жҖҺд№Ҳзј–еҶҷPythonи„ҡжң¬
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңжҖҺд№Ҳзј–еҶҷPythonи„ҡжң¬вҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
StreamlitжҳҜ第дёҖдёӘдё“й—Ёй’ҲеҜ№жңәеҷЁеӯҰд№ е’Ңж•°жҚ®з§‘еӯҰеӣўйҳҹзҡ„еә”з”ЁејҖеҸ‘жЎҶжһ¶пјҢе®ғжҳҜејҖеҸ‘иҮӘе®ҡд№үжңәеҷЁеӯҰд№ е·Ҙе…·зҡ„жңҖеҝ«зҡ„ж–№жі•пјҢдҪ еҸҜд»Ҙи®Өдёәе®ғзҡ„зӣ®ж ҮжҳҜеҸ–д»ЈFlaskеңЁжңәеҷЁеӯҰд№ йЎ№зӣ®дёӯзҡ„ең°дҪҚпјҢеҸҜд»Ҙеё®еҠ©жңәеҷЁеӯҰд№ е·ҘзЁӢеёҲеҝ«йҖҹејҖеҸ‘з”ЁжҲ·дәӨдә’е·Ҙе…·гҖӮ
1гҖҒHello world
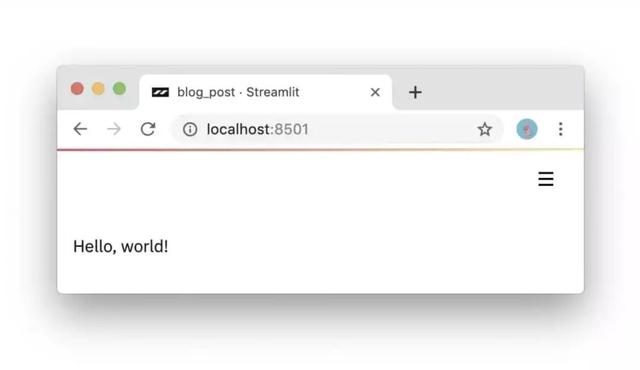
Streamlitеә”з”Ёе°ұжҳҜPythonи„ҡжң¬пјҢжІЎжңүйҡҗеҗ«зҡ„зҠ¶жҖҒпјҢдҪ еҸҜд»ҘдҪҝз”ЁеҮҪж•°и°ғз”ЁйҮҚжһ„гҖӮеҸӘиҰҒдҪ дјҡеҶҷPythonи„ҡжң¬пјҢдҪ е°ұдјҡејҖеҸ‘Streamlitеә”з”ЁгҖӮдҫӢеҰӮпјҢдёӢйқўзҡ„д»Јз ҒеңЁзҪ‘йЎөдёӯиҫ“еҮә Hello,world!пјҡ
import streamlit as st
st.write('Hello, world!')з»“жһңеҰӮдёӢпјҡ
2гҖҒдҪҝз”ЁUI组件
Streamlitе°Ҷ组件и§ҶдёәеҸҳйҮҸпјҢеңЁStreamlitдёӯжІЎжңүеӣһи°ғпјҢжҜҸдёҖдёӘдәӨдә’йғҪжҳҜ з®ҖеҚ•ең°иҝ”еӣһпјҢд»ҺиҖҢзЎ®дҝқд»Јз Ғе№ІеҮҖпјҡ
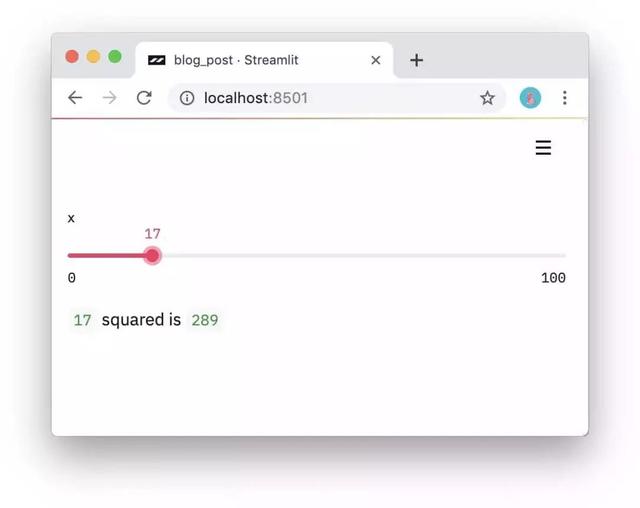
import streamlit as st
x = st.slider('x')
st.write(x, 'squared is', x * x)з»“жһңеҰӮдёӢпјҡ
3гҖҒж•°жҚ®йҮҚз”Ёе’Ңи®Ўз®—
еҰӮжһңдҪ иҰҒдёӢиҪҪеӨ§йҮҸж•°жҚ®жҲ–иҖ…иҝҗиЎҢеӨҚжқӮзҡ„и®Ўз®—иҜҘжҖҺд№Ҳе®һзҺ°пјҹе…ій”®еңЁдәҺе®үе…Ёең°йҮҚз”Ёж•°жҚ®гҖӮStreamlitеј•е…ҘдәҶзј“еӯҳеҺҹиҜӯеҸҜд»Ҙи®©Steamlitеә”з”Ё е®үе…ЁгҖҒиҪ»жқҫзҡ„йҮҚз”ЁдҝЎжҒҜгҖӮдҫӢеҰӮпјҢдёӢйқўзҡ„д»Јз ҒеҸӘйңҖиҰҒд»ҺUdacityзҡ„иҮӘеҠЁ й©ҫ驶иҪҰйЎ№зӣ®дёӢиҪҪдёҖж¬Ўж•°жҚ®пјҢд»ҺиҖҢеҫ—еҲ°дёҖдёӘз®ҖеҚ•гҖҒеҝ«йҖҹзҡ„еә”з”Ёпјҡ
