HBaseдҪңдёәдёҖж¬ҫжөҒиЎҢзҡ„еҲҶеёғејҸNoSQLж•°жҚ®еә“пјҢиў«еҗ„дёӘе…¬еҸёеӨ§йҮҸеә”з”ЁпјҢе…¶дёӯжңүеҫҲеӨҡдёҡеҠЎеңәжҷҜпјҢдҫӢеҰӮдҝЎжҒҜжөҒе’Ңе№ҝе‘ҠдёҡеҠЎпјҢеҜ№и®ҝй—®зҡ„еҗһеҗҗе’Ң延иҝҹиҰҒжұӮйғҪйқһеёёй«ҳгҖӮHBase2.0дёәдәҶе°ҪжңҖеӨ§еҸҜиғҪйҒҝе…ҚJava GCеҜ№е…¶йҖ жҲҗзҡ„жҖ§иғҪеҪұе“ҚпјҢе·Із»ҸеҜ№иҜ»еҶҷдёӨжқЎж ёеҝғи·Ҝеҫ„еҒҡдәҶoffheapеҢ–пјҢд№ҹе°ұжҳҜеҜ№иұЎзҡ„з”іиҜ·йғҪзӣҙжҺҘеҗ‘JVM offheapз”іиҜ·пјҢиҖҢoffheapеҲҶеҮәжқҘзҡ„еҶ…еӯҳйғҪжҳҜдёҚдјҡиў«JVM GCзҡ„пјҢйңҖиҰҒз”ЁжҲ·иҮӘе·ұжҳҫејҸең°йҮҠж”ҫгҖӮеңЁеҶҷи·Ҝеҫ„дёҠпјҢе®ўжҲ·з«ҜеҸ‘иҝҮжқҘзҡ„иҜ·жұӮеҢ…йғҪдјҡиў«еҲҶй…ҚеҲ°offheapзҡ„еҶ…еӯҳеҢәеҹҹпјҢзӣҙеҲ°ж•°жҚ®жҲҗеҠҹеҶҷе…ҘWALж—Ҙеҝ—е’ҢMemstoreпјҢе…¶дёӯз»ҙжҠӨMemstoreзҡ„ConcurrentSkipListSetе…¶е®һд№ҹдёҚжҳҜзӣҙжҺҘеӯҳCellж•°жҚ®пјҢиҖҢжҳҜеӯҳCellзҡ„еј•з”ЁпјҢзңҹе®һзҡ„еҶ…еӯҳж•°жҚ®иў«зј–з ҒеңЁMSLABзҡ„еӨҡдёӘChunkеҶ…пјҢиҝҷж ·жҜ”иҫғдҫҝдәҺз®ЎзҗҶoffheapеҶ…еӯҳгҖӮзұ»дјјең°пјҢеңЁиҜ»и·Ҝеҫ„дёҠпјҢе…Ҳе°қиҜ•еҺ»иҜ»BucketCacheпјҢCacheжңӘе‘Ҫдёӯж—¶еҲҷеҺ»HFileдёӯиҜ»еҜ№еә”зҡ„BlockпјҢиҝҷе…¶дёӯеҚ з”ЁеҶ…еӯҳжңҖеӨҡзҡ„BucketCacheе°ұж”ҫеңЁoffheapдёҠпјҢжӢҝеҲ°BlockеҗҺзј–з ҒжҲҗCellеҸ‘йҖҒз»ҷз”ЁжҲ·пјҢж•ҙдёӘиҝҮзЁӢеҹәжң¬дёҠйғҪдёҚж¶үеҸҠheapеҶ…еҜ№иұЎз”іиҜ·гҖӮ
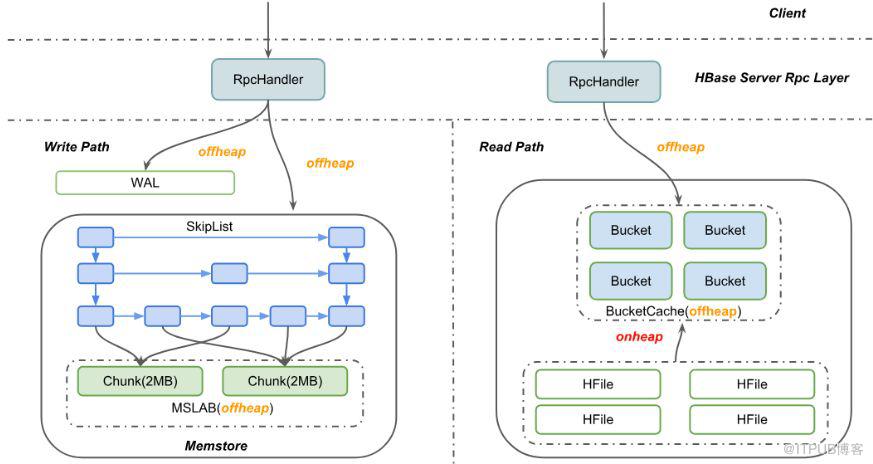
дҪҶжҳҜеңЁе°ҸзұіеҶ…йғЁжңҖиҝ‘зҡ„жҖ§иғҪжөӢиҜ•з»“жһңдёӯеҸ‘зҺ°пјҢ100% Getзҡ„еңәжҷҜеҸ—Young GCзҡ„еҪұе“Қд»Қ然жҜ”иҫғдёҘйҮҚпјҢеңЁHBASE-21879иҙҙзҡ„дёӨе№…еӣҫдёӯпјҢеҸҜд»ҘйқһеёёжҳҺжҳҫзҡ„и§ӮеҜҹеҲ°Getж“ҚдҪңзҡ„p999延иҝҹи·ҹG1 Young GCзҡ„иҖ—ж—¶еҹәжң¬зӣёеҗҢпјҢйғҪеңЁ100msе·ҰеҸігҖӮжҢүзҗҶиҜҙпјҢеңЁHBASE-11425д№ӢеҗҺпјҢеә”иҜҘжҳҜжүҖжңүзҡ„еҶ…еӯҳеҲҶй…ҚйғҪжҳҜеңЁoffheapзҡ„пјҢheapеҶ…еә”иҜҘеҮ д№ҺжІЎжңүеҶ…еӯҳз”іиҜ·гҖӮдҪҶжҳҜпјҢеңЁд»”з»ҶжўізҗҶд»Јз ҒеҗҺпјҢеҸ‘зҺ°д»ҺHFileдёӯиҜ»Blockзҡ„иҝҮзЁӢд»Қ然жҳҜе…ҲжӢ·иҙқеҲ°е