这篇文章给大家介绍SparkSQL基础知识都有哪些,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。

一个sql 过来 解析成unresolved,只拿出来字段名和表名 但是不知道字段名和表名在哪个位置 需要通过Schema 确定表的位置等信息, 生成逻辑执行计划,Logical,知道数据从哪里来了 通过一些列优化过滤生成物理执行计划Physical 最后把物理执行计划放到spark集群上运行

Spark SQL就是写SQL,这是错误的观点 Spark SQL不是SQL,超出SQL,因为SQL是其一部分 Spark SQL 是处理结构化数据的,只是Spark中的一个模块 Spark SQL 与 Hive on Spark 不是一个东西 Spark SQL 是spark里面的 Hive on Spark 的功能是比Spark SQL多的 Hive on Spark 稳定性不是很好
关系数据库集群成本很高,还是有限的 SQL : schema + file 使用sql的前提就是有schema ,作用到文件上去 hive是进程的 hive2.0 默认引擎是Tez Hive on Spark 就是把hive执行引擎改成spark
mr spark Tez
spark sql 可以跨数据源进行join,例如hdfs与mysql里表内容join Spark SQL运行可以不用hive,只要你连接到hive的metastore就可以
hiveserver2开启可以用JDBC或者ODBC直接连接

spark-sql 与 spark-shell ,thriftserver thriftserver对应hive里面的hiveserver2
./beeline -u jdbc:hive2://localhost:10000 -n root
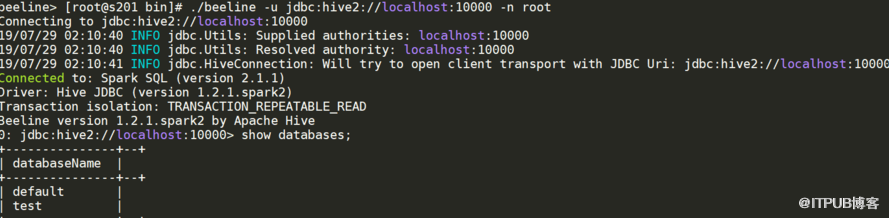
spark-shell、spark-sql 都是是一个独立的 spark application, 启动几个就要几个application,非常耗资源 用thriftserver,无论启动多少个客户端(beeline)连接在一个thriftserver, 是一个独立的spark application, 后面不用在重新申请资源。前一个beeline缓存的,下一个beeline也可以用 用thriftserver,可在ui看执行计划,优化有优势
这个要起来,要不spark-shell, spark-sql,连接不上,这个跟hive一样

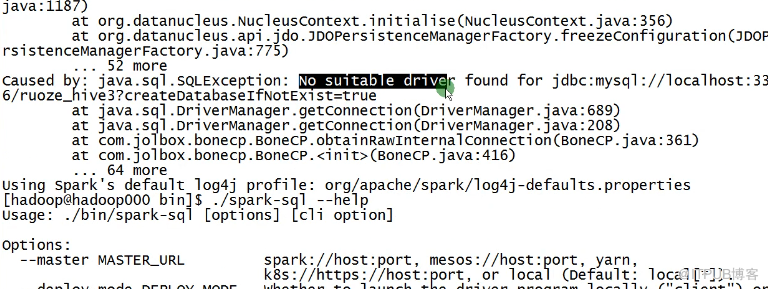
spark-shell --master local[2] --jars /soft/hive/lib/mysql-connector-java-8.0.12.jar 这样启动不起来 你可以试试把mysql-connector-java-8.0.12.jar 放到spark的jars里

关于SparkSQL基础知识都有哪些就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





