这篇文章主要介绍“怎么用UTF-8解决GBK中生僻字乱码问题”,在日常操作中,相信很多人在怎么用UTF-8解决GBK中生僻字乱码问题问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”怎么用UTF-8解决GBK中生僻字乱码问题”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
GBK字符集中 很多生僻字都无法显示,或者虽然能显示 但是使用正则表达式过滤之后,发现生僻字被过滤掉了。系统认为生僻字并非汉字。
先创建一个GBK数据库
打开数据库后执行SQL
CREATE TABLE "SYSDBA"."T1"
(
"A" VARCHAR2(50)) ;
insert into t1
values('于彬');
SELECT A,regexp_replace(A,'[[:punct:]]') FROM T1
将数据插入到表中并且使用正则进行筛选
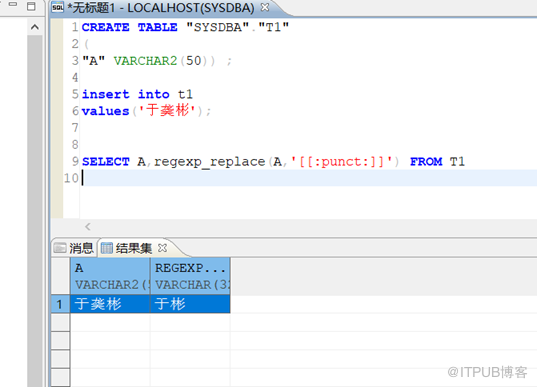
发现筛选后。中间的汉字没有了。现在创建一个 UTF-8的数据库。
将这条数据使用DTS迁移到新的UTF-8库中
再次执行该正则表达式SQL
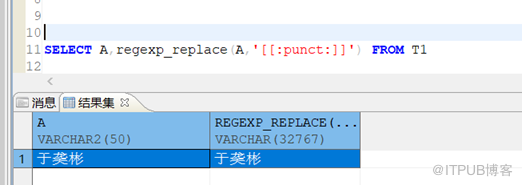
UTF-8确实可以稍微减少生僻字过滤或者显示错误的问题,
但是这些只是部分补救办法。最好的办法还是在一开始沟通好需求,如果存在生僻字的情况直接使用UTF-8字符集
到此,关于“怎么用UTF-8解决GBK中生僻字乱码问题”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/69949798/viewspace-2661600/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