ҶеҶ…еҺ»зҡ„пјҢдёҖзӣҙеҲ°BucketCacheзҡ„WriterThreadејӮжӯҘең°жҠҠBlockеҲ·ж–°еҲ°OffheapпјҢе ҶеҶ…зҡ„DataBlockжүҚйҮҠж”ҫгҖӮиҖҢзЈҒзӣҳеһӢеҺӢжөӢиҜ•йӘҢдёӯпјҢз”ұдәҺж•°жҚ®йҮҸеӨ§пјҢCacheе‘ҪдёӯзҺҮ并дёҚй«ҳ(~70%)пјҢжүҖд»ҘдјҡжңүеӨ§йҮҸзҡ„BlockиҜ»еҸ–иө°зЈҒзӣҳIOпјҢдәҺжҳҜHeapеҶ…дә§з”ҹеӨ§йҮҸзҡ„е№ҙиҪ»д»ЈеҜ№иұЎпјҢжңҖз»ҲеҜјиҮҙYoungеҢәGCеҺӢеҠӣдёҠеҚҮгҖӮ
ж¶ҲйҷӨYoung GCзӣҙжҺҘзҡ„жҖқи·Ҝе°ұжҳҜд»ҺHFileиҜ»DataBlockзҡ„ж—¶еҖҷпјҢзӣҙжҺҘеҫҖOffheapдёҠиҜ»гҖӮд№ӢеүҚз•ҷдёӢиҝҷдёӘеқ‘пјҢдё»иҰҒжҳҜHDFSдёҚж”ҜжҢҒByteBufferзҡ„PreadжҺҘеҸЈпјҢеҪ“然еҗҺйқўејҖдәҶHDFS-3246еңЁи·ҹиҝӣиҝҷдёӘдәӢжғ…гҖӮдҪҶеҗҺйқўеҸ‘зҺ°зҡ„дёҖдёӘй—®йўҳе°ұжҳҜпјҡRpcи·Ҝеҫ„дёҠиҜ»еҮәжқҘзҡ„DataBlockпјҢиҝӣдәҶBucketCacheд№ӢеҗҺе…¶е®һжҳҜе…Ҳж”ҫеҲ°дёҖдёӘеҸ«еҒҡRamCacheзҡ„дёҙж—¶MapдёӯпјҢиҖҢдё”BlockдёҖж—ҰиҝӣдәҶиҝҷдёӘMapе°ұеҸҜд»Ҙиў«е…¶д»–зҡ„RPCз»ҷе‘ҪдёӯпјҢжүҖд»ҘеҪ“еүҚRPCйҖҖеҮәеҗҺ并дёҚиғҪзӣҙжҺҘе°ұжҠҠд№ӢеүҚиҜ»еҮәжқҘзҡ„DataBlockз»ҷйҮҠж”ҫдәҶпјҢеҝ…йЎ»иҖғиҷ‘RamCacheжҳҜеҗҰд№ҹйҮҠж”ҫдәҶгҖӮдәҺжҳҜпјҢе°ұйңҖиҰҒдёҖз§ҚжңәеҲ¶жқҘи·ҹиёӘдёҖеқ—еҶ…еӯҳжҳҜеҗҰеҗҢж—¶дёҚеҶҚиў«жүҖжңүRPCи·Ҝеҫ„е’ҢRamCacheеј•з”ЁпјҢеҸӘжңүеңЁйғҪдёҚеј•з”Ёзҡ„жғ…еҶөдёӢпјҢжүҚиғҪйҮҠж”ҫеҶ…еӯҳгҖӮиҮӘ然иҖҢиЁҖзҡ„жғіеҲ°з”Ёreference CountжңәеҲ¶жқҘи·ҹиёӘByteBufferпјҢеҗҺйқўеҸ‘зҺ°е…¶е®һNettyе·Із»Ҹиҫғе®Ңж•ҙең°е®һзҺ°дәҶиҝҷдёӘдёңиҘҝпјҢдәҺжҳҜзңӢдәҶдёҖдёӢNettyзҡ„еҶ…еӯҳз®ЎзҗҶжңәеҲ¶гҖӮ
NettyдҪңдёәдёҖдёӘй«ҳжҖ§иғҪзҡ„еҹәзЎҖжЎҶжһ¶пјҢдёәдәҶдҝқиҜҒGCеҜ№жҖ§иғҪзҡ„еҪұе“ҚйҷҚеҲ°жңҖдҪҺпјҢеҒҡдәҶеӨ§йҮҸзҡ„offheapеҢ–гҖӮиҖҢoffheapзҡ„еҶ…еӯҳжҳҜзЁӢеәҸе‘ҳиҮӘе·ұз”іиҜ·е’ҢйҮҠж”ҫпјҢеҝҳи®°йҮҠж”ҫжҲ–иҖ…жҸҗеүҚйҮҠж”ҫйғҪдјҡйҖ жҲҗеҶ…еӯҳжі„йңІй—®йўҳпјҢжүҖд»ҘдёҖдёӘеҘҪзҡ„еҶ…еӯҳз®ЎзҗҶеҷЁеҫҲйҮҚиҰҒгҖӮйҰ–е…ҲпјҢд»Җд№Ҳж ·зҡ„еҶ…еӯҳеҲҶй…ҚеҷЁпјҢжүҚз®—дёҖдёӘжҳҜдёҖдёӘвҖңеҘҪвҖқзҡ„еҶ…еӯҳеҲҶй…ҚеҷЁпјҡ
