жҖҺд№Ҳз”ЁPythonеҲҶжһҗ44дёҮжқЎж•°жҚ®
жң¬зҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іжҖҺд№Ҳз”ЁPythonеҲҶжһҗ44дёҮжқЎж•°жҚ®пјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еӯҰд№ пјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·пјҢиҜқдёҚеӨҡиҜҙпјҢи·ҹзқҖе°Ҹзј–дёҖиө·жқҘзңӢзңӢеҗ§гҖӮ
жңүдёӘж®өеӯҗи®ІвҖңеҚҒе№ҙж–ҮжЎҲиҖҒеҸёжңәпјҢдёҚеҰӮзҪ‘жҳ“иҜ„и®әеҢәпјҢзҪ‘жҳ“ж–ҮиұӘйҒҚең°иө°пјҢиҜ„и®әе…ЁйғЁеҚ•иә«зӢ—вҖқпјҢзҪ‘жҳ“дә‘йҹід№җзҡ„иҜ„и®әеҢәд№ҹдёҖзӣҙйғҪжҳҜеҗ„зұ»ж–ҮжЎҲеӨ§зҘһзҡ„иҒҡйӣҶең°гҖӮ
йӮЈд№ҲжҲ‘们жҷ®йҖҡз”ЁжҲ·еҲ°еә•еҰӮдҪ•жҲҗдёәзҪ‘жҳ“дә‘йҹід№җиҜ„и®әйҮҢзҡ„зғӯиҜ„ж®өеӯҗжүӢпјҹ
и®©жҲ‘жқҘеҲҶжһҗдёҖдёӢгҖӮ
иҺ·еҸ–ж•°жҚ®
е…¶е®һйҖ»иҫ‘并дёҚеӨҚжқӮпјҡ
зҲ¬еҸ–жӯҢеҚ•еҲ—иЎЁйҮҢзҡ„жүҖжңүжӯҢеҚ•urlгҖӮ
иҝӣе…ҘжҜҸзҜҮжӯҢеҚ•зҲ¬еҸ–жүҖжңүжӯҢжӣІurlпјҢеҺ»йҮҚгҖӮ
иҝӣе…ҘжҜҸйҰ–жӯҢжӣІйҰ–йЎөзҲ¬еҸ–зғӯиҜ„пјҢжұҮжҖ»гҖӮ
жӯҢеҚ•еҲ—иЎЁжҳҜиҝҷж ·зҡ„пјҡ
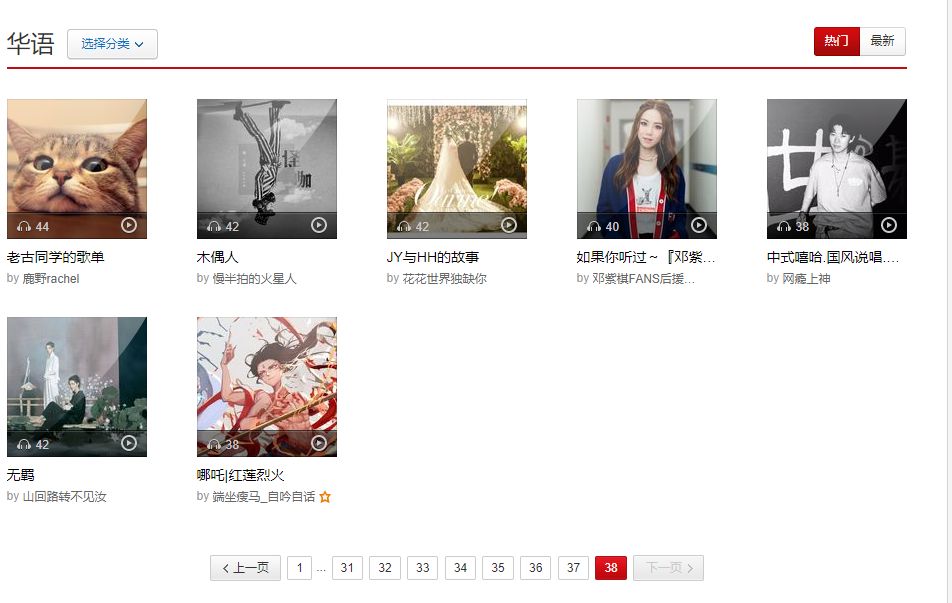
зҝ»йЎө并и§ӮеҜҹе®ғзҡ„urlеҸҳеҢ–пјҢжіЁж„ҸдёӢж–№еҠЁеӣҫпјҢжҜҸж¬Ўзҝ»йЎөжң«е°ҫеҸҳеҢ–35гҖӮ

йҮҮз”Ёrequests+pyqueryжқҘзҲ¬еҸ–гҖӮ
еңЁеӯҰд№ иҝҮзЁӢдёӯжңүд»Җд№ҲдёҚжҮӮеҫ—еҸҜд»ҘеҠ жҲ‘зҡ„
pythonеӯҰд№ дәӨжөҒжүЈжүЈqunпјҢ784758214
зҫӨйҮҢжңүдёҚй”ҷзҡ„еӯҰд№ и§Ҷйў‘ж•ҷзЁӢгҖҒејҖеҸ‘е·Ҙе…·дёҺз”өеӯҗд№ҰзұҚгҖӮ
дёҺдҪ еҲҶдә«pythonдјҒдёҡеҪ“дёӢдәәжүҚйңҖжұӮеҸҠжҖҺд№Ҳд»Һйӣ¶еҹәзЎҖеӯҰд№ еҘҪpythonпјҢе’ҢеӯҰд№ д»Җд№ҲеҶ…е®№
