本篇文章给大家分享的是有关用Python做数据科学时容易忘记的八个要点分别是什么,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
如果你发觉自己在编程时一次又一次地查找相同的问题、概念或是语法,你不是一个人!
虽然我们在StackOverflow或其他网站上查找答案是很正常的事情,但这样做确实比较花时间,也让人怀疑你是否完全理解了这门编程语言。
我们现在生活的世界里,似乎有着无限的免费资源,而你只需要一次搜索即可获得。然而,这既是这个时代的幸事,也是一种诅咒。如果没能有效利用资源,而是对它们过度依赖,你就会养成不良的习惯,长期处于不利境地。

当我谷歌一个问题,发现有人提了同样问题,但下面只有一个回答,而且2003年以后就再也没有新的答案的时候,我真是和那个提问者同病相怜!弱小,可怜又无助!
“你是谁!你在哪儿!最后你发现了啥!”
就个人而言,我发现自己也是多次从类似的技术问答中找代码(见上文插图漫画);而不是花时间学习和巩固概念,以便下次可以自己把代码写出来。
网上搜索答案是一种懒惰的行为,虽然在短期内它可能是最简便的途径,但它终究不利于你的成长,并且会降低工作效率和对语法的熟知能力(咳咳,面试的时候这些知识很重要)。
目标
最近,我一直在Udemy学习名为Python for Data Science and Machine Learning的数据科学在线课程。在该系列课程的早期课件中,我想起了用Python做数据分析时一直被我忽略的一些概念和语法。
为了一劳永逸地巩固我对这些概念的理解,并为大家免去一些StackOverflow的搜索,我在文章中整理了自己在使用Python,NumPy和Pandas时总是忘记的东西。
我为每个要点提供了简短的描述和示例。为了给读者带来福利,我还添加了视频和其他资源的链接,以便大家更深入地了解各个概念。
单行List Comprehension
每次需要定义某种列表时都要写for循环是很乏味的,好在Python有一种内置的方法可以用一行代码解决这个问题。该语法可能有点难以理解,但是一旦熟悉了这种技巧,你就会经常使用它。

