҠеӣҫжүҖзӨәпјҢеҸ¶еӯҗиҠӮзӮ№д№Ӣй—ҙжңүеҸҢеҗ‘й“ҫиЎЁпјҢе°ұжҳҜдёәдәҶжҸҗй«ҳзҙўеј•иҢғеӣҙжү«жҸҸзҡ„ж•ҲзҺҮпјҢеӣ дёәзҙўеј•еҖјзҡ„еҲ—еҖјжҳҜжңүеәҸзҡ„пјҢжүҫеҲ°дәҶиө·е§ӢеҖјеҗҺпјҢзӣҙжҺҘе°ұеҸҜд»ҘжңүеәҸзҡ„еҺ»зӣёйӮ»дёӯжүҫеҲ°дёӢдёҖдёӘеҖјпјҢдҫӢеҰӮ where id between 10 and 20 ,oracle еҸ‘зҺ°з¬¬дёҖдёӘжңҖе°Ҹй”®еҖјеӨ§дәҺжҲ–зӯүдәҺ10зҡ„зҙўеј•еҸ¶еӯҗеқ—пјҢ然еҗҺж°ҙе№іең°йҒҚеҺҶеҸ¶еӯҗиҠӮзӮ№й“ҫиЎЁпјҢзӣҙеҲ°жңҖеҗҺдёҖдёӘеӨ§дәҺ20зҡ„еҖјпјӣ
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҡB*зҙўеј•дёӯдёҚеӯҳеңЁйқһе”ҜдёҖйҷҗеҲ¶пјҢд№ҹе°ұжҳҜиҜҙйқһе”ҜдёҖеҲ—дёҠд№ҹеҸҜд»ҘеҲӣе»әB*зҙўеј•пјҢдҪҶжҳҜеңЁдёҖдёӘйқһе”ҜдёҖзҙўеј•дёӯпјҢoracleдјҡжҠҠrowidдҪңдёәдёҖдёӘйўқеӨ–зҡ„еҲ—пјҲжңүдёҖдёӘй•ҝеәҰеӯ—иҠӮпјүиҝҪеҠ еҲ°й”®дёҠпјҢдҪҝеҫ—й”®е”ҜдёҖпјҢдҫӢеҰӮжңүдёҖдёӘcreate index index_name on table( x ,y)зҙўеј•пјҢд»ҺжҰӮеҝөдёҠиҜҙпјҢд»–е°ұжҳҜcreate unique index index_name on table( x ,y,rowid).еңЁдёҖдёӘе”ҜдёҖзҙўеј•дёӯпјҢж №жҚ®дҪ е®ҡд№үзҡ„е”ҜдёҖжҖ§пјҢoracle дёҚдјҡеҶҚеҗ‘зҙўеј•й”®еўһеҠ rowid,еңЁйқһе”ҜдёҖзҙўеј•дёӯпјҢдҪ дјҡеҸ‘зҺ°пјҢж•°жҚ®дјҡйҰ–е…ҲжҢүзҙўеј•й”®еҖјжҺ’еәҸпјҢ然еҗҺжҢүrowidеҚҮеәҸжҺ’еәҸпјҢиҖҢеңЁе”ҜдёҖзҙўеј•дёӯпјҢж•°жҚ®еҸӘжҢүзқҖзҙўеј•й”®еҖјжҺ’еәҸпјӣ
дёүпјҡдҪҝз”ЁB*ж ‘зҙўеј•жЈҖзҙўж•°жҚ®зҡ„иҝҮзЁӢгҖӮ
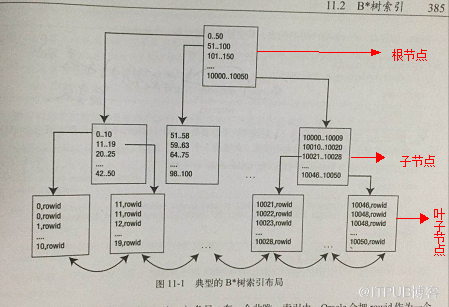
й’ҲеҜ№дёӢеӣҫB+treeзҙўеј•зҡ„еҺҹзҗҶпјҲдҝ®ж”№иҮӘзҪ‘з»ңпјүпјҡ
然еҗҺй’ҲеҜ№дёҠеӣҫжЁЎжӢҹдёӢ where id=29зҡ„е…·дҪ“иҝҮзЁӢпјҡгҖӮ