def get_list():
list1 = []
for i in range(0,1295,35):
url = 'https://music.163.com/discover/playlist/?order=hot&cat=%E5%8D%8E%E8%AF%AD&limit=35&offset='+str(i)
print('е·ІжҲҗеҠҹйҮҮйӣҶ%iйЎөжӯҢеҚ•\n' %(i/35+1))
data = []
html = restaurant(url)
doc = pq(html)
for i in range(1,36): # дёҖйЎө35дёӘжӯҢеҚ•
a = doc('#m-pl-container > li:nth-child(' + str(i) +') > div > a').attr('href')
a1 = 'https://music.163.com/api' + a.replace('?','/detail?')
data.append(a1)
list1.extend(data)
time.sleep(5+random.random())
return list1иҝҷж ·жҲ‘们е°ұеҸҜд»ҘиҺ·еҫ—38йЎөжҜҸйЎө35зҜҮжӯҢеҚ•пјҢе…ұ1300+зҜҮжӯҢеҚ•гҖӮ
дёӢйқўжҲ‘们йңҖиҰҒиҝӣе…ҘжҜҸзҜҮжӯҢеҚ•зҲ¬еҸ–жүҖжңүжӯҢжӣІurlпјҢ并且иҰҒжіЁж„ҸжңҖеҗҺвҖңеҺ»йҮҚвҖқпјҢдёҚеҗҢжӯҢеҚ•еҸҜиғҪеҢ…еҗ«еҗҢдёҖйҰ–жӯҢжӣІгҖӮ
зӮ№ејҖдёҖзҜҮжӯҢеҚ•пјҢжіЁж„ҸзәўиүІеңҲеҮәзҡ„idгҖӮ
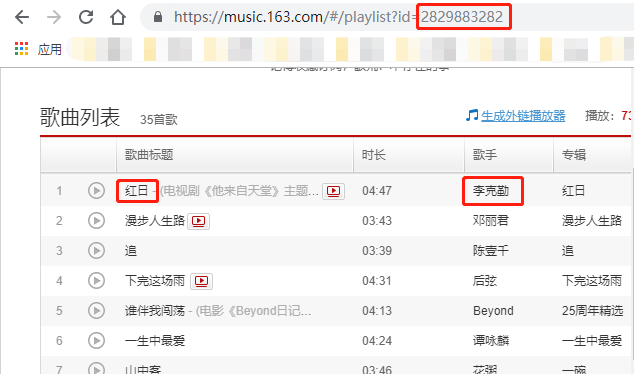
и§ӮеҜҹдёҖдёӢпјҢжҲ‘们иҰҒеңЁжҜҸзҜҮжӯҢеҚ•дёӢж–№иҺ·еҸ–зҡ„дҝЎжҒҜд№ҹе°ұжҳҜзәўжЎҶеңҲеҮәзҡ„иҝҷдәӣпјҢеҲ©з”ЁеҲҡеҲҡзҲ¬еҸ–еҲ°зҡ„жӯҢеҚ•idе’ҢзҪ‘жҳ“дә‘йҹід№җзҡ„apiпјҲдёӢдёҖзҜҮж–Үз« з»Ҷи®ІпјүеҸҜд»Ҙжһ„йҖ еҮәпјҡ
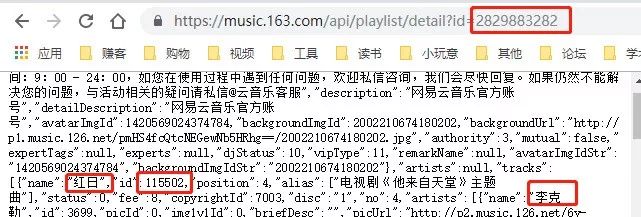
дёҚж–№дҫҝзңӢзҡ„иҜқжҲ‘们解жһҗдёҖдёӢjsonгҖӮ

def get_playlist(url):
data = []
doc = get_json(url)
obj=json.loads(doc)
jobs=obj['result']['tracks']
for job in jobs:
dic = {}
