MatplotlibеҸҜи§ҶеҢ–жңҖжңүд»·еҖјзҡ„еӣҫиЎЁжңүе“Әдәӣ
иҝҷзҜҮж–Үз« дё»иҰҒдёәеӨ§е®¶еұ•зӨәдәҶвҖңMatplotlibеҸҜи§ҶеҢ–жңҖжңүд»·еҖјзҡ„еӣҫиЎЁжңүе“ӘдәӣвҖқпјҢеҶ…е®№з®ҖиҖҢжҳ“жҮӮпјҢжқЎзҗҶжё…жҷ°пјҢеёҢжңӣиғҪеӨҹеё®еҠ©еӨ§е®¶и§ЈеҶіз–‘жғ‘пјҢдёӢйқўи®©е°Ҹзј–еёҰйўҶеӨ§е®¶дёҖиө·з ”究并еӯҰд№ дёҖдёӢвҖңMatplotlibеҸҜи§ҶеҢ–жңҖжңүд»·еҖјзҡ„еӣҫиЎЁжңүе“ӘдәӣвҖқиҝҷзҜҮж–Үз« еҗ§гҖӮ
д»Ӣз»Қ
иҝҷдәӣеӣҫиЎЁж №жҚ®еҸҜи§ҶеҢ–зӣ®ж Үзҡ„7дёӘдёҚеҗҢжғ…жҷҜиҝӣиЎҢеҲҶз»„гҖӮ дҫӢеҰӮпјҢеҰӮжһңиҰҒжғіиұЎдёӨдёӘеҸҳйҮҸд№Ӣй—ҙзҡ„е…ізі»пјҢиҜ·жҹҘзңӢвҖңе…іиҒ”вҖқйғЁеҲҶдёӢзҡ„еӣҫиЎЁгҖӮ жҲ–иҖ…пјҢеҰӮжһңжӮЁжғіиҰҒжҳҫзӨәеҖјеҰӮдҪ•йҡҸж—¶й—ҙеҸҳеҢ–пјҢиҜ·жҹҘзңӢвҖңеҸҳеҢ–вҖқйғЁеҲҶпјҢдҫқжӯӨзұ»жҺЁгҖӮ
жңүж•ҲеӣҫиЎЁзҡ„йҮҚиҰҒзү№еҫҒпјҡ
еңЁдёҚжӯӘжӣІдәӢе®һзҡ„жғ…еҶөдёӢдј иҫҫжӯЈзЎ®е’Ңеҝ…иҰҒзҡ„дҝЎжҒҜгҖӮ
и®ҫи®Ўз®ҖеҚ•пјҢжӮЁдёҚеҝ…еӨӘиҙ№еҠӣе°ұиғҪзҗҶи§Је®ғгҖӮ
д»Һе®ЎзҫҺи§’еәҰж”ҜжҢҒдҝЎжҒҜиҖҢдёҚжҳҜжҺ©зӣ–дҝЎжҒҜгҖӮ
дҝЎжҒҜжІЎжңүи¶…иҙҹиҚ·гҖӮ
еҮҶеӨҮе·ҘдҪң
еңЁд»Јз ҒиҝҗиЎҢеүҚе…Ҳеј•е…ҘдёӢйқўзҡ„и®ҫзҪ®еҶ…е®№гҖӮ еҪ“然пјҢеҚ•зӢ¬зҡ„еӣҫиЎЁпјҢеҸҜд»ҘйҮҚж–°и®ҫзҪ®жҳҫзӨәиҰҒзҙ гҖӮ
# !pip install brewer2mpl
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
import warnings; warnings.filterwarnings(action='once')
large = 22; med = 16; small = 12
params = {'axes.titlesize': large,
'legend.fontsize': med,
'figure.figsize': (16, 10),
'axes.labelsize': med,
'axes.titlesize': med,
'xtick.labelsize': med,
'ytick.labelsize': med,
'figure.titlesize': large}
plt.rcParams.update(params)
plt.style.use('seaborn-whitegrid')
sns.set_style("white")
%matplotlib inline
# Version
print(mpl.__version__) #> 3.0.0
print(sns.__version__) #> 0.9.0
3.0.20.9.0
дёҖгҖҒе…іиҒ” пјҲCorrelationпјү
е…іиҒ”еӣҫиЎЁз”ЁдәҺеҸҜи§ҶеҢ–2дёӘжҲ–жӣҙеӨҡеҸҳйҮҸд№Ӣй—ҙзҡ„е…ізі»гҖӮ д№ҹе°ұжҳҜиҜҙпјҢдёҖдёӘеҸҳйҮҸеҰӮдҪ•зӣёеҜ№дәҺеҸҰдёҖдёӘеҸҳеҢ–гҖӮ
1 ж•ЈзӮ№еӣҫпјҲScatter plotпјү
ж•ЈзӮ№еӣҫжҳҜз”ЁдәҺз ”з©¶дёӨдёӘеҸҳйҮҸд№Ӣй—ҙе…ізі»зҡ„з»Ҹе…ёзҡ„е’Ңеҹәжң¬зҡ„еӣҫиЎЁгҖӮ еҰӮжһңж•°жҚ®дёӯжңүеӨҡдёӘз»„пјҢеҲҷеҸҜиғҪйңҖиҰҒд»ҘдёҚеҗҢйўңиүІеҸҜи§ҶеҢ–жҜҸдёӘз»„гҖӮ еңЁ matplotlib дёӯпјҢжӮЁеҸҜд»ҘдҪҝз”Ё plt.scatterplotпјҲпјү ж–№дҫҝең°жү§иЎҢжӯӨж“ҚдҪңгҖӮ
# Import dataset
midwest = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/midwest_filter.csv")
# Prepare Data
# Create as many colors as there are unique midwest['category']
categories = np.unique(midwest['category'])
colors = [plt.cm.tab10(i/float(len(categories)-1)) for i in range(len(categories))]
# Draw Plot for Each Category
plt.figure(figsize=(16, 10), dpi= 80, facecolor='w', edgecolor='k')
for i, category in enumerate(categories):
plt.scatter('area', 'poptotal',
data=midwest.loc[midwest.category==category, :],
s=20, cmap=colors[i], label=str(category))
# "c=" дҝ®ж”№дёә "cmap="пјҢPythonж•°жҚ®д№ӢйҒ“ еӨҮжіЁ
# Decorations
plt.gca().set(xlim=(0.0, 0.1), ylim=(0, 90000),
xlabel='Area', ylabel='Population')
plt.xticks(fontsize=12); plt.yticks(fontsize=12)
plt.title("Scatterplot of Midwest Area vs Population", fontsize=22)
plt.legend(fontsize=12)
plt.show()
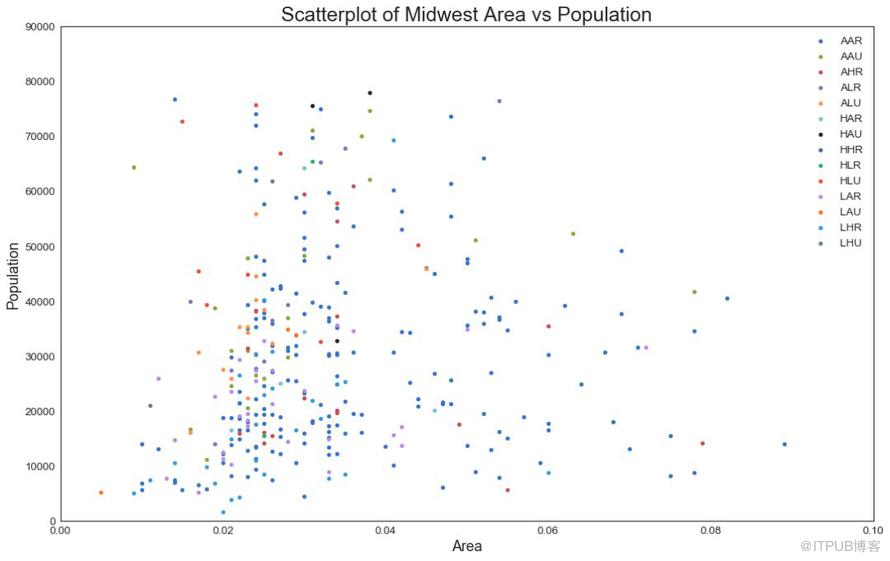
еӣҫ1
2 еёҰиҫ№з•Ңзҡ„ж°”жіЎеӣҫпјҲBubble plot with Encirclingпјү
жңүж—¶пјҢжӮЁеёҢжңӣеңЁиҫ№з•ҢеҶ…жҳҫзӨәдёҖз»„зӮ№д»Ҙејәи°ғе…¶йҮҚиҰҒжҖ§гҖӮ еңЁиҝҷдёӘдҫӢеӯҗдёӯпјҢдҪ д»Һж•°жҚ®жЎҶдёӯиҺ·еҸ–и®°еҪ•пјҢ并用дёӢйқўд»Јз ҒдёӯжҸҸиҝ°зҡ„ encircleпјҲпјү жқҘдҪҝиҫ№з•ҢжҳҫзӨәеҮәжқҘгҖӮ
from matplotlib import patches
from scipy.spatial import ConvexHull
import warnings; warnings.simplefilter('ignore')
sns.set_style("white")
# Step 1: Prepare Data
midwest = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/midwest_filter.csv")
# As many colors as there are unique midwest['category']
categories = np.unique(midwest['category'])
colors = [plt.cm.tab10(i/float(len(categories)-1)) for i in range(len(categories))]
# Step 2: Draw Scatterplot with unique color for each category
fig = plt.figure(figsize=(16, 10), dpi= 80, facecolor='w', edgecolor='k')
for i, category in enumerate(categories):
plt.scatter('area', 'poptotal', data=midwest.loc[midwest.category==category, :],
s='dot_size', cmap=colors[i], label=str(category), edgecolors='black', linewidths=.5)
# "c=" дҝ®ж”№дёә "cmap="пјҢPythonж•°жҚ®д№ӢйҒ“ еӨҮжіЁ
# Step 3: Encircling
# https://stackoverflow.com/questions/44575681/how-do-i-encircle-different-data-sets-in-scatter-plot
def encircle(x,y, ax=None, **kw):
if not ax: ax=plt.gca()
p = np.c_[x,y]
hull = ConvexHull(p)
poly = plt.Polygon(p[hull.vertices,:], **kw)
ax.add_patch(poly)
# Select data to be encircled
midwest_encircle_data = midwest.loc[midwest.state=='IN', :]
