怎么利用Neo4j联邦实现LDBC社交网络分割,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
Neo4j 4.0发布了一个令人兴奋新功能:Neo4j联邦。Neo4j联邦的操作原理从本质上讲非常简单,它提供了一种方式来执行针对多个Neo4j数据库的Cypher查询。
可以通过多种方式来使用此功能,包括跨多个独立数据库的联合查询与分析,数据存储和处理可以水平扩展,也可以进行不同的混合部署。
接下来,我们将探讨如何使用联邦功能来实现著名且具有挑战性的LDBC社交网络基准图的水平缩放(即分片)。
对图数据进行分片是一个众所周知的难题。我们将展示如何使用Neo4j联邦实现分片,Neo4j 联邦将分片存储为独立和不相交的图,这意味着关系不会跨越分片。而是使用我们称为代理节点并关联ID值的方法对此类关系进行建模。我们将依赖有关数据模型和将要运行的查询以及要针对哪些查询进行优化的知识,以针对特定用例创建分片数据模型。
最后,我们将通过比较分片版本和非分片版本之间的查询时间和吞吐量,展示联邦功能如何提高查询性能。
LDBC社交网络基准提供了数据模型规范以及数据生成器,以及一组查询规范。需要注意的是,我们并没有使用基准所指定的基准工作负载,而是借用其数据模型和查询来进行另一种演示。该测试旨在证明分片和非分片配置之间的差异,并探讨图形分片的注意事项,而不是提供行业基准。