import streamlit as st
import pandas as pd
# Reuse this data across runs!
read_and_cache_csv = st.cache(pd.read_csv)
BUCKET = "https://streamlit-self-driving.s3-us-west-2.amazonaws.com/"
data = read_and_cache_csv(BUCKET + "labels.csv.gz", nrows=1000)
desired_label = st.selectbox('Filter to:', ['car', 'truck'])
st.write(data[data.label == desired_label])з»“жһңеҰӮдёӢпјҡ

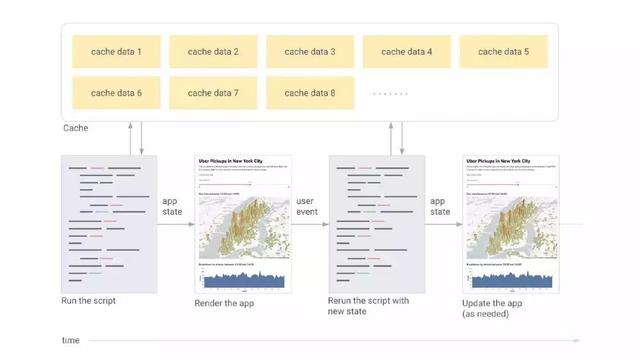
з®ҖиҖҢиЁҖд№ӢпјҢStreamlitзҡ„е·ҘдҪңж–№ејҸеҰӮдёӢпјҡ
еҜ№дәҺз”ЁжҲ·зҡ„жҜҸдёҖж¬ЎдәӨдә’пјҢж•ҙдёӘи„ҡжң¬д»ҺеӨҙеҲ°е°ҫжү§иЎҢдёҖйҒҚ
StreamlitеҹәдәҺUI组件зҡ„зҠ¶жҖҒз»ҷеҸҳйҮҸиөӢеҖј
зј“еӯҳи®©StreamlitеҸҜд»ҘйҒҝе…ҚйҮҚеӨҚиҜ·жұӮж•°жҚ®жҲ–йҮҚеӨҚи®Ўз®—
жҲ–иҖ…еҸӮиҖғдёӢеӣҫпјҡ
еҰӮжһңдёҠйқўзҡ„еҶ…е®№иҝҳжІЎжңүиҜҙжё…жҘҡпјҢдҪ еҸҜд»ҘзӣҙжҺҘдёҠжүӢе°қиҜ•StreamlitпјҒ
$ pip install --upgrade streamlit
$ streamlit hello
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://10.0.1.29:8501
иҝҷдјҡиҮӘеҠЁжү“ејҖжң¬ең°зҡ„webжөҸи§ҲеҷЁе№¶и®ҝй—®Streamlitеә”з”Ёпјҡ
4гҖҒе®һдҫӢпјҡиҮӘеҠЁй©ҫ驶数жҚ®йӣҶе·Ҙе…·
дёӢйқўзҡ„Streamlitеә”з”Ёи®©дҪ еҸҜд»ҘеңЁж•ҙдёӘUdacityиҮӘеҠЁй©ҫ驶иҪҰиҫҶз…§зүҮж•°жҚ®йӣҶдёӯиҝӣиЎҢиҜӯд№үеҢ–жҗңзҙўпјҢеҸҜи§ҶеҢ–дәәе·Ҙж ҮжіЁпјҢ并且еҸҜд»Ҙе®һж—¶иҝҗиЎҢдёҖдёӘYOLO зӣ®ж ҮжЈҖжөӢеҷЁпјҡ
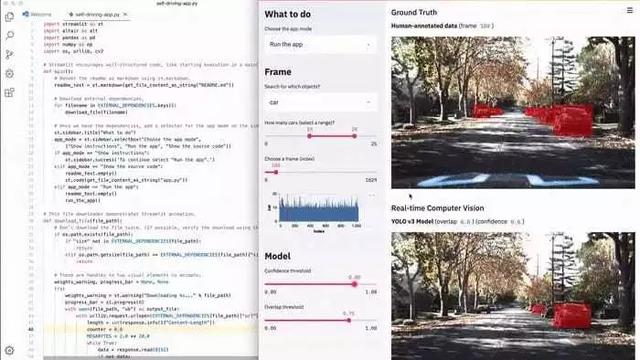
гҖҒж•ҙдёӘеә”з”ЁеҸӘжңү300иЎҢPythonд»Јз ҒпјҢз»қеӨ§еӨҡж•°жҳҜжңәеҷЁеӯҰд№ д»Јз ҒгҖӮе®һйҷ…дёҠ е…¶дёӯеҸӘжңү23дёӘStreamlitи°ғз”ЁгҖӮдҪ еҸҜд»Ҙе°қиҜ•иҮӘе·ұиҝҗиЎҢпјҡ
$ pip install --upgrade streamlit opencv-python
$ streamlit run https://raw.githubusercontent.com/streamlit/demo-self-driving/master/app.py
вҖңжҖҺд№Ҳзј–еҶҷPythonи„ҡжң¬вҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ





