@?/rdbms/admin/awrrpt.sql -- ж ҮеҮҶжҠҘе‘ҠпјҢзү№е®ҡж—¶й—ҙж®өеҶ…жҖ»дҪ“жҖ§иғҪжҠҘе‘Ҡ
@?/rdbms/admin/awrddrpt.sql -- еҜ№жҜ”жҠҘе‘ҠпјҢдёӨдёӘж—¶й—ҙж®өеҶ…жҖ§иғҪеҜ№жҜ”
@?/rdbms/admin/ashrpt.sql -- ASHжҠҘе‘ҠпјҢзү№е®ҡж—¶й—ҙж®өеҶ…еҺҶеҸІдјҡиҜқжҖ§иғҪжҠҘе‘Ҡ
@?/rdbms/admin/awrsqrpt.sql -- SQLжҠҘе‘ҠпјҢзү№е®ҡж—¶й—ҙж®өеҶ…SQLжҖ§иғҪжҠҘе‘Ҡ
AWR/ASHжҠҘе‘ҠеҫҲдёҚй”ҷпјҢдҪҶд№ҹжңүдёҖдәӣзјәйҷ·гҖӮ
-
йҰ–е…ҲпјҢAWRеҸҚеә”зҡ„жҳҜзӮ№еҜ№зӮ№зҡ„ж•°жҚ®гҖӮ
жҜ”еҰӮиҜҙпјҢжҲ‘з”ҹжҲҗдёҖдёӘд»ҠеӨ©9:00еҲ°12:00зҡ„AWRжҠҘе‘ҠпјҢйӮЈд№ҲпјҢжҲ‘зңӢеҲ°зҡ„пјҢе°ұжҳҜ12:00е’Ң9:00дёӨдёӘж—¶й—ҙзӮ№зҡ„еҸҳеҢ–гҖӮдҪҶжҳҜпјҢ9:00-10:00, 10:00-11:00,11:-12:00 еҲҶеҲ«жҳҜд»Җд№Ҳж ·зҡ„пјҢжҲ‘们зңӢдёҚеҲ°гҖӮ
-
еҸҰеӨ–дёҖдёӘй—®йўҳпјҢAWRжҠҠж•°жҚ®йғҪзҪ—еҲ—еҮәжқҘпјҢдҪҶеҚҙзјәд№Ҹж•°жҚ®й—ҙзҡ„иҒ”зі».
-
AWRж··е…ҘеӨ§йҮҸж— з”Ёж•°жҚ®
, еҜјиҮҙз”ҹжҲҗAWRжҠҘе‘ҠйңҖиҰҒ30з§’еҲ°еҮ еҲҶй’ҹзҡ„ж—¶й—ҙпјҢжүҖд»ҘпјҢеҰӮжһңжҲ‘们жңүиЈёж•°жҚ®пјҢе…¶е®һеҸҜд»Ҙжӣҙй«ҳж•ҲпјҢжӣҙж·ұе…Ҙзҡ„жҢ–жҺҳOracleж•°жҚ®еә“зҡ„жҖ§иғҪдҝЎжҒҜгҖӮ
еңЁиЈёж•°жҚ®йҮҢйқўпјҢи®°еҪ•зҡ„еҗ„з§ҚжҢҮж Үдё»иҰҒжңү4зұ»
жңҖеӨҡзҡ„дёҖз§Қ
жҳҜ"зҙҜи®ЎеҖј"
дёҫдёӘдҫӢеӯҗ dba_hist_sysstat йҮҢдјҡи®°еҪ•ж•°жҚ®еә“зҡ„йҖ»иҫ‘иҜ»гҖӮи®°еҪ•зҡ„дёҚжҳҜиҝҷдёҖдёӘе°Ҹж—¶дә§з”ҹзҡ„йҖ»иҫ‘иҜ»пјҢиҖҢжҳҜд»Һж•°жҚ®еә“еҗҜеҠЁеҲ°дә§з”ҹеҝ«з…§зҡ„ж—¶еҖҷзҡ„жҖ»зҡ„йҖ»иҫ‘иҜ»гҖӮиҝҷе°ұеҸ«зҙҜи®ЎеҖјпјҢеӨ§еӨҡж•°зҡ„жҢҮж Үзҡ„жҳҜзҙҜи®ЎеҖјгҖӮ
д№ҹжңүйғЁеҲҶж•°жҚ®и®°еҪ•зҡ„жҳҜ"
еҪ“еүҚеҖј"
жҜ”еҰӮиҜҙпјҢж•°жҚ®еә“еҪ“еүҚзҡ„PGAдҪҝз”ЁйҮҸпјҢж•°жҚ®еә“зҡ„дјҡиҜқж•°зӯүпјҢиҝҳжңүжҜ”иҫғзү№ж®Ҡзҡ„пјҢдјҡи®°еҪ•дёӨж¬Ўеҝ«з…§д№Ӣй—ҙзҡ„еҸҳеҢ–еҖјгҖӮжҲ‘们еҸҜд»Ҙи®ӨдёәпјҢиҝҷжҳҜдёҖз§Қйў„и®Ўз®—пјҢжңҖеёёи§Ғзҡ„и®°еҪ•еҸҳеҢ–еҖјзҡ„дёӨзұ»ж•°жҚ®пјҢеҲҶеҲ«жҳҜSQLзӣёе…із»ҹи®ЎдҝЎжҒҜпјҢд»ҘеҸҠж®ө(segment)зӣёе…із»ҹи®ЎдҝЎжҒҜпјҢеҪ“然пјҢSQL/Segmentи®°еҪ•еҸҳеҢ–еҖјзҡ„еҗҢж—¶пјҢд№ҹи®°еҪ•дәҶзҙҜи®ЎеҖјгҖӮ
иҝҳжңүдёҖзұ»пјҢи®°еҪ•зҡ„жҳҜ
вҖқз»ҹи®ЎеҖјвҖң
