1、项目背景与分析说明
1)项目背景
网购已经成为人们生活不可或缺的一部分,本次项目基于淘宝app平台数据,通过相关指标对用户行为进行分析,从而探索用户相关行为模式。
2)数据和字段说明
本文使用的数据集包含了2014.11.18到2014.12.18之间,淘宝App移动端一个月内的用户行为数据。该数据有12256906天记录,共6列数据。
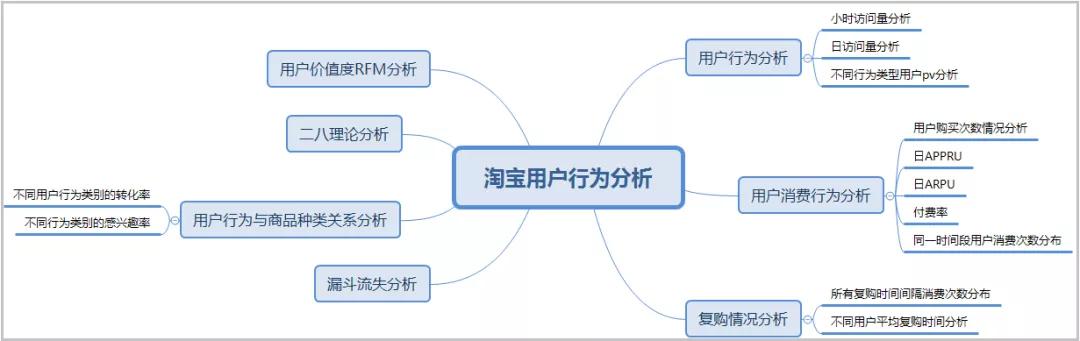
3)分析的维度
4)电商常用分析方法
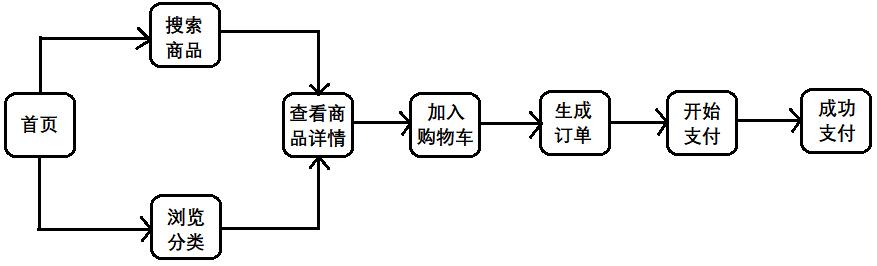
5)什么是漏斗分析?
“漏斗分析”是一套流程式数据分析,它能够科学反映用户行为状态,以及从起点到终点各阶段用户转化率情况的一种重要分析模型。
2、导入相关库
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
# 设置为seaborn绘图风格
sns.set(style="darkgrid",font_scale=1.5)
# 用来显示中文标签
mpl.rcParams["font.family"] = "SimHei"
# 用来显示负号
mpl.rcParams["axes.unicode_minus"] = False
# 有时候运行代码时会有很多warning输出,像提醒新版本之类的,如果不想这些乱糟糟的输出,可以使用如下代码
warnings.filterwarnings('ignore')
3、数据预览、数据预处理
# 注意:str是为了将所有的字段都读成字符串
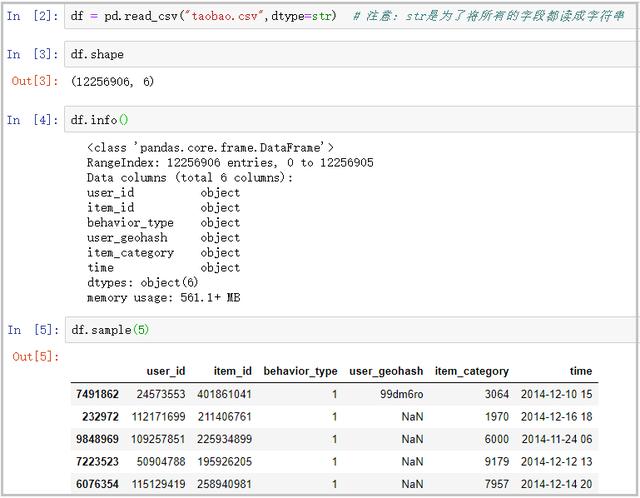
df = pd.read_csv("taobao.csv",dtype=str)
df.shape
df.info()
df.sample(5)
结果如下:
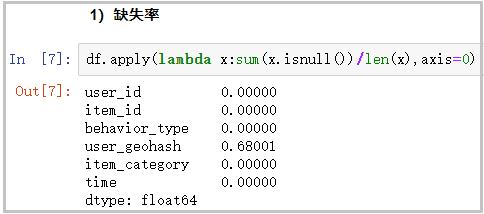
1)计算缺失率
# 由于地理位置的缺失值太多,我们也没办法填充,因此先删除这一列
df.apply(lambda x:sum(x.isnull())/len(x),axis=0)
结果如下:
2)删除地理位置这一列
df.drop(["user_geohash"],axis=1,inplace=True)
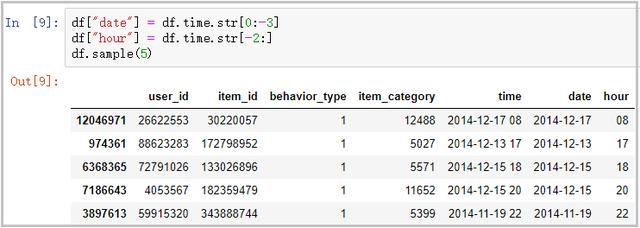
3)处理时间time列,将该列拆分为date日期列,和hour小时列
df["date"] = df.time.str[0:-3]
df["hour"] = df.time.str[-2:]
df.sample(5)
结果如下:
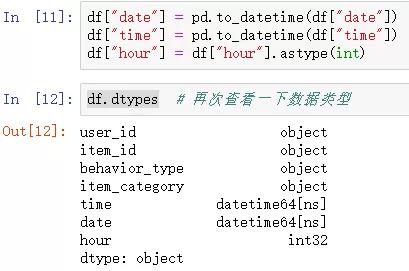
4)将time、date列都变为标准日期格式,将hour列变为int格式
df["date"] = pd.to_datetime(df["date"])
df["time"] = pd.to_datetime(df["time"])
df["hour"] = df["hour"].astype(int)
df.dtypes
