AWR(全称Automatic Workload Repository)是Oracle 10g版本推出的新特性,随数据库一起被安装的性能收集和分析工具。AWR可以收集场景运行期间的各方面性能数据,还可以从统计数据中分析出度量数据,通过分析报告,可以了解整个系统的运行情况,因而,oracle数据库常用的性能调优利器。
AWR是通过对比两次快照(snapshot)收集到的统计信息来生成报告。报告格式可以选择TXT或HTML,通常会选择生成方便阅读的HTML格式的报告。
生成AWR报告的方法如下:
1、使用sqlplus或pl/sql连接数据库,执行快照生成命令,注意执行的用户必须拥有DBA角色:
exec dbms_workload_repository.create_snapshot;
2、执行awr报告生成脚本,命令如下,注意在执行该命令前,通常会在场景执行后和结束前分别执行一次上述的快照命令:
@$ORACLE_HOME/rdbms/admin/awrrpt.sql
效果如下:

如果使用pl/sql,在命令窗口(Command Window)指定awrrpt.sql的绝对路径,执行该脚本即可。
3、执行脚本会进入交互模式,输入html,即指定生成html格式的报告,如图:

4、输入要读取多少天内的快照信息,通常输入1,即最近1天内的快照,如图:

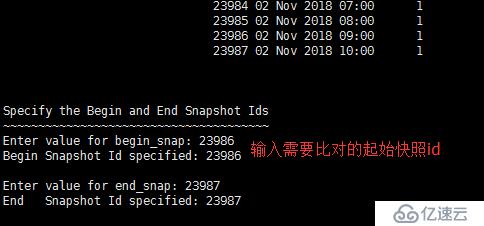
5、指定需要比对的开始快照和结束快照的id,如图:
6、输入要生成awr报告的名字,以.html结尾,默认以前面输入的snap_id命名,如图:

7、脚本执行完成即可生成awr报告,默认报告会生成在当前路径,如oracle用户的家目录,或者使用pl/sql,默认在工具目录下。
AWR报告提供了详细的数据,通过Main Report部分可以快速了解SQL、实例活动、等待事件、段统计等各部分的度量数据,如图所示:

1、前言分析

从该部分可以了解到数据库的空闲程度,如果DB Time远远小于Elapsed时间,说明数据库比较空闲。从上图可知,在3.15分钟的时间段内,数据库耗时31.11分钟,该时间是累加了所有CPU的时间,服务器有48个CPU,平均每个CPU耗时0.64(31/48),CPU利用率约20%(0.64/3.15), 说明系统压力不大。
2、Report Summary分析

Report Summary的Cache Sizes部分显示了SGA中每个区域的大小,其中,Buffer Cache用于缓存物理磁盘上的磁盘块,加快对磁盘数据的访问速度;shared pool主要包括library cache和dictionary cache。library cache用来存储最近解析(或编译)后SQL、PL/SQL和Java classes等。 dictionary cache用来存储最近引用的数据字典。发生在library cache或dictionary cache的cache miss代价要比发生在buffer cache的代价高得多,因此shared pool的设置要确保最近使用的数据都能被cache。

Load Profile 显示数据库整体负载情况。经验上Logons大于每秒2个、Hard parses大于每秒100、全部parses超过每秒300表示可能有争用问题。

该部分数据显示了Oracle关键指标的内存命中率及数据库实例的操作效率。各指标的期望数据是100%,但需要根据应用的特点判断是否存在瓶颈。
Buffer Nowait:表示在内存获得数据的未等待比例,Buffer Nowait的这个值一般需要大于99%,否则可能存在争用;
buffer hit:表示从内存中命中数据块的比率,如果此值低于80%,应该给数据库分配更多的内存。数据块在数据缓冲区中的命中率,通常应在95%以上;
Redo NoWait:表示在LOG缓冲区获得Buffer的未等待比例,这个值一般需要大于90%;
library hit:表示从Library Cache中检索到一个解析过的SQL语句的比率,通常应该保持在95%以上,否则需要要考虑加大共享池、使用绑定变量、修改cursor_sharing等参数;
Latch Hit:通常Latch Hit要大于99%,否则意味着Shared Pool latch争用,可能由于未共享的SQL,或者Library Cache太小,可使用绑定变量或调大Shared Pool解决;
Parse CPU to Parse Elapsd:解析实际运行时间/(解析实际运行时间+解析中等待资源时间),越高越好;
Non-Parse CPU :SQL实际运行时间/(SQL实际运行时间+SQL解析时间),太低表示解析消耗时间过多;
Execute to Parse:是语句执行与分析的比例,如果要SQL重用率高,则这个比例会很高。该值越高表示一次解析后被重复执行的次数越多;
In-memory Sort:在内存中排序的比率,如果过低说明有大量的排序在临时表空间中进行,需考虑调大PGA。如果低于95%,可以通过适当调大初始化参数PGA_AGGREGATE_TARGET或者SORT_AREA_SIZE来解决;
Soft Parse:软解析的百分比(softs/softs+hards),近似sql在共享区的命中率,如果太低,则需要调整应用使用绑定变量;

Memory Usage %:对于已经运行一段时间的数据库来说,Memory Usage使用率应该稳定在75%-90%间,如果太小,说明Shared Pool有浪费,而如果高于90,说明共享池中有争用,内存不足;
SQL with executions>1:执行次数大于1的sql比率,如果此值太小(一般是70%),说明需要在应用中更多使用绑定变量,避免过多SQL解析;
Memory for SQL w/exec>1:执行次数大于1的SQL消耗内存的占比;
3、Top 5 Timed Events分析

该部分显示了系统中最严重的5个等待,并按所占等待时间的比例倒序列示。性能问题诊断或调优时,通常会首先从这里入手,根据等待事件确定排查和优化方向。在没有性能问题的数据库中,CPU time总是列在第一个。
4、SQL Statistics分析

该部分依据资源类别列出了资源消耗最严重的SQL语句,并显示它们在统计期内所占资源的比例,为性能调优提供方向。如CPU资源是系统性能瓶颈时,优化CPU time 最多的SQL语句将获得最大效果,而在I/O等待最严重的系统中,优化Reads最多的SQL语句往往能获得明显效果。
5、IO 分析

该部分列出了每个表空间的I/O统计数据。通过,Av Rd(ms)不应该超过30,否则认为有I/O争用。
关于python学习、分享、交流,笔者开通了微信公众号【小蟒社区】,感兴趣的朋友可以关注下,欢迎加入,建立属于我们自己的小圈子,一起学python。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