е°ұжҳҜжҠҠдёҖж®өж—¶й—ҙеҶ…зҡ„ж•°жҚ®пјҢеҒҡдәҶз»ҹи®Ўд№ӢеҗҺдҝқеӯҳдәҶиө·жқҘпјҢиҝҷдәӣдё»иҰҒжҳҜMETRICзұ»зҡ„ж•°жҚ®гҖӮжҜ”еҰӮиҜҙпјҢжҜҸз§’CPU, жҜҸз§’жңҖеӨ§зӯүеҫ…ж—¶й—ҙзӯүгҖӮ
еҜ№дәҺDBAжқҘиҜҙпјҢжңҖе…іеҝғзҡ„дёҖиҲ¬жҳҜ
еҸҳеҢ–еҖј
пјҢ
дёӨж¬Ўеҝ«з…§д№Ӣй—ҙзҡ„еҸҳеҢ–йҮҸгҖӮиҝҷжҳҜдёҖдёӘз®ҖеҚ•зҡ„SQL, иҺ·еҸ–ж•°жҚ®еә“зҡ„еҺҶеҸІжҖ§иғҪдҝЎжҒҜйҮҢзҡ„redo size дҝЎжҒҜ
select SNAP_ID,STAT_NAME,VALUE from DBA_HIST_SYSSTAT
where STAT_NAME=вҖҳredo sizeвҖҷ order by snap_id;
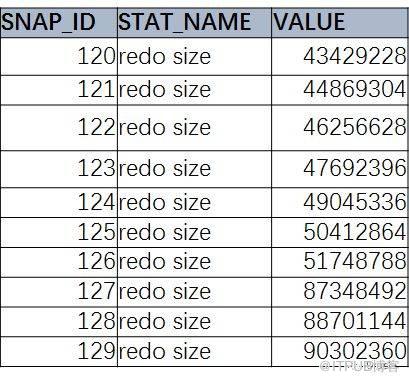
жҲ‘们зҺ°еңЁзңӢеҲ°зҡ„пјҢе°ұжҳҜзҙҜи®ЎеҖјгҖӮйӮЈд№ҲпјҢжҖҺд№Ҳж–№дҫҝзҡ„иҺ·еҸ–еҸҳеҢ–еҖје‘ўпјҹ
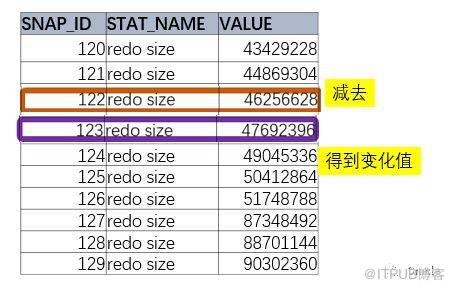
1гҖҒ
иҰҒеҸ–еҫ—еҸҳеҢ–еҖј
пјҢйңҖиҰҒеҸ–еҮәеҗҺйқўзҡ„и®°еҪ•пјҢеҮҸеҺ»еүҚйқўзҡ„и®°еҪ•гҖӮ
еҰӮжһңд»…д»…жҳҜдёӨдёӘж—¶й—ҙзӮ№пјҢжңҖз®ҖеҚ•зҡ„ж–№жі•е°ұжҳҜи®ҝй—®иҝҷдёӘиЎЁдёӨж¬ЎпјҢ然еҗҺзӣёеҮҸгҖӮ
select a.value - b.value
from DBA_HIST_SYSSTAT A,DBA_HIST_SYSSTAT B
where A.STAT_NAME=вҖҳredo sizeвҖҷ and
A.STAT_NAME = B.STAT_NAME and a.snap_id = 123 and b.snap_id = 122
иҝҷж ·еҫ—еҲ°жҳҜдёӨдёӘзӮ№д№Ӣй—ҙзҡ„е·®еҖјпјҢдҪҶжҳҜеҜ№жҲ‘们жқҘиҜҙпјҢзҺ©зҺ©жҳҜдёҚеӨҹзҡ„гҖӮ
2гҖҒжңүж—¶еҖҷпјҢжҲ‘们еёҢжңӣеҫ—еҲ°дёҖдёӘж—¶й—ҙж®өеҶ…пјҢжҜҸдёӨдёӘиҝһз»ӯеҝ«з…§д№Ӣй—ҙзҡ„
еҸҳеҢ–еҖј
гҖӮжҜ”еҰӮиҜҙпјҢ9:00-21:00, жҲ‘们еёҢжңӣиҺ·еҫ— 9:00-10:00, 10:-11:00... 20:00-21:00, жҜҸдёӘж—¶й—ҙж®өеҲҶеҲ«зҡ„еҸҳеҢ–еҖјгҖӮ
иҝҷйҮҢе°ұж¶үеҸҠеҲ°Oracleзҡ„еҲҶжһҗеҮҪж•°дәҶ
еҲҶжһҗеҮҪж•°
Oracleзҡ„еҲҶжһҗеҮҪж•°жҸҗдҫӣдәҶеңЁдёҖдёӘз»“жһңйӣҶеҶ…пјҢи·ЁиЎҢи®ҝй—®ж•°жҚ®зҡ„иғҪеҠӣгҖӮ
еҲҶжһҗеҮҪж•°йҮҢйқўзҡ„LEAD/LAGжӯЈжҳҜи·ЁиЎҢиҺ·еҸ–ж•°жҚ®зҡ„еҲ©еҷЁ
LAG : еҗҢдёҖз»„еҶ…пјҢжҺ’еңЁеҪ“еүҚиЎҢд№ӢеүҚзҡ„ж•°жҚ®
LEAD : еҗҢдёҖз»„еҶ…пјҢжҺ’еңЁеҪ“еүҚиЎҢд№ӢеҗҺзҡ„ж•°жҚ®

еҰӮеӣҫжүҖзӨәпјҢеҸҜд»ҘзңӢеҲ°пјҢжҲ‘们иҰҒзҡ„жҳҜжӢҝеҪ“еүҚvalue еҮҸеҺ» lag valueгҖӮ
select snap_id,stat_name,
value-lag(value) over
(partition by stat_name order by snap_id)
from dba_hist_sysstat