dic['name']=jsonpath.jsonpath(job,'$..name')[0] #жӯҢжӣІеҗҚз§°
dic['id']=jsonpath.jsonpath(job,'$..id')[0] #жӯҢжӣІID
data.append(dic)
return dataиҝҷж ·жҲ‘们е°ұиҺ·еҸ–дәҶжүҖжңүжӯҢеҚ•дёӢзҡ„жӯҢжӣІпјҢи®°еҫ—еҺ»йҮҚгҖӮ
#еҺ»йҮҚ
data = data.drop_duplicates(subset=None, keep='first', inplace=True)
еү©дёӢе°ұжҳҜиҺ·еҸ–жҜҸйҰ–жӯҢжӣІзҡ„зғӯиҜ„дәҶпјҢдёҺеүҚйқўиҺ·еҸ–жӯҢжӣІзұ»дјјпјҢд№ҹжҳҜж №жҚ®apiжһ„йҖ пјҢеҫҲе®№жҳ“е°ұжүҫеҲ°дәҶгҖӮ
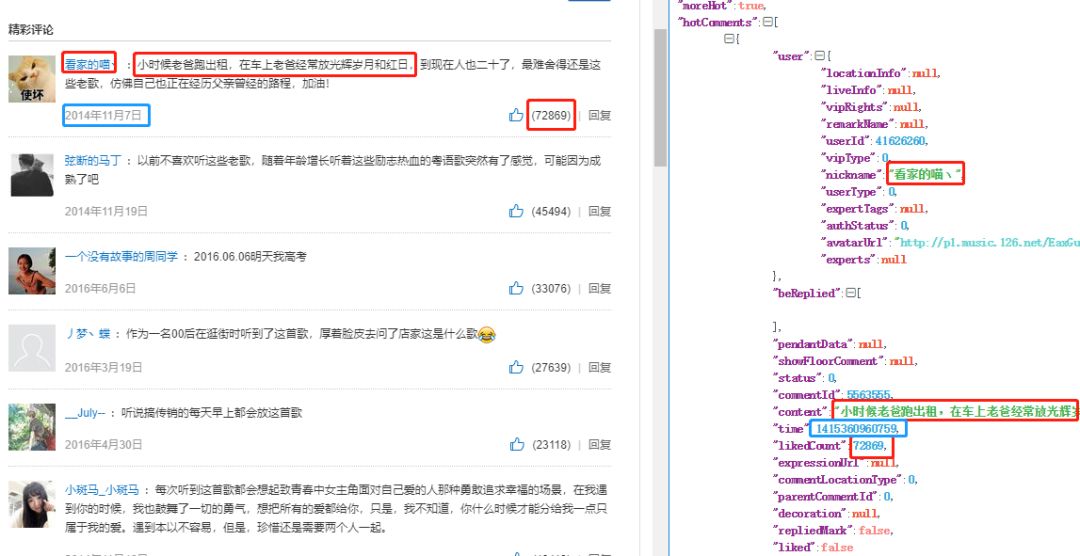
def get_comments(url,k):
data = []
doc = get_json(url)
obj=json.loads(doc)
jobs=obj['hotComments']
for job in jobs:
dic = {}
dic['content']=jsonpath.jsonpath(job,'$..content')[0]
dic['time']= stampToTime(jsonpath.jsonpath(job,'$..time')[0])
dic['userId']=jsonpath.jsonpath(job['user'],'$..userId')[0] #з”ЁжҲ·ID
dic['nickname']=jsonpath.jsonpath(job['user'],'$..nickname')[0]#з”ЁжҲ·еҗҚ
dic['likedCount']=jsonpath.jsonpath(job,'$..likedCount')[0]
dic['name']= k
data.append(dic)
return dataжұҮжҖ»еҗҺе°ұиҺ·еҫ—дәҶ44дёҮжқЎйҹід№җзғӯиҜ„ж•°жҚ®гҖӮ

ж•°жҚ®еҲҶжһҗ
жё…жҙ—еЎ«е……дёҖдёӢгҖӮ
def data_cleaning(data):
cols = data.columns
for col in cols:
if data[col].dtype == 'object':
data[col].fillna('зјәеӨұж•°жҚ®', inplace = True)
else:
data[col].fillna(0, inplace = True)