# Draw polygon surrounding vertices
encircle(midwest_encircle_data.area, midwest_encircle_data.poptotal, ec="k", fc="gold", alpha=0.1)
encircle(midwest_encircle_data.area, midwest_encircle_data.poptotal, ec="firebrick", fc="none", linewidth=1.5)
# Step 4: Decorations
plt.gca().set(xlim=(0.0, 0.1), ylim=(0, 90000),
xlabel='Area', ylabel='Population')
plt.xticks(fontsize=12); plt.yticks(fontsize=12)
plt.title("Bubble Plot with Encircling", fontsize=22)
plt.legend(fontsize=12)
plt.show()
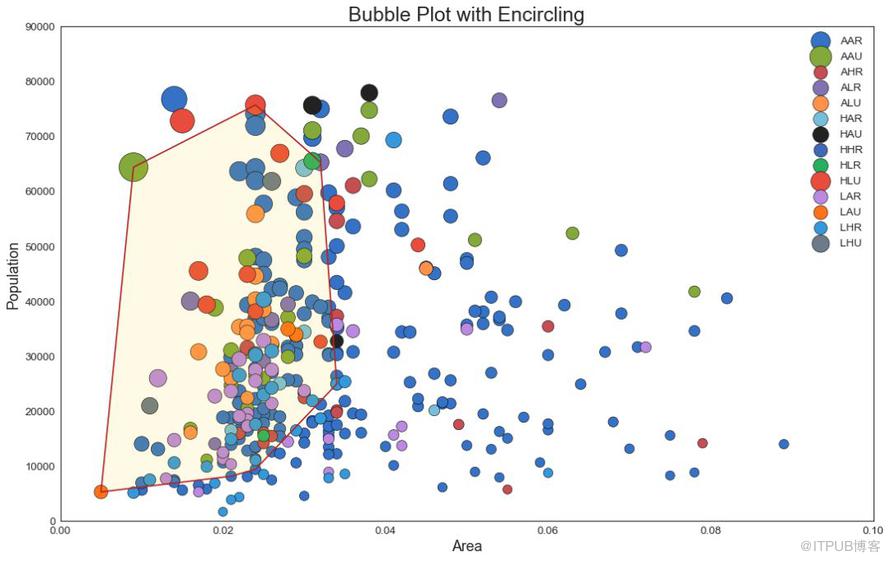
еӣҫ2
3 еёҰзәҝжҖ§еӣһеҪ’жңҖдҪіжӢҹеҗҲзәҝзҡ„ж•ЈзӮ№еӣҫ пјҲScatter plot with linear regression line of best fitпјү
еҰӮжһңдҪ жғідәҶи§ЈдёӨдёӘеҸҳйҮҸеҰӮдҪ•зӣёдә’ж”№еҸҳпјҢйӮЈд№ҲжңҖдҪіжӢҹеҗҲзәҝе°ұжҳҜеёёз”Ёзҡ„ж–№жі•гҖӮ дёӢеӣҫжҳҫзӨәдәҶж•°жҚ®дёӯеҗ„з»„д№Ӣй—ҙжңҖдҪіжӢҹеҗҲзәҝзҡ„е·®ејӮгҖӮ иҰҒзҰҒз”ЁеҲҶ组并仅дёәж•ҙдёӘж•°жҚ®йӣҶз»ҳеҲ¶дёҖжқЎжңҖдҪіжӢҹеҗҲзәҝпјҢиҜ·д»ҺдёӢйқўзҡ„ sns.lmplotпјҲпјүи°ғз”ЁдёӯеҲ йҷӨ hue ='cyl'еҸӮж•°гҖӮ
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")
df_select = df.loc[df.cyl.isin([4,8]), :]
# Plot
sns.set_style("white")
gridobj = sns.lmplot(x="displ", y="hwy", hue="cyl", data=df_select,
height=7, aspect=1.6, robust=True, palette='tab10',
scatter_kws=dict(s=60, linewidths=.7, edgecolors='black'))
# Decorations
gridobj.set(xlim=(0.5, 7.5), ylim=(0, 50))
plt.title("Scatterplot with line of best fit grouped by number of cylinders", fontsize=20)
plt.show()
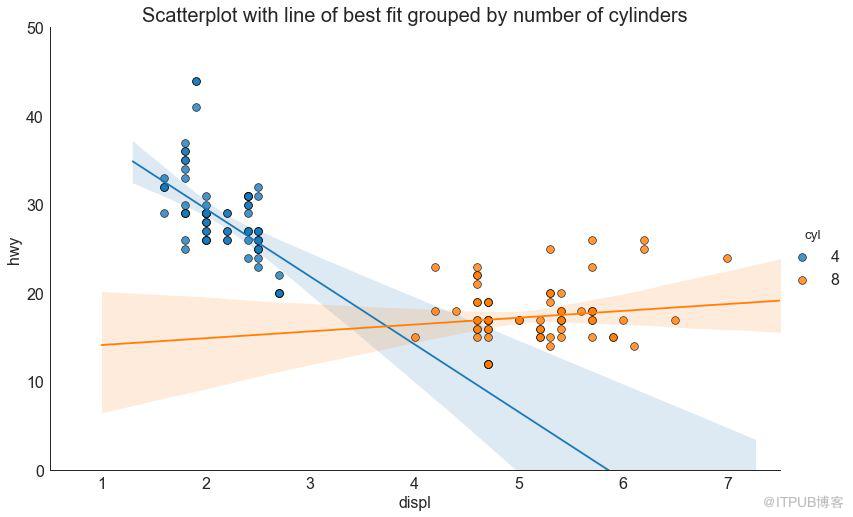
еӣҫ3
й’ҲеҜ№жҜҸеҲ—з»ҳеҲ¶зәҝжҖ§еӣһеҪ’зәҝ
жҲ–иҖ…пјҢеҸҜд»ҘеңЁе…¶жҜҸеҲ—дёӯжҳҫзӨәжҜҸдёӘз»„зҡ„жңҖдҪіжӢҹеҗҲзәҝгҖӮ еҸҜд»ҘйҖҡиҝҮеңЁ sns.lmplot() дёӯи®ҫзҪ® col=groupingcolumn еҸӮж•°жқҘе®һзҺ°пјҢеҰӮдёӢпјҡ
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")
df_select = df.loc[df.cyl.isin([4,8]), :]
# Each line in its own column
sns.set_style("white")
gridobj = sns.lmplot(x="displ", y="hwy",
data=df_select,
height=7,
robust=True,
palette='Set1',
col="cyl",
scatter_kws=dict(s=60, linewidths=.7, edgecolors='black'))
# Decorations
gridobj.set(xlim=(0.5, 7.5), ylim=(0, 50))
plt.show()
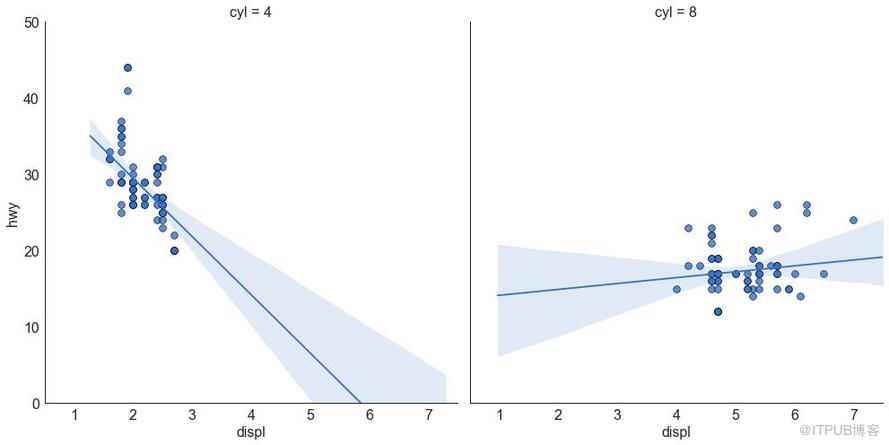
еӣҫ3-2
4 жҠ–еҠЁеӣҫ пјҲJittering with stripplotпјү
йҖҡеёёпјҢеӨҡдёӘж•°жҚ®зӮ№е…·жңүе®Ңе…ЁзӣёеҗҢзҡ„ X е’Ң Y еҖјгҖӮ з»“жһңпјҢеӨҡдёӘзӮ№з»ҳеҲ¶дјҡйҮҚеҸ 并йҡҗи—ҸгҖӮ дёәйҒҝе…Қиҝҷз§Қжғ…еҶөпјҢиҜ·е°Ҷж•°жҚ®зӮ№зЁҚеҫ®жҠ–еҠЁпјҢд»ҘдҫҝжӮЁеҸҜд»Ҙзӣҙи§Ӯең°зңӢеҲ°е®ғ们гҖӮ дҪҝз”Ё seaborn зҡ„ stripplotпјҲпјү еҫҲж–№дҫҝе®һзҺ°иҝҷдёӘеҠҹиғҪгҖӮ
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")
# Draw Stripplot
fig, ax = plt.subplots(figsize=(16,10), dpi= 80)
sns.stripplot(df.cty, df.hwy, jitter=0.25, size=8, ax=ax, linewidth=.5)
# Decorations
plt.title('Use jittered plots to avoid overlapping of points', fontsize=22)
plt.show()
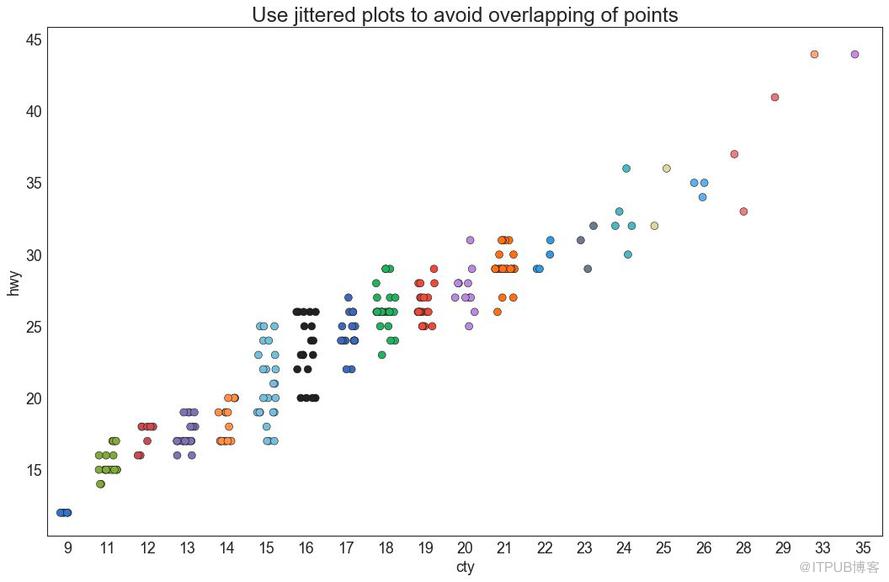
еӣҫ4
5 и®Ўж•°еӣҫ пјҲCounts Plotпјү
йҒҝе…ҚзӮ№йҮҚеҸ й—®йўҳзҡ„еҸҰдёҖдёӘйҖүжӢ©жҳҜеўһеҠ зӮ№зҡ„еӨ§е°ҸпјҢиҝҷеҸ–еҶідәҺиҜҘзӮ№дёӯжңүеӨҡе°‘зӮ№гҖӮ еӣ жӯӨпјҢзӮ№зҡ„еӨ§е°Ҹи¶ҠеӨ§пјҢе…¶е‘Ёеӣҙзҡ„зӮ№зҡ„йӣҶдёӯеәҰи¶Ҡй«ҳгҖӮ
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")
df_counts = df.groupby(['hwy', 'cty']).size().reset_index(name='counts')
# Draw Stripplot
fig, ax = plt.subplots(figsize=(16,10), dpi= 80)
sns.stripplot(df_counts.cty, df_counts.hwy, size=df_counts.counts*2, ax=ax)
# Decorations
plt.title('Counts Plot - Size of circle is bigger as more points overlap', fontsize=22)
plt.show()
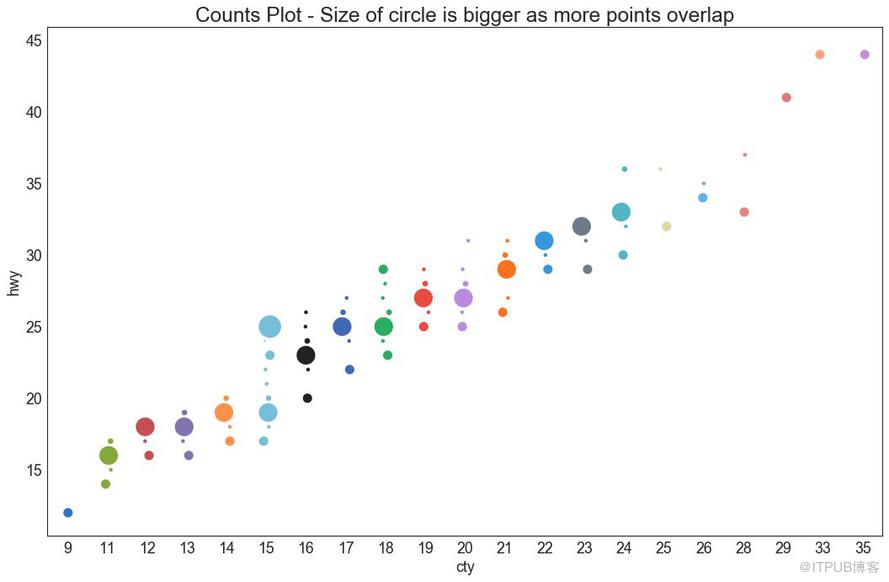
еӣҫ5
6 иҫ№зјҳзӣҙж–№еӣҫ пјҲMarginal Histogramпјү
иҫ№зјҳзӣҙж–№еӣҫе…·жңүжІҝ X е’Ң Y иҪҙеҸҳйҮҸзҡ„зӣҙж–№еӣҫгҖӮ иҝҷз”ЁдәҺеҸҜи§ҶеҢ– X е’Ң Y д№Ӣй—ҙзҡ„е…ізі»д»ҘеҸҠеҚ•зӢ¬зҡ„ X е’Ң Y зҡ„еҚ•еҸҳйҮҸеҲҶеёғгҖӮ иҝҷз§Қеӣҫз»Ҹеёёз”ЁдәҺжҺўзҙўжҖ§ж•°жҚ®еҲҶжһҗпјҲEDAпјүгҖӮ
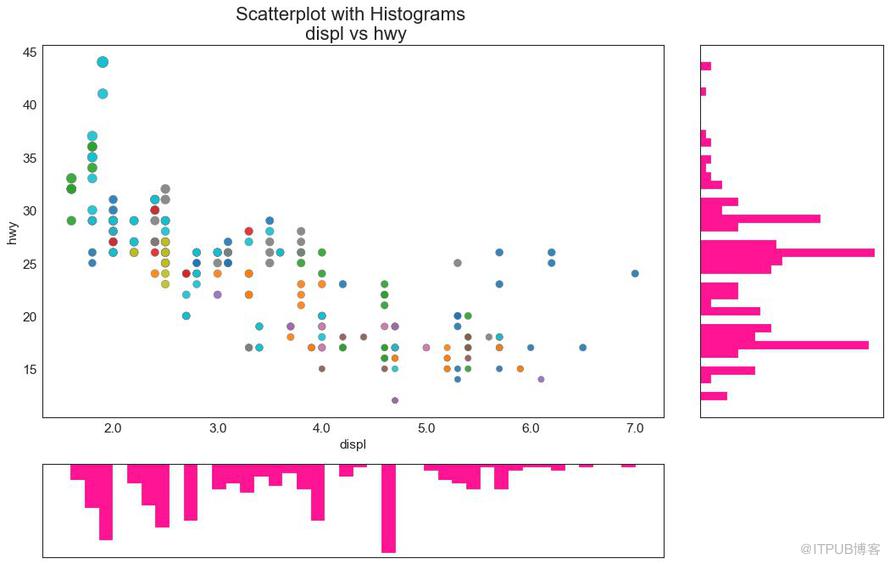
еӣҫ6
7 иҫ№зјҳз®ұеҪўеӣҫ пјҲMarginal Boxplotпјү
иҫ№зјҳз®ұеӣҫдёҺиҫ№зјҳзӣҙж–№еӣҫе…·жңүзӣёдјјзҡ„з”ЁйҖ”гҖӮ 然иҖҢпјҢз®ұзәҝеӣҫжңүеҠ©дәҺзІҫзЎ®е®ҡдҪҚ X е’Ң Y зҡ„дёӯдҪҚж•°гҖҒ第25е’Ң第75зҷҫеҲҶдҪҚж•°гҖӮ
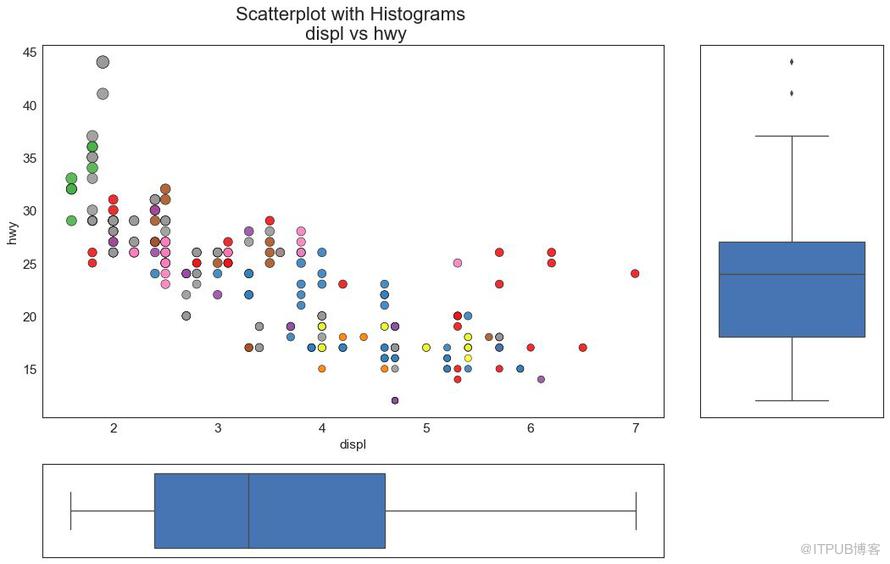
еӣҫ7
8 зӣёе…іеӣҫ пјҲCorrellogramпјү
зӣёе…іеӣҫз”ЁдәҺзӣҙи§Ӯең°жҹҘзңӢз»ҷе®ҡж•°жҚ®жЎҶпјҲжҲ–дәҢз»ҙж•°з»„пјүдёӯжүҖжңүеҸҜиғҪзҡ„ж•°еҖјеҸҳйҮҸеҜ№д№Ӣй—ҙзҡ„зӣёе…іеәҰйҮҸгҖӮ
# Import Dataset
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")
# Plot
plt.figure(figsize=(12,10), dpi= 80)
sns.heatmap(df.corr(), xticklabels=df.corr().columns, yticklabels=df.corr().columns, cmap='RdYlGn', center=0, annot=True)