where stat_name = 'redo size'
order by snap_id;
иҝҷе°ұжҳҜеҲҶжһҗеҮҪж•°LAGзҡ„е®Ңж•ҙиҜӯжі•гҖӮ
3гҖҒ
жҲ‘们дёҖиҲ¬дёҚдјҡж»Ўи¶іиҺ·еҸ–дёҖдёӘжҢҮж Үзҡ„еҸҳеҢ–еҖјзҡ„пјҢдёӢйқўзҡ„иЎЁпјҢжүҚжҳҜжҲ‘们еёҢжңӣиҺ·еҫ—зҡ„гҖӮ
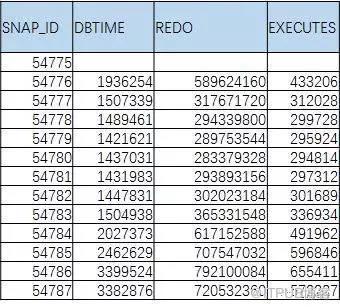
иҝҷйҮҢеҸҲеј•е…ҘдәҶиҝӣйҳ¶SQLзҡ„еҸҰдёҖдёӘеҶҷжі•
пјҡиЎҢеҲ—иҪ¬жҚўгҖӮ

еӨ§е®¶еҸҜд»ҘдҪ“дјҡдёҖдёӢпјҢеҰӮдҪ•дҪҝз”Ёsum(case when .. then .. end )жҲ–иҖ…max(case when .. then .. end )зҡ„еҪўејҸзҡ„еҪўејҸжқҘиҝӣиЎҢиЎҢеҲ—иҪ¬жҚў
пјҢдҪҶз”ЁCase whenжқҘеҶҷиЎҢеҲ—иҪ¬жҚўпјҢеҫҲе®№жҳ“дҪҝSQLеҶ—й•ҝпјҢиҖҢдё”е®№жҳ“еҮәй”ҷгҖӮ
Oracle 11gдёӯпјҢжҸҗдҫӣдәҶжӣҙж–№дҫҝзҡ„ж–№ејҸиҝӣиЎҢиЎҢеҲ—иҪ¬жҚў

еӨ§е®¶еҸҜд»ҘзңӢеҲ°пјҢж Үй»„еӨ§еҶҷзҡ„PIVOTпјҢ жӯЈжҳҜOracle 11gдёӯеј•е…Ҙзҡ„иЎҢеҲ—иҪ¬жҚўеҲ©еҷЁгҖӮ
дҪҝз”ЁPIVOT, еўһеҮҸжҢҮж ҮжһҒе…¶з®ҖеҚ•пјҡ

еҫҲиҪ»жқҫе°ұеҠ дәҶдёӨдёӘжҢҮж ҮпјҢеҰӮжһңи§үеҫ—еҲ—еҗҚдёҚеҘҪзңӢпјҢд№ҹеҸҜд»ҘиҮӘе·ұжҢҮе®ҡгҖӮ
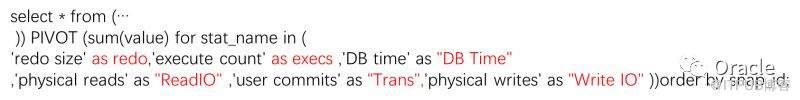
е…¶е®һпјҢжҲ‘们еҸҜд»ҘеҫҲиҪ»жқҫзҡ„е°ұжҠҠAWRжҠҘе‘Ҡдёӯзҡ„"Load Profile"йғЁеҲҶйҖҡиҝҮиЎҢеҲ—иҪ¬жҚўз»ҷеҸ–еҮәжқҘпјҢиҖҢдё”пјҢжҳҜеӨҡдёӘиҝһз»ӯеҸҳеҢ–зҡ„еҖјгҖӮ

жҠҠи·‘зҡ„з»“жһңжӢ·еҲ°Excel, еҫҲе®№жҳ“е°ұеҮәжқҘдёҖдёӘжјӮдә®зҡ„и¶ӢеҠҝеӣҫгҖӮ

дҪҶжҳҜпјҢиҝҷдёӘеӣҫжҳҜжңүй—®йўҳзҡ„пјҡ
еӣҫйҮҢзҡ„REDO SizeжҳҜд»ҘbyteдёәеҚ•дҪҚзҡ„пјҢеҖјеӨӘеӨ§пјҢжҠҠеҲ«зҡ„жҢҮж Үз»ҹз»ҹеҺӢеҲ°е’Ң0е·®дёҚеӨҡпјҢеӨҡдёӘжҢҮж ҮиҰҒеҲ°еҗҢдёҖдёӘеӣҫпјҢиҝҳиғҪзңӢеҮәеҗ„иҮӘзҡ„и¶ӢеҠҝпјҢеҜ№дәҺеӨҡжҢҮж Үе…іиҒ”зҡ„еҲҶжһҗеҫҲжңүдҪңз”ЁгҖӮ
иҝҷж—¶еҖҷпјҢеҸҲжңүдёҖдёӘеҲҶжһҗеҮҪж•°еҮәжқҘдәҶгҖӮжІЎй”ҷпјҢеӣ дёәжҲ‘们жҳҜеңЁеҜ№Oracleзҡ„жҖ§иғҪж•°жҚ®иҝӣиЎҢеҲҶжһҗпјҢжүҖд»ҘпјҢйңҖиҰҒеӨ§йҮҸзҡ„дҪҝз”ЁвҖқеҲҶжһҗеҮҪж•°вҖң
еҲҶжһҗеҮҪж•°пјҡ Ratio_To_Report жұӮеҪ“еүҚиЎҢж•°жҚ®еңЁжүҖжңүеҗҢз»„ж•°жҚ®еҶ…еҚ зҡ„жҜ”дҫӢгҖӮ
жҜ”еҰӮиҜҙпјҢжҲ‘зҡ„з»“жһңйӣҶйҮҢжңү3иЎҢпјҢеҲҶеҲ«жҳҜ1,3,6. йӮЈд№Ҳ1еҜ№еә”зҡ„йӮЈдёҖиЎҢпјҢеҚ жҖ»ж•°жҚ®(1+3+6)зҡ„10%, еҮәжқҘзҡ„з»“жһңе°ұжҳҜ0.1пјҲ10%пјү.