й«ҳ并еҸ‘дё”зәҝзЁӢе®үе…ЁгҖӮдёҖиҲ¬дёҖдёӘиҝӣзЁӢе…ұдә«дёҖдёӘе…ЁеұҖзҡ„еҶ…еӯҳеҲҶй…ҚеҷЁпјҢеҫ—дҝқиҜҒеӨҡзәҝзЁӢ并еҸ‘з”іиҜ·йҮҠж”ҫж—ўй«ҳж•ҲеҸҲдёҚеҮәй—®йўҳгҖӮ
й«ҳж•Ҳзҡ„з”іиҜ·е’ҢйҮҠж”ҫеҶ…еӯҳпјҢиҝҷдёӘдёҚз”ЁеӨҡиҜҙгҖӮ
ж–№дҫҝи·ҹиёӘеҲҶй…ҚеҮәеҺ»еҶ…еӯҳзҡ„з”ҹе‘Ҫе‘Ёжңҹе’Ңе®ҡдҪҚеҶ…еӯҳжі„йңІй—®йўҳгҖӮ
й«ҳж•Ҳзҡ„еҶ…еӯҳеҲ©з”ЁзҺҮгҖӮжңүдәӣеҶ…еӯҳеҲҶй…ҚеҷЁеҲҶй…ҚеҲ°дёҖе®ҡзЁӢеәҰпјҢиҷҪ然иҝҳз©әй—ІеӨ§йҮҸеҶ…еӯҳзўҺзүҮпјҢдҪҶеҚҙеҶҚд№ҹжІЎжі•еҲҶеҮәдёҖдёӘзЁҚеҫ®еӨ§дёҖзӮ№зҡ„еҶ…еӯҳжқҘгҖӮжүҖд»ҘйңҖиҰҒйҖҡиҝҮжӣҙзІҫз»ҶеҢ–зҡ„з®ЎзҗҶпјҢе®һзҺ°жӣҙй«ҳзҡ„еҶ…еӯҳеҲ©з”ЁзҺҮгҖӮ
е°ҪйҮҸдҝқиҜҒеҗҢдёҖдёӘеҜ№иұЎеңЁзү©зҗҶеҶ…еӯҳдёҠеӯҳеӮЁзҡ„иҝһз»ӯжҖ§гҖӮдҫӢеҰӮеҲҶй…ҚеҷЁеҪ“еүҚе·Із»Ҹж— жі•еҲҶй…ҚеҮәдёҖеқ—е®Ңж•ҙиҝһз»ӯзҡ„70MBеҶ…еӯҳжқҘпјҢжңүдәӣеҲҶй…ҚеҷЁеҸҜиғҪдјҡйҖҡиҝҮеӨҡдёӘеҶ…еӯҳзўҺзүҮжӢјжҺҘеҮәдёҖеқ—70MBзҡ„еҶ…еӯҳпјҢдҪҶе…¶е®һеҗҲйҖӮзҡ„з®—жі•и®ҫи®ЎпјҢеҸҜд»ҘдҝқиҜҒжӣҙй«ҳзҡ„иҝһз»ӯжҖ§пјҢд»ҺиҖҢе®һзҺ°жӣҙй«ҳзҡ„еҶ…еӯҳи®ҝй—®ж•ҲзҺҮгҖӮ
дёәдәҶдјҳеҢ–еӨҡзәҝзЁӢз«һдәүз”іиҜ·еҶ…еӯҳеёҰжқҘйўқеӨ–ејҖй”ҖпјҢNettyзҡ„PooledByteBufAllocatorй»ҳи®ӨдёәжҜҸдёӘеӨ„зҗҶеҷЁеҲқе§ӢеҢ–дәҶдёҖдёӘеҶ…еӯҳжұ пјҢеӨҡдёӘзәҝзЁӢйҖҡиҝҮHashйҖүжӢ©жҹҗдёӘзү№е®ҡзҡ„еҶ…еӯҳжұ гҖӮиҝҷж ·еҚідҪҝжҳҜеӨҡеӨ„зҗҶеҷЁе№¶еҸ‘еӨ„зҗҶзҡ„жғ…еҶөдёӢпјҢжҜҸдёӘеӨ„зҗҶеҷЁеҹәжң¬дёҠиғҪдҪҝз”Ёеҗ„иҮӘзӢ¬з«Ӣзҡ„еҶ…еӯҳжұ пјҢд»ҺиҖҢзј“и§Јз«һдәүеҜјиҮҙзҡ„еҗҢжӯҘзӯүеҫ…ејҖй”ҖгҖӮ
Nettyзҡ„еҶ…еӯҳз®ЎзҗҶи®ҫи®Ўзҡ„жҜ”иҫғзІҫз»ҶгҖӮйҰ–е…ҲпјҢе°ҶеҶ…еӯҳеҲ’еҲҶжҲҗдёҖдёӘдёӘ16MBзҡ„ChunkпјҢжҜҸдёӘChunkеҸҲз”ұ2048дёӘ8KBзҡ„Pageз»„жҲҗгҖӮиҝҷйҮҢйңҖиҰҒжҸҗдёҖдёӢпјҢеҜ№жҜҸдёҖж¬ЎеҶ…еӯҳз”іиҜ·пјҢйғҪе°ҶдәҢиҝӣеҲ¶еҜ№йҪҗпјҢдҫӢеҰӮйңҖиҰҒз”іиҜ·150Bзҡ„еҶ…еӯҳпјҢеҲҷе®һйҷ…еҫ…з”іиҜ·зҡ„еҶ…еӯҳе…¶е®һжҳҜ256BпјҢиҖҢдё”дёҖдёӘPageеңЁжңӘиҝӣCacheеүҚпјҲеҗҺз»ӯдјҡи®ІеҲ°CacheпјүйғҪеҸӘиғҪиў«дёҖж¬Ўз”іиҜ·еҚ з”ЁпјҢд№ҹе°ұжҳҜиҜҙдёҖдёӘPageеҶ…з”іиҜ·дәҶ256Bзҡ„еҶ…еӯҳеҗҺпјҢеҗҺйқўзҡ„иҜ·жұӮд№ҹе°ҶдёҚдјҡеңЁиҝҷдёӘPageдёӯз”іиҜ·пјҢиҖҢжҳҜеҺ»жүҫе…¶д»–е®Ңе…Ёз©әй—Ізҡ„PageгҖӮжңүдәәеҸҜиғҪдјҡз–‘й—®пјҢйӮЈиҝҷж ·еІӮдёҚжҳҜеҶ…еӯҳеҲ©з”ЁзҺҮи¶…дҪҺпјҹеӣ дёәдёҖдёӘ8KBзҡ„Pageиў«еҲҶй…ҚдәҶ256Bд№ӢеҗҺпјҢе°ұеҶҚд№ҹеҲҶй…ҚдәҶгҖӮе…¶е®һдёҚжҳҜпјҢеӣ дёәеҗҺйқўиҝӣдәҶCacheеҗҺпјҢиҝҳжҳҜеҸҜд»ҘеҲҶй…ҚеҮә31дёӘ256Bзҡ„ByteBufferзҡ„гҖӮ
еӨҡдёӘChunkеҸҲеҸҜд»Ҙз»„жҲҗдёҖдёӘChunkListпјҢеҶҚж №жҚ®ChunkеҶ…еӯҳеҚ з”ЁжҜ”дҫӢпјҲChunkдҪҝз”ЁеҶ…еӯҳ/16MB * 100%пјүеҲ’еҲҶжҲҗдёҚеҗҢзӯүзә§зҡ„ChunkListгҖӮдҫӢеҰӮпјҢдёӢеӣҫдёӯж №жҚ®еҶ…еӯҳдҪҝз”ЁжҜ”дҫӢдёҚеҗҢпјҢеҲҶжҲҗдәҶ6дёӘдёҚеҗҢзӯүзә§зҡ„ChunkListпјҢе…¶дёӯq050еҶ…зҡ„ChunkйғҪжҳҜеҚ з”ЁжҜ”дҫӢеңЁ[50,100)иҝҷдёӘеҢәй—ҙеҶ…гҖӮйҡҸзқҖеҶ…еӯҳзҡ„дёҚж–ӯеҲҶй…ҚпјҢq050еҶ…зҡ„жҹҗдёӘChunkеҚ з”ЁжҜ”дҫӢеҸҜиғҪзӯүдәҺ100пјҢеҲҷиҜҘChunkиў«жҢӘеҲ°q075иҝҷдёӘChunkListдёӯгҖӮеӣ дёәеҶ…еӯҳдёҖзӣҙеңЁз”іиҜ·е’ҢйҮҠж”ҫпјҢдёҠйқўйӮЈдёӘChunkеҸҜиғҪеӣ жҹҗдәӣеҜ№иұЎйҮҠж”ҫеҗҺпјҢеҜјиҮҙеҶ…еӯҳеҚ з”ЁжҜ”е°ҸдәҺ75пјҢеҲҷеҸҲдјҡиў«ж”ҫеӣһеҲ°q050иҝҷдёӘChunkListдёӯпјӣеҪ“然д№ҹжңүеҸҜиғҪжҹҗж¬ЎеҲҶй…ҚеҗҺпјҢеҶ…еӯҳеҚ з”ЁжҜ”дҫӢеҶҚж¬ЎеҲ°иҫҫ100пјҢеҲҷдјҡиў«жҢӘеҲ°q100еҶ…гҖӮиҝҷж ·и®ҫи®Ўзҡ„дёҖдёӘеҘҪеӨ„еңЁдәҺпјҢеҸҜд»Ҙе°ҪйҮҸи®©з”іиҜ·иҜ·жұӮиҗҪеңЁжҜ”иҫғз©әй—Ізҡ„ChunkдёҠпјҢд»ҺиҖҢжҸҗй«ҳдәҶеҶ…еӯҳеҲҶй…Қзҡ„ж•ҲзҺҮгҖӮ
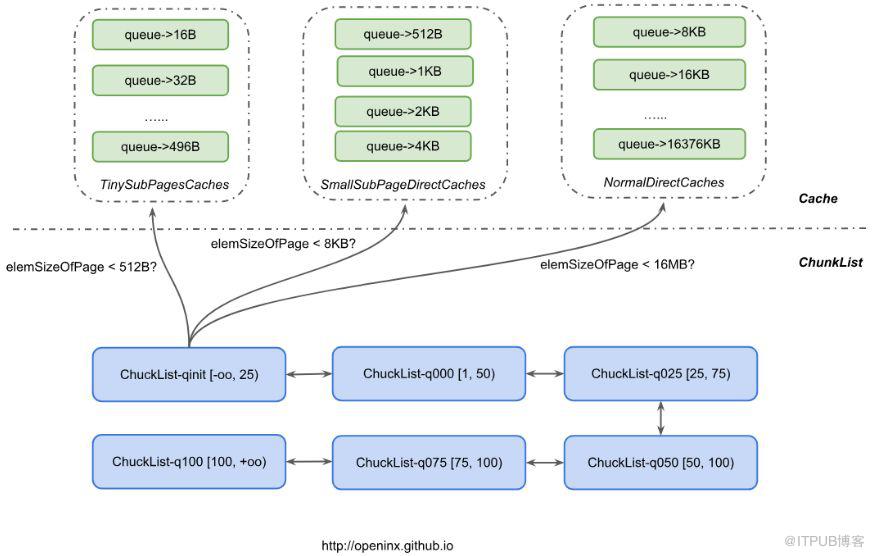
д»Қд»ҘдёҠиҝ°дёәдҫӢпјҢжҹҗеҜ№иұЎAз”іиҜ·дәҶ150BеҶ…еӯҳпјҢдәҢиҝӣеҲ¶еҜ№йҪҗеҗҺе®һйҷ…з”іиҜ·дәҶ256Bзҡ„еҶ…еӯҳгҖӮеҜ№иұЎAйҮҠж”ҫеҗҺпјҢеҜ№еә”з”іиҜ·зҡ„Pageд№ҹе°ұйҮҠж”ҫпјҢNettyдёәдәҶжҸҗй«ҳеҶ…еӯҳзҡ„дҪҝз”Ёж•ҲзҺҮпјҢдјҡжҠҠиҝҷдәӣPageж”ҫеҲ°еҜ№еә”зҡ„CacheдёӯпјҢеҜ№иұЎAз”іиҜ·зҡ„PageжҳҜжҢүз…§256BжқҘеҲ’еҲҶзҡ„пјҢжүҖд»ҘзӣҙжҺҘжҢүдёҠеӣҫжүҖзӨәпјҢиҝӣе…ҘдәҶдёҖдёӘеҸ«еҒҡTinySubPagesCachesзҡ„зј“еҶІжұ гҖӮиҝҷдёӘзј“еҶІжұ е®һйҷ…дёҠжҳҜз”ұеӨҡдёӘйҳҹеҲ—з»„жҲҗпјҢжҜҸдёӘйҳҹеҲ—еҶ…д»ЈиЎЁPageеҲ’еҲҶзҡ„дёҚеҗҢе°әеҜёпјҢдҫӢеҰӮqueue->32BпјҢиЎЁзӨәиҝҷдёӘйҳҹеҲ—дёӯпјҢзј“еӯҳзҡ„йғҪжҳҜжҢүз…§32BжқҘеҲ’еҲҶзҡ„PageпјҢдёҖж—Ұжңү32Bзҡ„з”іиҜ·иҜ·жұӮпјҢе°ұзӣҙжҺҘеҺ»иҝҷдёӘйҳҹеҲ—жүҫжңӘеҚ ж»Ўзҡ„PageгҖӮиҝҷйҮҢпјҢеҸҜд»ҘеҸ‘зҺ°пјҢйҳҹеҲ—дёӯзҡ„еҗҢдёҖдёӘPageеҸҜд»Ҙиў«еӨҡж¬Ўз”іиҜ·пјҢеҸӘжҳҜ他们申иҜ·зҡ„еҶ…еӯҳеӨ§е°ҸйғҪдёҖж ·пјҢиҝҷд№ҹе°ұдёҚеӯҳеңЁд№ӢеүҚиҜҙзҡ„еҶ…еӯҳеҚ з”ЁзҺҮдҪҺзҡ„й—®йўҳпјҢеҸҚиҖҢеҚ з”ЁзҺҮдјҡжҜ”иҫғй«ҳгҖӮ
еҪ“然пјҢCacheеҸҲжҢүз…§PageеҶ…йғЁеҲ’еҲҶйҮҸпјҲз§°д№ӢдёәelemSizeOfPageпјҢд№ҹе°ұжҳҜдёҖдёӘPageеҶ…дјҡеҲ’еҲҶжҲҗ8KB/elemSizeOfPageдёӘзӣёзӯүеӨ§е°Ҹзҡ„е°Ҹеқ—пјүеҲҶжҲҗ3дёӘдёҚеҗҢзұ»еһӢзҡ„CacheгҖӮеҜ№йӮЈдәӣе°ҸдәҺ512Bзҡ„з”іиҜ·иҜ·жұӮпјҢе°Ҷе°қиҜ•еҺ»TinySubPagesCachesдёӯз”іиҜ·пјӣеҜ№йӮЈдәӣе°ҸдәҺ8KBзҡ„з”іиҜ·иҜ·жұӮпјҢе°Ҷе°қиҜ•еҺ»SmallSubPagesDirectCachesдёӯз”іиҜ·пјӣеҜ№йӮЈдәӣе°ҸдәҺ16MBзҡ„з”іиҜ·иҜ·жұӮпјҢе°Ҷе°қиҜ•еҺ»NormalDirectCachesдёӯз”іиҜ·гҖӮиӢҘеҜ№еә”зҡ„CacheдёӯпјҢдёҚеӯҳеңЁиғҪз”Ёзҡ„еҶ…еӯҳпјҢеҲҷзӣҙжҺҘеҺ»дёӢйқўзҡ„6дёӘChunkListдёӯжүҫChunkз”іиҜ·пјҢеҪ“然иҝҷдәӣChunkжңүеҸҜиғҪйғҪиў«з”іиҜ·ж»ЎдәҶпјҢйӮЈд№ҲеҸӘиғҪеҗ‘OffheapзӣҙжҺҘз”іиҜ·дёҖдёӘChunkжқҘж»Ўи¶ійңҖжұӮдәҶгҖӮ
ChunkеҶ…йғЁеҲҶй…Қзҡ„иҝһз»ӯжҖ§пјҲcache coherenceпјү
дёҠж–Үеҹәжң¬зҗҶжё…дәҶChunkд№ӢдёҠеҶ…еӯҳз”іиҜ·зҡ„еҺҹзҗҶпјҢжҖ»дҪ“жқҘзңӢпјҢNettyзҡ„еҶ…еӯҳеҲҶй…ҚиҝҳжҳҜеҒҡзҡ„йқһеёёзІҫз»Ҷзҡ„пјҢд»Һз®—жі•дёҠзңӢпјҢж— и®әжҳҜз”іиҜ·/йҮҠж”ҫж•ҲзҺҮиҝҳжҳҜеҶ…еӯҳеҲ©з”ЁзҺҮйғҪжҜ”иҫғжңүдҝқйҡңгҖӮиҝҷйҮҢз®ҖеҚ•йҳҗиҝ°дёҖдёӢChunkеҶ…йғЁеҰӮдҪ•еҲҶй…ҚеҶ…еӯҳгҖӮ
дёҖдёӘй—®йўҳе°ұжҳҜпјҡеҰӮжһңиҰҒеңЁдёҖдёӘChunkеҶ…з”іиҜ·32KBзҡ„еҶ…еӯҳпјҢйӮЈд№ҲChunkеә”иҜҘжҖҺд№ҲеҲҶй…ҚPageжүҚжҜ”иҫғй«ҳж•ҲпјҢеҗҢж—¶з”ЁжҲ·зҡ„еҶ…еӯҳи®ҝй—®ж•ҲзҺҮжҜ”иҫғй«ҳпјҹ
