google chrome团队出品的puppeteer 是依赖nodejs和chromium的自动化测试库,它的最大优点就是可以处理网页中的动态内容,如JavaScript,能够更好的模拟用户。
有些网站的反爬虫手段是将部分内容隐藏于某些javascript/ajax请求中,致使直接获取a标签的方式不奏效。甚至有些网站会设置隐藏元素“陷阱”,对用户不可见,脚本触发则认为是机器。这种情况下,puppeteer的优势就凸显出来了。
它可实现如下功能:
开源地址:[https://github.com/GoogleChrome/puppeteer/][1]
npm i puppeteer注意先安装nodejs, 并在nodejs文件根目录下执行(npm文件同级)。
安装过程中会下载chromium,大约120M。
用两天(大约10小时)摸索,绕过了相当多的异步的坑,笔者对puppeteer和nodejs有了一定的掌握。
一张长图,抓取blog文章列表: 
以csdn blog为例,文章内容需要点击“阅读全文”来获取,这就导致只能读取dom的脚本失效。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; i<makLoop;i++){
try{
await page.evaluate(()=>window.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h3 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl<hrefs.length){
url = hrefs[countUrl];
countUrl++;
}else{
browser.close();
return;
}
console.log('processing url: '+url);
try{
const tab = await browser.newPage();
await tab.setUserAgent(userAgent);
await tab.setViewport({width:414, height:736});
await tab.setRequestInterception(true);
//filter to block images
tab.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
录屏可以在我公众号查看,下边是截图:
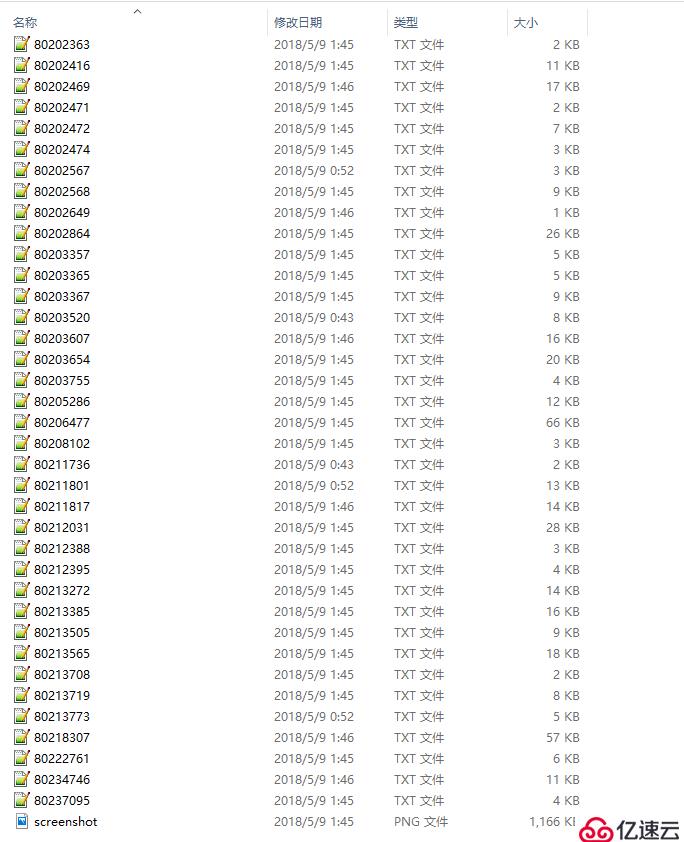
文章内容列表:
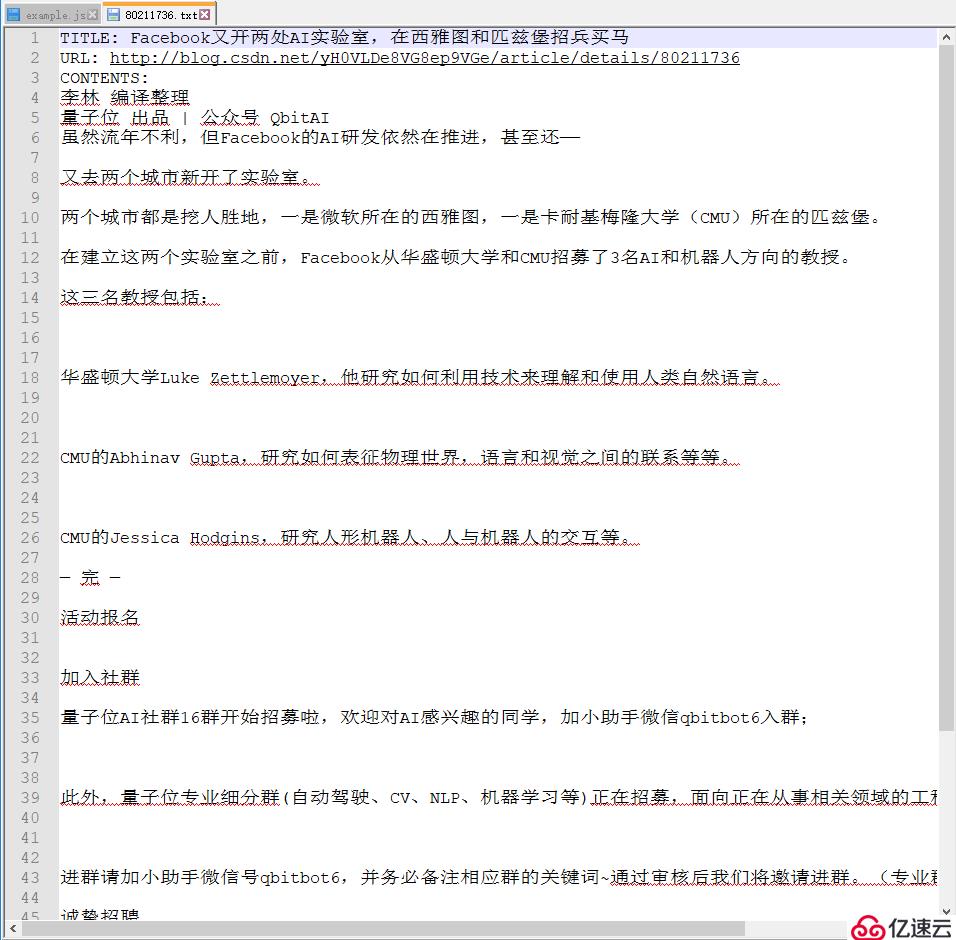
文章内容:
以前就想过既然nodejs是使用JavaScript脚本语言,那么它肯定能处理网页的JavaScript内容,但并没有发现合适的/高效率的库。直到发现puppeteer,才下定决心试水。
话说回来,nodejs的异步真的是很头疼的一件事,这上百行代码我竟然折腾了10个小时。
大家可拓展下代码中process()方法,使用async.eachSeries,我使用的递归方式并不是最优解。
事实上,逐一处理并不高效,原本我写了一个异步的关闭browser方法:
let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown<=0){
clearInterval(tryCloseBrowser);
console.log("none process running, close.")
browser.close();
}
},3000);按照这个思路,代码的最初版本是同时打开多个tab页,效率很高,但容错率很低,大家可以试着自己写一下。
看过我的文章的人都知道,我写文章更强调处理问题的方式/方法,给大家一些思维上的建议。
对于nodejs和puppeteer我是完全陌生的(当然,我知道他们适合做什么,仅此而已)。如果大家还记得《10倍速程序员》里提到的按需记忆的理念,那么你就会理解我刻意的不去系统的学习新技术。
我说说我接触puppeteer到完成我需要功能的所有思维逻辑:
2018年5月9日02点13分
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