select * from (
select snaptime,RATIO_TO_REPORT(value) over(partition by stat_name) value,stat_name,snap_id
from (вҖҰ )) PIVOT (sum(value) for stat_name in (
вҖҰ))order by snap_id;
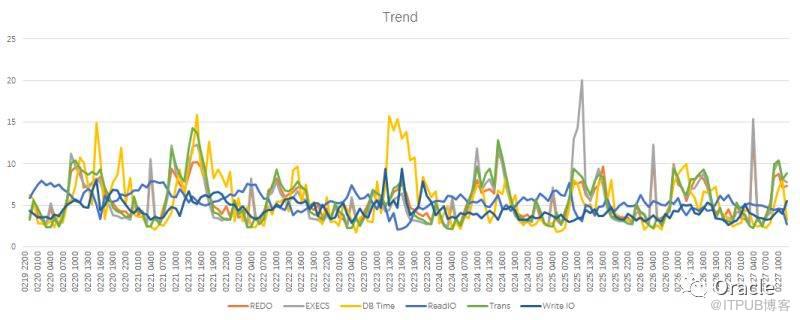
еңЁиҝҷдёӘеӣҫйҮҢйқўпјҢеӨ§е®¶е°ұйғҪе№ізӯүдәҶпјҢд№ҹжӣҙж–№дҫҝзҡ„еҺ»зңӢеҗ„дёӘжҢҮж Үд№Ӣй—ҙжҳҜеҗҰеӯҳеңЁе…іиҒ”

еҶҚз»ҷеӨ§е®¶зңӢеҸҰдёҖдёӘSQL, иҝҳжҳҜratio_to_report, иҝҷж¬ЎпјҢжҲ‘们жӢҝеҲ°зҡ„з»“жһңпјҢе…¶е®һжҳҜAWRжҠҘе‘ҠйҮҢеҸҰдёҖдёӘйқһеёёйҮҚиҰҒзҡ„ж•°жҚ®:
Top Timed Events
жҲ‘жҠҠжҜҸдёӘж—¶й—ҙж®өзҡ„CPUж—¶й—ҙе’Ңйқһз©әй—ІдәӢ件з»ҷж”ҫеңЁдёҖиө·пјҢ然еҗҺи®Ўз®—жҜҸдёӘдәӢ件(еҗ«CPU)еңЁжҜҸдёӘж—¶й—ҙж®өеҚ зҡ„зҷҫеҲҶжҜ”пјҢе°ұеҫ—еҲ° Top Timed EventsпјҢиҖҢдё”жҳҜиҝһз»ӯзҡ„еӨҡдёӘж—¶й—ҙзҡ„ж•°жҚ®гҖӮ
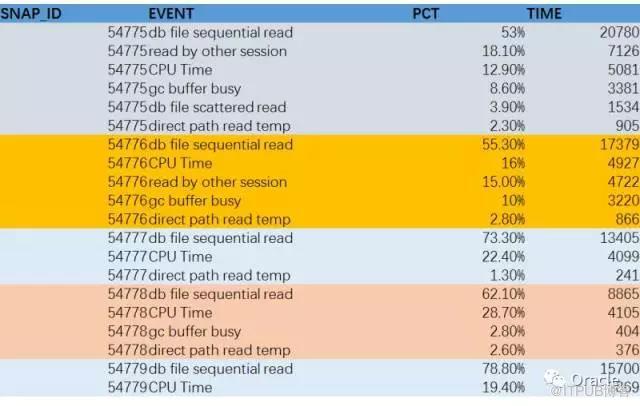
еңЁзңӢAWRж—¶пјҢжңүеҮ дёӘеҢәеҹҹжҳҜеҝ…зңӢзҡ„гҖӮ
еҸӮиҖғеүҚйқўз”ЁжқҘжј”зӨәlag() еҮҪж•°зҡ„йғЁеҲҶпјҡ
select * from (select snap_id,STAT_NAME,
value-lag(value) over(partition by STAT_NAME
order by snap_id) value
from dba_hist_sysstat where stat_name in (
вҖҳredo sizeвҖҷ,вҖҳexecute countвҖҷ,вҖҳDB timeвҖҷ,вҖҳphysical readsвҖҳ
) ) PIVOT (sum(value) for stat_name in (
'redo size','execute count','DB time','physical readsвҖҳ
))order by snap_id;
жҠҠstat_nameйҮҢйқўзҡ„йғЁеҲҶпјҢеҠ дёҠLOAD PROFILEзҡ„е…¶д»–жҢҮж ҮпјҢе°ұжҳҜдёӘе®Ңж•ҙзҡ„load profileдәҶгҖӮ
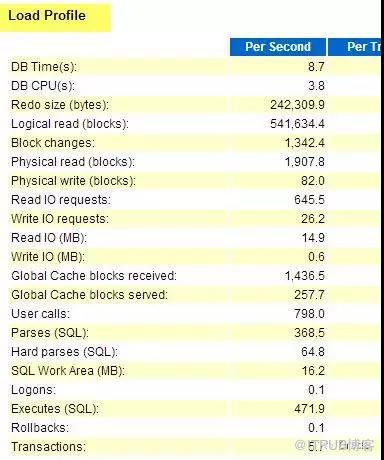
йҖҡиҝҮload profile, еӨ§е®¶еҸҜд»ҘеҜ№зі»з»ҹзҡ„жҖ»дҪ“иҙҹиҪҪжңүдёӘеҮҶзЎ®зҡ„и®ӨиҜҶгҖӮ
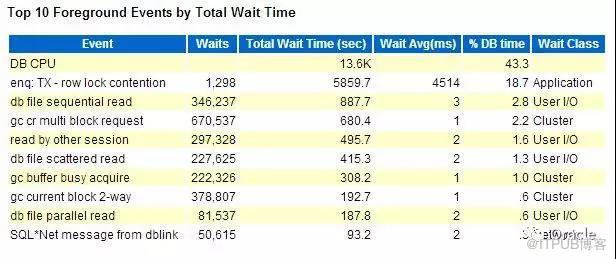