在规范中可以找到LDBC SNB数据模型的完整描述。我们将在此处提供简化的概述,并以导入到Neo4j中时架构的外观表示。
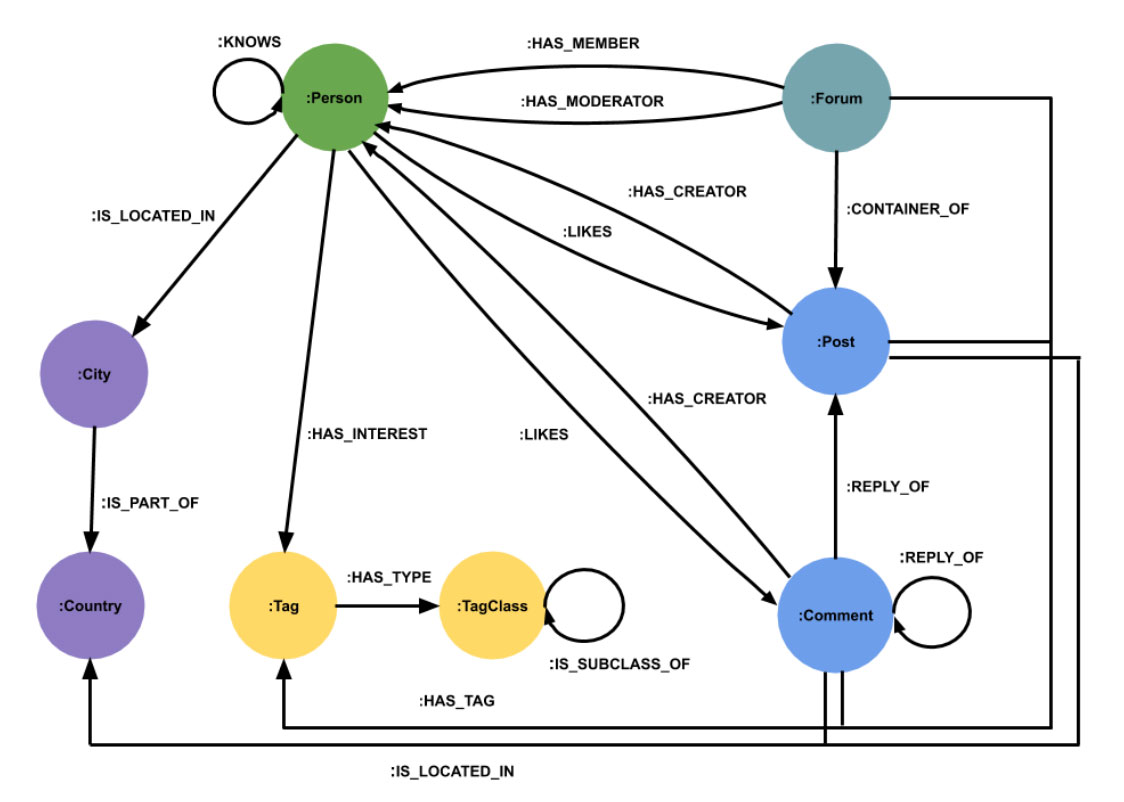
该模型包含一个由不同的人和他们的友谊关系组成的图组件,并构成了社交网络的核心。就数据大小而言,该图组件的最大部分是留言板组件,该组件为包含帖子和评论回复链的论坛建模。人们可以通过多种不同方式与论坛,帖子和评论相关联。
论坛,帖子和评论都有标签,每个人都可以有一组代表其兴趣的标签。标签是按类别进行分类的。不同的人位于不同国家(或地区)的城市中,每个帖子或评论也在一个国家中创建
完整模型包含更多实体,例如大学,公司和大洲,我们暂时不在此描述。
分片数据模型始终是一个复杂的问题,没有通用的解决方案。确定要“剪切”的关系不仅取决于模型本身,还取决于数据分布和预期的查询执行模式。
根据国家或地区进行分片似乎是自然的选择。这种分片方案是基于这样的假设,即用户更可能会认识来自同一国家的人并与之互动。详细讨论为什么这种分片方案在这种情况下是否是最佳的讨论超出了本文的讨论范围。简化的解释是,典型的查询将不得不在各个分片之间进行过多的“跳转”。
在考虑了多种选择之后,我们决定采用以下分片方案。
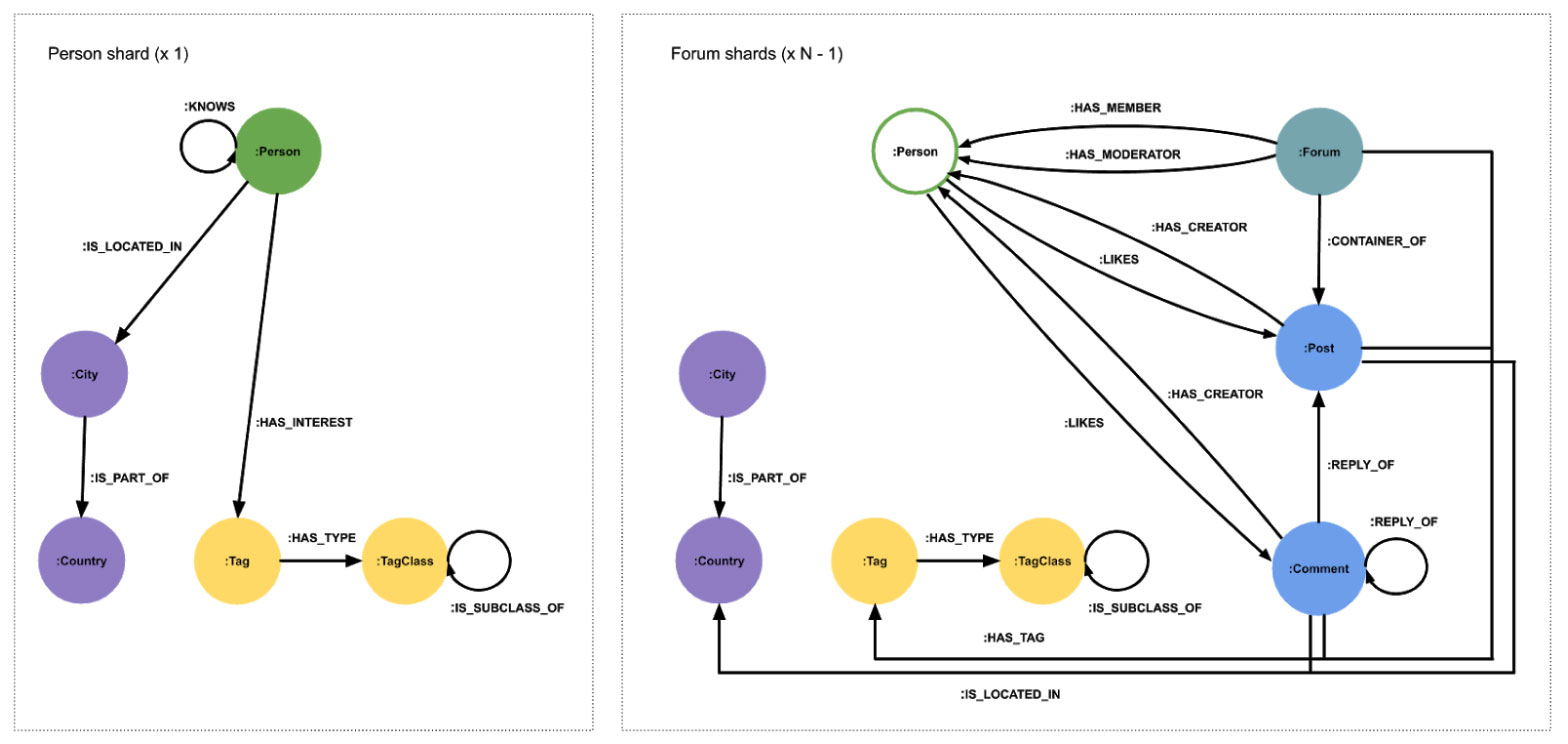