дёҖдёӘз®ҖеҚ•зҡ„жҖқи·Ҝе°ұжҳҜпјҢжҠҠ16MBзҡ„ChunkеҲ’еҲҶжҲҗ2048дёӘ8KBзҡ„PageпјҢ然еҗҺз”ЁдёҖдёӘйҳҹеҲ—жқҘз»ҙжҠӨиҝҷдәӣPageгҖӮеҰӮжһңдёҖдёӘPageиў«з”ЁжҲ·з”іиҜ·пјҢеҲҷд»ҺйҳҹеҲ—дёӯеҮәйҳҹпјӣPageиў«з”ЁжҲ·йҮҠж”ҫпјҢеҲҷйҮҚж–°е…ҘйҳҹгҖӮиҝҷж ·еҶ…еӯҳзҡ„еҲҶй…Қе’ҢйҮҠж”ҫж•ҲзҺҮйғҪйқһеёёй«ҳпјҢйғҪжҳҜO(1)зҡ„еӨҚжқӮеәҰгҖӮдҪҶй—®йўҳжҳҜпјҢдёҖдёӘ32KBеҜ№иұЎдјҡиў«еҲҶж•ЈеңЁ4дёӘдёҚиҝһз»ӯзҡ„PageпјҢз”ЁжҲ·зҡ„еҶ…еӯҳи®ҝй—®ж•ҲзҺҮдјҡеҸ—еҲ°еҪұе“ҚгҖӮ
Nettyзҡ„ChunkеҶ…еҲҶй…Қз®—жі•пјҢеҲҷе…јйЎҫдәҶз”іиҜ·/йҮҠж”ҫж•ҲзҺҮе’Ңз”ЁжҲ·еҶ…еӯҳи®ҝй—®ж•ҲзҺҮгҖӮжҸҗй«ҳз”ЁжҲ·еҶ…еӯҳи®ҝй—®ж•ҲзҺҮзҡ„дёҖз§Қж–№ејҸе°ұжҳҜпјҢж— и®әз”ЁжҲ·з”іиҜ·еӨҡеӨ§зҡ„еҶ…еӯҳйҮҸпјҢйғҪи®©е®ғиҗҪеңЁдёҖеқ—иҝһз»ӯзҡ„зү©зҗҶеҶ…еӯҳдёҠпјҢиҝҷз§Қзү№жҖ§жҲ‘们称д№ӢдёәCache coherenceгҖӮ
жқҘзңӢдёҖдёӢNettyзҡ„з®—жі•и®ҫи®Ўпјҡ
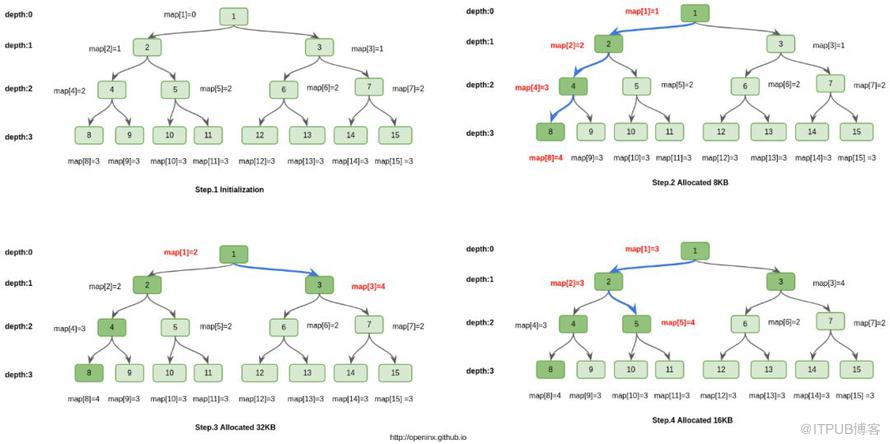
йҰ–е…ҲпјҢ16MBзҡ„ChunkеҲҶжҲҗ2048дёӘ8KBзҡ„PageпјҢиҝҷ2048дёӘPageжӯЈеҘҪеҸҜд»Ҙз»„жҲҗдёҖйў—е®Ңе…ЁдәҢеҸүж ‘пјҲзұ»дјје Ҷж•°жҚ®з»“жһ„пјүпјҢиҝҷйў—е®Ңе…ЁдәҢеҸүж ‘еҸҜд»Ҙз”ЁдёҖдёӘint[] mapжқҘз»ҙжҠӨгҖӮдҫӢеҰӮпјҢmap[1]е°ұиЎЁзӨәrootпјҢmap[2]е°ұиЎЁзӨәrootзҡ„е·Ұе„ҝеӯҗпјҢmap[3]е°ұиЎЁзӨәrootзҡ„еҸіе„ҝеӯҗпјҢдҫқж¬Ўзұ»жҺЁпјҢmap[2048]жҳҜ第дёҖдёӘеҸ¶еӯҗиҠӮзӮ№пјҢmap[2049]жҳҜ第дәҢдёӘеҸ¶еӯҗиҠӮзӮ№вҖҰпјҢmap[4095]жҳҜжңҖеҗҺдёҖдёӘеҸ¶еӯҗиҠӮзӮ№гҖӮиҝҷ2048дёӘеҸ¶еӯҗиҠӮзӮ№пјҢжӯЈеҘҪдҫқж¬ЎеҜ№еә”2048дёӘPageгҖӮ
иҝҷжЈөж ‘зҡ„зү№зӮ№е°ұжҳҜпјҢд»»дҪ•дёҖйў—еӯҗж ‘зҡ„жүҖжңүPageйғҪжҳҜеңЁзү©зҗҶеҶ…еӯҳдёҠиҝһз»ӯзҡ„гҖӮжүҖд»ҘпјҢз”іиҜ·32KBзҡ„зү©зҗҶеҶ…еӯҳиҝһз»ӯзҡ„ж“ҚдҪңпјҢеҸҜд»ҘиҪ¬еҸҳжҲҗжүҫдёҖйў—жӯЈеҘҪжңү4дёӘPageз©әй—Ізҡ„еӯҗж ‘пјҢиҝҷж ·е°ұи§ЈеҶідәҶз”ЁжҲ·еҶ…еӯҳи®ҝй—®ж•ҲзҺҮзҡ„й—®йўҳпјҢдҝқиҜҒдәҶCache Coherenceзү№жҖ§гҖӮ
дҪҶеҰӮдҪ•и§ЈеҶіеҲҶй…Қе’ҢйҮҠж”ҫзҡ„ж•ҲзҺҮзҡ„й—®йўҳе‘ўпјҹ
