浅谈对数据库隔离级别的理解
当人们提及数据库管理系统 (DBMS),必会提及事务、 ACID特性以及事务隔离级别。 事务本身是为了保证系统的运行状态最终将处于一致性 (满足一组约束条件 )的状态而出现的概念,其中的 ACID特性中的 I(Isolation)要保证在并发操作情况下 数据库 最终可以处于 ”一致 ”的状态。但是自问一下便会产生诸多疑点 : 到底什么是事务隔离级别?为什么要有事务隔离级别?作为理论基础的每种隔离级别如何定义以及分别有什么作用呢?下面主要结合经典论文 [1]和相关经验来简要地谈谈自己的理解。
(一 ) 到底什么是事务隔离级别?为什么要有事务隔离级别?
事务四大特性 ACID中的 I(Isolation)字面意思是 ”隔离性 ”,实质上就是指对数据操作的并发控制。那么该问题换句话说即, 为什么需要并发控制?它解决了什么问题?
在数据库中, 如果对于同一数据项的所有事务操作都被串行化地执行,那么执行过程与结果是没有问题的。如果存在并发操作,即多个事务的生命周期 (时间区间 )之间存在交集,就 可能产生操作上的冲突和依赖,进而引发异常现象。对于同一数据项,两个并发操作的执行过程一定是有先后而非物理上的同时的,其结果取决于争抢与调度策略。 操作顺序类型可以分为 读 -读、读 -写、写 -读、写 -写 4种类型,其中后三种包含写的操作序列是有冲突的, 它们可能会引发执行结果的异常,或者叫异常现象 (Anomaly)。
例如,有如下命令在没有任何并发控制机制 (比如锁 )的情况下按如下调度顺序执行 :
|
时刻 |
事务 1 |
事务 2 |
|
t0 |
BEGIN; // x = 10 |
BEGIN; |
|
t1 |
w1[x]: 更新 x = x + 1; // x = 11 |
|
|
t2 |
|
r2[x]: read x; // x = 11,依赖 w1[x] |
|
t3 |
a1: abort(引发回滚 ); // x = 10 |
|
|
t4 |
|
更新 y : = x |
表 1.
这样构成的 执行序列模式 (现象 )是 w1[x]...r2[x]...a1...,符合 “写 -读 ” 的冲突模式,而上述 case确实产生了异常,即 :
(1) 按照上述执行序列,事务 2读取的数据是事务 1未提交的脏数据 x = 11,实际上是不应当被事务 2看到的不一致的数据,如果该数据被事务 2后续应用于更新某条记录 y := 11,那么将导致数据库的状态不一致。 (这便是大家所知的 ”脏读 ” )
(2) 如果把事务 1放在事务 2之前执行,那么这是串行化的事务执行方式,这时事务 2读到的 x值应该是事务 1未开始前的值 (已回滚 ),即 x = 10,这是正确的结果。具体如下 :
|
时刻 |
事务 1 |
事务 2 |
|
t0 |
BEGIN; // x = 10 |
|
|
t1 |
w1[x]: 更新 x = x + 1; // x = 11 |
|
|
t2 |
| |
|
|
|
BEGIN; // x = 10,与事务1串行,无问题 |
|
t3 |
|
|
|
t4 |
|
更新 y : = x |
|
|
|
... ... |
表 2.