结果如下:
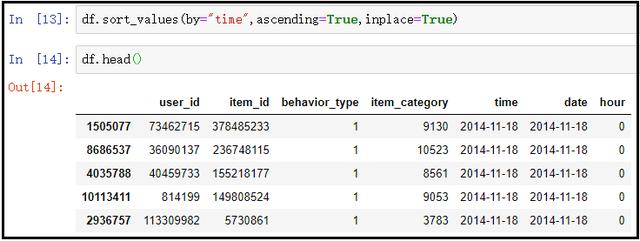
5)将数据按照time列,升序排列
df.sort_values(by="time",ascending=True,inplace=True)
df.head()
解果如下:
6)删除原始索引,重新生成新的索引
df.reset_index(drop=True,inplace=True)
df.head()
结果如下:
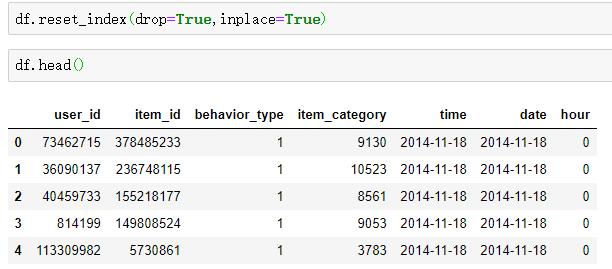
知识点:注意reset_index()中传入参数drop的这种用法。
7)使用describe()函数查看数据的分布,这里使用了一个include参数,注意一下
# 查看所有object字符串类型的数据分布状况
df.describe(include=["object"])
# describe()默认只会统计数值型变量的数据分布情况。
df.describe()
# 查看所有数据类型的数据分布状况
df.describe(include="all")
结果如下:
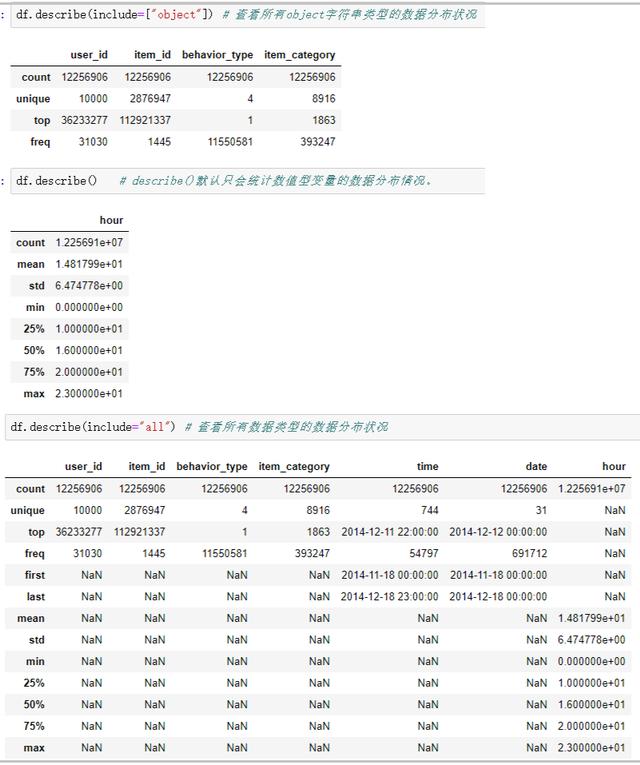
知识点:注意describe()函数中传入参数include的用法。
8)对时间数据做一个概览
df["date"].unique()
结果如下:
4、模型构建
1)流量指标的处理
pv:指的是页面总浏览量。每个用户每刷新一次网页,就会增加一次pv。
uv:指的是独立访客数。一台电脑一个ip也就是一个独立访客。实际分析中,我们都是认为每个人只使用一台电脑,即每一个独立访客代表一个用户。
① 总计pv和uv
total_pv = df["user_id"].count()
total_pv
total_uv = df["user_id"].nunique()
total_uv
结果如下:
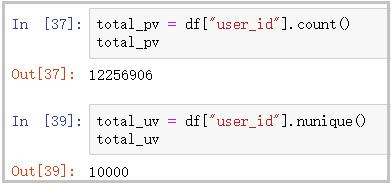
结果分析:从图中可以看到,该网站页面的总浏览量为12256906次,该页面的独立访客数共有10000个。
② 日期维度下的uv和pv:uv表示页面总浏览量,pv表示独立访客数
pv_daily = df.groupby("date")['user_id'].count()
pv_daily.head(5)
uv_daily = df.groupby("date")['user_id'].apply(lambda x: x.nunique())
# uv_daily = df.groupby("date")['user_id'].apply(lambda x: x.drop_duplicates().count())
uv_daily.head()
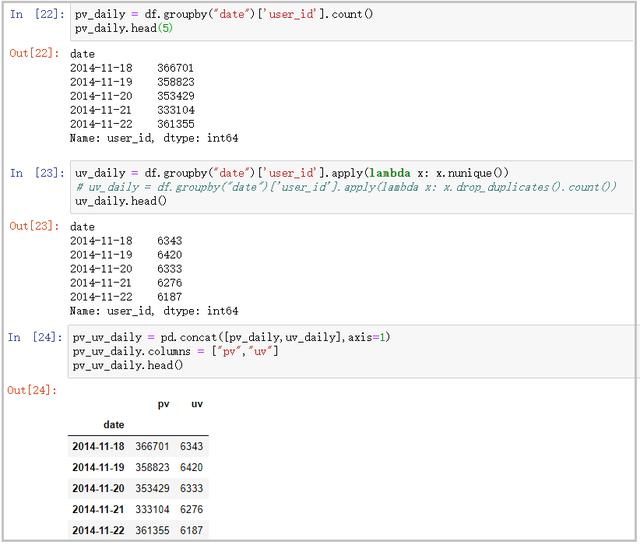
pv_uv_daily = pd.concat([pv_daily,uv_daily],axis=1)
pv_uv_daily.columns = ["pv","uv"]
pv_uv_daily.head()
# 绘图代码如下
plt.figure(figsize=(16,10))