жҖқи·Ҝе…¶е®һдёҚжҳҜзү№еҲ«йҡҫпјҢдҪҶжҳҜNettyдёӯз”Ёеҗ„з§ҚдәҢиҝӣеҲ¶дјҳеҢ–д№ӢеҗҺпјҢжҳҫзҡ„дёҚйӮЈд№Ҳе®№жҳ“зҗҶи§ЈгҖӮжүҖд»ҘпјҢжҲ‘з”»дәҶдёҖеүҜеӣҫгҖӮе…¶жң¬иҙЁе°ұжҳҜпјҢе®Ңе…ЁдәҢеҸүж ‘зҡ„жҜҸдёӘиҠӮзӮ№idйғҪз»ҙжҠӨдёҖдёӘmap[id]еҖјпјҢиҝҷдёӘеҖјиЎЁзӨәд»Ҙidдёәж №зҡ„еӯҗж ‘дёҠпјҢжҢүз…§еұӮж¬ЎйҒҚеҺҶпјҢ第дёҖдёӘе®Ңе…Ёз©әй—Іеӯҗж ‘еҜ№еә”ж №иҠӮзӮ№зҡ„ж·ұеәҰгҖӮдҫӢеҰӮеңЁstep.3еӣҫдёӯпјҢid=2пјҢеұӮж¬ЎйҒҚеҺҶзў°еҲ°зҡ„第дёҖйў—е®Ңе…Ёз©әй—Іеӯҗж ‘жҳҜid=5дёәж №зҡ„еӯҗж ‘пјҢе®ғзҡ„ж·ұеәҰдёә2пјҢжүҖд»Ҙmap[2]=2гҖӮ
зҗҶи§ЈдәҶmap[id]иҝҷдёӘжҰӮеҝөд№ӢеҗҺпјҢеҶҚзңӢеӣҫе…¶е®һе°ұжІЎжңүйӮЈд№ҲйҡҫзҗҶи§ЈдәҶгҖӮеӣҫдёӯз”»зҡ„жҳҜеңЁдёҖдёӘ64KBзҡ„chunkпјҲз”ұ8дёӘpageз»„жҲҗпјҢеҜ№еә”ж ‘жңҖеә•еұӮзҡ„8дёӘеҸ¶еӯҗиҠӮзӮ№пјүдёҠпјҢдҫқж¬ЎеҲҶй…Қ8KBгҖҒ32KBгҖҒ16KBзҡ„з»ҙжҠӨжөҒзЁӢгҖӮеҸҜд»ҘеҸ‘зҺ°пјҢж— и®әжҳҜз”іиҜ·еҶ…еӯҳпјҢиҝҳжҳҜйҮҠж”ҫеҶ…еӯҳпјҢж“ҚдҪңзҡ„еӨҚжқӮеәҰйғҪжҳҜlog(N)пјҢNд»ЈиЎЁиҠӮзӮ№зҡ„дёӘж•°гҖӮиҖҢеңЁNettyдёӯпјҢN=2048пјҢжүҖд»Ҙз”іиҜ·гҖҒйҮҠж”ҫеҶ…еӯҳзҡ„еӨҚжқӮеәҰйғҪеҸҜд»Ҙи®ӨдёәжҳҜеёёж•°зә§еҲ«зҡ„гҖӮ
йҖҡиҝҮдёҠиҝ°з®—жі•пјҢNettyеҗҢж—¶дҝқиҜҒдәҶChunkеҶ…йғЁеҲҶй…Қ/з”іиҜ·еӨҡдёӘPagesзҡ„й«ҳж•Ҳе’Ңз”ЁжҲ·еҶ…еӯҳи®ҝй—®зҡ„й«ҳж•ҲгҖӮ
еј•з”Ёи®Ўж•°е’ҢеҶ…еӯҳжі„жјҸжЈҖжҹҘдёҠж–ҮжҸҗеҲ°пјҢHBaseзҡ„ByteBufд№ҹе°қиҜ•йҮҮз”Ёеј•з”Ёи®Ўж•°жқҘи·ҹиёӘдёҖеқ—еҶ…еӯҳзҡ„з”ҹе‘Ҫе‘ЁжңҹпјҢиў«еј•з”ЁдёҖж¬ЎеҲҷе…¶refCount++пјҢеҸ–ж¶Ҳеј•з”ЁеҲҷrefCount--пјҢдёҖж—ҰrefCount=0еҲҷи®ӨдёәеҶ…еӯҳеҸҜд»Ҙеӣһ收еҲ°еҶ…еӯҳжұ гҖӮжҖқи·ҜеҫҲз®ҖеҚ•пјҢеҸӘжҳҜйңҖиҰҒиҖғиҷ‘дёӢзәҝзЁӢе®үе…Ёзҡ„й—®йўҳгҖӮ