* Line 8是对for loop的单行简化
请参阅上图和下文的示例,比较一下在创建列表时,你通常使用的for循环样板和以单行代码创建这二者之间的差别。
x = [1,2,3,4] out = [] for item in x: out.append(item**2) print(out) [1, 4, 9, 16] # vs. x = [1,2,3,4] out = [item**2 for item in x] print(out) [1, 4, 9, 16]
Lambda 函数
编程的过程中经常为了实现最后的功能,创建一个又一个阶段性的函数,这些函数往往就只用一两次。这个过程很烦人。这时候Lambda函数来搭救你了!
Lambda函数用于在Python中创建小型的,一次性的和匿名的函数对象。基本上,它们可以让你“在不创建新函数的情况下”创建一个函数。
lambda函数的基本语法如下:
lambda arguments: expression
所以,只要给它一个表达式,lambda函数可以执行所有常规函数可执行的操作。请看下面的简单示例和后文中的视频,以更好地感受lambda函数强大的功能。
double = lambda x: x * 2 print(double(5)) 10
Map和Filter
一旦掌握了lambda函数,并学会将它们与map和filter函数配合使用,你将拥有一个强大的工具。
具体来说,map函数接受一个列表并通过对每个元素执行某种操作来将其转换为新列表。在下面的示例中,它遍历每个元素并将其乘以2的结果映射到新列表。请注意,这里的list函数只是将输出转换为列表类型。
# Map seq = [1, 2, 3, 4, 5] result = list(map(lambda var: var*2, seq)) print(result) [2, 4, 6, 8, 10]
filter函数需要的输入是列表和规则,非常类似于map,但它通过将每个元素与布尔过滤规则进行比较来返回原始列表的子集。
# Filter seq = [1, 2, 3, 4, 5] result = list(filter(lambda x: x > 2, seq)) print(result) [3, 4, 5]
Arange和Linspace
要创建快速简单的NumPy数组,可以查看arange和linspace函数。它们都有特定的用途,但在这里我们看中的是它们都输出Numpy数组(而非其使用范围),这通常更容易用于数据科学。
Arange在给定的范围内返回间隔均匀的值。除了起始值和终止值,你还可以根据需要定义步长或数据类型。请注意,终止值是一个“截止”值,因此它不会被包含在数组输出中。
# np.arange(start, stop, step) np.arange(3, 7, 2) array([3, 5])
Linspace与Arange非常相似,但略有不同。Linspace是在指定的范围内返回指定个数的间隔均匀的数字。所以给定一个起始值和终止值,并指定返回值的个数,linspace将根据你指定的个数在NumPy数组中划好等分。这对于数据可视化和在定义图表坐标轴时特别有用。
# np.linspace(start, stop, num) np.linspace(2.0, 3.0, num=5) array([ 2.0, 2.25, 2.5, 2.75, 3.0])
Axis的真正意义
在Pandas中删除列或在NumPy矩阵中对值进行求和时,可能会遇到这问题。即使没有,那么你也肯定会在将来的某个时候碰到。我们现在来看看删除列的示例:
df.drop('Row A', axis=0) df.drop('Column A', axis=1)
在我知道自己为什么要这样定义坐标轴之前,我不知道我写了多少次这行代码。你可以从上面看出,如果要处理列,就将axis设为1,如果要处理行,则将其设为0。
但为什么会这样呢?我记得我最喜欢的解释是这个:
df.shape (# of Rows, # of Columns)
从Pandas的dataframe调用shape属性时会返回一个元组,其中第一个值表示行数,第二个值表示列数。如果你想想在Python中是如何建立索引的,即行为0,列为1,会发现这与我们定义坐标轴值的方式非常相似。很有趣吧!
Concat, Merge, 和Join
如果你熟悉SQL,那么这些概念对你来说可能会更容易。无论如何,这些功能基本上就是以特定方式组合dataframe的方法。可能很难评判在什么时候使用哪个最好,所以让我们都回顾一下。
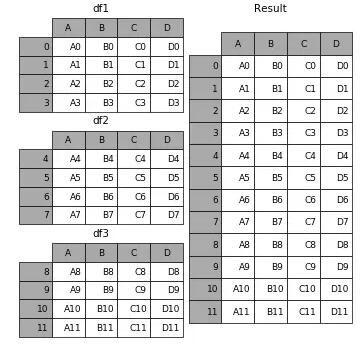
Concat允许用户在其下方或旁边附加一个或多个dataframe(取决于你如何定义轴)。
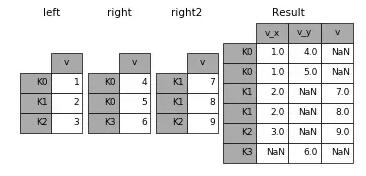
Merge可以基于特定的、共有的主键(Primary Key)组合多个dataframe。

Join,就像merge一样,可以组合两个dataframe。但是,它根据它们的索引进行组合,而不是某些特定的主键。
大家可以查看很有帮助的Pandas文档,了解语法和具体示例和你可能会遇到的特殊情况。
Pandas Apply
apply类似于map函数,不过它是用于Pandas DataFrames的,或者更具体地说是用于Series的。如果你不熟悉也没关系,Series在很大程度上与NumPy中的阵列(array)非常相似。
Apply会根据你指定的内容向列或行中的每个元素发送一个函数。你可以想象这是多么有用,特别是在对整个DataFrame的列处理格式或运算数值的时候,可以省去循环。
透视表
最后要说到的是透视表。如果你熟悉Microsoft Excel,那么你可能已经听说过数据透视表。Pandas内置的pivot_table函数将电子表格样式的数据透视表创建为DataFrame。请注意,透视表中的维度存储在MultiIndex对象中,用来声明DataFrame的index和columns。
结语
我的这些Python编程小贴士就到此为止啦。我希望我介绍的这些在使用Python做数据科学时经常遇到的重要但又有点棘手的方法、函数和概念能给你带来帮助。
而我自己在整理这些内容并试图用简单的术语来阐述它们的过程中也受益良多。
以上就是用Python做数据科学时容易忘记的八个要点分别是什么,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