plt.subplot(211)
plt.plot(pv_daily,c="r")
plt.title("每天页面的总访问量(PV)")
plt.subplot(212)
plt.plot(uv_daily,c="g")
plt.title("每天页面的独立访客数(UV)")
#plt.suptitle("PV和UV的变化趋势")
plt.tight_layout()
plt.savefig("PV和UV的变化趋势",dpi=300)
plt.show()
结果如下:
绘图如下:
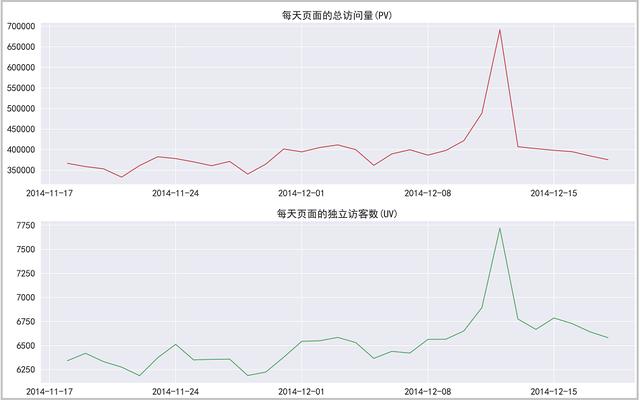
结果分析:从图中可以看出,pv和uv数据呈现高度的正相关。双12前后,pv和uv都在350000-400000之间波动,双十二的时候,页面访问量急剧上升,证明这次活动的效果很好。
③ 时间维度下的pv和uv
pv_hour = df.groupby("hour")['user_id'].count()
pv_hour.head()
uv_hour = df.groupby("hour")['user_id'].apply(lambda x: x.nunique())
uv_hour.head()
pv_uv_hour = pd.concat([pv_hour,uv_hour],axis=1)
pv_uv_hour.columns = ["pv_hour","uv_hour"]
pv_uv_hour.head()
# 绘图代码如下
plt.figure(figsize=(16,10))
pv_uv_hour["pv_hour"].plot(c="steelblue",label="每个小时的页面总访问量")
plt.ylabel("页面访问量")
pv_uv_hour["uv_hour"].plot(c="red",label="每个小时的页面独立访客数",secondary_y=True)
plt.ylabel("页面独立访客数")
plt.xticks(range(0,24),pv_uv_hour.index)
plt.legend(loc="best")
plt.grid(True)
plt.tight_layout()
plt.savefig("每个小时的PV和UV的变化趋势",dpi=300)
plt.show()
结果如下:
绘图如下:
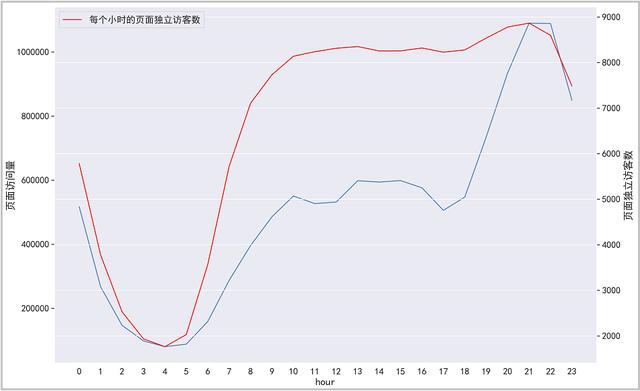
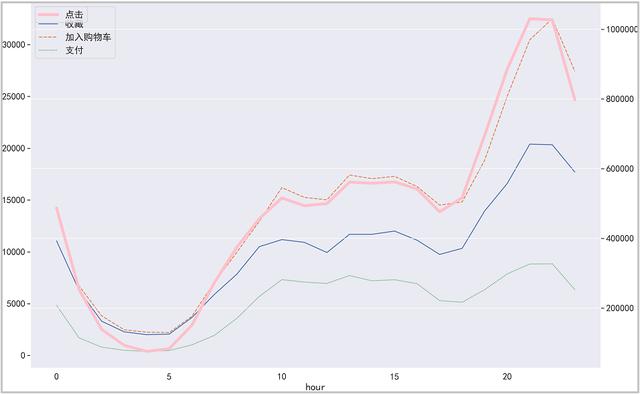
结果分析:从图中可以看出,晚上22:00-凌晨5:00,页面的访问用户数量和访问量逐渐降低,该时间段很多人都是处在休息之中。而从早上6:00-10:00用户数量逐渐呈现上升趋势,10:00-18:00有一个比较平稳的状态,这个时间段是正常的上班时间。但是18:00以后,一直到晚上22:00,用户剧烈激增,一直达到一天中访问用户数的最大值。运营人员可以参考用户的活跃时间段,采取一些促销活动。
2)用户行为指标
① 总计点击、收藏、添加购物车、支付用户的情况