# Decorations
plt.title('Correlogram of mtcars', fontsize=22)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()
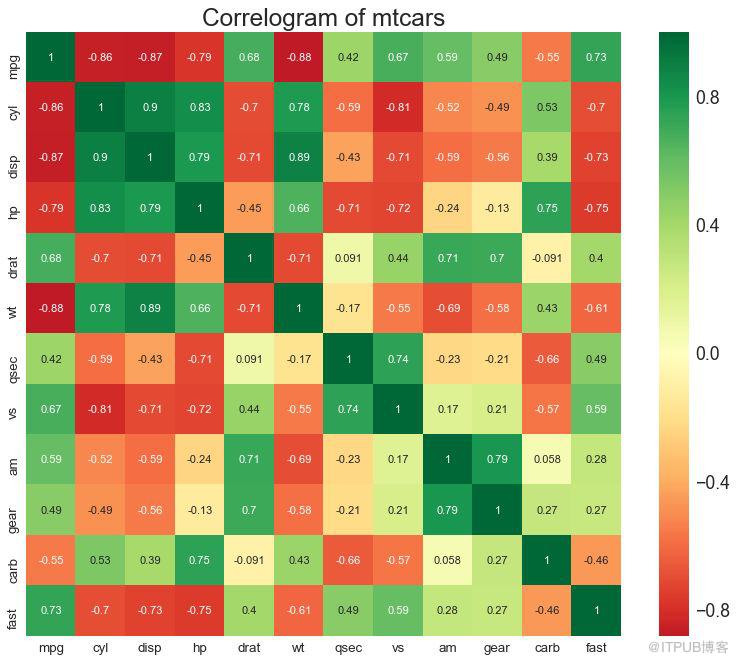
еӣҫ8
9 зҹ©йҳөеӣҫ пјҲPairwise Plotпјү
зҹ©йҳөеӣҫжҳҜжҺўзҙўжҖ§еҲҶжһҗдёӯзҡ„жңҖзҲұпјҢз”ЁдәҺзҗҶи§ЈжүҖжңүеҸҜиғҪзҡ„ж•°еҖјеҸҳйҮҸеҜ№д№Ӣй—ҙзҡ„е…ізі»гҖӮ е®ғжҳҜеҸҢеҸҳйҮҸеҲҶжһҗзҡ„еҝ…еӨҮе·Ҙе…·гҖӮ
# Load Dataset
df = sns.load_dataset('iris')
# Plot
plt.figure(figsize=(10,8), dpi= 80)
sns.pairplot(df, kind="scatter", hue="species", plot_kws=dict(s=80, edgecolor="white", linewidth=2.5))
plt.show()
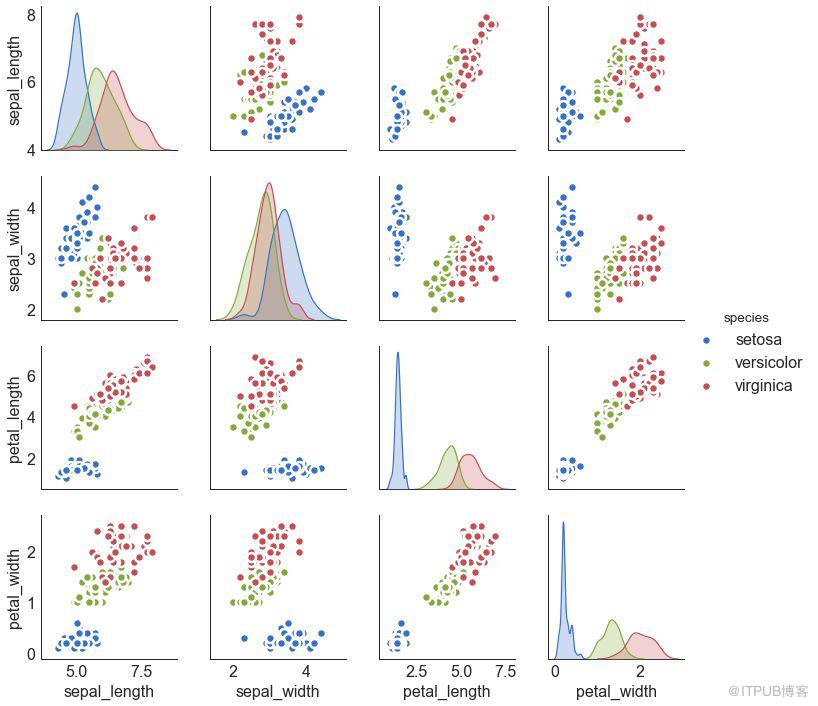
еӣҫ9
# Load Dataset
df = sns.load_dataset('iris')
# Plot
plt.figure(figsize=(10,8), dpi= 80)
sns.pairplot(df, kind="reg", hue="species")
plt.show()
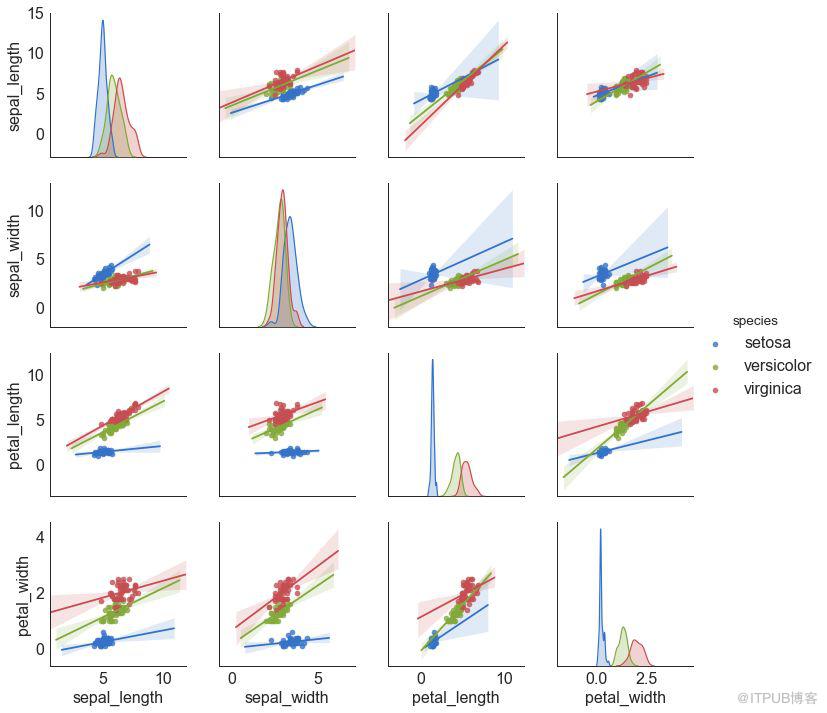
еӣҫ9-2
дәҢгҖҒеҒҸе·® пјҲDeviationпјү
10 еҸ‘ж•ЈеһӢжқЎеҪўеӣҫ пјҲDiverging Barsпјү
еҰӮжһңжӮЁжғіж №жҚ®еҚ•дёӘжҢҮж ҮжҹҘзңӢйЎ№зӣ®зҡ„еҸҳеҢ–жғ…еҶөпјҢ并еҸҜи§ҶеҢ–жӯӨе·®ејӮзҡ„йЎәеәҸе’Ңж•°йҮҸпјҢйӮЈд№Ҳж•ЈеһӢжқЎеҪўеӣҫ пјҲDiverging Barsпјү жҳҜдёҖдёӘеҫҲеҘҪзҡ„е·Ҙе…·гҖӮ е®ғжңүеҠ©дәҺеҝ«йҖҹеҢәеҲҶж•°жҚ®дёӯз»„зҡ„жҖ§иғҪпјҢ并且йқһеёёзӣҙи§ӮпјҢ并且еҸҜд»Ҙз«ӢеҚідј иҫҫиҝҷдёҖзӮ№гҖӮ
# Prepare Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")
x = df.loc[:, ['mpg']]
df['mpg_z'] = (x - x.mean())/x.std()
df['colors'] = ['red' if x < 0 else 'green' for x in df['mpg_z']]
df.sort_values('mpg_z', inplace=True)
df.reset_index(inplace=True)
# Draw plot
plt.figure(figsize=(14,10), dpi= 80)
plt.hlines(y=df.index, xmin=0, xmax=df.mpg_z, color=df.colors, alpha=0.4, linewidth=5)
# Decorations
plt.gca().set(ylabel='$Model$', xlabel='$Mileage$')
plt.yticks(df.index, df.cars, fontsize=12)
plt.title('Diverging Bars of Car Mileage', fontdict={'size':20})
plt.grid(linestyle='--', alpha=0.5)
plt.show()
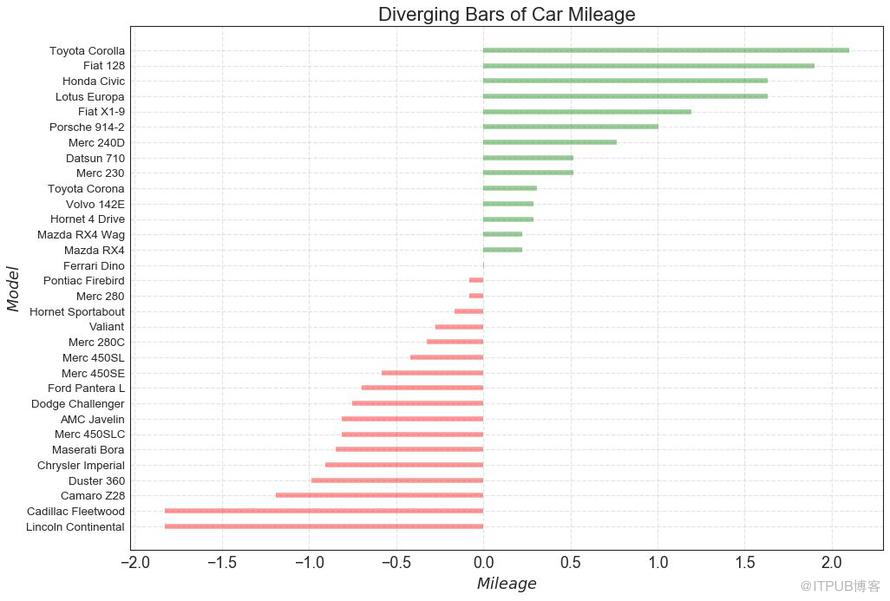
еӣҫ10
11 еҸ‘ж•ЈеһӢж–Үжң¬ пјҲDiverging Textsпјү
еҸ‘ж•ЈеһӢж–Үжң¬ пјҲDiverging TextsпјүдёҺеҸ‘ж•ЈеһӢжқЎеҪўеӣҫ пјҲDiverging BarsпјүзӣёдјјпјҢеҰӮжһңдҪ жғід»ҘдёҖз§ҚжјӮдә®е’ҢеҸҜе‘ҲзҺ°зҡ„ж–№ејҸжҳҫзӨәеӣҫиЎЁдёӯжҜҸдёӘйЎ№зӣ®зҡ„д»·еҖјпјҢе°ұеҸҜд»ҘдҪҝз”Ёиҝҷз§Қж–№жі•гҖӮ
# Prepare Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")
x = df.loc[:, ['mpg']]
df['mpg_z'] = (x - x.mean())/x.std()
df['colors'] = ['red' if x < 0 else 'green' for x in df['mpg_z']]
df.sort_values('mpg_z', inplace=True)
df.reset_index(inplace=True)
# Draw plot
plt.figure(figsize=(14,14), dpi= 80)
plt.hlines(y=df.index, xmin=0, xmax=df.mpg_z)
for x, y, tex in zip(df.mpg_z, df.index, df.mpg_z):
t = plt.text(x, y, round(tex, 2), horizontalalignment='right' if x < 0 else 'left',
verticalalignment='center', fontdict={'color':'red' if x < 0 else 'green', 'size':14})
# Decorations
plt.yticks(df.index, df.cars, fontsize=12)
plt.title('Diverging Text Bars of Car Mileage', fontdict={'size':20})
plt.grid(linestyle='--', alpha=0.5)
plt.xlim(-2.5, 2.5)
plt.show()
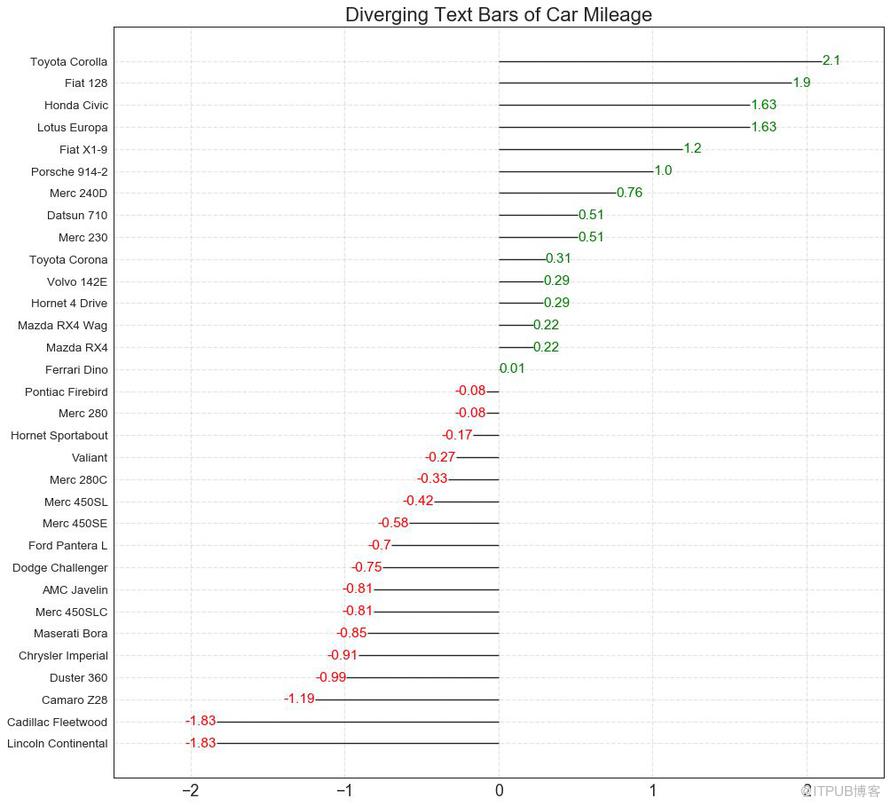
еӣҫ11
12 еҸ‘ж•ЈеһӢеҢ…зӮ№еӣҫ пјҲDiverging Dot Plotпјү
еҸ‘ж•ЈеһӢеҢ…зӮ№еӣҫ пјҲDiverging Dot Plotпјүд№ҹзұ»дјјдәҺеҸ‘ж•ЈеһӢжқЎеҪўеӣҫ пјҲDiverging BarsпјүгҖӮ 然иҖҢпјҢдёҺеҸ‘ж•ЈеһӢжқЎеҪўеӣҫ пјҲDiverging BarsпјүзӣёжҜ”пјҢжқЎзҡ„зјәеӨұеҮҸе°‘дәҶз»„д№Ӣй—ҙзҡ„еҜ№жҜ”еәҰе’Ңе·®ејӮгҖӮ
# Prepare Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")
x = df.loc[:, ['mpg']]
df['mpg_z'] = (x - x.mean())/x.std()
df['colors'] = ['red' if x < 0 else 'darkgreen' for x in df['mpg_z']]
df.sort_values('mpg_z', inplace=True)
df.reset_index(inplace=True)
# Draw plot
plt.figure(figsize=(14,16), dpi= 80)
plt.scatter(df.mpg_z, df.index, s=450, alpha=.6, color=df.colors)
for x, y, tex in zip(df.mpg_z, df.index, df.mpg_z):
t = plt.text(x, y, round(tex, 1), horizontalalignment='center',
verticalalignment='center', fontdict={'color':'white'})
# Decorations
# Lighten borders
plt.gca().spines["top"].set_alpha(.3)
plt.gca().spines["bottom"].set_alpha(.3)
plt.gca().spines["right"].set_alpha(.3)
plt.gca().spines["left"].set_alpha(.3)
plt.yticks(df.index, df.cars)
plt.title('Diverging Dotplot of Car Mileage', fontdict={'size':20})
plt.xlabel('$Mileage$')
plt.grid(linestyle='--', alpha=0.5)
plt.xlim(-2.5, 2.5)
plt.show()
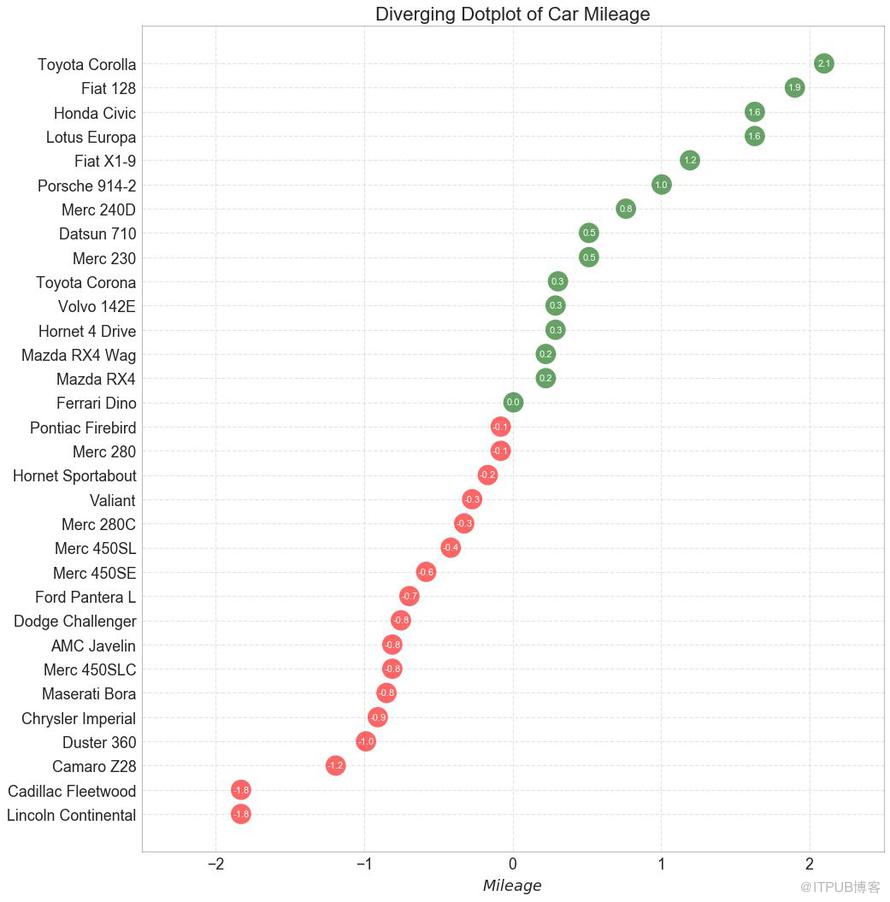
еӣҫ12
13 еёҰж Үи®°зҡ„еҸ‘ж•ЈеһӢжЈ’жЈ’зі–еӣҫ пјҲDiverging Lollipop Chart with Markersпјү
еёҰж Үи®°зҡ„жЈ’жЈ’зі–еӣҫйҖҡиҝҮејәи°ғжӮЁжғіиҰҒеј•иө·жіЁж„Ҹзҡ„д»»дҪ•йҮҚиҰҒж•°жҚ®зӮ№е№¶еңЁеӣҫиЎЁдёӯйҖӮеҪ“ең°з»ҷеҮәжҺЁзҗҶпјҢжҸҗдҫӣдәҶдёҖз§ҚеҜ№е·®ејӮиҝӣиЎҢеҸҜи§ҶеҢ–зҡ„зҒөжҙ»ж–№ејҸгҖӮ
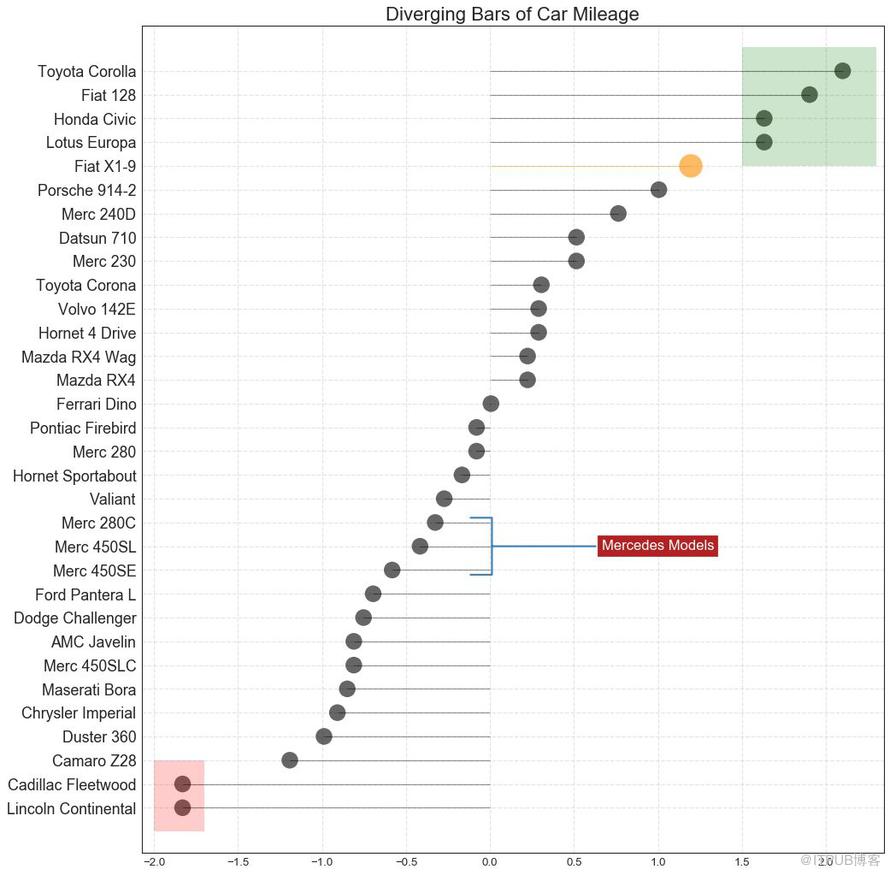