选择的分片方案是异构的,这意味着并非所有分片都包含相同种类的数据。所有个人和与他们相关的数据都保存在一个分片 中。论坛,其帖子和评论分布在其余分片上。地理数据和标签结构被复制到每个分片上。论坛分片包含简化的人员代理节点表示形式,仅保留其原始id属性
这种分片方案有两个优点。首先,它允许有效的查询人与人之间的关系,这在许多查询中至关重要。其次,由于论坛本质上是一片森林,因此它们可以分布在其余分片上,而没有最重要的关系跨越分片边界。
将所有人放在一个片上不是问题,因为消息和评论要比个人信息多几个数量级。从理论上讲,如果社交网络发展得飞快,以至于“人物”图无法有效地安装在一台机器上,那么它可能会被进一步分割。
同样,在所有分片上复制标签,城市和国家也不成问题,因为这类数据非常小且静态。
我们设计了许多测试方案,来评估上述分片模型的性能,尤其是针对非分片模型进行了比较,以及随着分片数量的增加如何更改性能。此处重点关注的方案是查看在将数据集分配给越来越多的越来越小的分片时,读取性能如何扩展。
我们要强调的是,我们只是借鉴了LDBC社交网络基准测试的数据模型,数据生成器和查询,但是测试执行的目标和方法不同。
LDBC SNB指定许多查询,分为若干类别。我们从“交互式复杂读取”类别中选择了四个查询(查询4,查询6,查询7和查询9),它们代表了该工作负载,我们将在其上展示我们的结果。这些查询的定义可以在LDBC SNB规范中找到。