这样, (1), (2) 两种调度方式所对应的保序的执行序列产生的结果是不一样的, (2)串行化执行是正确的, (1)的结果 (因为脏读 )产生了不一致的数据状态。
上述异常只是诸多类异常中的一种,并发控制就是要解决这些异常,但是并发控制需要达到什么程度呢?因为并发控制程度高对应着并发执行效率低,数据库用户并非时刻都需要最强的并发控制方式,这是一致性与并发度的权衡,隔离级别就是这一权衡的控制参数。
我们把事务及事务隔离级别的语境设定在数据库系统上,那么可以认为 :
从数据库使用者的角度来看, 异常现象是并发操作时可能出现的问题, 并发控制是避免某些异常现象导致问题的过程或手段, 隔离级别是对并发控制程度的 抽象描述。即 数据库使用者通过设定事务隔离级别,来配置数据库系统,使之在并发操作时能够规避某些异常现象。
从数据库开发者的角度来看,需要解决并发操作时的 异常现象是根本需求,而 隔离级别是把这些无穷多的现象级需求进行了分类、抽象、归纳,将 规避异常现象之需求转化为了 满足有限种类隔离级别之需求。即 数据库开发者只需要实现定义好的几种隔离级别,就可以为数据库系统提供规避某些 (可能是无穷多 )异常现象的功能。具体 DBMS中的隔离级别的定义可能会有区别,但实现上至少需要不弱于 ANSI-SQL标准。
隔离级别如何设定是与异常现象 /行为序列的分类、归纳方式有密切联系的。要想严谨 (从数学上 )地定义隔离级别,必然需要对异常现象给出形式 (而严格 )化的定义。
本节要点 :
|
-> 并发事务导致执行结果破坏某些约束 (问题源头 ) -> 起因归为读写冲突 (w-w/w-r/r-w) -> 异常现象 (Anomaly)(不完全 )归纳为异常模式 -> 更广义的行为序列 (现象 -Phenomenon)被归纳为行为序列模式 -> 禁止行为序列或异常序列模式可规避某些并发操作问题 -> 根据行为序列模式的归纳来定义 : 解决某些问题即符合特定隔离级别。 |
(二 ) 如何标准化、形式化地描述并发读写的 (异常 )现象?如何理解它们?
在论文 [1]中,已经给出了并发操作的异常现象或者普通现象的形式化描述。即 使用 行为序列描述一系列操作过程,其中行为被简化抽象为读、写两种类型,数字标注表示行为的所属事务 (事务 N),括号中的参数表示操作对象 (x,y,z,...)。形如 ”w1[x]...r2[x]...”就表示一个行为序列模式(表3-P2),那么对 行为序列的形式化定义可以看做是 行为序列模式,是对具有一定共性 ( 特征 )的行为序列的抽象表达。它表达了 某种模式的行为序列的集合。
下文分为几个部分 : 行为序列模式的形式化定义、操作对象分类、形象化理解、各类模式汇总,来对本节的问题进行说明。 ( 以下均以单版本值的情况进行说明,不考虑 MVCC)
* 行为序列模式的场景分类 : (P0-P3,A5 等定义见 表3.)
分类
1.
单条数据的并发操作现象
(
one data item)
>>
单条数据的读写操作序列的形式化描述是完备的,对应于
P0(w-w冲突
),P1(w-r冲突
),P2(r-w冲突
) 三类读写冲突
(r-r没有冲突
);
分类 2. 数据集合的并发操作现象 ( one data set of data items)
>> 数据集操作对应于 P3(潜在幻象 );
分类 3. 带约束的数据项操作现象 ( data items with constraints)
>> 具有关联约束的数据操作对应于 A5(A5A(r-w-w-r),A5B(r-r-w-w),...)以及其它可能的涉及数据关联约束的行为模式;
* 常见的行为序列模式及其形式化定义 (包含了异常序列模式 )
|
常见现象 |
异常现象集合 /模式 (原始 ANSI-SQL标准所涉及 ) |
普通现象集合 /模式 (包含了相应异常现象, ) (增强版 ANSI-SQL隔离级别 ) |
|
e.g. 脏写 记录 w-w 冲突 |
未定义 A0 |
P0: w1[x]...w2[x]...(c1/a1/c2/a2) |
|
e.g. 脏读 记录 w-r 冲突 |
A1: w1[x]... r2[x]...a1 先写后读 ; |
P1: w1[x]...r2[x]...(c1/a1/c2/a2) P1包含 A1; |
|
e.g. 不可重复读 记录 r-w 冲突 |
A2: r1[x]...w2[x]...c2... r1[x] 先读后写 ; |
P2: r1[x]...w2[x]...(c1/a1/c2/a2) P2包含 A2; |
|
e.g. 幻象 集合 r-w冲突 |
A3: r1[P]...w2[x in P]...c2...r1[P] 先读后写 ; |
P3: r1[P]...w2[x in P]...(c1/a1/c2/a2) P3包含 A3; |
|
e.g. 写丢失 记录 r-w-w冲突 |
- |
P4: r1[x]... w2[x]...w1[x]...c1 P2包含 P4, 先读后写 ; |
|
e.g. 读偏斜 关联数据冲突 |
A5A: (属于 A5类模式 ) r1[x]...w2[x]...w2[y]...c2... r1[y] 先读后写 ; |
P2包含 P4 |
|
e.g. 写偏斜 关联数据冲突 |
A5B: (属于 A5类模式 ) r1[x]...r2[y]... w1[y]...w2[x]...(c1/c2) 先读后写 ; |
P2包含 A5 |
|
... (等等 ) |
... |
... |
表 3.