йҰ–е…Ҳж №жҚ®ж №иҠӮзӮ№жүҫеҲ°зЈҒзӣҳеқ—1пјҢиҜ»е…ҘеҶ…еӯҳгҖӮгҖҗзЈҒзӣҳI/Oж“ҚдҪң第1ж¬ЎгҖ‘
жҜ”иҫғе…ій”®еӯ—29еңЁеҢәй—ҙпјҲ17,35пјүпјҢжүҫеҲ°зЈҒзӣҳеқ—1зҡ„жҢҮй’ҲP2гҖӮ
ж №жҚ®P2жҢҮй’ҲжүҫеҲ°зЈҒзӣҳеқ—3пјҢиҜ»е…ҘеҶ…еӯҳгҖӮгҖҗзЈҒзӣҳI/Oж“ҚдҪң第2ж¬ЎгҖ‘
жҜ”иҫғе…ій”®еӯ—29еңЁеҢәй—ҙпјҲ26,30пјүпјҢжүҫеҲ°зЈҒзӣҳеқ—3зҡ„жҢҮй’ҲP2гҖӮ
ж №жҚ®P2жҢҮй’ҲжүҫеҲ°зЈҒзӣҳеқ—8пјҢиҜ»е…ҘеҶ…еӯҳгҖӮгҖҗзЈҒзӣҳI/Oж“ҚдҪң第3ж¬ЎгҖ‘
еңЁзЈҒзӣҳеқ—8дёӯзҡ„е…ій”®еӯ—еҲ—иЎЁдёӯжүҫеҲ°е…ій”®еӯ—29гҖӮ
еҲҶжһҗдёҠйқўиҝҮзЁӢпјҢеҸ‘зҺ°йңҖиҰҒ3ж¬ЎзЈҒзӣҳI/Oж“ҚдҪңпјҢе’Ң3ж¬ЎеҶ…еӯҳжҹҘжүҫж“ҚдҪңгҖӮз”ұдәҺеҶ…еӯҳдёӯзҡ„е…ій”®еӯ—жҳҜдёҖдёӘжңүеәҸиЎЁз»“жһ„пјҢеҸҜд»ҘеҲ©з”ЁдәҢеҲҶжі•жҹҘжүҫжҸҗй«ҳж•ҲзҺҮгҖӮиҖҢ3ж¬ЎзЈҒзӣҳI/Oж“ҚдҪңжҳҜеҪұе“Қж•ҙдёӘB-TreeжҹҘжүҫж•ҲзҺҮзҡ„еҶіе®ҡеӣ зҙ гҖӮ
еӣӣпјҡoracleb*treeзҙўеј•зҡ„йҷҗеҲ¶
1пјүеңЁзҙўеј•еҲ—дёҠдҪҝз”ЁеҮҪж•°гҖӮеҰӮSUBSTR,DECODE,INSTRзӯүпјҢеҜ№зҙўеј•еҲ—иҝӣиЎҢиҝҗз®—.йңҖиҰҒе»әз«ӢеҮҪж•°зҙўеј•е°ұеҸҜд»Ҙи§ЈеҶідәҶгҖӮ
дҫӢеҰӮпјҡиЎЁdeptпјҢжңүcol_1,col_2,зҺ°еңЁеҜ№col_1еҒҡupperеҮҪж•°зҙўеј• еҰӮдёӢпјҡ
CREATE INDEX index_name ON dept(upper(col_1));
еҮҪж•°зҙўеј•жҳҜеҹәдәҺд»Јд»·зҡ„дјҳеҢ–ж–№ејҸ-CBOпјҢпјҲеңЁOracle8еҸҠд»ҘеҗҺзҡ„зүҲжң¬,OracleејәеҲ—жҺЁиҚҗз”ЁCBOзҡ„ж–№ејҸпјҢиҖҢйқһRBOпјү,жүҖд»ҘиЎЁеҝ…йЎ»з»ҸиҝҮanalyzeжүҚеҸҜд»ҘдҪҝз”ЁпјҢжҲ–иҖ…дҪҝз”ЁhintsжүҚеҸҜд»Ҙ пјӣ
2пјүж–°е»әзҡ„иЎЁиҝҳжІЎжқҘеҫ—еҸҠз”ҹжҲҗз»ҹи®ЎдҝЎжҒҜпјҢеҲҶжһҗдёҖдёӢе°ұеҘҪдәҶпјҢжҲ‘们зҹҘйҒ“oracleдјҳеҢ–еҷЁжҳҜеҹәдәҺз»ҹи®ЎдҝЎжҒҜжқҘеҲӨж–ӯжү§иЎҢи®ЎеҲ’зҡ„пјҢеҰӮжһңз»ҹи®ЎдҝЎжҒҜдёҚеҮҶзЎ®пјҢйӮЈд№ҲoracleеҸҜиғҪдјҡеҒҡеҮәдёҚиө°зҙўеј•зҡ„жү§иЎҢи®ЎеҲ’гҖӮ