йҖҡиҝҮиҝҷдёӘйғЁеҲҶпјҢеӨ§е®¶еҸҜд»ҘдәҶи§Јж•ҙдёӘзі»з»ҹзҡ„жҖ§иғҪ瓶йўҲ:
select snap_id,event,pct||'%' PCT,time from (
select snap_id,event,round(time)time,
round(RATIO_TO_REPORT(TIME) over(partition by snap_id)*100,1) pct
from( select 'CPU Time' EVENT,snap_id,value/100 - LAG(value)over(partition by stat_name order by snap_id)/100 TIME
from DBA_HIST_SYSSTAT where stat_name = 'CPU used by this session'
union all select event_name,snap_id, time_waited_micro/1e6 -
LAG(time_waited_micro) over(partition by event_name order by snap_id)/1e6
from DBA_HIST_SYSTEM_EVENT where wait_class!='Idle'
)where time>0) where pct>1 order by snap_id,time desc
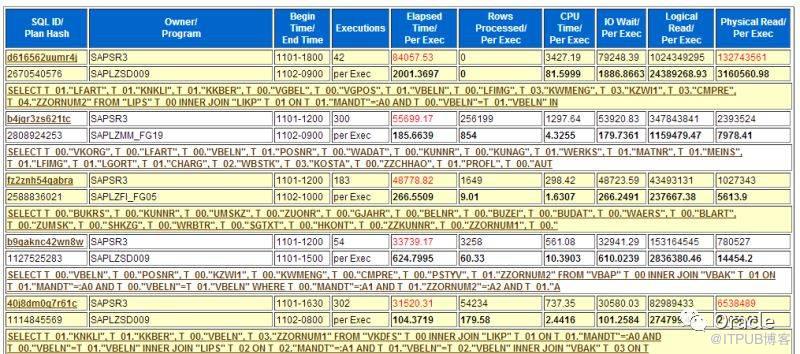
йҖҡиҝҮTop SQL, жҲ‘们еҸҜд»ҘдәҶи§Јзі»з»ҹиҝҗиЎҢиҝҮе“Әдәӣдё»иҰҒзҡ„иҜӯеҸҘгҖӮ
дҪҶжҳҜпјҢдј з»ҹзҡ„AWRжҠҘе‘Ҡдёӯзҡ„Top SQLжҳҜжңүзјәйҷ·зҡ„гҖӮжңҖдё»иҰҒзҡ„й—®йўҳпјҢе®ғзҡ„дҝЎжҒҜжҳҜеҲҶж•Јзҡ„гҖӮ
еңЁеҜ№SQLиҝӣиЎҢеҲӨж–ӯж—¶пјҢжҲ‘дјҡз»“еҗҲеӨҡдёӘжҢҮж ҮгҖӮжү§иЎҢж—¶й—ҙ(elapsed Time)гҖҒCPUж—¶й—ҙ(CPU Time)гҖҒйҖ»иҫ‘иҜ»(Buffer gets)гҖҒзү©зҗҶиҜ»(disk reads)гҖҒжү§иЎҢж¬Ўж•°пјҲexecutionsпјүгҖҒиҝ”еӣһиЎҢж•°пјҲrows_processedпјү,дҪҶжҳҜпјҢдј з»ҹзҡ„awrжҠҘе‘ҠпјҢиҝҷдәӣжҢҮж ҮеҲҶеёғеңЁдёҚеҗҢдҪҚзҪ®гҖӮзңӢиө·жқҘеҫҲдёҚж–№дҫҝгҖӮ
жҜ”еҰӮиҜҙиҝҷдёӘпјҢжңүжү§иЎҢж—¶й—ҙпјҢжү§иЎҢж¬Ўж•°пјҢCPUж—¶й—ҙгҖӮдҪҶзјәд№ҸйҖ»иҫ‘иҜ»пјҢзү©зҗҶиҜ»пјҢиҝ”еӣһиЎҢж•°зӯүпјҢжңүж—¶еҖҷпјҢиҝҳеҫ—дё“й—ЁеҺ»жүҫгҖӮ
жүҖд»Ҙе‘ўпјҢжҲ‘з»Ҹеёёи®ҝй—®иЈёж•°жҚ®пјҢдҪҝз”ЁSQL, зӣҙжҺҘд»Һж•°жҚ®еә“йҮҢеҸ–еҮәеҢ…еҗ«е®Ңж•ҙдҝЎжҒҜзҡ„Top SQL.
еҸҰеӨ–пјҢж №жҚ®дёҚеҗҢзҡ„жғ…еҶөпјҢжҲ‘们еҸҜиғҪе…іеҝғзҡ„зӮ№д№ҹдёҚдёҖж ·гҖӮ
жҜ”еҰӮиҜҙпјҢзі»з»ҹCPUж¶ҲиҖ—дёҘйҮҚпјҢжҲ‘们жӣҙе…іеҝғSQL order by CPU, I/OдёҘйҮҚж—¶пјҢе…іеҝғзҡ„еҲҷжҳҜзү©зҗҶиҜ»гҖӮжүҖд»ҘжҲ‘з”Ёзҡ„SQL, еҸҜд»Ҙж”ҜжҢҒеҗҢж—¶еҸ–еҮәжҢүдёҚеҗҢжҢҮж Үзҡ„жҺ’еәҸзҡ„Top N SQL.
жҜ”еҰӮиҜҙпјҢ Top 10 by elapsed time, Top 10 by CPU, Top 10 by disk reads.
еӨ§е®¶йғҪзҹҘйҒ“пјҢдј з»ҹзҡ„order by + rownum < N зҡ„ж–№ејҸеҸӘж”ҜжҢҒеҜ№е…¶дёӯдёҖдёӘжҢҮж ҮиҝӣиЎҢжҺ’еҗҚпјҢжҳҫ然жҳҜдёҚеӨҹзҡ„гҖӮиҖҢеҲҶжһҗеҮҪж•°пјҢеҸҲеҶҚж¬ЎеҸ‘жҢҘдәҶдҪңз”ЁгҖӮ
select sql.*, (select SQL_TEXT from dba_hist_sqltext t
where t.sql_id = sql.sql_id and rownum=1 ) SQLTEXT
from (select a.* ,
RANK() over( order by els desc) as r_els,
RANK() over( order by phy desc) as r_phy,
RANK() over( order by get desc) as r_get,
RANK() over( order by exe desc) as r_exe,
RANK() over( order by CPU desc) as r_cpu
from (
select sql_id,sum(executions_delta) exe,round(sum(elapsed_time_delta
) / 1e6, 2) els
,round(sum(cpu_time_delta) / 1e6, 2) cpu,
round(sum(iowait_delta) / 1e6, 2) iow,sum(buffer_gets_delta) get,
sum(disk_reads_delta) phy,sum(rows_processed_delta) RWO,
round(sum(elapsed_time_delta) / greatest(sum(executions_delta), 1) / 1e6,4) elsp,
round(sum(cpu_time_delta) / greatest(sum(executions_delta), 1) / 1e6, 4) cpup,
round(sum(iowait_delta) / greatest(sum(executions_delta), 1) / 1e6, 4) iowp,
round(sum(buffer_gets_delta) / greatest(sum(executions_delta), 1), 2) getp,
round(sum(disk_reads_delta) / greatest(sum(executions_delta), 1), 2) phyp,
round(sum(rows_processed_delta) / greatest(sum(executions_delta), 1), 2) ROWP
from dba_hist_sqlstat s
--where snap_id between ... and ...
group by sql_id
) a
)SQL where r_els <= 10 or r_phy <=10 or r_cpu<=10 order by els desc
еӨ§е®¶еҸҜд»ҘзңӢеҲ°пјҢиҝҷйҮҢйқўз”ЁеҲ°дәҶ RANK() еҮҪж•°гҖӮиҝҷдёӘеҮҪж•°еҸҜд»Ҙеҫ—еҮәж №жҚ®жҹҗдёӘжҢҮж ҮжҺ’еәҸзҡ„жҺ’еҗҚгҖӮ然еҗҺеҶҚйҖҡиҝҮжңҖеҗҺзҡ„ r_els <= 10 or r_phy <=10 or r_cpu<=10 зҡ„иҝҮж»ӨжқЎд»¶пјҢе°ұеҸҜд»ҘиҺ·еҸ–жҢүз…§еӨҡдёӘжҢҮж ҮжҺ’еәҸзҡ„Top NдәҶгҖӮ
жңүж—¶еҖҷпјҢжҲ‘дјҡжҠҠиҝҷдёӘз»“жһңжғіеҠһжі•еҒҡжҲҗHTML, е°ұеҸҳжҲҗиҝҷдёӘж•ҲжһңдәҶгҖӮ
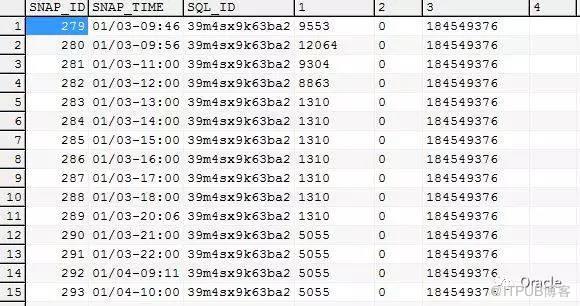
еңЁеҲҶжһҗSQLдёӯпјҢиҝҳжңүеҫҲйҮҚиҰҒзҡ„дҝЎжҒҜгҖӮ
第дёҖдёӘжҳҜжү§иЎҢи®ЎеҲ’гҖӮ
select * from table(dbms_xplan.display_awr('&SQLID'))
йҷӨдәҶжү§иЎҢи®ЎеҲ’пјҢиҝҳжңүдёҖдёӘдҝЎжҒҜдёҚеҸҜжҲ–зјәпјҢе°ұжҳҜз»‘е®ҡеҸҳйҮҸгҖӮ