type_1 = df[df['behavior_type']=="1"]["user_id"].count()
type_2 = df[df['behavior_type']=="2"]["user_id"].count()
type_3 = df[df['behavior_type']=="3"]["user_id"].count()
type_4 = df[df['behavior_type']=="4"]["user_id"].count()
print("点击用户:",type_1)
print("收藏用户:",type_2)
print("添加购物车用户:",type_3)
print("支付用户:",type_4)
结果如下:
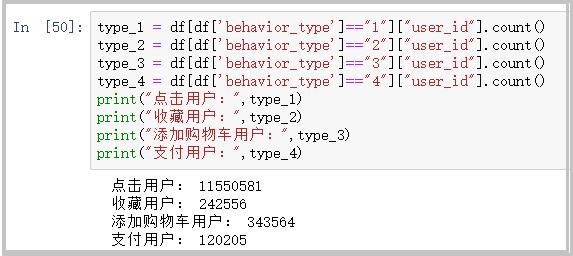
结果分析:从图中可以看到,用户进行页面点击–>收藏和加如购物车–>支付,逐渐呈现下降趋势。关于这方面的分析,将在下面的漏斗图中继续更为深入的说明。
② 日期维度下,点击、收藏、添加购物车、支付用户的情况
pv_date_type = pd.pivot_table(df,index='date',
columns='behavior_type',
values='user_id',
aggfunc=np.size)
pv_date_type.columns = ["点击","收藏","加入购物车","支付"]
pv_date_type.head()
# 绘图如下
plt.figure(figsize=(16,10))
sns.lineplot(data=pv_date_type[['收藏', '加入购物车', '支付']])
plt.tight_layout()
plt.savefig("不同日期不同用户行为的PV变化趋势",dpi=300)
plt.show()
结果如下:

绘图如下:
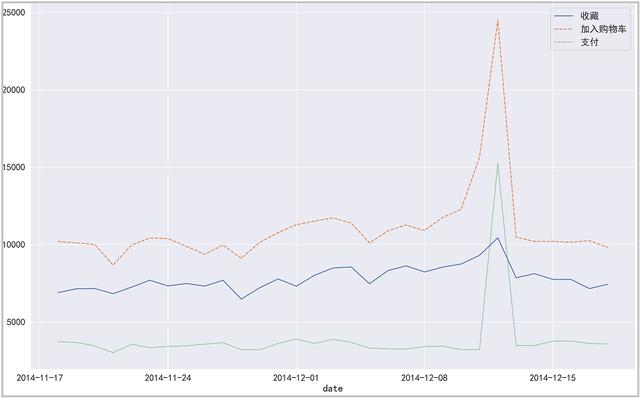
③ 时间维度下,点击、收藏、添加购物车、支付用户的情况
pv_hour_type = pd.pivot_table(df,index='hour',
columns='behavior_type',
values='user_id',
aggfunc=np.size)
pv_hour_type.columns = ["点击","收藏","加入购物车","支付"]
pv_hour_type.head()
# 绘图如下
plt.figure(figsize=(16,10))
sns.lineplot(data=pv_hour_type[['收藏', '加入购物车', '支付']])
pv_hour_type["点击"].plot(c="pink",linewidth=5,label="点击",secondary_y=True)
plt.legend(loc="best")
plt.tight_layout()
plt.savefig("不同小时不同用户行为的PV变化趋势",dpi=300)
plt.show()
结果如下:
绘图如下:
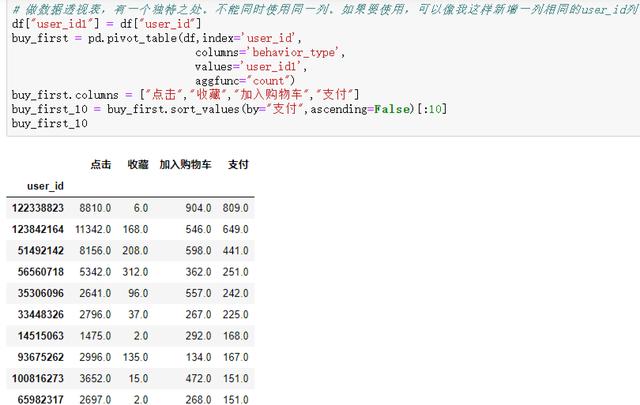