3пјүoracleдјҳеҢ–еҷЁcboжҳҜеҹәдәҺcostзҡ„жҲҗжң¬еҲҶжһҗпјҢи®ҝй—®зҡ„иЎЁиҝҮе°ҸпјҢдҪҝз”Ёе…ЁиЎЁжү«жҸҸзҡ„ж¶ҲиҖ—е°ҸдәҺдҪҝз”Ёзҙўеј•гҖӮ
4пјүдҪҝз”Ё<>гҖҒnot in гҖҒnot existпјҢеҜ№дәҺиҝҷдёүз§Қжғ…еҶөдёӯеӨ§еӨҡж•°жғ…еҶөдёӢи®Өдёәз»“жһңйӣҶеҫҲеӨ§пјҢдёҖиҲ¬еӨ§дәҺ5%-15%е°ұдёҚиө°зҙўеј•иҖҢиө°е…ЁиЎЁжү«жҸҸпјҲFTS)гҖӮ
5) like "%_" зҷҫеҲҶеҸ·еңЁеүҚгҖӮ
6) еҚ•зӢ¬еј•з”ЁеӨҚеҗҲзҙўеј•йҮҢйқһ第дёҖдҪҚзҪ®зҡ„зҙўеј•еҲ—,oracleе’ҢmysqlдёҖж ·пјҢbtreeзҙўеј•йғҪжҳҜжңҖе·ҰеҢ№й…ҚеҺҹеҲҷпјҢеҪ“дҪ еҲӣе»әз»„еҗҲзҙўеј•пјҲAпјҢBпјҢCпјүзӣёеҪ“дәҺеҲӣе»әдәҶ(A)гҖҒ (A,B)гҖҒпјҲAпјҢBпјҢC)дёүдёӘзҙўеј•пјӣ
7пјүеӯ—з¬ҰеһӢеӯ—ж®өдёәж•°еӯ—ж—¶еңЁwhereжқЎд»¶йҮҢдёҚж·»еҠ еј•еҸ·пјҢиҝҷйҮҢoracleеҶ…йғЁдҪҝз”ЁеҮҪж•°еҒҡйҡҗеЈ«иҪ¬жҚўпјҢжүҖд»ҘеҸҜд»ҘеҪ’з»“дёә第дёҖзұ»пјҢдҪҝз”ЁеҮҪж•°еҜјиҮҙзҙўеј•еӨұж•ҲпјҢеҖјеҫ—жіЁж„Ҹзҡ„жҳҜпјҡVARCHAR2->NUMBERзҡ„йҡҗејҸиҪ¬жҚўпјҢеҸҜд»Ҙиө°зҙўеј•пјӣNUMBER->VARCHAR2зҡ„йҡҗејҸиҪ¬жҚўпјҢе°ұеҜјиҮҙзҙўеј•еӨұж•ҲдәҶгҖӮпјҲVARCHAR2->NUMBERдёҚдјҡи®©зҙўеј•еӨұж•ҲпјҢеҸҜд»ҘзҗҶи§ЈжҲҗиҪ¬жҚўдёәwhere id = to_number('123')гҖӮNUMBER->VARCHAR2дјҡи®©зҙўеј•еӨұж•ҲпјҢжҲ‘зҢңжөӢжҳҜиҪ¬жҚўдёәwhere to_number(name) = 123пјү
8пјүеҪ“еҸҳйҮҸйҮҮз”Ёзҡ„жҳҜtimesеҸҳйҮҸпјҢиҖҢиЎЁзҡ„еӯ—ж®өйҮҮз”Ёзҡ„жҳҜdateеҸҳйҮҸж—¶.жҲ–зӣёеҸҚжғ…еҶөгҖӮ
9)зҙўеј•еӨұж•ҲпјҲINVALID)пјҢеҸҜд»ҘиҖғиҷ‘йҮҚе»әзҙўеј•пјҢalterгҖҖindexгҖҖindex_name rebuild online;гҖӮ