return(data)жҢүз…§зӮ№иөһж•°жҺ’дёӘеәҸгҖӮ
#жҺ’еәҸ
df1['likedCount'] = df1['likedCount'].astype('int')
df_2 = df1.sort_values(by="likedCount",ascending=False)
df_2.head()
еҶҚзңӢзңӢе“ӘдәӣзғӯиҜ„жҳҜиў«еӨҚеҲ¶зІҳиҙҙжҗ¬жқҘжҗ¬еҺ»зҡ„гҖӮ
#жҺ’еәҸ
df_line = df.groupby(['content']).count().reset_index().sort_values(by="name",ascending=False)
df_line.head()

第дёҖдёӘе’Ң第дёүдёӘеҸӘжҳҜжң«е°ҫжңүжІЎжңүеҸҘеҸ·зҡ„еҢәеҲ«пјҢеҸҜд»ҘеҪ’дёәдёҖзұ»гҖӮиҝҷж ·зҡ„иҜқпјҢйҮҚеӨҚж¬Ўж•°жңҖеӨҡдёӘиҝҷеҸҘиҜқз«ҹ然йҮҚеӨҚдәҶ412ж¬ЎпјҢйўқ~~
зңӢзңӢдёҠзғӯиҜ„ж¬Ўж•°ж¬Ўж•°жңҖеӨҡзҡ„жҳҜе“ӘдҪҚеӨ§зҘһпјҹд»Һд»–зҡ„иә«дёҠжҲ‘们иғҪеӯҰеҲ°д»Җд№Ҳз»ҸйӘҢпјҹ
df_user = df.groupby(['userId']).count().reset_index().sort_values(by="name",ascending=False)
df_user.head()
жҢүз…§ user_id жұҮжҖ»дёҖдёӢпјҢжҺ’еәҸгҖӮ
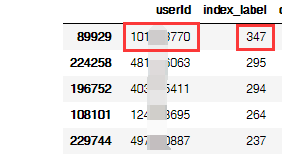
жҲҗеҠҹвҖңжҚ•иҺ·вҖқдёҖжһҡвҖңж®өеӯҗжүӢвҖқпјҢдёҠзғӯиҜ„ж¬Ўж•°й«ҳиҫҫ347пјҢжҲ‘们еҶҚзңӢзңӢиҝҷдҪҚеӨ§зҘһ究з«ҹйғҪиҜ„и®әдәӣд»Җд№Ҳпјҹ
df_user_max = df.loc[(df['userId'] == 101***770)]
df_user_max.head()

иҝҷдҪҚвҖңеӨұзң зҡ„йҷҲе…Ҳз”ҹвҖқзңӢжқҘеҗ„з§Қжғ…иҜқеЁҙзҶҹдәҺжүӢе•ҠпјҢдёӢйқўе°ұд»Ҙд»–дёҫдҫӢжқҘзңӢзңӢеҰӮдҪ•жҲҗдёәзҪ‘жҳ“дә‘йҹід№җиҜ„и®әйҮҢзҡ„зғӯиҜ„ж®өеӯҗжүӢеҗ§гҖӮ
ж•°жҚ®еҸҜи§ҶеҢ–
е…ҲзңӢзңӢиҝҷ347жқЎиҜ„и®әзҡ„иөһж•°еҲҶеёғгҖӮ
#иөһж•°еҲҶеёғеӣҫ
import matplotlib.pyplot as plt