说明 : (以下说明不是最重点的,主要是为后面的 行为模式关系图做铺垫,可对照查看 )
(1) 行为序列说明 : 例如, P1: w1[x]...r2[x]...(c1/a1/c2/a2),要表达的是 事务 1写数据项 x,之后 (还可能经历其它数据项 /事务的操作 ),事务 2写数据 x,之后,事务 1/2以任意顺序和方式 (提交 /中止 )结束;
(2) 行为序列模式的语义 : 满足某种模式 P的序列可以构成一个集合,集合中有些具体序列 可能产生异常结果,也可能不会。比如,符合 P2模式的序列不一定就符合 A2(脏读 ),而符合 A2的具体序列不一定就会造成真正的影响。 (比如 r2[x]中的读取操作不被任何后续的应用程序或人员的操作锁依赖而仅仅看一下就丢弃了,那么就不会产生影响 )。
(3) A1-A3: 这 3种异常现象序列模式是 ANSI-SQL定义隔离级别所使用的异常行为序列模式,但是这些描述的是某个具体种类的异常,对记录级读写冲突的描述不够完备,因此论文 [1]中提出了 P0-P3来扩充 A1-A3。 (比如, A1模式为 : “w1[x]...r2[x]...a1”,是 3元组;而 P1模式为 : “w1[x]...r2[x]...”,是 2元组 (因为任意的结束顺序和方式 (c1/a1/c2/a2)并没有够成对序列模式的限制,因此可忽略 )。 显然 A1是 P1的特例 , A2/P2,A3/P3类似 )
(4) 可串行化级别 : 上述 A1-A3的不完备也说明了基于 A1-A3来定义的 ANSI-SQL隔离级别不够严谨 ( 具体见 (三 )的表 4 )。
(5) P4: 写丢失现象
a) P4不同于 P0,虽然都涉及 w-w冲突,但是 P0的模式是 ”w1[x]-w2[x]-...”,而 P4的冲突是 ”r1[x]...w2[x]...w1[x]-...”,相对于 P0在最前面还有一次同一数据项的读取操作,这暗示了后面的 w1[x]有可能依赖于 r1[x]的读取结果,而 P0并没有这一点。