еӣҫ13
14 йқўз§Ҝеӣҫ пјҲArea Chartпјү
йҖҡиҝҮеҜ№иҪҙе’Ңзәҝд№Ӣй—ҙзҡ„еҢәеҹҹиҝӣиЎҢзқҖиүІпјҢйқўз§ҜеӣҫдёҚд»…ејәи°ғеі°е’Ңи°·пјҢиҖҢдё”иҝҳејәи°ғй«ҳзӮ№е’ҢдҪҺзӮ№зҡ„жҢҒз»ӯж—¶й—ҙгҖӮ й«ҳзӮ№жҢҒз»ӯж—¶й—ҙи¶Ҡй•ҝпјҢзәҝдёӢйқўз§Ҝи¶ҠеӨ§гҖӮ
import numpy as np
import pandas as pd
# Prepare Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/economics.csv", parse_dates=['date']).head(100)
x = np.arange(df.shape[0])
y_returns = (df.psavert.diff().fillna(0)/df.psavert.shift(1)).fillna(0) * 100
# Plot
plt.figure(figsize=(16,10), dpi= 80)
plt.fill_between(x[1:], y_returns[1:], 0, where=y_returns[1:] >= 0, facecolor='green', interpolate=True, alpha=0.7)
plt.fill_between(x[1:], y_returns[1:], 0, where=y_returns[1:] <= 0, facecolor='red', interpolate=True, alpha=0.7)
# Annotate
plt.annotate('Peak \n1975', xy=(94.0, 21.0), xytext=(88.0, 28),
bbox=dict(boxstyle='square', fc='firebrick'),
arrowprops=dict(facecolor='steelblue', shrink=0.05), fontsize=15, color='white')
# Decorations
xtickvals = [str(m)[:3].upper()+"-"+str(y) for y,m in zip(df.date.dt.year, df.date.dt.month_name())]
plt.gca().set_xticks(x[::6])
plt.gca().set_xticklabels(xtickvals[::6], rotation=90, fontdict={'horizontalalignment': 'center', 'verticalalignment': 'center_baseline'})
plt.ylim(-35,35)
plt.xlim(1,100)
plt.title("Month Economics Return %", fontsize=22)
plt.ylabel('Monthly returns %')
plt.grid(alpha=0.5)
plt.show()
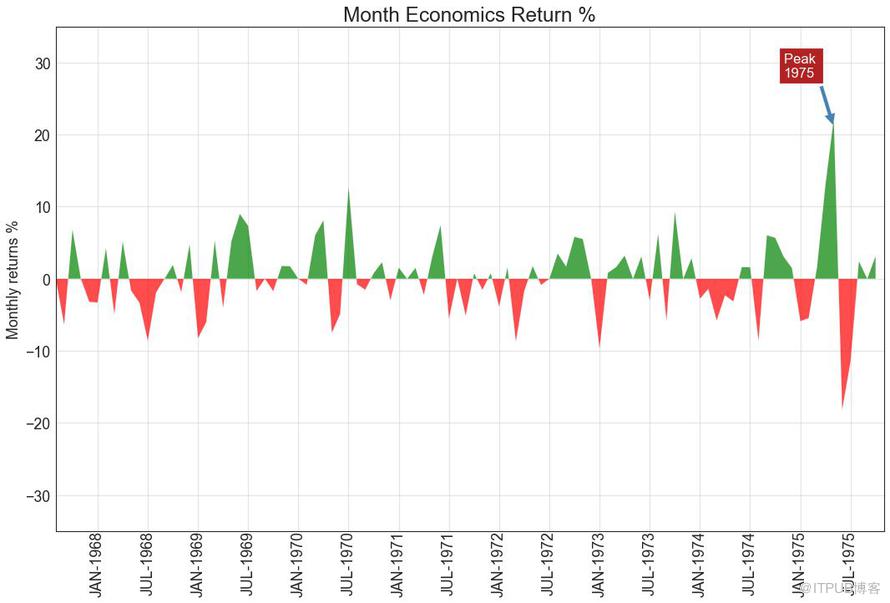
еӣҫ14
дёүгҖҒжҺ’еәҸ пјҲRankingпјү
15 жңүеәҸжқЎеҪўеӣҫ пјҲOrdered Bar Chartпјү
жңүеәҸжқЎеҪўеӣҫжңүж•Ҳең°дј иҫҫдәҶйЎ№зӣ®зҡ„жҺ’еҗҚйЎәеәҸгҖӮ дҪҶжҳҜпјҢеңЁеӣҫиЎЁдёҠж–№ж·»еҠ еәҰйҮҸж ҮеҮҶзҡ„еҖјпјҢз”ЁжҲ·еҸҜд»Ҙд»ҺеӣҫиЎЁжң¬иә«иҺ·еҸ–зІҫзЎ®дҝЎжҒҜгҖӮ
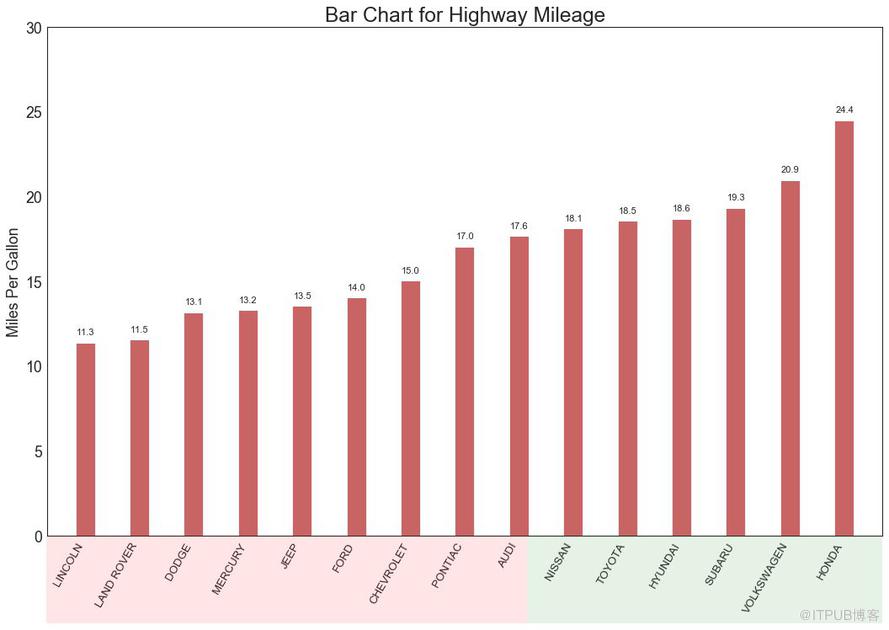
еӣҫ15
16 жЈ’жЈ’зі–еӣҫ пјҲLollipop Chartпјү
жЈ’жЈ’зі–еӣҫиЎЁд»ҘдёҖз§Қи§Ҷи§үдёҠд»Өдәәж„үжӮҰзҡ„ж–№ејҸжҸҗдҫӣдёҺжңүеәҸжқЎеҪўеӣҫзұ»дјјзҡ„зӣ®зҡ„гҖӮ
# Prepare Data
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
df = df_raw[['cty', 'manufacturer']].groupby('manufacturer').apply(lambda x: x.mean())
df.sort_values('cty', inplace=True)
df.reset_index(inplace=True)
# Draw plot
fig, ax = plt.subplots(figsize=(16,10), dpi= 80)
ax.vlines(x=df.index, ymin=0, ymax=df.cty, color='firebrick', alpha=0.7, linewidth=2)
ax.scatter(x=df.index, y=df.cty, s=75, color='firebrick', alpha=0.7)
# Title, Label, Ticks and Ylim
ax.set_title('Lollipop Chart for Highway Mileage', fontdict={'size':22})
ax.set_ylabel('Miles Per Gallon')
ax.set_xticks(df.index)
ax.set_xticklabels(df.manufacturer.str.upper(), rotation=60, fontdict={'horizontalalignment': 'right', 'size':12})
ax.set_ylim(0, 30)
# Annotate
for row in df.itertuples():
ax.text(row.Index, row.cty+.5, s=round(row.cty, 2), horizontalalignment= 'center', verticalalignment='bottom', fontsize=14)
plt.show()
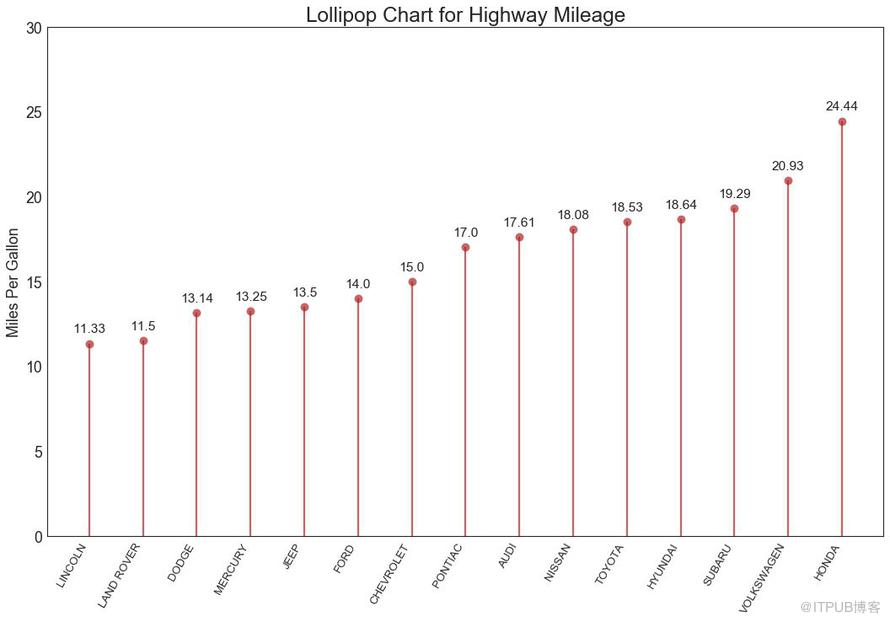
еӣҫ16
17 еҢ…зӮ№еӣҫ пјҲDot Plotпјү
еҢ…зӮ№еӣҫиЎЁдј иҫҫдәҶйЎ№зӣ®зҡ„жҺ’еҗҚйЎәеәҸпјҢ并且з”ұдәҺе®ғжІҝж°ҙе№іиҪҙеҜ№йҪҗпјҢеӣ жӯӨжӮЁеҸҜд»Ҙжӣҙе®№жҳ“ең°зңӢеҲ°зӮ№еҪјжӯӨд№Ӣй—ҙзҡ„и·қзҰ»гҖӮ
# Prepare Data
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
df = df_raw[['cty', 'manufacturer']].groupby('manufacturer').apply(lambda x: x.mean())
df.sort_values('cty', inplace=True)
df.reset_index(inplace=True)
# Draw plot
fig, ax = plt.subplots(figsize=(16,10), dpi= 80)
ax.hlines(y=df.index, xmin=11, xmax=26, color='gray', alpha=0.7, linewidth=1, linestyles='dashdot')
ax.scatter(y=df.index, x=df.cty, s=75, color='firebrick', alpha=0.7)
# Title, Label, Ticks and Ylim
ax.set_title('Dot Plot for Highway Mileage', fontdict={'size':22})
ax.set_xlabel('Miles Per Gallon')
ax.set_yticks(df.index)
ax.set_yticklabels(df.manufacturer.str.title(), fontdict={'horizontalalignment': 'right'})
ax.set_xlim(10, 27)
plt.show()
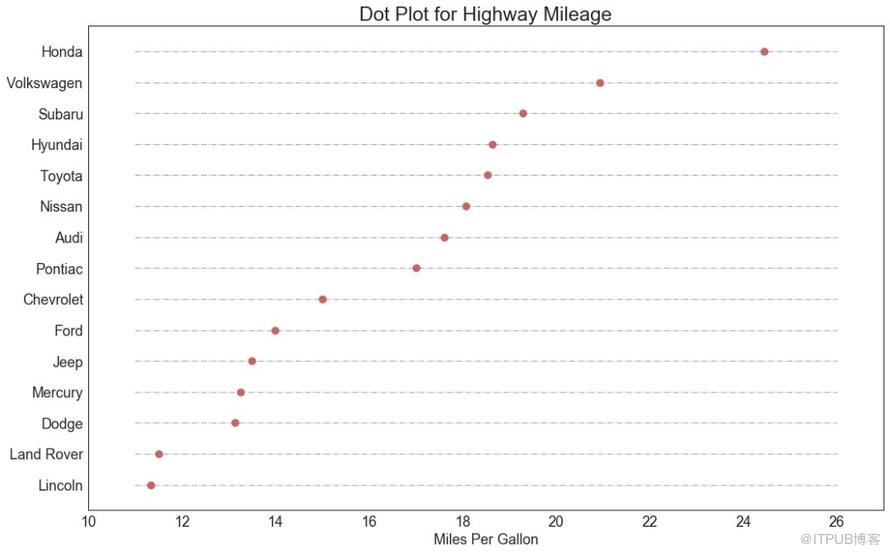
еӣҫ17
18 еқЎеәҰеӣҫ пјҲSlope Chartпјү
еқЎеәҰеӣҫжңҖйҖӮеҗҲжҜ”иҫғз»ҷе®ҡдәә/йЎ№зӣ®зҡ„вҖңеүҚвҖқе’ҢвҖңеҗҺвҖқдҪҚзҪ®гҖӮ
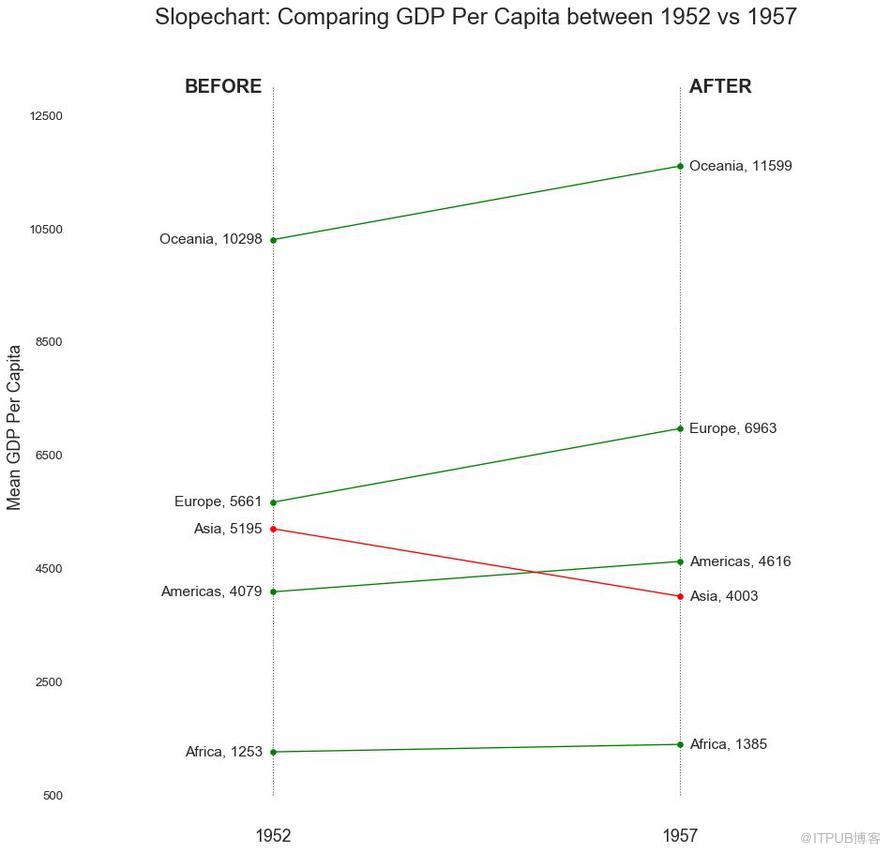
еӣҫ18
19 е“‘й“ғеӣҫ пјҲDumbbell Plotпјү
е“‘й“ғеӣҫиЎЁдј иҫҫдәҶеҗ„з§ҚйЎ№зӣ®зҡ„вҖңеүҚвҖқе’ҢвҖңеҗҺвҖқдҪҚзҪ®д»ҘеҸҠйЎ№зӣ®зҡ„зӯүзә§жҺ’еәҸгҖӮ еҰӮжһңжӮЁжғіиҰҒе°Ҷзү№е®ҡйЎ№зӣ®/и®ЎеҲ’еҜ№дёҚеҗҢеҜ№иұЎзҡ„еҪұе“ҚеҸҜи§ҶеҢ–пјҢйӮЈд№Ҳе®ғйқһеёёжңүз”ЁгҖӮ
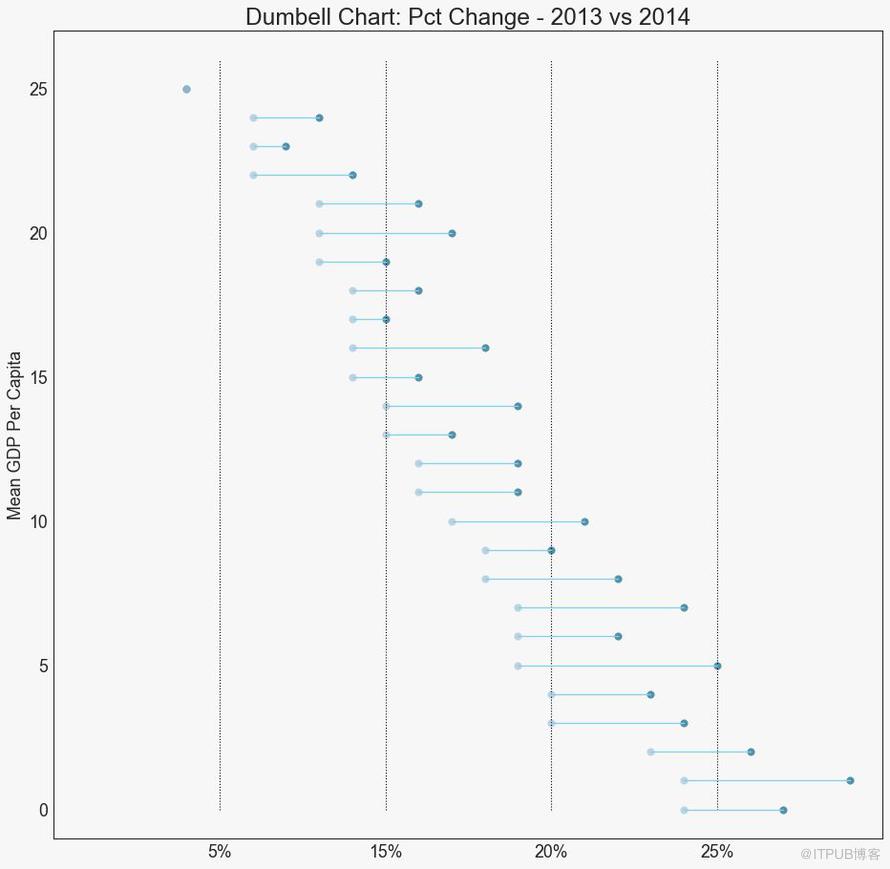
еӣҫ19
еӣӣгҖҒеҲҶеёғ пјҲDistributionпјү
20 иҝһз»ӯеҸҳйҮҸзҡ„зӣҙж–№еӣҫ пјҲHistogram for Continuous Variableпјү