10)B-treeзҙўеј• is nullдёҚдјҡиө°,is not nullдјҡиө°;
дә”пјҡoracleе’Ңmysqlзҡ„btreeзҙўеј•зҡ„еҢәеҲ«
е…¶е®һoracleе’Ңmysqlзҡ„btreeзҙўеј•з»“жһ„е’ҢеҺҹзҗҶеҫҲзӣёдјјпјҢеҸӘжҳҜoracleеҸ¶еӯҗиҠӮзӮ№еӯҳеӮЁзҡ„жҳҜй”®еҖј+rowidпјҢmysqlзҡ„зҙўеј•еҸ¶еӯҗз»“зӮ№еӯҳеӮЁзҡ„еҶ…е®№еӣ еӯҳеӮЁеј•ж“ҺдёҚеҗҢиҖҢдёҚеҗҢпјҢиҝҳжңүдё»й”®зҙўеј•е’ҢдәҢзә§зҙўеј•д№ӢеҲҶеҰӮдёӢпјҡ
oracleеҸ¶еӯҗиҠӮзӮ№еӯҳеӮЁзҡ„жҳҜй”®еҖј+rowid
MyISAMеј•ж“Һдёӯleaf nodeеӯҳеӮЁзҡ„еҶ…е®№:
дё»й”®зҙўеј• пјҡд»…д»…еӯҳеӮЁиЎҢжҢҮй’Ҳпјӣ
дәҢзә§зҙўеј•пјҡд»…д»…жҳҜиЎҢжҢҮй’Ҳпјӣ
InnoDBеј•ж“Һдёӯleaf nodeеӯҳеӮЁзҡ„еҶ…е®№
дё»й”®зҙўеј• пјҡиҒҡйӣҶзҙўеј•еӯҳеӮЁе®Ңж•ҙзҡ„ж•°жҚ®пјҲж•ҙиЎҢж•°жҚ®пјүпјҲзұ»дјјдәҺoracleзҡ„зҙўеј•з»„з»ҮиЎЁпјү
дәҢзә§зҙўеј•пјҡеӯҳеӮЁзҙўеј•еҲ—еҖј+дё»й”®дҝЎжҒҜ
жҖ»з»“пјҡ
зҙўеј•иғҪжҸҗй«ҳжЈҖзҙўж•°жҚ®зҡ„ж•ҲзҺҮпјҢдҪҶжҳҜзҙўеј•зҡ„е»әз«Ӣеҝ…йЎ»ж…ҺйҮҚпјҢеҜ№жҜҸдёӘзҙўеј•зҡ„еҝ…иҰҒжҖ§йғҪеә”иҜҘз»ҸиҝҮд»”з»ҶеҲҶжһҗпјҢиҰҒжңүе»әз«Ӣзҡ„дҫқжҚ®гҖӮеӣ дёәеӨӘеӨҡзҡ„зҙўеј•дёҺдёҚе……еҲҶгҖҒдёҚжӯЈзЎ®зҡ„зҙўеј•еҜ№жҖ§иғҪйғҪжҜ«ж— зӣҠеӨ„пјҡеңЁиЎЁдёҠе»әз«Ӣзҡ„жҜҸдёӘзҙўеј•йғҪдјҡеўһеҠ еӯҳеӮЁејҖй”ҖпјҢзҙўеј•еҜ№дәҺжҸ’е…ҘгҖҒеҲ йҷӨгҖҒжӣҙж–°ж“ҚдҪңд№ҹдјҡеўһеҠ еӨ„зҗҶдёҠзҡ„ејҖй”ҖгҖӮеҸҰеӨ–пјҢиҝҮеӨҡзҡ„еӨҚеҗҲзҙўеј•пјҢеңЁжңүеҚ•еӯ—ж®өзҙўеј•зҡ„жғ…еҶөдёӢпјҢдёҖиҲ¬йғҪжҳҜжІЎжңүеӯҳеңЁд»·еҖјзҡ„пјӣзӣёеҸҚпјҢиҝҳдјҡйҷҚдҪҺж•°жҚ®еўһеҠ еҲ йҷӨж—¶зҡ„жҖ§иғҪпјҢзү№еҲ«жҳҜеҜ№йў‘з№Ғжӣҙж–°зҡ„иЎЁжқҘиҜҙпјҢиҙҹйқўеҪұе“ҚжӣҙеӨ§гҖӮ