b) P4”r1[x]...w2[x]...w1[x]-...c1”写丢失现象被包含于 P2” r1[x]...w2[x]...”(先读后写 )。
(6) A5: 具有关联约束的 两个数据项的操作序列,可能会导致关联约束被破坏 (可以是用户自定义的约束 )。需要注意,基于任意多个数据项之间的关联约束并未在文中明确定义,因此在 P0-P3,A5之外还存在着其它的异常现象
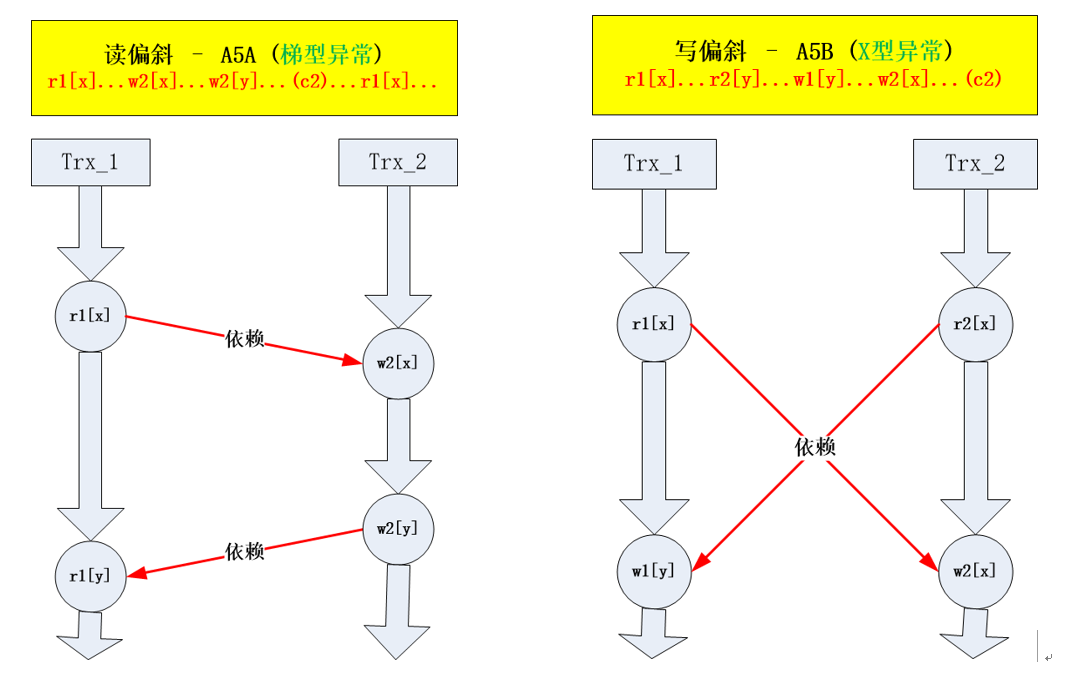
a) A5A 读偏斜 : 事务 1要读取 2个具有一定约束的数据项,需要 2次读操作 (r1[x]......r1[y]),在它们之间被插入了事务 2的关于写操作 (r1[x]... w1[x]...w2[y]...c2...r1[y]...),这样在第二次读操作时约束关系已经被破坏了。
b) A5B 写偏斜 : 两个事务分别要先读取一个数据项 (r1[x]...r2[y]...),再根据读到的值来计算并更新另一个数据项 (...w1[y]...w2[x]),如果两个事务无法可串行化的执行,那么可能会出现破坏约束的情况。例如 :初值 x=y=50; r1[x=50]... r2[y=50]...w1[y:=x+1=]... ... ... ...
(7) P2: 不可重复读现象,该现象是比较有意思的 :
a) P2包含了 A2,这在前面 (3)已经提及。
b) P2包含了 P4,这在前面 (4)已经提及。
c) P2包含了 A5A与 A5B,这在前面已经提及。
(8) END
至此可见, A(i)序列模式 包含于 P(i)序列模式, i = 1,2,3 . 而 P0更是 A(i)类没有定义出来的序列模式。 P(i)类模式 (w-w,w-r,r-w + 数据项 /数据集合 ) 比 A(i)类异常集合更加完备。