зӣҙж–№еӣҫжҳҫзӨәз»ҷе®ҡеҸҳйҮҸзҡ„йў‘зҺҮеҲҶеёғгҖӮ дёӢйқўзҡ„еӣҫиЎЁзӨәеҹәдәҺзұ»еһӢеҸҳйҮҸеҜ№йў‘зҺҮжқЎиҝӣиЎҢеҲҶз»„пјҢд»ҺиҖҢжӣҙеҘҪең°дәҶи§Јиҝһз»ӯеҸҳйҮҸе’Ңзұ»еһӢеҸҳйҮҸгҖӮ
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare data
x_var = 'displ'
groupby_var = 'class'
df_agg = df.loc[:, [x_var, groupby_var]].groupby(groupby_var)
vals = [df[x_var].values.tolist() for i, df in df_agg]
# Draw
plt.figure(figsize=(16,9), dpi= 80)
colors = [plt.cm.Spectral(i/float(len(vals)-1)) for i in range(len(vals))]
n, bins, patches = plt.hist(vals, 30, stacked=True, density=False, color=colors[:len(vals)])
# Decoration
plt.legend({group:col for group, col in zip(np.unique(df[groupby_var]).tolist(), colors[:len(vals)])})
plt.title(f"Stacked Histogram of ${x_var}$ colored by ${groupby_var}$", fontsize=22)
plt.xlabel(x_var)
plt.ylabel("Frequency")
plt.ylim(0, 25)
plt.xticks(ticks=bins[::3], labels=[round(b,1) for b in bins[::3]])
plt.show()

еӣҫ20
21 зұ»еһӢеҸҳйҮҸзҡ„зӣҙж–№еӣҫ пјҲHistogram for Categorical Variableпјү
зұ»еһӢеҸҳйҮҸзҡ„зӣҙж–№еӣҫжҳҫзӨәиҜҘеҸҳйҮҸзҡ„йў‘зҺҮеҲҶеёғгҖӮ йҖҡиҝҮеҜ№жқЎеҪўеӣҫиҝӣиЎҢзқҖиүІпјҢеҸҜд»Ҙе°ҶеҲҶеёғдёҺиЎЁзӨәйўңиүІзҡ„еҸҰдёҖдёӘзұ»еһӢеҸҳйҮҸзӣёе…іиҒ”гҖӮ
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare data
x_var = 'manufacturer'
groupby_var = 'class'
df_agg = df.loc[:, [x_var, groupby_var]].groupby(groupby_var)
vals = [df[x_var].values.tolist() for i, df in df_agg]
# Draw
plt.figure(figsize=(16,9), dpi= 80)
colors = [plt.cm.Spectral(i/float(len(vals)-1)) for i in range(len(vals))]
n, bins, patches = plt.hist(vals, df[x_var].unique().__len__(), stacked=True, density=False, color=colors[:len(vals)])
# Decoration
plt.legend({group:col for group, col in zip(np.unique(df[groupby_var]).tolist(), colors[:len(vals)])})
plt.title(f"Stacked Histogram of ${x_var}$ colored by ${groupby_var}$", fontsize=22)
plt.xlabel(x_var)
plt.ylabel("Frequency")
plt.ylim(0, 40)
plt.xticks(ticks=bins, labels=np.unique(df[x_var]).tolist(), rotation=90, horizontalalignment='left')
plt.show()
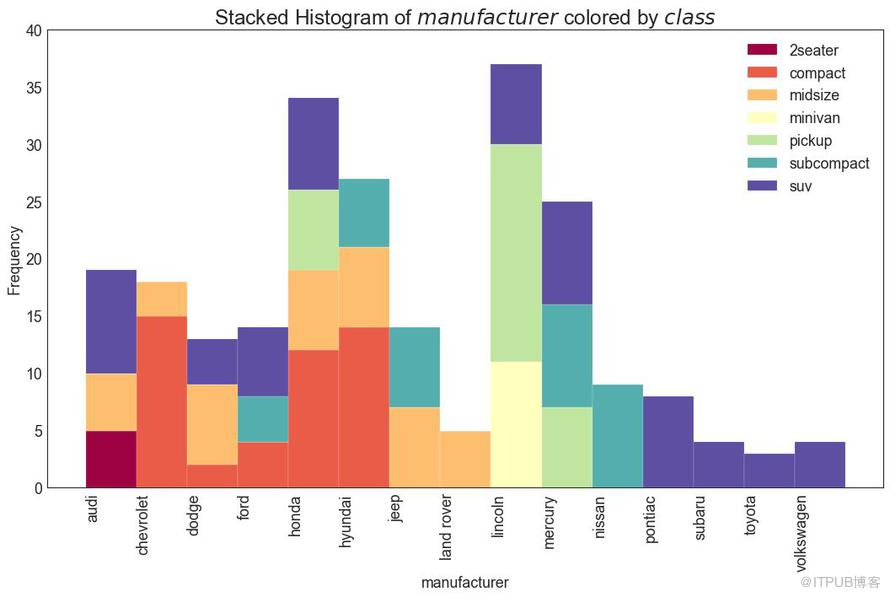
еӣҫ21
22 еҜҶеәҰеӣҫ пјҲDensity Plotпјү
еҜҶеәҰеӣҫжҳҜдёҖз§Қеёёз”Ёе·Ҙе…·пјҢз”ЁдәҺеҸҜи§ҶеҢ–иҝһз»ӯеҸҳйҮҸзҡ„еҲҶеёғгҖӮ йҖҡиҝҮвҖңе“Қеә”вҖқеҸҳйҮҸеҜ№е®ғ们иҝӣиЎҢеҲҶз»„пјҢжӮЁеҸҜд»ҘжЈҖжҹҘ X е’Ң Y д№Ӣй—ҙзҡ„е…ізі»гҖӮд»ҘдёӢжғ…еҶөз”ЁдәҺиЎЁзӨәзӣ®зҡ„пјҢд»ҘжҸҸиҝ°еҹҺеёӮйҮҢзЁӢзҡ„еҲҶеёғеҰӮдҪ•йҡҸзқҖжұҪзјёж•°зҡ„еҸҳеҢ–иҖҢеҸҳеҢ–гҖӮ
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Draw Plot
plt.figure(figsize=(16,10), dpi= 80)
sns.kdeplot(df.loc[df['cyl'] == 4, "cty"], shade=True, color="g", label="Cyl=4", alpha=.7)
sns.kdeplot(df.loc[df['cyl'] == 5, "cty"], shade=True, color="deeppink", label="Cyl=5", alpha=.7)
sns.kdeplot(df.loc[df['cyl'] == 6, "cty"], shade=True, color="dodgerblue", label="Cyl=6", alpha=.7)
sns.kdeplot(df.loc[df['cyl'] == 8, "cty"], shade=True, color="orange", label="Cyl=8", alpha=.7)
# Decoration
plt.title('Density Plot of City Mileage by n_Cylinders', fontsize=22)
plt.legend()
plt.show()
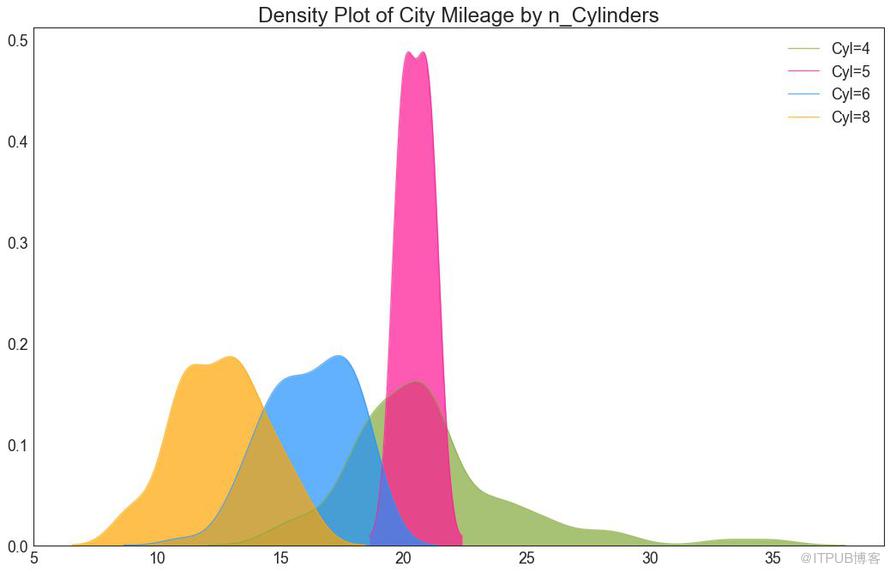
еӣҫ22
23 зӣҙж–№еҜҶеәҰзәҝеӣҫ пјҲDensity Curves with Histogramпјү
еёҰжңүзӣҙж–№еӣҫзҡ„еҜҶеәҰжӣІзәҝжұҮйӣҶдәҶдёӨдёӘеӣҫжүҖдј иҫҫзҡ„йӣҶдҪ“дҝЎжҒҜпјҢеӣ жӯӨжӮЁеҸҜд»Ҙе°Ҷе®ғ们ж”ҫеңЁдёҖдёӘеӣҫдёӯиҖҢдёҚжҳҜдёӨдёӘеӣҫдёӯгҖӮ
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Draw Plot
plt.figure(figsize=(13,10), dpi= 80)
sns.distplot(df.loc[df['class'] == 'compact', "cty"], color="dodgerblue", label="Compact", hist_kws={'alpha':.7}, kde_kws={'linewidth':3})
sns.distplot(df.loc[df['class'] == 'suv', "cty"], color="orange", label="SUV", hist_kws={'alpha':.7}, kde_kws={'linewidth':3})
sns.distplot(df.loc[df['class'] == 'minivan', "cty"], color="g", label="minivan", hist_kws={'alpha':.7}, kde_kws={'linewidth':3})
plt.ylim(0, 0.35)
# Decoration
plt.title('Density Plot of City Mileage by Vehicle Type', fontsize=22)
plt.legend()
plt.show()
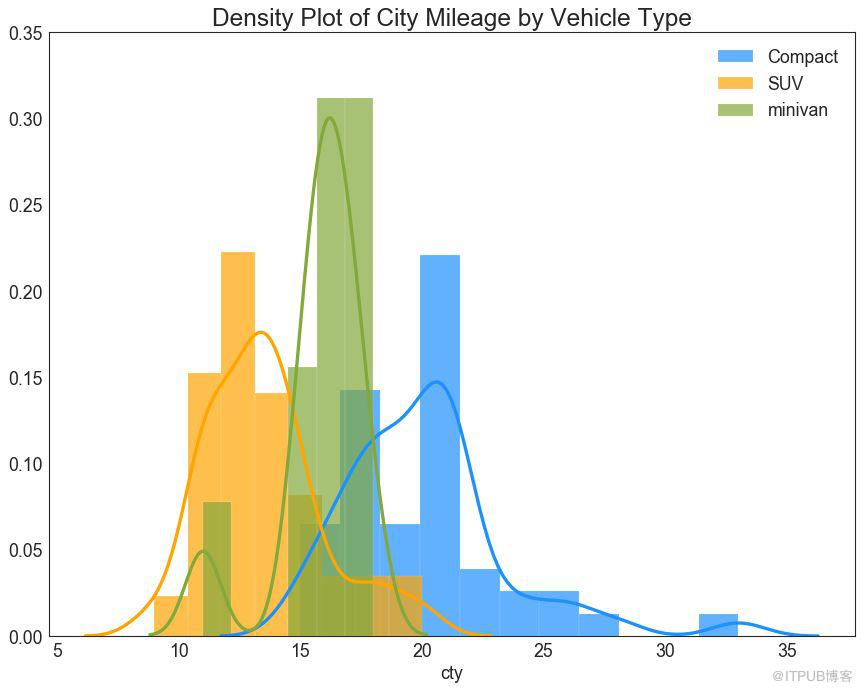
еӣҫ23
24 Joy Plot
Joy Plotе…Ғи®ёдёҚеҗҢз»„зҡ„еҜҶеәҰжӣІзәҝйҮҚеҸ пјҢиҝҷжҳҜдёҖз§ҚеҸҜи§ҶеҢ–еӨ§йҮҸеҲҶз»„ж•°жҚ®зҡ„еҪјжӯӨе…ізі»еҲҶеёғзҡ„еҘҪж–№жі•гҖӮ е®ғзңӢиө·жқҘеҫҲжӮҰзӣ®пјҢ并清жҘҡең°дј иҫҫдәҶжӯЈзЎ®зҡ„дҝЎжҒҜгҖӮ е®ғеҸҜд»ҘдҪҝз”ЁеҹәдәҺ matplotlib зҡ„ joypy еҢ…иҪ»жқҫжһ„е»әгҖӮ пјҲгҖҺPythonж•°жҚ®д№ӢйҒ“гҖҸжіЁпјҡйңҖиҰҒе®үиЈ… joypy еә“пјү
# !pip install joypy
# Pythonж•°жҚ®д№ӢйҒ“ еӨҮжіЁ
import joypy
# Import Data
mpg = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Draw Plot
plt.figure(figsize=(16,10), dpi= 80)