жҲ‘зў°еҲ°зҡ„SQLй—®йўҳйҮҢйқўпјҢжңүдёҖдёӘе…ёеһӢеҲҶзұ»пјҢе°ұжҳҜSQLжң¬жқҘжү§иЎҢеҘҪеҘҪзҡ„пјҢзӘҒ然еҸҳе·®гҖӮиҝҷж—¶еҖҷпјҢеңЁеҲҶжһҗж—¶пјҢйңҖиҰҒеҫҲе…іжіЁзҡ„пјҢе°ұжҳҜеҺҶеҸІз»‘е®ҡеҸҳйҮҸгҖӮOracleеңЁAWRиЈёж•°жҚ®дёӯд№ҹдҝқз•ҷдәҶз»‘е®ҡеҸҳйҮҸ:
DBA_HIST_SQLSTAT.BIND_DATA иҝҷдёӘж ҸдҪҚйҮҢйқўпјҢдҝқеӯҳдәҶз»‘е®ҡеҸҳйҮҸ
йҖҡиҝҮд»ҘдёӢSQL, еҸҜд»ҘиҺ·еҸ–еҺҶеҸІз»‘е®ҡеҸҳйҮҸ:
select snap_id,sq.sql_id,bm.position, dbms_sqltune.extract_bind(sq.bind_data,bm.position).value_string value_string
from dba_hist_sqlstat sq ,dba_hist_sql_bind_metadata bm
where sq.sql_id = bm.sql_id --and sq.sql_id = '&sql'
еҮәжқҘзҡ„жҳҜиЎҢж јејҸзҡ„пјҢиҜ»иө·жқҘдёҚж–№дҫҝгҖӮз”ЁPIVOT еҒҡдёҖдёӘиЎҢеҲ—иҪ¬жҚўе°ұжјӮдә®дәҶгҖӮ
select * from ( select snap_id, to_char(sn.begin_interval_time,'MM/DD-HH24:MI') snap_time, sq.sql_id,bm.position, dbms_sqltune.extract_bind(bind_data,bm.position).value_string value_string from dba_hist_snapshot sn natural join dba_hist_sqlstat sq ,dba_hist_sql_bind_metadata bm
where sq.sql_id = bm.sql_id and sq.sql_id = '&sql'
) PIVOT (max(value_string) for position in (1,2,3,4,5,6,7,8,9,10))
order by snap_id
е®ҢзҫҺзҡ„еҸ–еҮәдёҚеҗҢж—¶й—ҙж®өзҡ„еҺҶеҸІз»‘е®ҡеҸҳйҮҸеҖј.
еҜ№дәҺвҖңSQLжң¬жқҘжү§иЎҢеҘҪеҘҪзҡ„пјҢзӘҒ然еҸҳе·®вҖқзҡ„й—®йўҳпјҢжңүдёҖдёӘжҜ”иҫғз®ҖжҙҒзҡ„и§ЈеҶіж–№ејҸпјҢе°ұжҳҜе°қиҜ•и®©SQLиө°еӣһд»ҘеүҚзҡ„жү§иЎҢи®ЎеҲ’гҖӮ
Select plan_hash_value ,Sum(Elapsed_time_Delta) /greatest(Sum(Executions_Delta),1),sum(Executions_Delta) From dba_hist_sqlstat where sql_id = '&SQLID' group by plan_hash_value ;
йҖҡиҝҮд»ҘдёҠSQL, еҸҜд»Ҙеҝ«йҖҹиҺ·еҸ–жҹҗдёӘSQLеӨҡдёӘжү§иЎҢи®ЎеҲ’зҡ„жү§иЎҢж•ҲжһңгҖӮ然еҗҺеҶҚжғіеҠһжі•еә”з”Ёе…¶жү§иЎҢи®ЎеҲ’пјҢеҫҖеҫҖеҸҜд»Ҙ收еҲ°еҘҮж•ҲгҖӮз»‘е®ҡжү§иЎҢи®ЎеҲ’зҡ„ж–№жі•жңүеӨҡз§ҚпјҢSPM/SQL Profile/SQL PatchзӯүпјҢе…·дҪ“жҲ‘е°ұдёҚеұ•ејҖдәҶгҖӮ
дёҚзҹҘйҒ“еӨ§е®¶жңүжІЎжңүзў°еҲ°иҝҮиҝҷж ·зҡ„жғ…еҶө, жңүж—¶еҖҷпјҢжҳҺжҳҺжҖ§иғҪ瓶йўҲеңЁSQL,дҪҶTop SQLдёӯDB Time(%)жҢҮж ҮеҚҙеҫҲдҪҺ,еүҚ10дёӘеҠ иө·жқҘд№ҹдёҚи¶і20%.
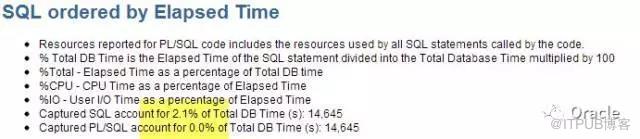
еғҸиҝҷдёӘAWR, Top SQL by elapsed TimeжүҚи®°еҪ•дәҶ2%. д№ҹе°ұжҳҜиҜҙпјҢдҪ еҸӘиғҪзңӢеҲ°2%зҡ„жҖ§иғҪзӣёе…ізҡ„SQL.
е…¶дёӯдёҖдёӘдё»иҰҒеҺҹеӣ жҳҜз”ұдәҺShared PoolеӨ§е°ҸйҷҗеҲ¶д»ҘеҸҠйқһз»‘е®ҡеҸҳйҮҸй—®йўҳпјҢеҜјиҮҙSQLеҸҜиғҪдјҡиў«жјҸи®°,
иҝҷз§Қжғ…еҶөдёӢпјҢжҖҺд№ҲеҠһе‘ўпјҹ
е…¶е®һпјҢжңүдёӘең°ж–№дёҚдјҡиў«жјҸи®°гҖӮе°ұжҳҜTop Segments.