дҪҶдәӢе®һдёҠпјҢеҚідҪҝжңүдәҶеј•з”Ёи®Ўж•°пјҢеҸҜиғҪиҝҳжҳҜе®№жҳ“зў°еҲ°еҝҳи®°жҳҫејҸrefCount--зҡ„ж“ҚдҪңпјҢNettyжҸҗдҫӣдәҶдёҖдёӘеҸ«еҒҡResourceLeakDetectorзҡ„и·ҹиёӘеҷЁгҖӮеңЁEnableзҠ¶жҖҒдёӢпјҢд»»дҪ•еҲҶеҮәеҺ»зҡ„ByteBufйғҪдјҡиҝӣе…ҘиҝҷдёӘи·ҹиёӘеҷЁдёӯпјҢеӣһ收ByteBufж—¶еҲҷд»Һи·ҹиёӘеҷЁдёӯеҲ йҷӨгҖӮдёҖж—ҰеҸ‘зҺ°жҹҗдёӘж—¶й—ҙзӮ№и·ҹиёӘеҷЁеҶ…зҡ„ByteBuffжҖ»ж•°еӨӘеӨ§пјҢеҲҷи®ӨдёәеӯҳеңЁеҶ…еӯҳжі„йңІгҖӮејҖеҗҜиҝҷдёӘеҠҹиғҪеҝ…然дјҡеҜ№жҖ§иғҪжңүжүҖеҪұе“ҚпјҢжүҖд»Ҙз”ҹдә§зҺҜеўғдёӢйғҪдёҚејҖиҝҷдёӘеҠҹиғҪпјҢеҸӘжңүеңЁжҖҖз–‘жңүеҶ…еӯҳжі„йңІй—®йўҳж—¶ејҖеҗҜз”ЁжқҘе®ҡдҪҚй—®йўҳз”ЁгҖӮ
Nettyзҡ„еҶ…еӯҳз®ЎзҗҶе…¶е®һеҒҡзҡ„еҫҲзІҫз»ҶпјҢеҜ№HBaseзҡ„OffheapеҢ–и®ҫи®ЎжңүдёҚе°‘еҗҜеҸ‘гҖӮзӣ®еүҚHBaseзҡ„еҶ…еӯҳеҲҶй…ҚеҷЁиҮіе°‘жңү3з§Қпјҡ
Rpcи·Ҝеҫ„дёҠoffheapеҶ…еӯҳеҲҶй…ҚеҷЁгҖӮе®һзҺ°иҫғдёәз®ҖеҚ•пјҢд»Ҙе®ҡй•ҝ64KBдёәеҚ•дҪҚеҲҶй…ҚPageз»ҷеҜ№иұЎпјҢеҸ‘зҺ°Offheapжұ ж— жі•еҲҶеҮәжқҘпјҢеҲҷзӣҙжҺҘеҺ»Heapз”іиҜ·гҖӮ
Memstoreзҡ„MSLABеҶ…еӯҳеҲҶй…ҚеҷЁпјҢж ёеҝғжҖқи·Ҝи·ҹRPCеҶ…еӯҳеҲҶй…ҚеҷЁзӣёе·®дёҚеӨ§гҖӮеә”иҜҘеҸҜд»ҘеҗҲдәҢдёәдёҖгҖӮ
BucketCacheдёҠзҡ„BucketAllocatorгҖӮ
е°ұ第1зӮ№е’Ң第2зӮ№иҖҢиЁҖпјҢжҲ‘и§үеҫ—д»ҠеҗҺе°қиҜ•ж”№жҲҗз”ЁNettyзҡ„PooledByteBufAllocatorеә”иҜҘй—®йўҳдёҚеӨ§пјҢжҜ•з«ҹNettyеңЁеӨҡж ёе№¶еҸ‘/еҶ…еӯҳеҲ©з”ЁзҺҮд»ҘеҸҠCacheCoherenceдёҠйғҪеҒҡдәҶдёҚе°‘дјҳеҢ–гҖӮз”ұдәҺBucketCacheж—ўеҸҜд»ҘеӯҳеҶ…еӯҳпјҢеҸҲеҸҜд»ҘеӯҳSSDзЈҒзӣҳпјҢз”ҡиҮіHDDзЈҒзӣҳгҖӮжүҖд»ҘBucketAllocatorеҒҡдәҶжӣҙй«ҳзЁӢеәҰзҡ„жҠҪиұЎпјҢз»ҙжҠӨзҡ„йғҪжҳҜдёҖдёӘ(offset,len)иҝҷж ·зҡ„дәҢе…ғз»„пјҢNettyзҺ°жңүзҡ„жҺҘеҸЈе№¶дёҚиғҪж»Ўи¶ійңҖжұӮпјҢжүҖд»Ҙдј°и®ЎжҡӮж—¶еҸӘиғҪз»ҙжҢҒзҺ°зҠ¶гҖӮ
еҸҜд»Ҙйў„жңҹзҡ„жҳҜпјҢHBase2.0жҖ§иғҪеҝ…е®ҡжҳҜжңқжӣҙеҘҪж–№еҗ‘еҸ‘еұ•зҡ„пјҢе°Өе…¶жҳҜGCеҜ№P999зҡ„еҪұе“Қдјҡи¶ҠжқҘи¶Ҡе°ҸгҖӮ
- end -
еҸӮиҖғиө„ж–ҷпјҡ
https://people.freebsd.org/~jasone/jemalloc/bsdcan2006/jemalloc.pdf
https://www.facebook.com/notes/facebook-engineering/scalable-memory-allocation-using-jemalloc/480222803919/
https://netty.io/wiki/reference-counted-objects.html