④ 支付次数前10的用户行为细分
df["user_id1"] = df["user_id"]
buy_first = pd.pivot_table(df,index='user_id',
columns='behavior_type',
values='user_id1',
aggfunc="count")
buy_first.columns = ["点击","收藏","加入购物车","支付"]
buy_first_10 = buy_first.sort_values(by="支付",ascending=False)[:10]
buy_first_10
# 绘制图形如下
plt.figure(figsize=(16,10))
plt.subplot(311)
plt.plot(buy_first_10["点击"],c="r")
plt.title("点击数的变化趋势")
plt.subplot(312)
plt.plot(buy_first_10["收藏"],c="g")
plt.title("收藏数的变化趋势")
plt.subplot(313)
plt.plot(buy_first_10["加入购物车"],c="b")
plt.title("加入购物车的变化趋势")
plt.xticks(np.arange(10),buy_first_10.index)
plt.tight_layout()
plt.savefig("支付数前10的用户,在点击、收藏、加入购物车的变化趋势",dpi=300)
plt.show()
结果如下:
绘图如下:
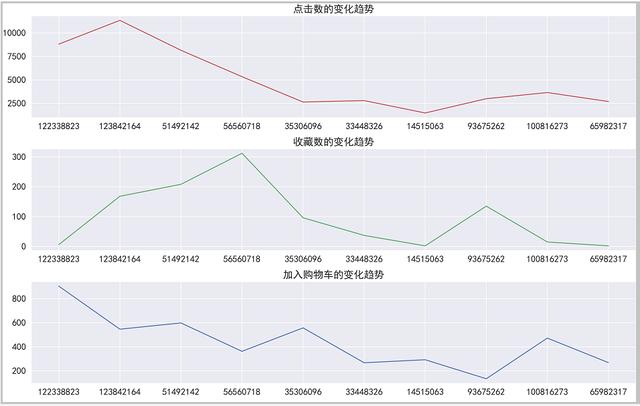
结果分析:通过这个分析,我们可以看出,购买次数最多的用户,点击、收藏、加入购车的次数不一定是最多的,
⑤ ARPPU分析:平均每用户收入,即可通过“总收入/AU” 计算得出
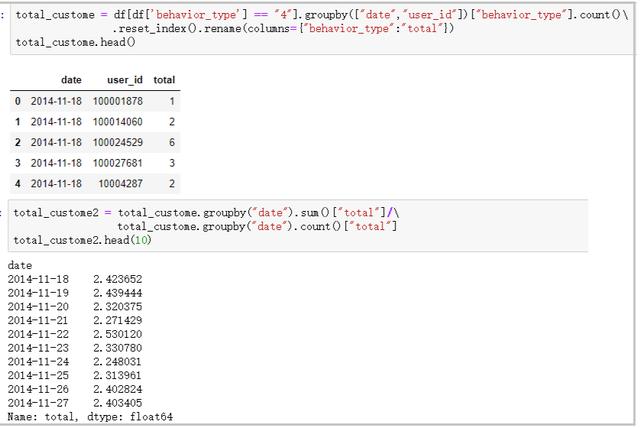
total_custome = df[df['behavior_type'] == "4"].groupby(["date","user_id"])["behavior_type"].count()\
.reset_index().rename(columns={"behavior_type":"total"})
total_custome.head()
total_custome2 = total_custome.groupby("date").sum()["total"]/\
total_custome.groupby("date").count()["total"]
total_custome2.head(10)
# 绘图如下
x = len(total_custome2.index.astype(str))
y = total_custome2.index.astype(str)
plt.plot(total_custome2.values)
plt.xticks(range(0,30,7),[y[i] for i in range(0,x,7)],rotation=90)
plt.title("每天的人均消费次数")
