-
功夫不负有心人,翻到了如下关键说明,大意是说,在基于GTID复制模式下转换为基于文件复制协议时,可以使用change master to
master_auto_position=0语句,并且要指定MASTER_LOG_FILE和MASTER_LOG_POS选项(经验证,如果不指定MASTER_LOG_FILE和MASTER_LOG_POS选项,则执行change
master语句时,那么SQL线程位置以IO线程位置为准,如果指定了MASTER_LOG_FILE和MASTER_LOG_POS选项,则IO线程位置以SQL线程位置为准),在5.7.4版本之后,使用change
master to …语句时,如果IO和SQL线程都处于停止状态,那么将会删除所有的relay
log文件,除非你同时指定了RELAY_LOG_FILE和RELAY_LOG_POS选项(经验证,只要不指定RELAY_LOG_FILE和RELAY_LOG_POS选项就会删除当前所有的relay
log,无论其他选项如何指定):

-
也就是说,我们使用change master
语句的时候,只使用master_auto_position选项而不指定MASTER_LOG_FILE和MASTER_LOG_POS选项本身就是一种不规范的行为,再加上没有指定RELAY_LOG_FILE和RELAY_LOG_POS选项,导致relay
log被清理了,我们知道,在前面执行stop slave;语句时,我们可以看到还有复制延迟的(Seconds_Behind_Master:
47),也就是说,这部分复制延迟的relay log被清理可能就是导致worker线程发生错误的原因(缺失的GTID
EVENT就记录在被清理的relay log中)
-
现在,原因我们应该找到了,但是还需要进一步确认,但根据目前的犯罪现场,已经调查不下去了,我们需要把复制先恢复之后,重新复现并在每一个步骤查看尽可能全面的信息以进行诊断。
-
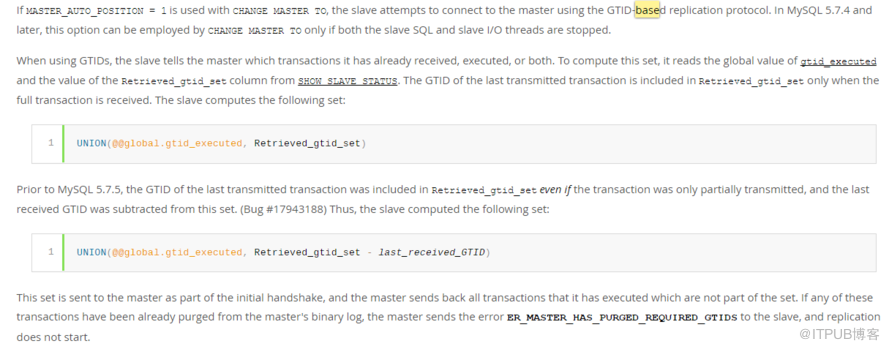
要恢复复制环境,我们可以把master_auto_position设置为1,根据GTID复制协议,设置为1启动复制时,会根据公式"UNION(@@global.gtid_executed,
Retrieved_gtid_set - last_received_GTID)"自动计算IO线程重新向主库请求binlog的GTID
SET,告诉主库自己当前已经执行了哪些事务,主库会把从库缺失的事务发送给从库。所以理论上只需要把master_auto_position设置为1启动的复制就可以恢复正常。
-
admin@localhost : sbtest 09:52:41> stop slave;
-
Query OK, 0 rows affected (0.00 sec)
-
admin@localhost : sbtest 09:52:47> change master to master_auto_position=1;
-
Query OK, 0 rows affected (0.02 sec)
-
admin@localhost : sbtest 09:53:01> start slave;
-
Query OK, 0 rows affected (0.02 sec)
-
admin@localhost : sbtest 09:53:11> show slave status\G;
-
*************************** 1. row ***************************
-
Slave_IO_State: Waiting for master to send event
-
......
-
Master_Log_File: mysql-bin.000036
-
Read_Master_Log_Pos: 127589755
-
Relay_Log_File: mysql-relay-bin.000002
-
Relay_Log_Pos: 849241
-
Relay_Master_Log_File: mysql-bin.000036
-
Slave_IO_Running: Yes
-
Slave_SQL_Running: Yes
-
......
-
Exec_Master_Log_Pos: 102801341
-
......
-
Seconds_Behind_Master: 3075
-
Master_SSL_Verify_Server_Cert: No
-
Last_IO_Errno: 0
-
Last_IO_Error:
-
Last_SQL_Errno: 0
-
Last_SQL_Error:
-
......
-
Last_IO_Error_Timestamp:
-
Last_SQL_Error_Timestamp:
-
......
-
Retrieved_Gtid_Set: b57c75c2-6205-11e7-8d9f-525400a4b2e1:710876-741652
-
Executed_Gtid_Set: b57c75c2-6205-11e7-8d9f-525400a4b2e1:1-711894
-
Auto_Position: 1
-
...
-
1 row in set (0.01 sec)