Q. 不可重复读现象 (A2/P2)与幻象现象 (A3/P3)的区别与联系是什么?
A. 不可重复读是仅仅针对单条数据。实际上可以认为,幻象是针对数据集合的不可重复读现象,因此幻象不仅包含了 MySQL中 RR隔离级别所能避免的幻读 (因为插入 新数据导致集合不可重复读 ),而是可以扩展到 因为增 /删 /改数据记录而导致的给定谓词条件下的数据集合的不可重复读。
例如 : SELECT pk_id FROM t WHERE cond;
在 RU(read uncommitted)隔离级别下,通过 WHERE条件相关的数据记录进行增 /删 /改,即 可改变查询结果集。这里需要改变的数据记录是要引起 cond判定的变化的,否则并不能影响查询结果。比如 INSERT一个满足 cond的 key值, UPDATE一个 key值 (其旧有或目标 key值满足 cond), DELETE一个 key值,都可以改变满足 cond的查询结果集。
* 异常现象的形象化说明
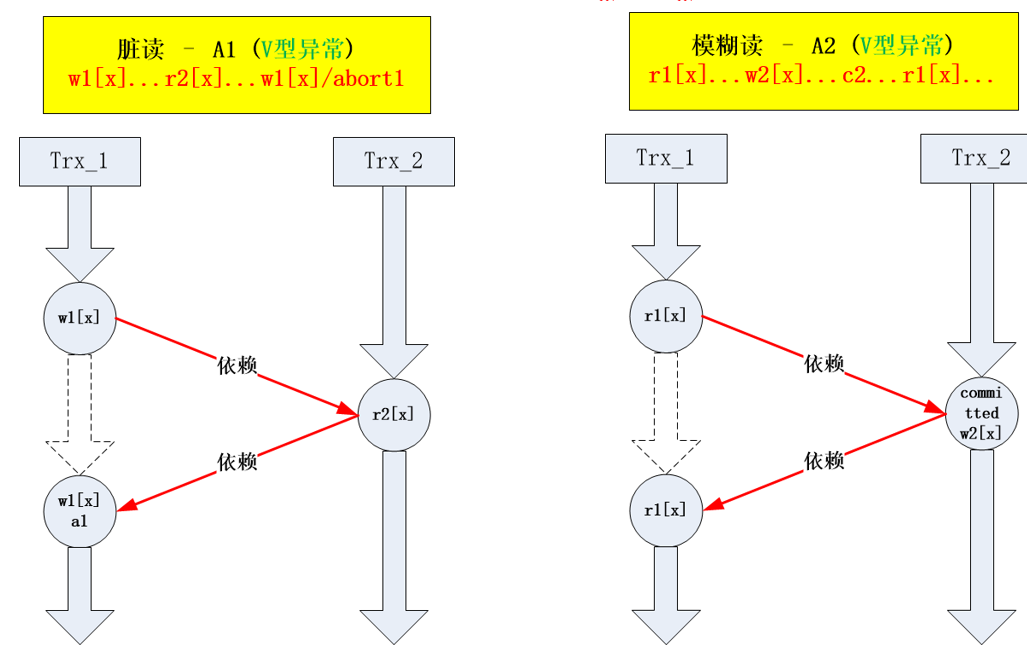
(1) 对于 A1-A2的异常 (A3类似于 A2)可以形象化表示为 ” V 型 ”异常 :
图 1.
(2) 什么是 A5类异常?什么是读倾斜、写偏斜?
实际上论文 [1]中的 A5表达的是具有关联约束的 两个数据项的操作异常,其中 A5A(读偏斜 read skew), A5B(写偏斜 write skew),可形象化地做如下表示 : (PS: 这里为避免歧义,将 skew译为偏斜,而非偏序 (一般容易理解为 partial ordering)。 )
图 2.
* 各类常见行为模式 (现象 )的关系汇总
论文 [1]中将本节中提及的序列之间的关系隐含在隔离级别的分析中了,笔者特此将其总结成一张关系图。 (下图某些集合关系的细节有待商榷,但可据此有宏观的认识 )
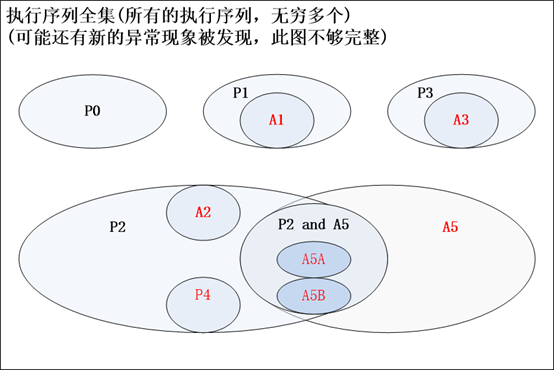
图 3.