plt.tight_layout()
plt.savefig("每天的人均消费次数",dpi=300)
plt.show()
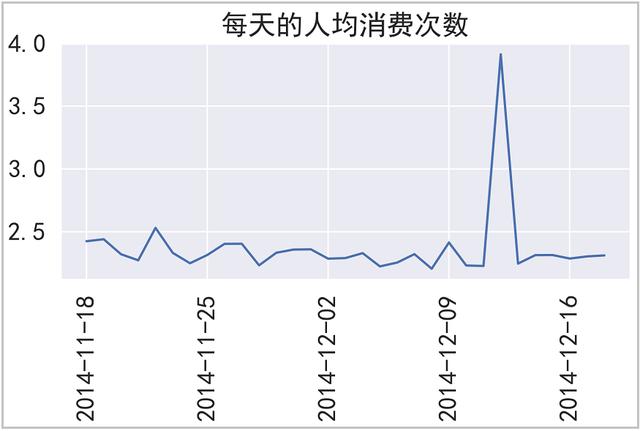
结果如下:
绘图如下:
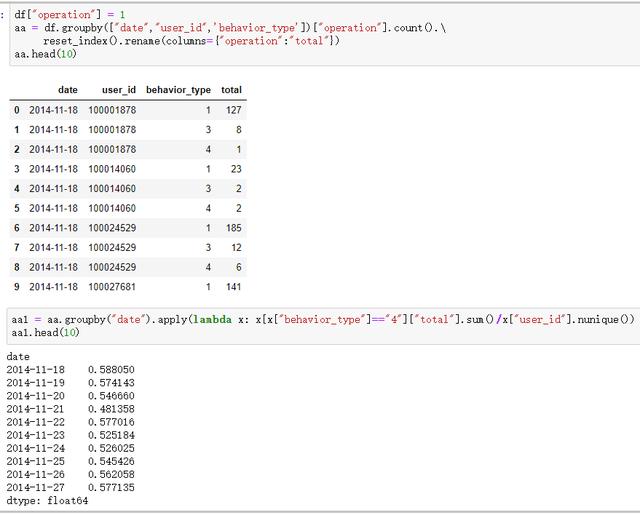
⑥ 日ARPU分析:表示的是平均每用户收入。ARPU = 总收入/AU得到
df["operation"] = 1
aa = df.groupby(["date","user_id",'behavior_type'])["operation"].count().\
reset_index().rename(columns={"operation":"total"})
aa.head(10)
aa1 = aa.groupby("date").apply(lambda x: x[x["behavior_type"]=="4"]["total"].sum()/x["user_id"].nunique())
aa1.head(10)
# 绘图如下
x = len(aa1.index.astype(str))
y = aa1.index.astype(str)
plt.plot(aa1.values)
plt.xticks(range(0,30,7),[y[i] for i in range(0,x,7)],rotation=90)
plt.title("每天的活跃用户消费次数")
plt.tight_layout()
plt.savefig("每天的活跃用户消费次数",dpi=300)
plt.show()
结果如下:
绘图如下:
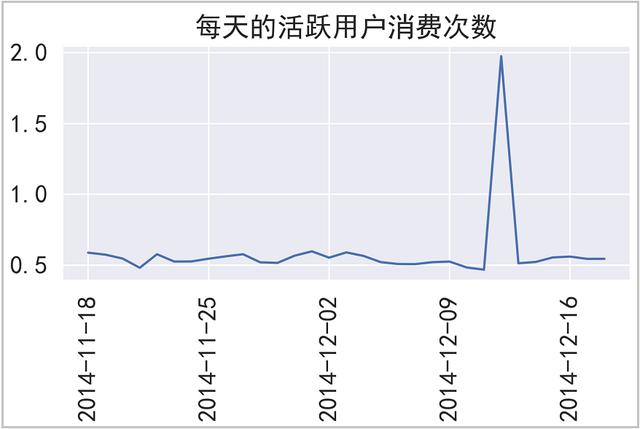
⑦ 付费率PUR = APA/AU,这里用【消费人数 / 活跃用户人数】代替
rate = aa.groupby("date").apply(lambda x: x[x["behavior_type"]=="4"]["total"].count()/x["user_id"].nunique())
rate.head(10)
# 绘图如下
x = len(rate.index.astype(str))
y = rate.index.astype(str)
plt.plot(rate.values)
plt.xticks(range(0,30,7),[y[i] for i in range(0,x,7)],rotation=90)
plt.title("付费率分析")
plt.tight_layout()
plt.savefig("付费率分析",dpi=300)
plt.show()
结果如下:
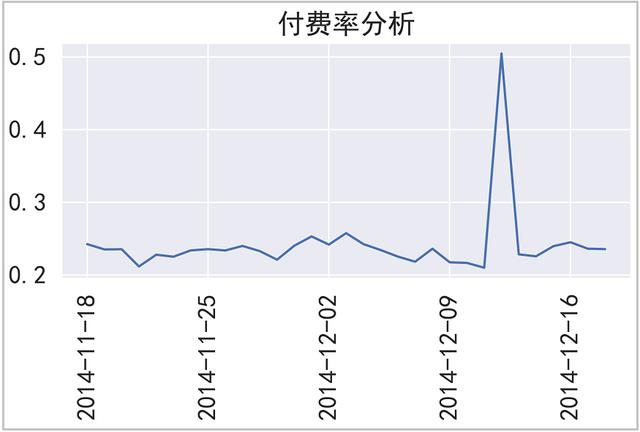
⑧ 复购情况分析(复购率)
re_buy = df[df["behavior_type"]=="4"].groupby("user_id")["date"].apply(lambda x: x.nunique())
print(len(re_buy))