fig, axes = joypy.joyplot(mpg, column=['hwy', 'cty'], by="class", ylim='own', figsize=(14,10))
# Decoration
plt.title('Joy Plot of City and Highway Mileage by Class', fontsize=22)
plt.show()
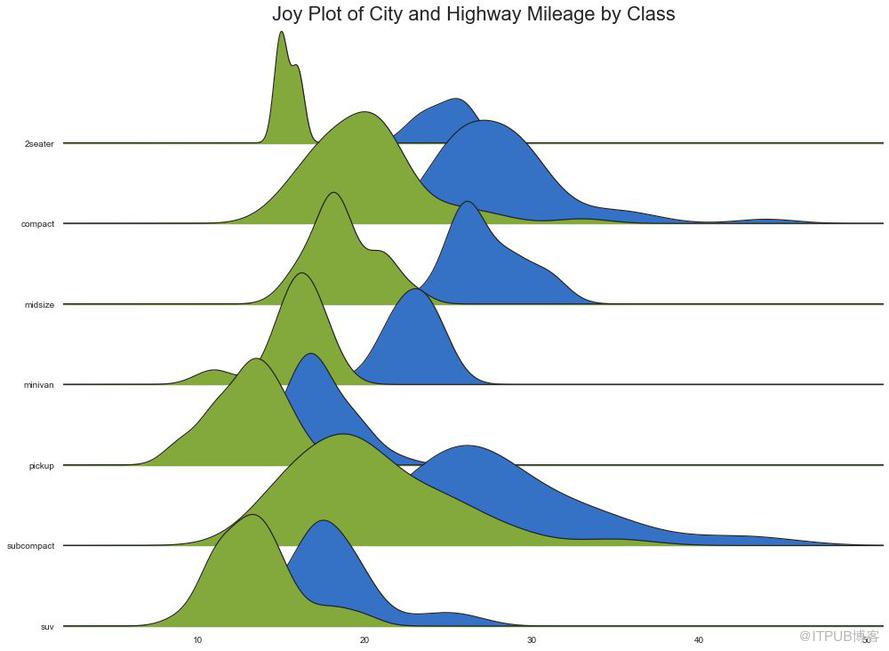
еӣҫ24
25 еҲҶеёғејҸеҢ…зӮ№еӣҫ пјҲDistributed Dot Plotпјү
еҲҶеёғејҸеҢ…зӮ№еӣҫжҳҫзӨәжҢүз»„еҲҶеүІзҡ„зӮ№зҡ„еҚ•еҸҳйҮҸеҲҶеёғгҖӮ зӮ№ж•°и¶Ҡжҡ—пјҢиҜҘеҢәеҹҹзҡ„ж•°жҚ®зӮ№йӣҶдёӯеәҰи¶Ҡй«ҳгҖӮ йҖҡиҝҮеҜ№дёӯдҪҚж•°иҝӣиЎҢдёҚеҗҢзқҖиүІпјҢз»„зҡ„зңҹе®һе®ҡдҪҚз«ӢеҚіеҸҳеҫ—жҳҺжҳҫгҖӮ
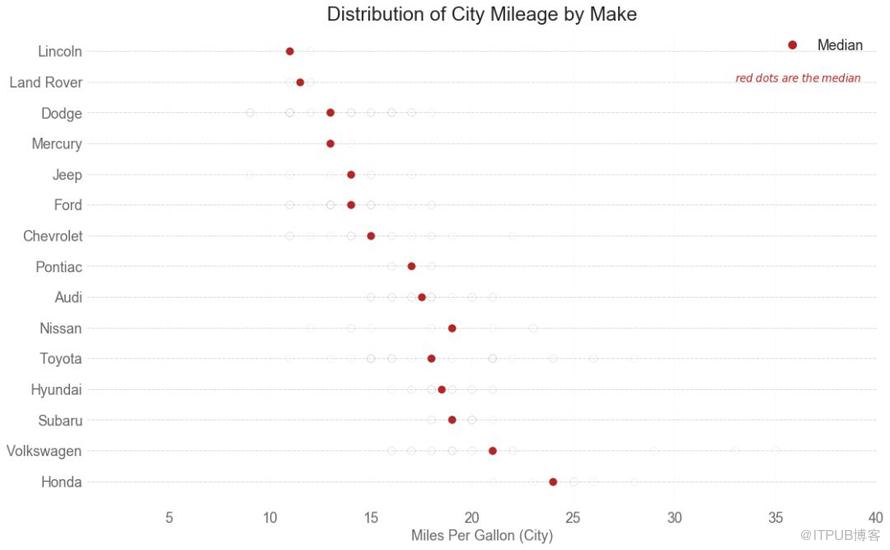
еӣҫ25
26 з®ұеҪўеӣҫ пјҲBox Plotпјү
з®ұеҪўеӣҫжҳҜдёҖз§ҚеҸҜи§ҶеҢ–еҲҶеёғзҡ„еҘҪж–№жі•пјҢи®°дҪҸдёӯдҪҚж•°гҖҒ第25дёӘ第45дёӘеӣӣеҲҶдҪҚж•°е’ҢејӮеёёеҖјгҖӮ дҪҶжҳҜпјҢжӮЁйңҖиҰҒжіЁж„Ҹи§ЈйҮҠеҸҜиғҪдјҡжүӯжӣІиҜҘз»„дёӯеҢ…еҗ«зҡ„зӮ№ж•°зҡ„жЎҶзҡ„еӨ§е°ҸгҖӮ еӣ жӯӨпјҢжүӢеҠЁжҸҗдҫӣжҜҸдёӘжЎҶдёӯзҡ„и§ӮеҜҹж•°йҮҸеҸҜд»Ҙеё®еҠ©е…ӢжңҚиҝҷдёӘзјәзӮ№гҖӮ
дҫӢеҰӮпјҢе·Ұиҫ№зҡ„еүҚдёӨдёӘжЎҶе…·жңүзӣёеҗҢеӨ§е°Ҹзҡ„жЎҶпјҢеҚідҪҝе®ғ们зҡ„еҖјеҲҶеҲ«жҳҜ5е’Ң47гҖӮ еӣ жӯӨпјҢеҶҷе…ҘиҜҘз»„дёӯзҡ„и§ӮеҜҹж•°йҮҸжҳҜеҝ…иҰҒзҡ„гҖӮ
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Draw Plot
plt.figure(figsize=(13,10), dpi= 80)
sns.boxplot(x='class', y='hwy', data=df, notch=False)
# Add N Obs inside boxplot (optional)
def add_n_obs(df,group_col,y):
medians_dict = {grp[0]:grp[1][y].median() for grp in df.groupby(group_col)}
xticklabels = [x.get_text() for x in plt.gca().get_xticklabels()]
n_obs = df.groupby(group_col)[y].size().values
for (x, xticklabel), n_ob in zip(enumerate(xticklabels), n_obs):
plt.text(x, medians_dict[xticklabel]*1.01, "#obs : "+str(n_ob), horizontalalignment='center', fontdict={'size':14}, color='white')
add_n_obs(df,group_col='class',y='hwy')
# Decoration
plt.title('Box Plot of Highway Mileage by Vehicle Class', fontsize=22)
plt.ylim(10, 40)
plt.show()
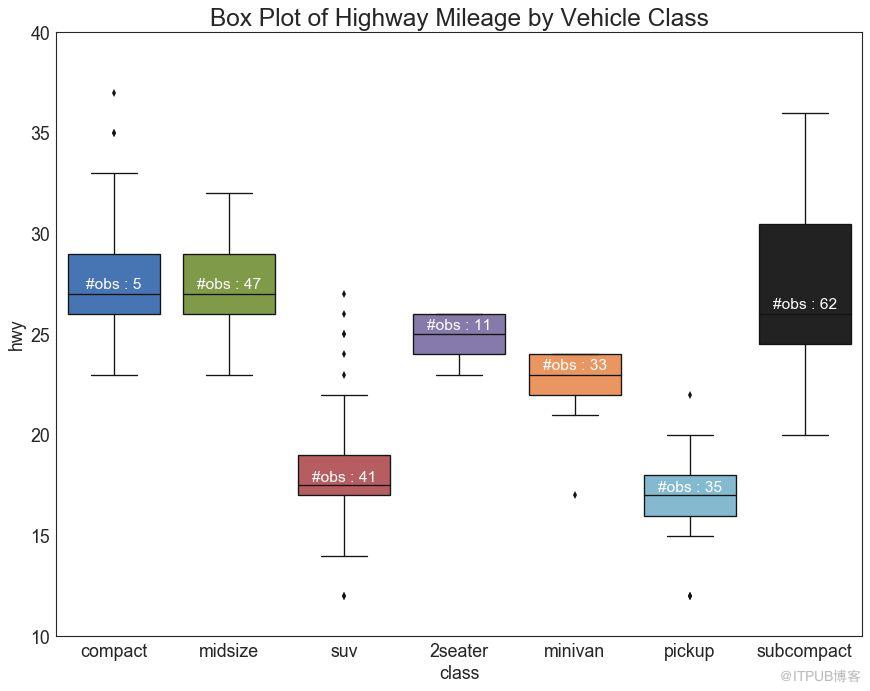
еӣҫ26
27 еҢ…зӮ№+з®ұеҪўеӣҫ пјҲDot + Box Plotпјү
еҢ…зӮ№+з®ұеҪўеӣҫ пјҲDot + Box Plotпјүдј иҫҫзұ»дјјдәҺеҲҶз»„зҡ„з®ұеҪўеӣҫдҝЎжҒҜгҖӮ жӯӨеӨ–пјҢиҝҷдәӣзӮ№еҸҜд»ҘдәҶи§ЈжҜҸз»„дёӯжңүеӨҡе°‘ж•°жҚ®зӮ№гҖӮ
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Draw Plot
plt.figure(figsize=(13,10), dpi= 80)
sns.boxplot(x='class', y='hwy', data=df, hue='cyl')
sns.stripplot(x='class', y='hwy', data=df, color='black', size=3, jitter=1)
for i in range(len(df['class'].unique())-1):
plt.vlines(i+.5, 10, 45, linestyles='solid', colors='gray', alpha=0.2)
# Decoration
plt.title('Box Plot of Highway Mileage by Vehicle Class', fontsize=22)
plt.legend(title='Cylinders')
plt.show()
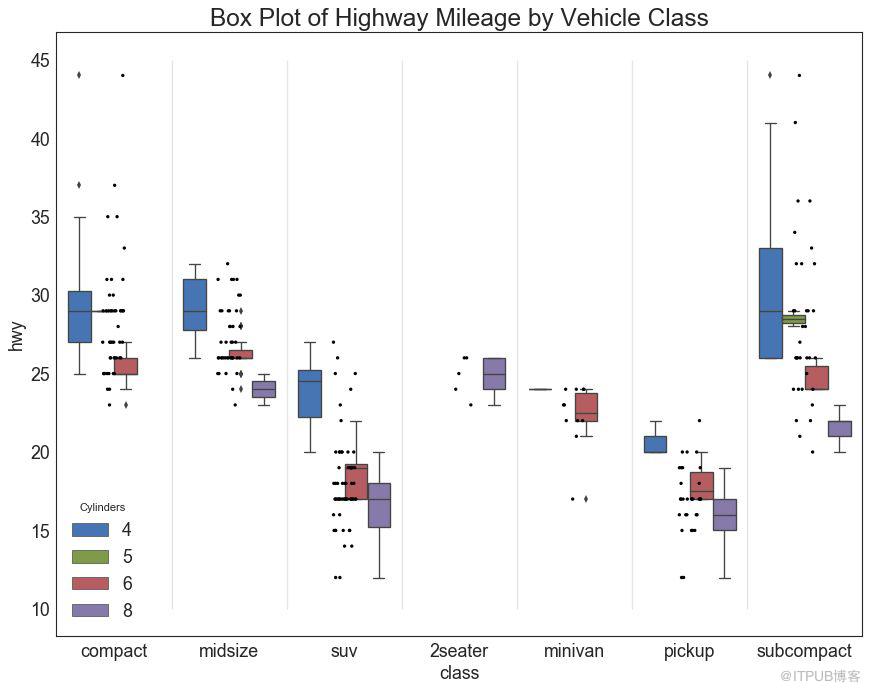
еӣҫ27
28 е°ҸжҸҗзҗҙеӣҫ пјҲViolin Plotпјү
е°ҸжҸҗзҗҙеӣҫжҳҜз®ұеҪўеӣҫеңЁи§Ҷи§үдёҠд»Өдәәж„үжӮҰзҡ„жӣҝд»Је“ҒгҖӮ е°ҸжҸҗзҗҙзҡ„еҪўзҠ¶жҲ–йқўз§ҜеҸ–еҶідәҺе®ғжүҖжҢҒжңүзҡ„и§ӮеҜҹж¬Ўж•°гҖӮ дҪҶжҳҜпјҢе°ҸжҸҗзҗҙеӣҫеҸҜиғҪжӣҙйҡҫд»Ҙйҳ…иҜ»пјҢ并且еңЁдё“дёҡи®ҫзҪ®дёӯдёҚеёёз”ЁгҖӮ
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Draw Plot
plt.figure(figsize=(13,10), dpi= 80)
sns.violinplot(x='class', y='hwy', data=df, scale='width', inner='quartile')
# Decoration
plt.title('Violin Plot of Highway Mileage by Vehicle Class', fontsize=22)
plt.show()
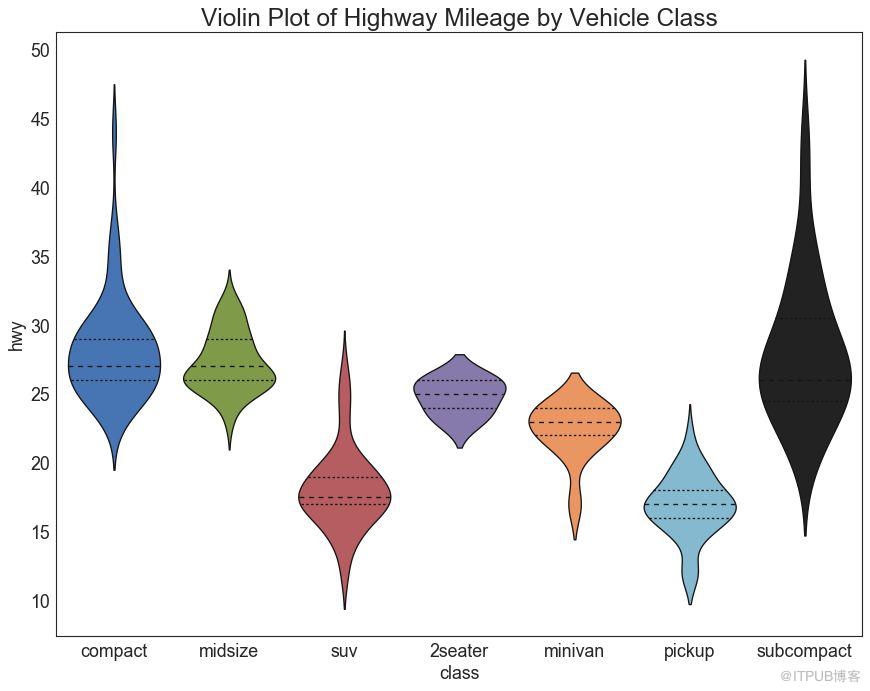
еӣҫ28
29 дәәеҸЈйҮ‘еӯ—еЎ” пјҲPopulation Pyramidпјү
дәәеҸЈйҮ‘еӯ—еЎ”еҸҜз”ЁдәҺжҳҫзӨәз”ұж•°йҮҸжҺ’еәҸзҡ„з»„зҡ„еҲҶеёғгҖӮ жҲ–иҖ…е®ғд№ҹеҸҜд»Ҙз”ЁдәҺжҳҫзӨәдәәеҸЈзҡ„йҖҗзә§иҝҮж»ӨпјҢеӣ дёәе®ғеңЁдёӢйқўз”ЁдәҺжҳҫзӨәжңүеӨҡе°‘дәәйҖҡиҝҮиҗҘй”Җжё йҒ“зҡ„жҜҸдёӘйҳ¶ж®өгҖӮ
# Read data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/email_campaign_funnel.csv")
# Draw Plot
plt.figure(figsize=(13,10), dpi= 80)
group_col = 'Gender'
order_of_bars = df.Stage.unique()[::-1]
colors = [plt.cm.Spectral(i/float(len(df[group_col].unique())-1)) for i in range(len(df[group_col].unique()))]
for c, group in zip(colors, df[group_col].unique()):
sns.barplot(x='Users', y='Stage', data=df.loc[df[group_col]==group, :], order=order_of_bars, color=c, label=group)
# Decorations
plt.xlabel("$Users$")
plt.ylabel("Stage of Purchase")
plt.yticks(fontsize=12)
plt.title("Population Pyramid of the Marketing Funnel", fontsize=22)
plt.legend()
plt.show()
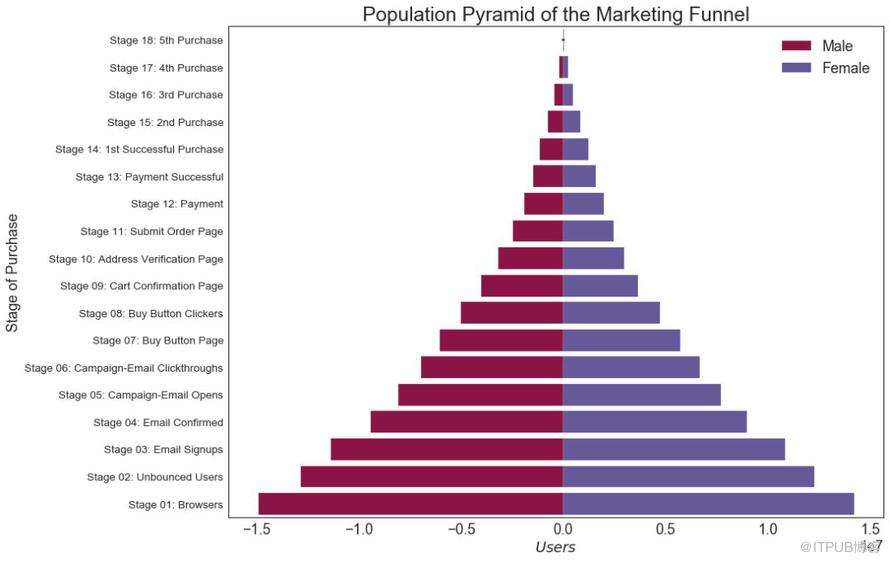
еӣҫ29
30 еҲҶзұ»еӣҫ пјҲCategorical Plotsпјү
з”ұ seabornеә“ жҸҗдҫӣзҡ„еҲҶзұ»еӣҫеҸҜз”ЁдәҺеҸҜи§ҶеҢ–еҪјжӯӨзӣёе…ізҡ„2дёӘжҲ–жӣҙеӨҡеҲҶзұ»еҸҳйҮҸзҡ„и®Ўж•°еҲҶеёғгҖӮ
# Load Dataset
titanic = sns.load_dataset("titanic")
# Plot
g = sns.catplot("alive", col="deck", col_wrap=4,
data=titanic[titanic.deck.notnull()],
kind="count", height=3.5, aspect=.8,
palette='tab20')