综上,已经对异常现象做了一个汇总
: 形式化的表述与直观上的描述。
现在有了异常现象,我们就看每种隔离级别是如何定义的以及解决了怎样的异常呢?
(三 ) 如何严格地定义隔离级别?
有了 (二 )中的形式化定义,隔离级别就可以被相对严谨的定义了。这里将直接引用论文与书籍中的描述。这里在 (一 )的理解上,稍加修饰 : 隔离级别的定义可以有多种定义方式,但其要表达的根本意思是,如果一个事务系统在运行时能够规避某些问题集,那么该系统的事务将具有某种相应的隔离级别,即 隔离级别抽象出 待规避的最小异常现象集合。 至于 DBMS的某种隔离级别的实现,是否还可能规避对应级别的最小问题集以外的异常序列,并不做限制。
下面我们就来看看论文 [1]中是如何就隔离级别的几种定义做递进式的说明的。
1. ANSI-SQL92中定义的 4中隔离级别 (解决 A1-A3中的部分或者全部异常 ):

表 4. - [1]-table 1
然而,由于 (二 )中表 3.告诉我们 A1-A3对异常的定义并不完备,因此上述 ANSI-SQL隔离级别的定义是不够完备的。尤其是仅因规避 A1-A3而得名的 ANOMALY-SERIALIABLE级别并不是真正的 可串行化 (SR)隔离级别,因为并发事务在满足可串行化隔离级别的情况下是没有并发操作异常发生的 (理论保证 ),而 ANOMALY-SERIALIABLE级别无法避免 A5A,A5B等异常的发生。因此 需要将情况扩充得更加完备,具体如下。
2. 基于 P0-P3的隔离级别定义 : (来自论文 [1])
经过将 ANSI异常现象 A1-A3扩充至 P0-P3,得到加强版 ANSI-SQL隔离级别定义 :
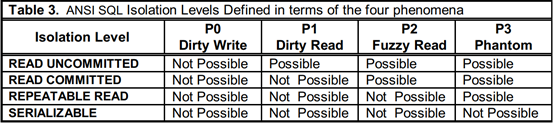
表 5. - [1]-table 3
以上已经将定义进行了将强处理,但是如何实现呢?老爷子 Jim Gray等人还根据各方资料总结了基于锁机制的隔离级别定义,这算是一种可实现化角度的定义,具体如下。
3. 基于锁机制的隔离级别定义 : (来自论文 [1])

表 6. - [1]-table 2
这里有一个论文 [1]提及的结论 : Table 3与 Table 2的 4种隔离级别的定义是等价的,也就是说 Locking-based 的 4种隔离级别与 ANSI-SQL加强版定义的 4种隔离级别等价。
|
Degree-0 << any defined Isolation Level. ANSI-RU << RU == Locking-RU == Degree-1 ANSI-RC << RC == Locking-RC == Degree-2 Degree-2 << ANSI-RR << RR == Locking-RR << Degree-3 ANOMALY-SR << SR == Degree-3 |
注意 : Serializable级别是最强的级别,理论上该级别解决了所有的异常现象。
4. 最终的隔离级别关系图 (来自论文 [1])
以 2、 3的定义 以及 (二 )中的序列模式关系为基础,最终我们得到了一张隔离级别关系图 :
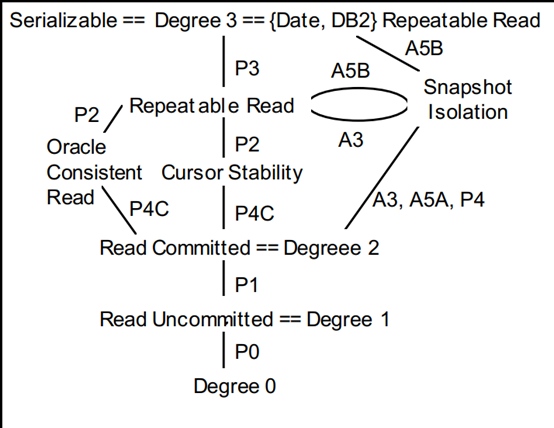
图 4. - [1]-Figure 2
最底层表示最弱的隔离级别,最顶层表示最强的隔离级别;而中间显示有些隔离级别之间并无绝对的强弱关系,因为分别有各自能够解决而对方不能保证解决的问题,这些分支主要在 RC级别与 SR(Serializable)级别之间;这里需要强调 : 每种 DBMS实现的隔离级别可能会在细节表现上有所不同,但至少应不弱于 ANSI-SQL标准;而每家的实现又取决于历史原因以及产品层面希望给用户怎样的吸引力,因此在不同数据库产品之间进行切换时,存储层和应用层都需要充分考虑隔离级别对用户的影响。
(四 ) 相关问题
Q. InnoDB - RR 隔离级别的意义何在?
A. InnoDB中隔离级别的实现手段有 2种,一种是 (行 )锁机制,一种是在 MVCC机制 (需要与锁机制结合 )。无论用户发起的事务中的 SQL都是基于锁并发控制的读 /写 SQL,还是也包含了基于 MVCC(无锁 )的只读 SQL,执行结果都应满足该事务所处隔离级别的语义。
对于InnoDB-RR隔离级别,一方面,在锁机制上采用 SS2PL策略 ( Locking Repeatable Read),理论上 (以及实际上 )已经达到了 可串行化的隔离级别 ( Locking-Serializable = Degree 3 >> Locking Repeatable Read = ANSI-SQL Phenomenon-based Repeatable Read >> ANSI-SQL Anomaly-based Repeatable Read),已经强于加强版 ANSI-SQL RR级别的定义了。另一方面,从现象上来讲 InnoDB-RR的锁机制避免了包括前述的幻读、读偏斜、写偏斜现象,但不仅限于此,而 RC隔离级别并不能解决诸如 A5A(读偏斜 ),A5B(写偏斜 )等异常,因此 MySQL内部将默认事务隔离级别设定为 RR,还是有重要意义的。
Q. 关于 SI(快照隔离 )级别
A. 论文 [1]中有所描述,是基于 MVCC技术实现的隔离级别,涉及的行为序列属于 多版本 (Multi-Versioning)行为序列,在理论上需要向 单值 (Single-Valued)行为序列做等价转换才能够将 SI并入 图 4.所示的隔离级别体系结构 (去做比较 )。文中涉及很多相关的分析过程,限于篇幅后续单独再对基于 MVCC技术的隔离级别做讨论。这里仅列举一些重要的结论 ( 图 4. ):
|
Degree-2 == RC << SI << SR = Degree-3 SI >><< RR |
Q. P2为何如此包容 (P2包含 A2,P4,A5A,A5B,...)?
A. 一方面, P2实际上抽象了 A2,P4,A5A,A5B等异常模式的共性—— ”先读后写 ”;另一方面, ”先读后写 ”很多时候意味着后写的目标数据对先读出的数据有依赖,这里可能是同一个数据项的依赖,也可能是 2个或者多个数据项的依赖,因此会涉及 A5A,A5B等诸多可能破坏关联约束的现象。
以上是笔者对事务隔离级别的粗浅理解—— 某种隔离级别定义了需要解决的某些并发操作问题的 最小 集合,谨为自己释疑,由于水平有限,理解尚不完备,还有许多相关问题值得学习和讨论,欢迎讨论指教。
参考文献 :
[1] “A Critique of ANSI SQL Isolation Levels,” Proc. ACM SIGMOD 95, pp. 1-10, San Jose CA, June 1995, © ACM
作者:贾春生(基础架构-数据库开发组)
现在注册滴滴云,有机会可得30元无门槛滴滴出行券
新购云服务1月5折 3月4.5折 6月低至4折
滴滴云使者招募,推荐最高返佣50%
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/31559758/viewspace-2676113/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务