本篇内容主要讲解“web算法中朴素贝叶斯如何实现文档分类”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“web算法中朴素贝叶斯如何实现文档分类”吧!
作业要求:
实验数据在bayes_datasets文件夹中。其中,
train为训练数据集,包含hotel和travel两个中文文本集,文本为txt格式。hotel文本集中全部都是介绍酒店信息的文档,travel文本集中全部都是介绍景点信息的文档;
Bayes_datasets/test为测试数据集,包含若干hotel类文档和travel类文档。
用朴素贝叶斯算法对上述两类文档进行分类。要求输出测试数据集的文档分类结果,即每类文档的数量。
(例:hotel:XX,travel:XX)
贝叶斯公式:
朴素贝叶斯算法的核心,贝叶斯公式如下:
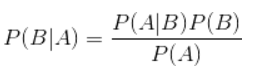
代码实现:
第一部分:读取数据
f_path = os.path.abspath('.')+'/bayes_datasets/train/hotel'
f1_path = os.path.abspath('.')+'/bayes_datasets/train/travel'
f2_path = os.path.abspath('.')+'/bayes_datasets/test'
ls = os.listdir(f_path)
ls1 = os.listdir(f1_path)
ls2 = os.listdir(f2_path)
#去掉网址的正则表达式
pattern = r"(http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*,]|(?:%[0-9a-fA-F][0-9a-fA-F]))+)|([a-zA-Z]+.\w+\.+[a-zA-Z0-9\/_]+)"
res = []
for i in ls:
with open(str(f_path+'\\'+i),encoding='UTF-8') as f:
lines = f.readlines()
tmp = ''.join(str(i.replace('\n','')) for i in lines)
tmp = re.sub(pattern,'',tmp)
remove_digits = str.maketrans('', '', digits)
tmp = tmp.translate(remove_digits)
# print(tmp)
res.append(tmp)
print("hotel总计:",len(res))
for i in ls1:
with open(str(f1_path + '\\' + i), encoding='UTF-8') as f:
lines = f.readlines()
tmp = ''.join(str(i.replace('\n', '')) for i in lines)
tmp = re.sub(pattern, '', tmp)
remove_digits = str.maketrans('', '', digits)
tmp = tmp.translate(remove_digits)
# print(tmp)
res.append(tmp)
print("travel总计:",len(res)-308)
#print(ls2)
for i in ls2:
with open(str(f2_path + '\\' + i), encoding='UTF-8') as f:
lines = f.readlines()
tmp = ''.join(str(i.replace('\n', '')) for i in lines)
tmp = re.sub(pattern, '', tmp)
remove_digits = str.maketrans('', '', digits)
tmp = tmp.translate(remove_digits)
# print(tmp)
res.append(tmp)
print("test总计:",len(res)-616)
print("数据总计:",len(res))
这一部分的任务是将放在各个文件夹下的txt文档读入程序,并将数据按照需要的形式存放。数据分为训练集和测试集,而训练集又包括景点和酒店两类,故数据总共分为三类,分三次分别读取。在训练集的每一个txt文件中最前端都有一串网址信息,我用正则表达式将其过滤掉,后来发现此部分并不会影响最终的结果。之后将三类文档依次读取,将读取的结果存放入一个结果list中。list的每一项为一个字符串,存放的是一个txt文件的去除掉要过滤的数据之后的全部信息。最终得到travel文件夹下共有308个文档,hotel文件夹下也有308个文档,测试集共有22个文档。
第二部分:分词,去除停用词
stop_word = {}.fromkeys([',','。','!','这','我','非常','是','、',':',';'])
print("中文分词后结果:")
corpus = []
for a in res:
seg_list = jieba.cut(a.strip(),cut_all=False)#精确模式
final = ''
for seg in seg_list:
if seg not in stop_word:#非停用词,保留
final += seg
seg_list = jieba.cut(final,cut_all=False)
output = ' '.join(list(seg_list))
# print(output)
corpus.append(output)
# print('len:',len(corpus))
# print(corpus)#分词结果
这一部分要做的是设置停用词集,即分词过程中过滤掉的无效词汇,将每一个txt文件中的数据进行中文分词。首先stop_word存放了停用词集,使用第三方库jieba进行中文分词,将去除停用词后的结果最后放入corpus中。
第三部分:计算词频
#将文本中的词语转换为词频矩阵
vectorizer = CountVectorizer()
#计算各词语出现的次数
X = vectorizer.fit_transform(corpus)
#获取词袋中所有文本关键词
word = vectorizer.get_feature_names()
#查看词频结果
#print(len(word))
for w in word:
print(w,end=" ")
print(" ")
#print("词频矩阵:")
X = X.toarray()
#print("矩阵len:",len(X))
#np.set_printoptions(threshold=np.inf)
#print(X)无锡人流多少钱 http://www.bhnnk120.com/
这一部分的任务是将文本中的词语转换为词频矩阵,并且计算各词语出现的次数。词频矩阵是将文档集合转换为矩阵,每个文档都是一行,每个单词(标记)是列,相应的(行,列)值是该文档中每个单词或标记的出现频率。
但我们需要注意的是,本次作业的词频矩阵的大小太大,我曾尝试输出整个词频矩阵,直接导致了程序卡顿,我也尝试了输出矩阵的第一项,也有近20000个元素,所以如果不是必需,可以不输出词频矩阵。
第四部分:数据分析
# 使用616个txt文件夹内容进行预测
print ("数据分析:")
x_train = X[:616]
x_test = X[616:]
#print("x_train:",len(x_train))
#print("x_test:",len(x_test))
y_train = []
# 1表示好评0表示差评
for i in range(0,616):
if i < 308:
y_train.append(1)#1表示旅店
else:
y_train.append(0)#0表示景点
#print(y_train)
#print(len(y_train))
y_test= [0,0,0,1,1,1,0,0,1,0,1,0,0,1,0,0,1,1,1,0,1,1]
# 调用MultionmialNB分类器
clf = MultinomialNB().fit(x_train,y_train)
pre = clf.predict(x_test)
print("预测结果:",pre)
print("真实结果:",y_test)
print(classification_report(y_test,pre))
hotel = 0
travel = 0
for i in pre:
if i == 0:
travel += 1
else:
hotel += 1
print("Travel:",travel)
print("Hotel:",hotel)
这部分的任务是将所有的训练数据根据其标签内容进行训练,然后根据训练得到的结果对测试数据进行预测分类。x_train代表所有的训练数据,共有616组;其对应的标签为y_train,也有616组,值为1代表酒店,值为0代表景点。x_test代表所有的测试数据,共有22组;其对应标签为y_test,亦22组,其值则由我自己事先根据其值手工写在程序中。此时需要注意的是测试集文件在程序中的读取顺序可能与文件夹目录中的顺序不一致。最后将测试集数据使用训练集数据调用MultionmialNB分类器得到的模型进行预测,并将预测结果与真实结果进行对比。
得出运行结果。
到此,相信大家对“web算法中朴素贝叶斯如何实现文档分类”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