这些查询的联邦Cypher实现可在此处找到。
接下来,我们将分享更多查询以及其他有趣测试场景的结果。
我们的测试数据集是使用LDBC SNB数据生成器以比例因子(SF)1000生成的。它包含大约27亿个节点。数据生成器创建的csv文件的大小约为1TB。
我们将生成的数据以四种不同的配置导入到Neo4j中
1个分片(无代理,整体参考)
10个分片(1个人员分片,9个论坛分片)
20个分片(1个人员分片,19个论坛分片)
40个分片(1个人员分片,39个论坛分片)
这些分片分别部署在各自独立的AWS EC2实例上,并且在这些实例上运行Neo4j 4.0。配置内存限制以使所有分片上的总可用量保持恒定,为1800GB。除了内存限制,Neo4j实例具有默认设置。
#分片 | 分片实例类型 | 内存(GB) | |||
总量 | 每个分片 | 页面缓存 | 堆 | ||
1个 | x1.32xlarge(128C,1,952GB) | 1,800 | 1,800 | 1,600 | 200 |
10 | m5d.12xlarge(48C,192GB) | 1,800 | 180 | 160 | 20 |
20 | m5d.8xlarge(32C,128GB) | 1,800 | 90 | 80 | 10 |
40 | m5d.4xlarge(16C,64GB) | 1,800 | 45 | 40 | 5 |
查询延迟是通过一次又一次执行单个查询来衡量的,同时记录从提交到每个查询结果执行完毕所消耗的时间。查询参数按照它们在LDBC参数文件中出现的顺序提供给每个查询执行。初始的查询执行结果集被认为是“热数据”,并且从统计信息中排除。联邦代理部署在t3.2xlarge类型(8C,32GB)的单个单独实例上
最大查询吞吐量是通过随着时间的推移增加并发发出的查询的数量来统计的,直至错误率或延迟开始超出定义的参数为止。联邦代理部署在c5.24xlarge类型(96C,192GB)的单个单独实例上
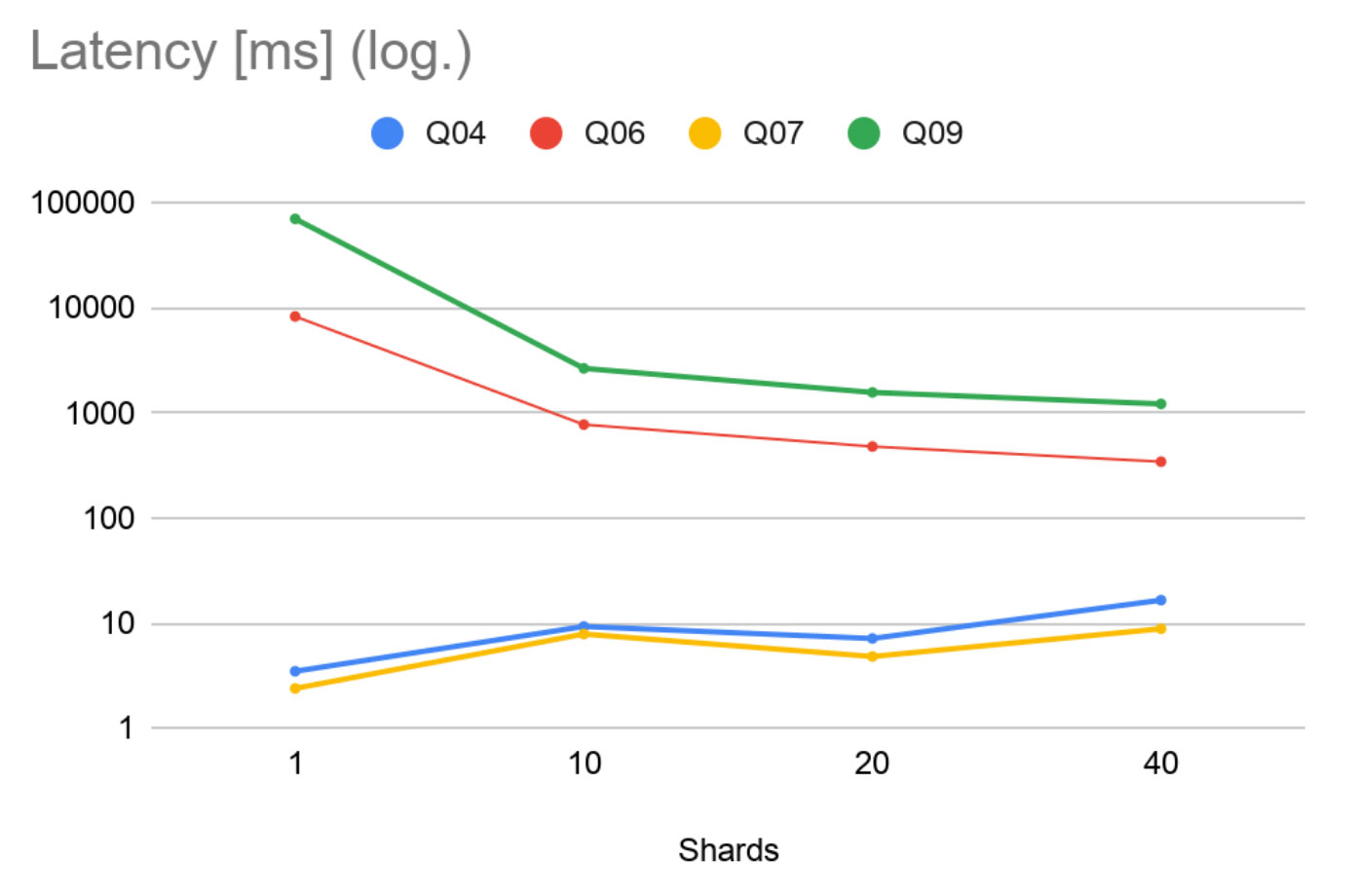
这些结果表明Q06和Q09比Q04和Q07重得多。我们可以看到,随着分片数量的增加,繁重的查询延迟大大减少(请注意,该图具有对数刻度)。对于较轻的工作负载,由于通信开销越来越占主导地位,因此延迟会按预期增加。尽管如此,我们仍设法将Q04和Q07的毫秒延迟保持在较低水平。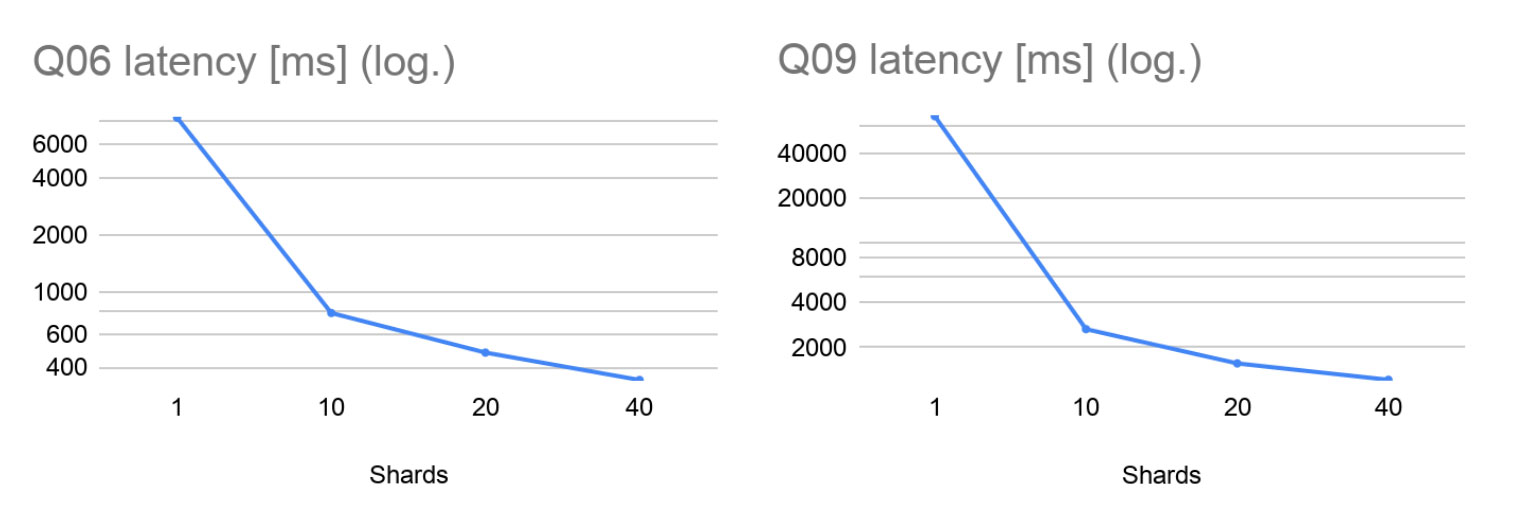