re_buy[re_buy >= 2].count() / re_buy.count()
结果如下:

3)漏斗分析
df_count = df.groupby("behavior_type").size().reset_index().\
rename(columns={"behavior_type":"环节",0:"人数"})
type_dict = {
"1":"点击",
"2":"收藏",
"3":"加入购物车",
"4":"支付"
}
df_count["环节"] = df_count["环节"].map(type_dict)
a = df_count.iloc[0]["人数"]
b = df_count.iloc[1]["人数"]
c = df_count.iloc[2]["人数"]
d = df_count.iloc[3]["人数"]
funnel = pd.DataFrame({"环节":["点击","收藏及加入购物车","支付"],"人数":[a,b+c,d]})
funnel["总体转化率"] = [i/funnel["人数"][0] for i in funnel["人数"]]
funnel["单一转化率"] = np.array([1.0,2.0,3.0])
for i in range(0,len(funnel["人数"])):
if i == 0:
funnel["单一转化率"][i] = 1.0
else:
funnel["单一转化率"][i] = funnel["人数"][i] / funnel["人数"][i-1]
# 绘图如下
import plotly.express as px
import plotly.graph_objs as go
trace = go.Funnel(
y = ["点击", "收藏及加入购物车", "购买"],
x = [funnel["人数"][0], funnel["人数"][1], funnel["人数"][2]],
textinfo = "value+percent initial",
marker=dict(color=["deepskyblue", "lightsalmon", "tan"]),
connector = {"line": {"color": "royalblue", "dash": "solid", "width": 3}})
data =[trace]
fig = go.Figure(data)
fig.show()
结果如下:
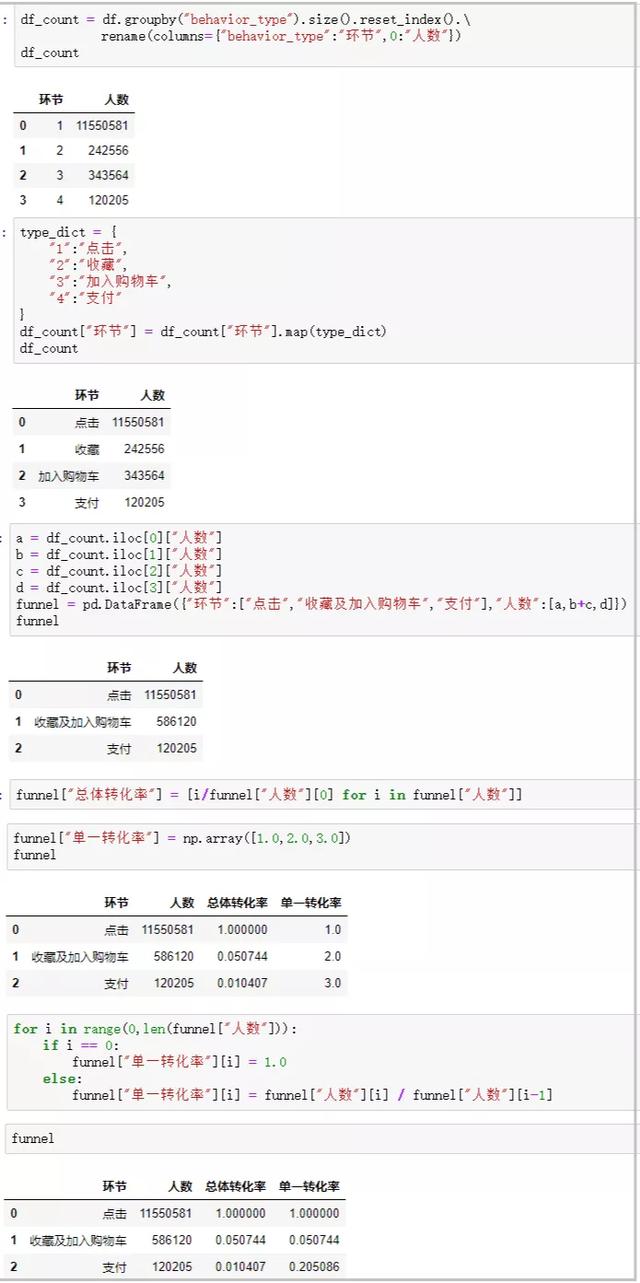
绘图如下:
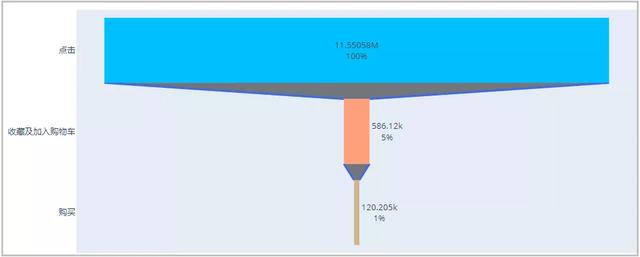
结果分析:由于收藏和加入购车都是有购买意向的一种用户行为,切不分先后顺序,因此我们将其合并看作一个阶段。从上面的漏斗图和funnel表可以看出,从浏览到具有购买意向(收藏和加入购物车),只有5%的转化率,但是到了真正到购买的转化率只有1%,再看“单一转化率”,从具有购买意向到真正购买的转化率达到了20%。说明从浏览到进行收藏和加入购物车的阶段,是指标提升的重要环节。
4)客户价值分析(RFM分析)
from datetime import datetime
