正所谓“福无双至,祸不单行”,生产上有套2节点Oracle 11.2.0.4数据库,其中2节点因硬件故障宕机,1节点去HANG住了。我们一起来分析这起故障。
凌晨4点半,值班同时电话说一套生产库节点2宕机了,机房的同事看机器正在启动,估计是硬件原因导致的。心想节点2宕了还有一个节点1在跑,应该问题不大,于是继续睡觉,离公司近的另一位DBA同事赶往现场支持。可是没有过多长时间,到现场的DBA反馈信息:活着的另一节点也出问题了。在宕掉的那个节点2上部署了ogg,由于宕机,自动切换到了节点1,但ogg的复制进程延迟一直的增长,感觉像是一直没有应用。
尝试用sqlplus进入库结果却报了ORA-00020超过最大进程数,无法登录数据库,无法分析数据库当前的状况。
于是分析哪个应用服务器连接这套数据库,是不是由于应用问题造成的。
找到连接数最多的那个ip上的应用,与相关业务人员确认,可以封堵其连接数据库的端口,减少数据库的外部连接。可是把这个ip禁掉之后,别的ip连接数又涨上来了。开始想到,是不是由于数据库的问题导致应用处理慢,进而导致连接数过多呢。现在无法登录数据库也无法进行验证。
与业务部门沟通是否可以尝试kill部分会话,让DBA可以连接到数据库后台,进行一些管理操作,和性能分析。得到业务部分同事的肯定答复之后,kill了部分LOCAL=NO的会话。以sysdba登录数据库后台,执行性能分析语句,刚查完session的等待事件,查第二个sql的时候,sql执行卡住了。从新的窗口登录数据库依然报ORA-00020。这里进一步确定了是由于数据库的性能问题导致了ogg及应用的问题。
数据库都HANG住了,如何分析呢?
想到了以前看别人分享的一个hanganalyze在数据库HANG住时可以用于分析HANG的原因,于是找到命令ORADEBUG hanganalyze 3。分析trace文件,看到hang chain如下图

再往下看,SMON进程在等待parallel recovery coord wait for reply,等待时间已经有289min,正是故障出现到hanganalyze的时间,而且他阻塞了1465个session。
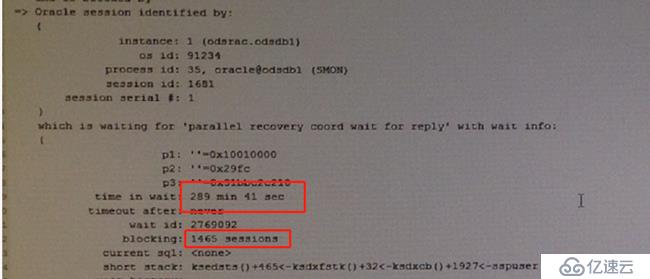
从trace中看到等待事件为parallel recover coord wait for reply 、gc domain validation。没见过这个等待事件,于是查询MOS,关于这两个等待事件的文档不是很多,找到一篇

不知是否触发了ORACLE的BUG。
由于时间紧迫,只能选择把节点1的数据库实例进行重启,重启后数据库恢复正常。
事后找大神帮忙分析原因,看SMON进程的trace信息 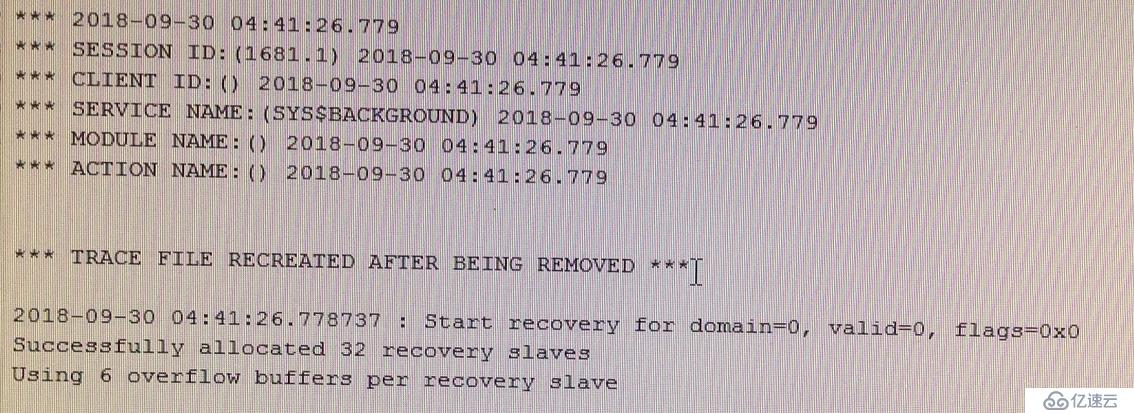
发现正在做并行恢复,查看OSW中的SMON进程监控,没有发现性能问题。 
查看到有大量的p00xx的进程,说明是在并行进行恢复,也没有看出有什么问题。
大神建议使用TFA查看日志进行详细,结果没有时间分析就给搁置了。
总结故障就是:节点2宕机,节点1要接管节点2的数据,结果节点1也因为接管HANG住了。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