data = df_user_max['likedCount']
#data.to_csv("df_user_max.csv", index_label="index_label",encoding='utf-8-sig')
plt.hist(data,100,normed=True,facecolor='g',alpha=0.9)
plt.show()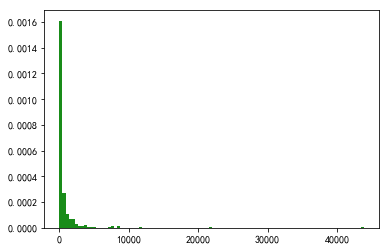
еҫҲжҳҺжҳҫпјҢиөһ数并дёҚеӨҡпјҢеӨ§йғЁеҲҶйғҪеңЁ500иөһд№ӢеҶ…пјҢеҮ зҷҫиөһеҚҙиғҪи·»иә«зғӯиҜ„пјҢиҝҷд№ҹдҫ§йқўиҜҙжҳҺдәҶиҝҷдәӣжӯҢжӣІжҳҜжҜ”иҫғе°Ҹдј—зҡ„пјҢзңӢжқҘжҳҜз»ҸеёёеңЁж–°жӯҢеҢәе№ҝж’’зҪ‘гҖӮ
жҲ‘们дҪҝз”Ёlen() жұӮеҮәжҜҸжқЎиҜ„и®әзҡ„еӯ—з¬ҰдёІй•ҝеәҰпјҢеҶҚз”»дёӘеҲҶеёғеӣҫ
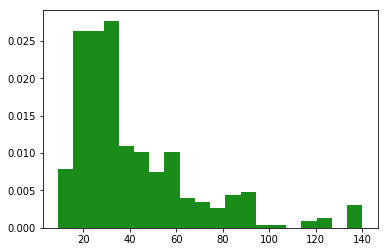
иҜ„и®әзҡ„еӯ—ж•°йӣҶдёӯеңЁ18вҖ”30еӯ—д№Ӣй—ҙпјҢиҝҷиҜҙжҳҺеңЁз•ҷиЁҖж—¶иҰҒжіЁж„Ҹеӯ—ж•°пјҢдҝқйҷ©зҡ„еҒҡжі•жҳҜдёҚиҰҒеӨӘй•ҝи®©дәәиҜ»дёҚдёӢеҺ»пјҢд№ҹдёҚиҰҒеӨӘзҹӯд»Ҙе…ҚдёҚеӨҹз»Ҹе…ёгҖӮ
еҒҡдёӘиҜҚдә‘гҖӮ

еҸҜд»ҘзңӢеҮәд»–зҡ„иҜ„и®әйЈҺж јжҳҜд»ҘдёҖйҰ–жӯҢдҪҝд»–вҖңжғіиө·вҖқвҖңж„ҹи§үвҖқдёәејҖеӨҙпјҢе®ҫиҜӯйҖҡеёёжҳҜвҖңе–ңж¬ўзҡ„еҘіеӯ©еӯҗвҖқпјҢд№ҹз»Ҹеёёз”ЁвҖқеҘ№вҖқжқҘжҢҮд»ЈгҖӮеҜ„жүҳзҡ„жғ…ж„ҹжҳҜвҖңеҗҺжӮ”вҖқвҖңжӮІдјӨвҖқпјҢж„ҹж…Ёзҡ„з»ҲзӮ№жҳҜвҖңж”ҫдёӢвҖқгҖӮ
д»ҘдёҠе°ұжҳҜжҖҺд№Ҳз”ЁPythonеҲҶжһҗ44дёҮжқЎж•°жҚ®пјҢе°Ҹзј–зӣёдҝЎжңүйғЁеҲҶзҹҘиҜҶзӮ№еҸҜиғҪжҳҜжҲ‘们ж—Ҙеёёе·ҘдҪңдјҡи§ҒеҲ°жҲ–з”ЁеҲ°зҡ„гҖӮеёҢжңӣдҪ иғҪйҖҡиҝҮиҝҷзҜҮж–Үз« еӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮжӣҙеӨҡиҜҰжғ…敬иҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