fig.suptitle('sf')
plt.show()
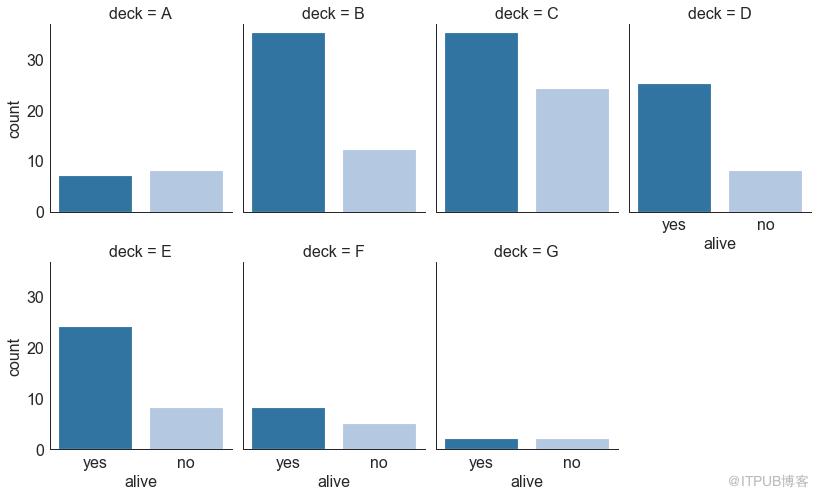
еӣҫ30
# Load Dataset
titanic = sns.load_dataset("titanic")
# Plot
sns.catplot(x="age", y="embark_town",
hue="sex", col="class",
data=titanic[titanic.embark_town.notnull()],
orient="h", height=5, aspect=1, palette="tab10",
kind="violin", dodge=True, cut=0, bw=.2)
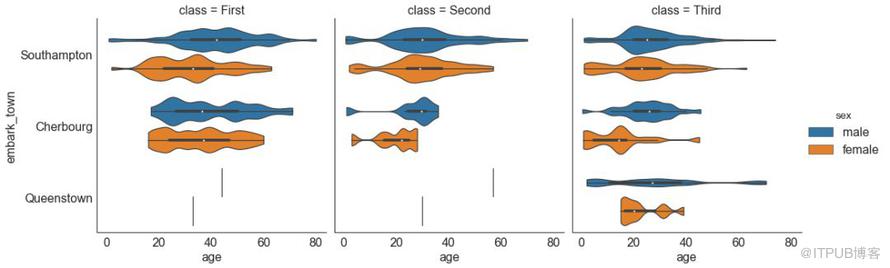
еӣҫ30-2
дә”гҖҒз»„жҲҗ пјҲCompositionпјү
31 еҚҺеӨ«йҘјеӣҫ пјҲWaffle Chartпјү
еҸҜд»ҘдҪҝз”Ё pywaffleеҢ… еҲӣе»әеҚҺеӨ«йҘјеӣҫпјҢ并用дәҺжҳҫзӨәжӣҙеӨ§зҫӨдҪ“дёӯзҡ„з»„зҡ„з»„жҲҗгҖӮ
пјҲгҖҺPythonж•°жҚ®д№ӢйҒ“гҖҸжіЁпјҡйңҖиҰҒе®үиЈ… pywaffle еә“пјү
#! pip install pywaffle
# Reference: https://stackoverflow.com/questions/41400136/how-to-do-waffle-charts-in-python-square-piechart
from pywaffle import Waffle
# Import
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare Data
df = df_raw.groupby('class').size().reset_index(name='counts')
n_categories = df.shape[0]
colors = [plt.cm.inferno_r(i/float(n_categories)) for i in range(n_categories)]
# Draw Plot and Decorate
fig = plt.figure(
FigureClass=Waffle,
plots={
'111': {
'values': df['counts'],
'labels': ["{0} ({1})".format(n[0], n[1]) for n in df[['class', 'counts']].itertuples()],
'legend': {'loc': 'upper left', 'bbox_to_anchor': (1.05, 1), 'fontsize': 12},
'title': {'label': '# Vehicles by Class', 'loc': 'center', 'fontsize':18}
},
},
rows=7,
colors=colors,
figsize=(16, 9)
)
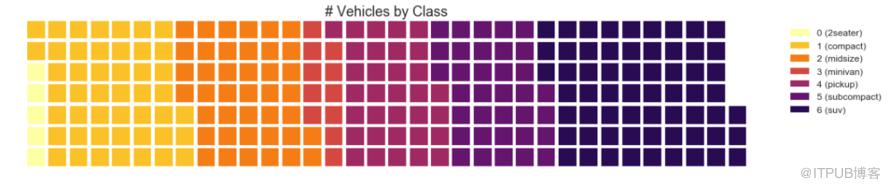
еӣҫ31
еӣҫ31-2
32 йҘјеӣҫ пјҲPie Chartпјү
йҘјеӣҫжҳҜжҳҫзӨәз»„жҲҗзҡ„з»Ҹе…ёж–№ејҸгҖӮ 然иҖҢпјҢзҺ°еңЁйҖҡеёёдёҚе»әи®®дҪҝз”Ёе®ғпјҢеӣ дёәйҰ…йҘјйғЁеҲҶзҡ„йқўз§Ҝжңүж—¶дјҡеҸҳеҫ—иҜҜеҜјгҖӮ еӣ жӯӨпјҢеҰӮжһңжӮЁиҰҒдҪҝз”ЁйҘјеӣҫпјҢејәзғҲе»әи®®жҳҺзЎ®и®°дёӢйҘјеӣҫжҜҸдёӘйғЁеҲҶзҡ„зҷҫеҲҶжҜ”жҲ–ж•°еӯ—гҖӮ
# Import
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare Data
df = df_raw.groupby('class').size()
# Make the plot with pandas
df.plot(kind='pie', subplots=True, figsize=(8, 8))
plt.title("Pie Chart of Vehicle Class - Bad")
plt.ylabel("")
plt.show()
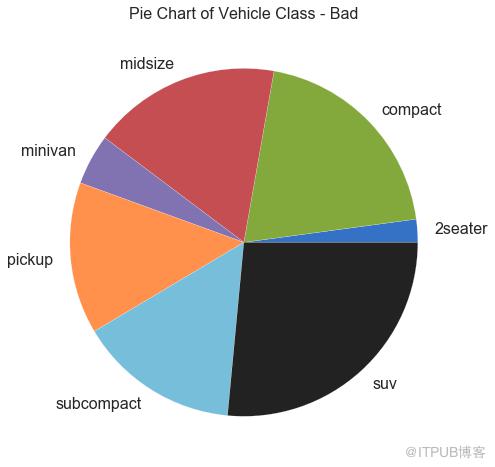
еӣҫ32
еӣҫ32-2
33 ж ‘еҪўеӣҫ пјҲTreemapпјү
ж ‘еҪўеӣҫзұ»дјјдәҺйҘјеӣҫпјҢе®ғеҸҜд»ҘжӣҙеҘҪең°е®ҢжҲҗе·ҘдҪңиҖҢдёҚдјҡиҜҜеҜјжҜҸдёӘз»„зҡ„иҙЎзҢ®гҖӮ
пјҲгҖҺPythonж•°жҚ®д№ӢйҒ“гҖҸжіЁпјҡйңҖиҰҒе®үиЈ… squarify еә“пјү
# pip install squarify
import squarify
# Import Data
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare Data
df = df_raw.groupby('class').size().reset_index(name='counts')
labels = df.apply(lambda x: str(x[0]) + "\n (" + str(x[1]) + ")", axis=1)
sizes = df['counts'].values.tolist()
colors = [plt.cm.Spectral(i/float(len(labels))) for i in range(len(labels))]
# Draw Plot
plt.figure(figsize=(12,8), dpi= 80)
squarify.plot(sizes=sizes, label=labels, color=colors, alpha=.8)
# Decorate
plt.title('Treemap of Vechile Class')
plt.axis('off')
plt.show()
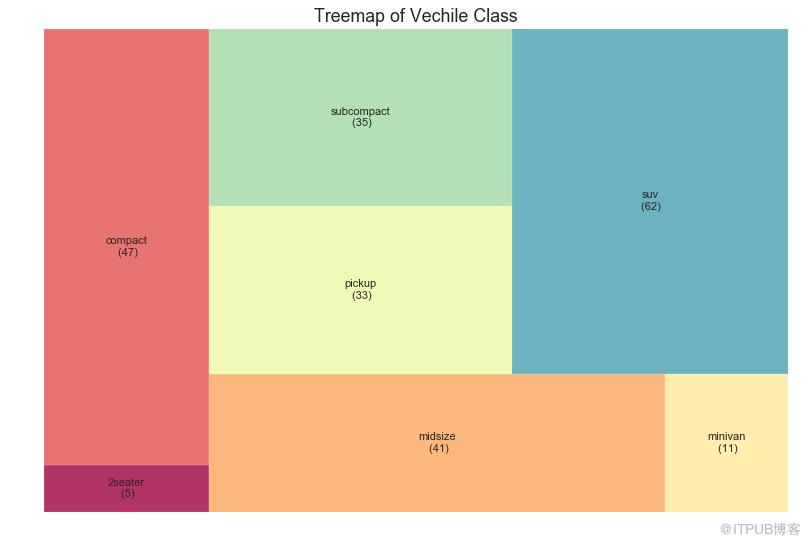
еӣҫ33
34 жқЎеҪўеӣҫ пјҲBar Chartпјү
жқЎеҪўеӣҫжҳҜеҹәдәҺи®Ўж•°жҲ–д»»дҪ•з»ҷе®ҡжҢҮж ҮеҸҜи§ҶеҢ–йЎ№зӣ®зҡ„з»Ҹе…ёж–№ејҸгҖӮ еңЁдёӢйқўзҡ„еӣҫиЎЁдёӯпјҢжҲ‘дёәжҜҸдёӘйЎ№зӣ®дҪҝз”ЁдәҶдёҚеҗҢзҡ„йўңиүІпјҢдҪҶжӮЁйҖҡеёёеҸҜиғҪеёҢжңӣдёәжүҖжңүйЎ№зӣ®йҖүжӢ©дёҖз§ҚйўңиүІпјҢйҷӨйқһжӮЁжҢүз»„еҜ№е…¶иҝӣиЎҢзқҖиүІгҖӮ йўңиүІеҗҚз§°еӯҳеӮЁеңЁдёӢйқўд»Јз Ғдёӯзҡ„all_colorsдёӯгҖӮ жӮЁеҸҜд»ҘйҖҡиҝҮеңЁ plt.plotпјҲпјүдёӯи®ҫзҪ®йўңиүІеҸӮж•°жқҘжӣҙж”№жқЎзҡ„йўңиүІгҖӮ
import random
# Import Data
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare Data
df = df_raw.groupby('manufacturer').size().reset_index(name='counts')
n = df['manufacturer'].unique().__len__()+1
all_colors = list(plt.cm.colors.cnames.keys())
random.seed(100)
c = random.choices(all_colors, k=n)
# Plot Bars
plt.figure(figsize=(16,10), dpi= 80)
plt.bar(df['manufacturer'], df['counts'], color=c, width=.5)
for i, val in enumerate(df['counts'].values):
plt.text(i, val, float(val), horizontalalignment='center', verticalalignment='bottom', fontdict={'fontweight':500, 'size':12})
# Decoration
plt.gca().set_xticklabels(df['manufacturer'], rotation=60, horizontalalignment= 'right')
plt.title("Number of Vehicles by Manaufacturers", fontsize=22)
plt.ylabel('# Vehicles')
plt.ylim(0, 45)
plt.show()
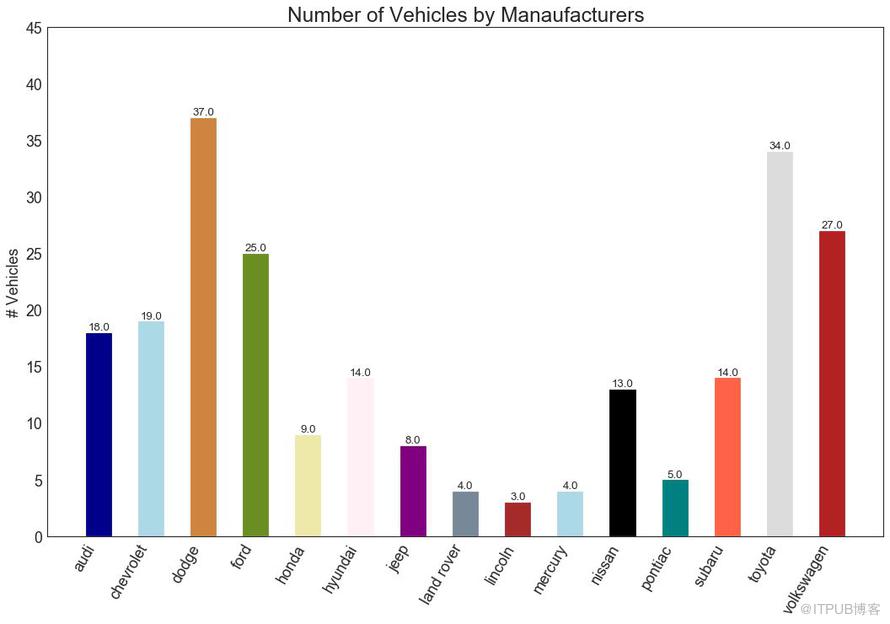
еӣҫ34
е…ӯгҖҒеҸҳеҢ– пјҲChangeпјү
35 ж—¶й—ҙеәҸеҲ—еӣҫ пјҲTime Series Plotпјү
ж—¶й—ҙеәҸеҲ—еӣҫз”ЁдәҺжҳҫзӨәз»ҷе®ҡеәҰйҮҸйҡҸж—¶й—ҙеҸҳеҢ–зҡ„ж–№ејҸгҖӮ еңЁиҝҷйҮҢпјҢжӮЁеҸҜд»ҘзңӢеҲ° 1949е№ҙ иҮі 1969е№ҙй—ҙиҲӘз©әе®ўиҝҗйҮҸзҡ„еҸҳеҢ–жғ…еҶөгҖӮ