# 最近一次购买距离现在的天数
recent_buy = df[df["behavior_type"]=="4"].groupby("user_id")["date"].\
apply(lambda x:datetime(2014,12,20) - x.sort_values().iloc[-1]).reset_index().\
rename(columns={"date":"recent"})
recent_buy["recent"] = recent_buy["recent"].apply(lambda x: x.days)
recent_buy[:10]
# 购买次数计算
buy_freq = df[df["behavior_type"]=="4"].groupby("user_id")["date"].count().reset_index().\
rename(columns={"date":"freq"})
buy_freq[:10]
# 将上述两列数据,合并起来
rfm = pd.merge(recent_buy,buy_freq,on="user_id")
rfm[:10]
# 给不同类型打分
r_bins = [0,5,10,15,20,50]
f_bins = [1,30,60,90,120,900]
rfm["r_score"] = pd.cut(rfm["recent"],bins=r_bins,labels=[5,4,3,2,1],right=False)
rfm["f_score"] = pd.cut(rfm["freq"],bins=f_bins,labels=[1,2,3,4,5],right=False)
for i in ["r_score","f_score"]:
rfm[i] = rfm[i].astype(float)
rfm.describe()
# 比较各分值与各自均值的大小
rfm["r"] = np.where(rfm["r_score"]>3.943957,"高","低")
rfm["f"] = np.where(rfm["f_score"]>1.133356,"高","低")
# 将r和f列的字符串合并起来
rfm["value"] = rfm["r"].str[:] + rfm["f"].str[:]
rfm.head()
# 自定义函数给用户贴标签
def trans_labels(x):
if x == "高高":
return "重要价值客户"
elif x == "低高":
return "重要唤回客户"
elif x == "高低":
return "重要深耕客户"
else:
return "重要挽回客户"
rfm["标签"] = rfm["value"].apply(trans_labels)
# 计算出每个标签的用户数量
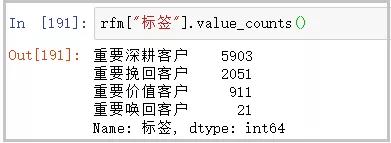
rfm["标签"].value_counts()
结果如下:
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