仔细研究繁重的查询,我们发现Q06在10个分片上的速度提高了约11倍,在20个分片上的速度提高了约17倍。这些极好的结果表明,如果分片数量合理,联邦可以针对此类工作负载实现几乎线性的加速。在相同的速度下,任何工作负载都无法无限并行化,而在40个分片上,我们的速度提高了约24倍。这些结果非常令人鼓舞,表明与联邦并行执行对延迟的影响远大于通信和协调开销。
延迟测量一次只能运行一个查询。下图显示了并发吞吐能力,即每秒测得的最大执行查询数。
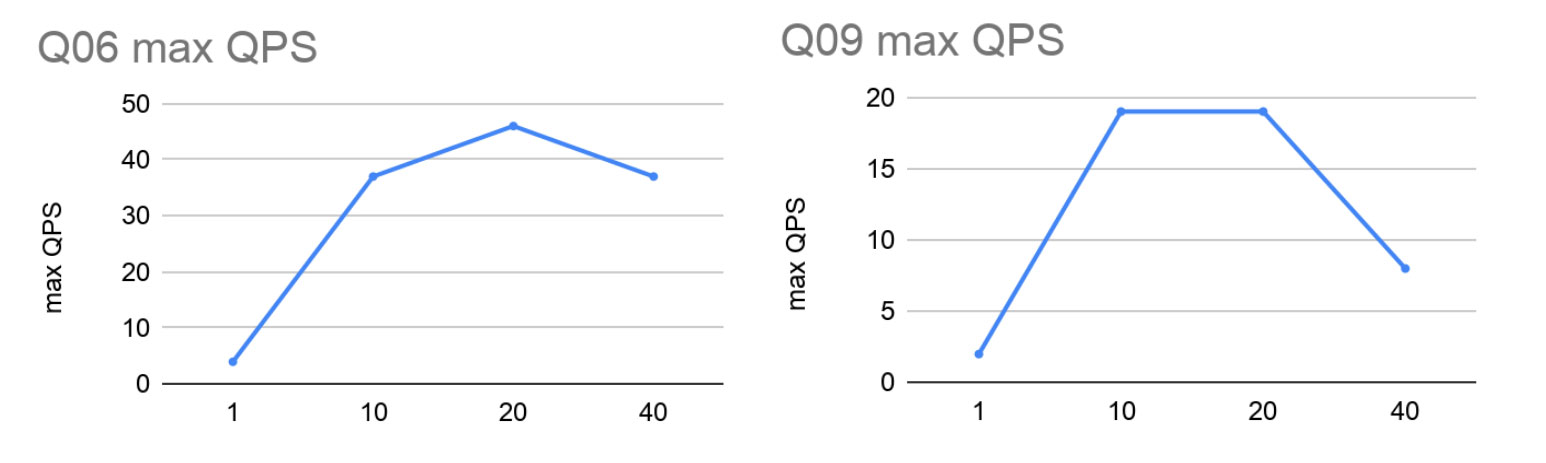
同样,我们看到了从单个实例到10个分片的惊人性能提升。有趣的是,当我们从单个实例到10个分片时,最大吞吐量的增加比添加的处理器核心数量增加的更多。这可以用以下事实解释:使用10台计算机不仅增加了更多的处理器核心,而且还增加了其他资源,例如总内存带宽。
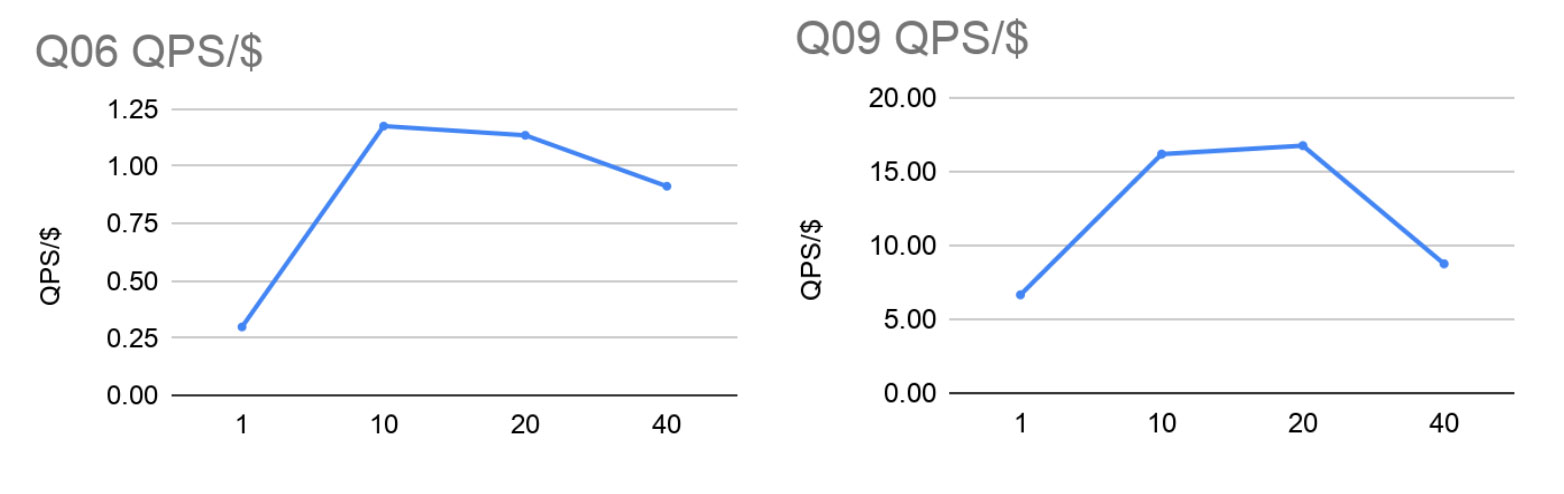
由于我们没有办法限制分片机上可用内核的数量以平衡计算能力总量,因此以下图显示了将最大QPS标准化为AWS EC2上整个设置的每小时总成本。
关于怎么利用Neo4j联邦实现LDBC社交网络分割问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/69975677/viewspace-2696755/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