йҖҡеёёпјҢеҰӮжһңTop SQLдёӯжүҫдёҚеҲ°еӨӘеӨҡдҝЎжҒҜпјҢжҲ‘们еҸҜд»ҘеҺ»зңӢзңӢTop Segments:
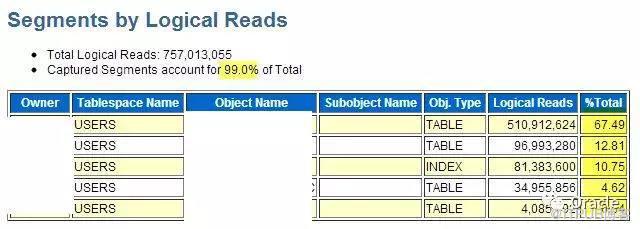
иҝҷжҳҜж‘ҳиҮӘеҗҢдёҖдёӘAWRзҡ„дҝЎжҒҜгҖӮ Top segments е‘ҠиҜүжҲ‘们пјҢеҜ№иЎЁзҡ„и®ҝй—®йӣҶдёӯеңЁеүҚйқў3дёӘпјҢжҲ‘们еҸҜд»Ҙдё“жіЁдәҺиҝҷеҮ дёӘиЎЁзҡ„й—®йўҳгҖӮ
еҪ“然пјҢ еҗҢж ·еҸҜд»ҘйҖҡиҝҮSQLзӣҙжҺҘи®ҝй—®иЈёж•°жҚ®иҺ·еҸ–зӣёе…ідҝЎжҒҜ:
Select begin_interval_time,seg.snap_id,PHYSICAL_READS_DELTA, object_name,subobject_name
from DBA_HIST_SEG_STAT SEG ,DBA_HIST_SEG_STAT_OBJ O , dba_hist_snapshot snap
where o.obj# = seg.obj# and o.dataobj# = seg.dataobj# and PHYSICAL_READS_DELTA > 1e5 and seg.snap_id = snap.snap_id
and begin_interval_time > sysdate - 4/24
order by PHYSICAL_READS_DELTA desc
иҝҷжҳҜдёҖдёӘеёёз”Ёзҡ„AWRиЈёж•°жҚ®зҡ„еҲ—иЎЁ:
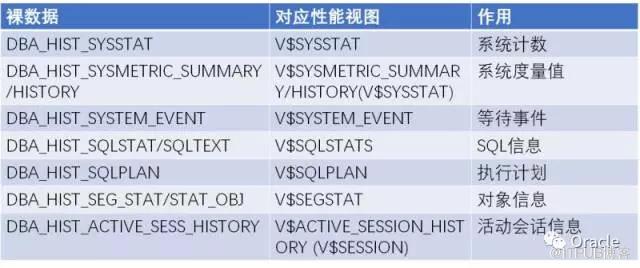 еӨҡж•°зҡ„AWRеҲҶжһҗеҸҜд»Ҙд»ҺиҝҷдәӣиЈёж•°жҚ®ејҖе§ӢгҖӮLoad Profile, Top Timed Event, Top SQL, SQL Plan, SQL з»‘е®ҡеҸҳйҮҸ, Top Segments,зӣёе…ізҡ„SQL йҷҶйҷҶз»ӯз»ӯйғҪиҙҙеҮәжқҘдәҶ.
еӨҡж•°зҡ„AWRеҲҶжһҗеҸҜд»Ҙд»ҺиҝҷдәӣиЈёж•°жҚ®ејҖе§ӢгҖӮLoad Profile, Top Timed Event, Top SQL, SQL Plan, SQL з»‘е®ҡеҸҳйҮҸ, Top Segments,зӣёе…ізҡ„SQL йҷҶйҷҶз»ӯз»ӯйғҪиҙҙеҮәжқҘдәҶ.
AWRиЈёж•°жҚ®еҰӮжӯӨзҡ„йҮҚиҰҒпјҢеҜ№дәҺе…іеҝғж•°жҚ®еә“жҖ§иғҪзҡ„DBA们пјҢжҲ‘们йңҖиҰҒеҘҪеҘҪзҡ„дҝқжҠӨеҘҪе®ғ们~
1. зі»з»ҹдҝқеӯҳж—¶й—ҙ,й»ҳи®Ө7еӨ©иҝңиҝңдёҚи¶іпјҢе»әи®®ж”№еҲ°30еӨ©д»ҘдёҠпјҢи·ЁиҝҮдёҖдёӘжңҲз»“е‘Ёжңҹ
2. йңҖиҰҒзҡ„ж—¶еҖҷпјҢжҲ‘们еҸҜд»ҘеҜ№иЈёж•°жҚ®иҝӣиЎҢзҰ»зәҝеӨҮд»Ҫ
@?/rdbms/admin/awrextr
3. з”ҡиҮіпјҢжҲ‘们еҸҜд»ҘжҠҠиЈёж•°жҚ®дё“й—ЁжүҫдёӘж•°жҚ®еә“еӯҳиө·жқҘпјҢдҪңдёәдёҖдёӘиө„ж–ҷеә“дҪҝз”ЁгҖӮ
@?/rdbms/admin/awrload
4. жңүж—¶еҖҷпјҢд№ҹеҸҜд»Ҙй’ҲеҜ№зү№е®ҡзҡ„иЎЁиҝӣиЎҢеӨҮд»ҪгҖӮжҜ”еҰӮиҜҙпјҢжҲ‘еҲҡеҲҡиҙҙзҡ„иҝҷдёӘеҲ—иЎЁ
д»ҘдёҠеҲҶдә«дё»иҰҒеҶ…е®№жҳҜпјҡ
1.
AWRзҡ„еҲҶжһҗеҠһжі•пјҡ
Load Profile, Top Timed Event, Top SQL, SQL Plan, SQL з»‘е®ҡеҸҳйҮҸ,Top Segments
2.
дёҖдәӣй«ҳзә§SQLз”Ёжі•:
еҲҶжһҗеҮҪж•° Lag/Rank/Ratio_to_report, иЎҢеҲ—иҪ¬жҚў PIVOT





