目的:分享一下公司的db故障处理流程,主要是思想。
事件描述及影响:
2018年9月30日04:43点,zabbix告警odsdb2数据库疑似宕机,机房值班人员通过堡垒机无法登录数据库服务器,从其他机器也无法ssh登录该机器,同时odsdb1数据库也HANG住,通过命令无法登录数据库。根据数据库业务流程图初步分析影响的各业务。(涉及公司业务可忽略)
事件排查:
4:46,机房值班人员通知DBA及亦庄值班人员分析情况
4:57,按照公司流程在相关群通告故障
5:23,值班人员反应数据库服务器已自动重启,但一直卡在启动界面
5:30,DBA到达现场协助问题排查
5:39,DBA发现ogg进程无法正常启动,原因是数据库连接进程达到上限(3000),数据库无法连接
6:03, 数据分析室人员参与分析ODS问题,确认ods 1节点数据库HANG住
6:56,机房值班人员尝试手动重启odsdb2服务器,仍然卡在启动界面
7:40,尝试通过封堵应用连接数据库的端口的方式,减少应用连接数据库的连接数
8:30,联系HP厂商报障
9:20,kill odsdb1数据库所有的外部连接(先保障主要业务)
9:30,对odsdb1数据库做hang analyze,分析数据库HANG住的原因
10:11,重启oddsdb1数据库实例
10:28,odsdb1恢复正常
10:30,ogg进程恢复正常
10:40,放开过封堵应用的端口
事件分析:
1、 odsdb2节点宕机重启,且无法启动,一直卡在启动界面,怀疑由于数据库硬件问题导致数据库宕机重启。通知服务器厂商进行报障
2、 odsdb1数据库HANG住无法正常提供服务,导致与ods数据库相关的所有应用及ogg受到影响
3、 odsdb1达到设置的最大连接进程数(3000),导致数据库无法登录,无法分析情况。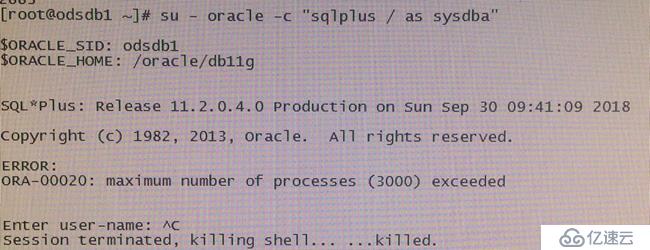
4、 分析哪个应用服务器连接ods数据库,封堵其连接数据库的端口,减少数据库的外部连接
5、 数据库无法登录,需要kill odsdb1数据库所有的外部连接后,可以登录数据库,但数据字典查询缓慢,无法正常分析hang住的原因。且kill掉外部连接后,很快连接数又会涨到最大值。使用hang analyze做trace进行分析。
通过hang analyze分析,数据库是由于gc domain validation 及parallel recory coord wait for reply。
这两个等待事件是数据库节点2宕机后,节点1要接管节点2的服务,回滚节点2上未提交的数据,恢复节点2的数据时的等待事件。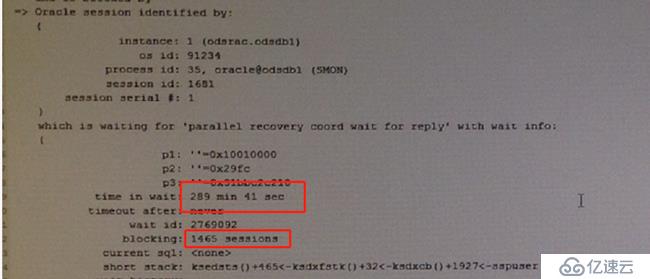
从上图的的信息可以知道,SMON进程在进行节点2的数据恢复,但是等待了289min41sec。且该进行阻塞了1456个进程sessions,由些可以知道节点1是在恢复节点2的数据时SMON进程异常,导致数据库1456个进程被阻塞。
查询Oracle官方网站MOS,发现与gc domain validation相关的一些BUG
6、 重启数据库,数据库恢复正常,可以对外提供服务。进而ODS相关的应用也都恢复正常。
后续的优化方案:
1、定期对数据库进行硬件检查防止此类问题再次发生(节后与数据中心沟通,争取每月做一次检查)
2、后续增加对ODS数据库的切换应急演练
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