# Import Data
df = pd.read_csv('https://github.com/selva86/datasets/raw/master/AirPassengers.csv')
# Draw Plot
plt.figure(figsize=(16,10), dpi= 80)
plt.plot('date', 'traffic', data=df, color='tab:red')
# Decoration
plt.ylim(50, 750)
xtick_location = df.index.tolist()[::12]
xtick_labels = [x[-4:] for x in df.date.tolist()[::12]]
plt.xticks(ticks=xtick_location, labels=xtick_labels, rotation=0, fontsize=12, horizontalalignment='center', alpha=.7)
plt.yticks(fontsize=12, alpha=.7)
plt.title("Air Passengers Traffic (1949 - 1969)", fontsize=22)
plt.grid(axis='both', alpha=.3)
# Remove borders
plt.gca().spines["top"].set_alpha(0.0)
plt.gca().spines["bottom"].set_alpha(0.3)
plt.gca().spines["right"].set_alpha(0.0)
plt.gca().spines["left"].set_alpha(0.3)
plt.show()
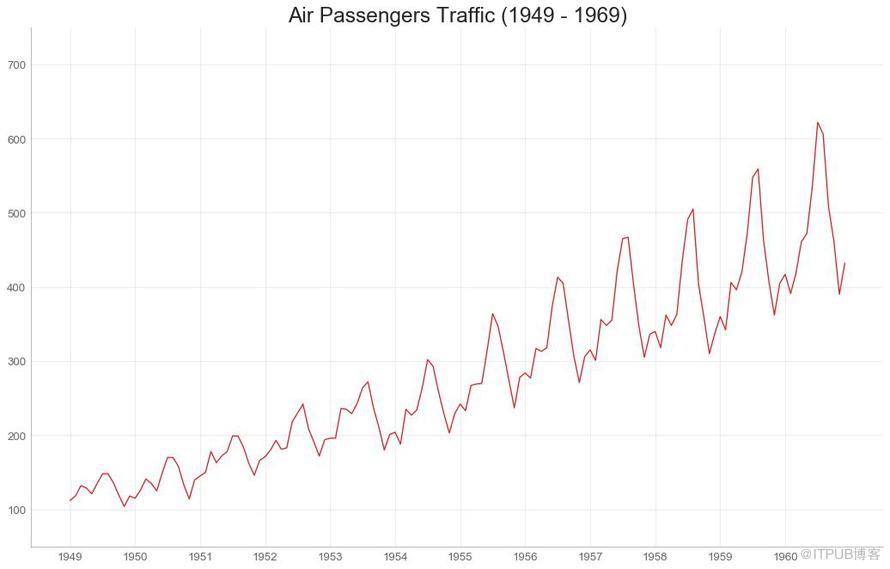
еӣҫ35
36 еёҰжіўеі°жіўи°·ж Үи®°зҡ„ж—¶еәҸеӣҫ пјҲTime Series with Peaks and Troughs Annotatedпјү
дёӢйқўзҡ„ж—¶й—ҙеәҸеҲ—з»ҳеҲ¶дәҶжүҖжңүеі°еҖје’ҢдҪҺи°·пјҢ并注йҮҠдәҶжүҖйҖүзү№ж®ҠдәӢ件зҡ„еҸ‘з”ҹгҖӮ
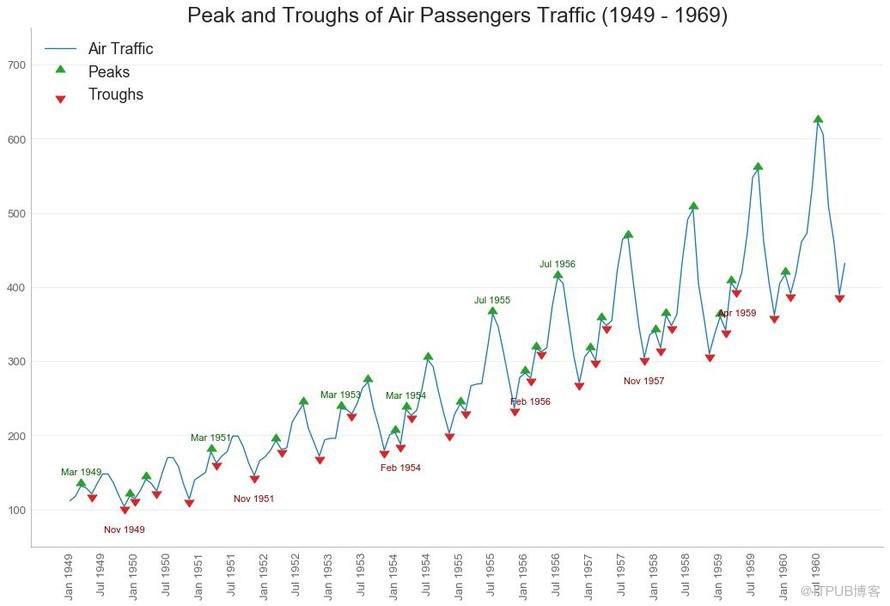
еӣҫ36
37 иҮӘзӣёе…іе’ҢйғЁеҲҶиҮӘзӣёе…іеӣҫ пјҲAutocorrelation (ACF) and Partial Autocorrelation (PACF) Plotпјү
иҮӘзӣёе…іеӣҫпјҲACFеӣҫпјүжҳҫзӨәж—¶й—ҙеәҸеҲ—дёҺе…¶иҮӘиә«ж»һеҗҺзҡ„зӣёе…іжҖ§гҖӮ жҜҸжқЎеһӮзӣҙзәҝпјҲеңЁиҮӘзӣёе…іеӣҫдёҠпјүиЎЁзӨәзі»еҲ—дёҺж»һеҗҺ0д№Ӣй—ҙзҡ„ж»һеҗҺд№Ӣй—ҙзҡ„зӣёе…іжҖ§гҖӮеӣҫдёӯзҡ„и“қиүІйҳҙеҪұеҢәеҹҹжҳҜжҳҫзқҖжҖ§ж°ҙе№ігҖӮ йӮЈдәӣдҪҚдәҺи“қзәҝд№ӢдёҠзҡ„ж»һеҗҺжҳҜжҳҫзқҖзҡ„ж»һеҗҺгҖӮ
йӮЈд№ҲеҰӮдҪ•и§ЈиҜ»е‘ўпјҹ
еҜ№дәҺз©әд№ҳж—…е®ўпјҢжҲ‘们зңӢеҲ°еӨҡиҫҫ14дёӘж»һеҗҺи·Ёи¶Ҡи“қзәҝпјҢеӣ жӯӨйқһеёёйҮҚиҰҒгҖӮ иҝҷж„Ҹе‘ізқҖпјҢ14е№ҙеүҚзҡ„иҲӘз©әж—…е®ўдәӨйҖҡйҮҸеҜ№д»ҠеӨ©зҡ„дәӨйҖҡзҠ¶еҶөжңүеҪұе“ҚгҖӮ
PACFеңЁеҸҰдёҖж–№йқўжҳҫзӨәдәҶд»»дҪ•з»ҷе®ҡж»һеҗҺпјҲж—¶й—ҙеәҸеҲ—пјүдёҺеҪ“еүҚеәҸеҲ—зҡ„иҮӘзӣёе…іпјҢдҪҶжҳҜеҲ йҷӨдәҶж»һеҗҺзҡ„иҙЎзҢ®гҖӮ
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
# Import Data
df = pd.read_csv('https://github.com/selva86/datasets/raw/master/AirPassengers.csv')
# Draw Plot
fig, (ax1, ax2) = plt.subplots(1, 2,figsize=(16,6), dpi= 80)
plot_acf(df.traffic.tolist(), ax=ax1, lags=50)
plot_pacf(df.traffic.tolist(), ax=ax2, lags=20)
# Decorate
# lighten the borders
ax1.spines["top"].set_alpha(.3); ax2.spines["top"].set_alpha(.3)
ax1.spines["bottom"].set_alpha(.3); ax2.spines["bottom"].set_alpha(.3)
ax1.spines["right"].set_alpha(.3); ax2.spines["right"].set_alpha(.3)
ax1.spines["left"].set_alpha(.3); ax2.spines["left"].set_alpha(.3)
# font size of tick labels
ax1.tick_params(axis='both', labelsize=12)
ax2.tick_params(axis='both', labelsize=12)
plt.show()
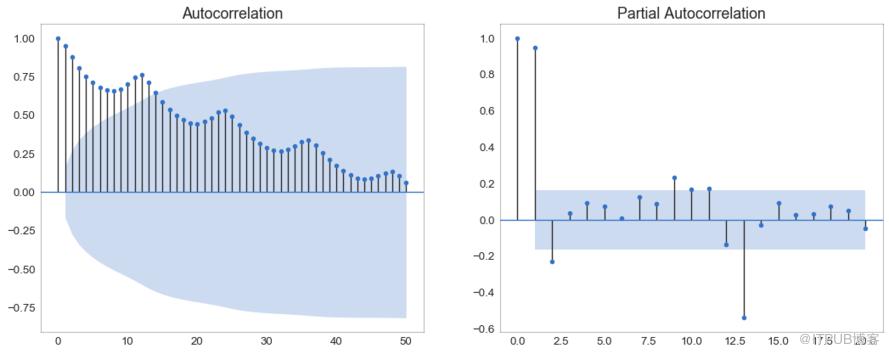
еӣҫ37
38 дәӨеҸүзӣёе…іеӣҫ пјҲCross Correlation plotпјү
дәӨеҸүзӣёе…іеӣҫжҳҫзӨәдәҶдёӨдёӘж—¶й—ҙеәҸеҲ—зӣёдә’д№Ӣй—ҙзҡ„ж»һеҗҺгҖӮ
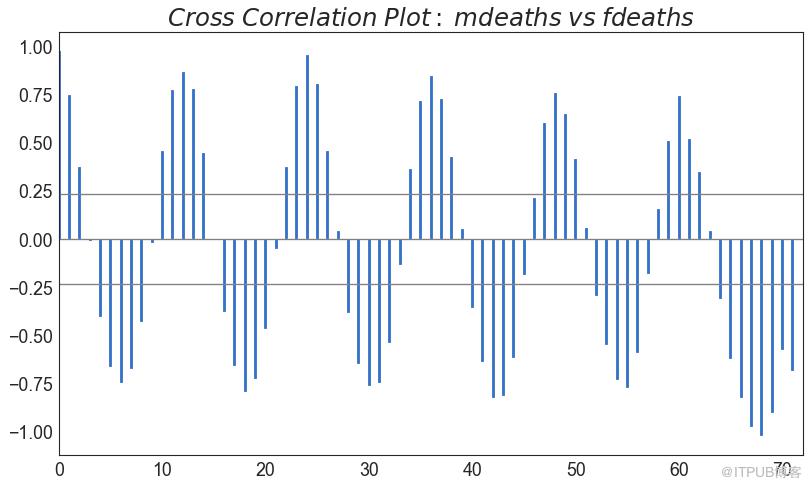
еӣҫ38
39 ж—¶й—ҙеәҸеҲ—еҲҶи§Јеӣҫ пјҲTime Series Decomposition Plotпјү
ж—¶й—ҙеәҸеҲ—еҲҶи§ЈеӣҫжҳҫзӨәж—¶й—ҙеәҸеҲ—еҲҶи§Јдёәи¶ӢеҠҝпјҢеӯЈиҠӮе’Ңж®Ӣе·®еҲҶйҮҸгҖӮ
from statsmodels.tsa.seasonal import seasonal_decompose
from dateutil.parser import parse
# Import Data
df = pd.read_csv('https://github.com/selva86/datasets/raw/master/AirPassengers.csv')
dates = pd.DatetimeIndex([parse(d).strftime('%Y-%m-01') for d in df['date']])
df.set_index(dates, inplace=True)
# Decompose
result = seasonal_decompose(df['traffic'], model='multiplicative')
# Plot
plt.rcParams.update({'figure.figsize': (10,10)})
result.plot().suptitle('Time Series Decomposition of Air Passengers')
plt.show()
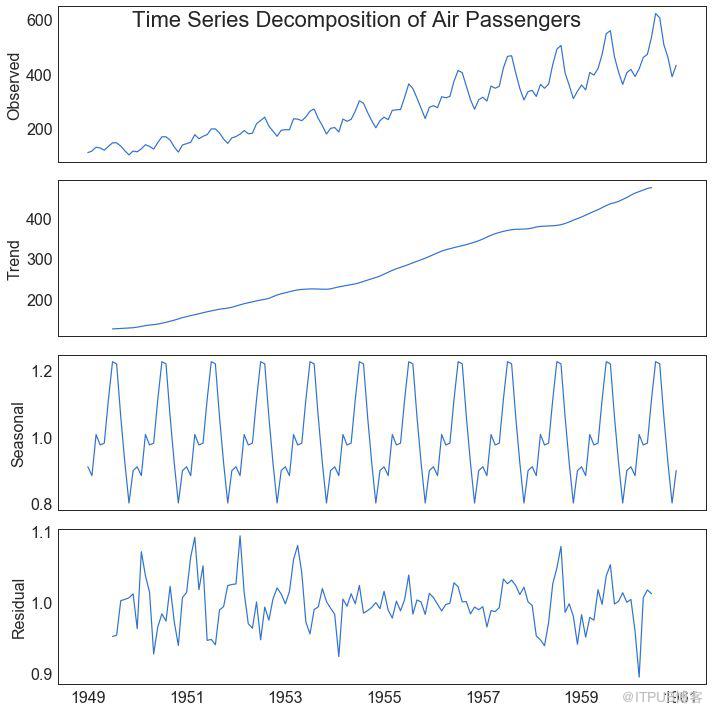
еӣҫ39
40 еӨҡдёӘж—¶й—ҙеәҸеҲ— пјҲMultiple Time Seriesпјү
жӮЁеҸҜд»Ҙз»ҳеҲ¶еӨҡдёӘж—¶й—ҙеәҸеҲ—пјҢеңЁеҗҢдёҖеӣҫиЎЁдёҠжөӢйҮҸзӣёеҗҢзҡ„еҖјпјҢеҰӮдёӢжүҖзӨәгҖӮ
еӣҫ40
41 дҪҝз”Ёиҫ…еҠ© Y иҪҙжқҘз»ҳеҲ¶дёҚеҗҢиҢғеӣҙзҡ„еӣҫеҪў пјҲPlotting with different scales using secondary Y axisпјү
еҰӮжһңиҰҒжҳҫзӨәеңЁеҗҢдёҖж—¶й—ҙзӮ№жөӢйҮҸдёӨдёӘдёҚеҗҢж•°йҮҸзҡ„дёӨдёӘж—¶й—ҙеәҸеҲ—пјҢеҲҷеҸҜд»ҘеңЁеҸідҫ§зҡ„иҫ…еҠ©YиҪҙдёҠеҶҚз»ҳеҲ¶з¬¬дәҢдёӘзі»еҲ—гҖӮ
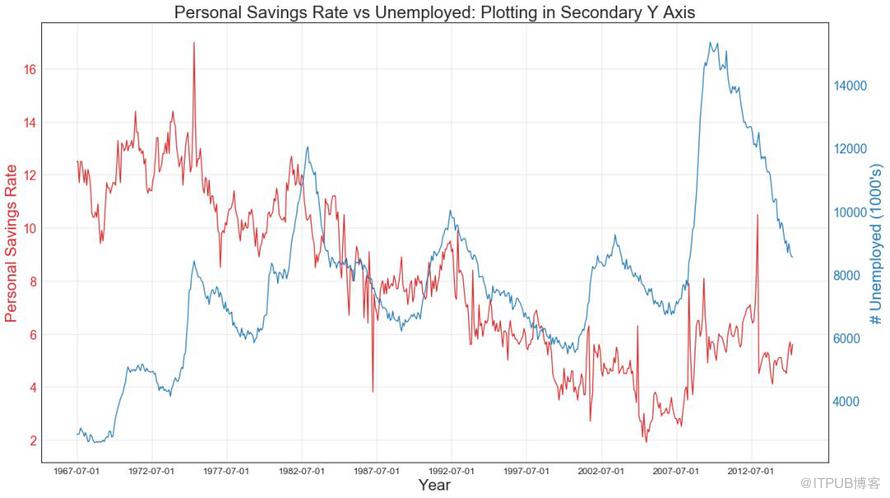
еӣҫ41
42 еёҰжңүиҜҜе·®еёҰзҡ„ж—¶й—ҙеәҸеҲ— пјҲTime Series with Error Bandsпјү
еҰӮжһңжӮЁжңүдёҖдёӘж—¶й—ҙеәҸеҲ—ж•°жҚ®йӣҶпјҢжҜҸдёӘж—¶й—ҙзӮ№пјҲж—Ҙжңҹ/ж—¶й—ҙжҲіпјүжңүеӨҡдёӘи§ӮжөӢеҖјпјҢеҲҷеҸҜд»Ҙжһ„е»әеёҰжңүиҜҜе·®еёҰзҡ„ж—¶й—ҙеәҸеҲ—гҖӮ жӮЁеҸҜд»ҘеңЁдёӢйқўзңӢеҲ°дёҖдәӣеҹәдәҺжҜҸеӨ©дёҚеҗҢж—¶й—ҙи®ўеҚ•зҡ„зӨәдҫӢгҖӮ еҸҰдёҖдёӘе…ідәҺ45еӨ©жҢҒз»ӯеҲ°иҫҫзҡ„и®ўеҚ•ж•°йҮҸзҡ„дҫӢеӯҗгҖӮ
еңЁиҜҘж–№жі•дёӯпјҢи®ўеҚ•ж•°йҮҸзҡ„е№іеқҮеҖјз”ұзҷҪзәҝиЎЁзӨәгҖӮ 并且计算95пј…зҪ®дҝЎеҢәй—ҙ并еӣҙз»•еқҮеҖјз»ҳеҲ¶гҖӮ
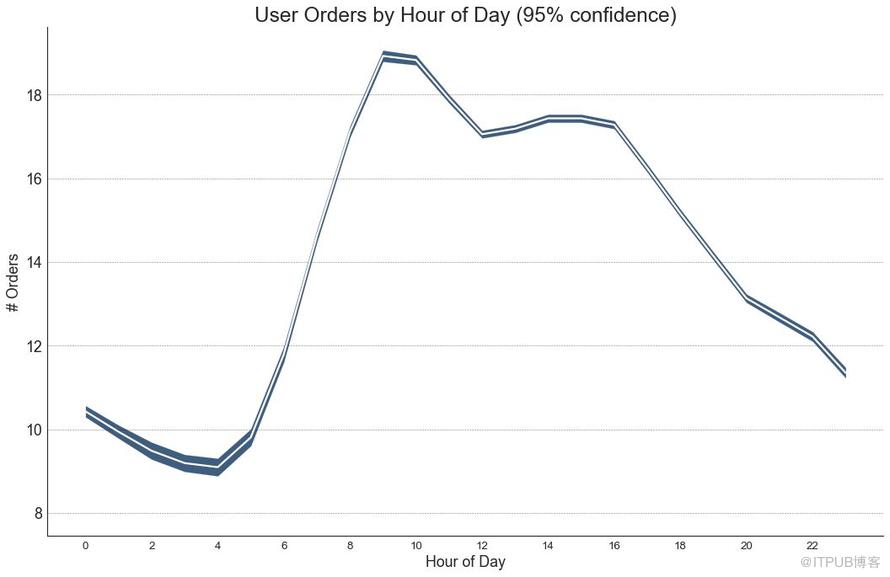
еӣҫ42
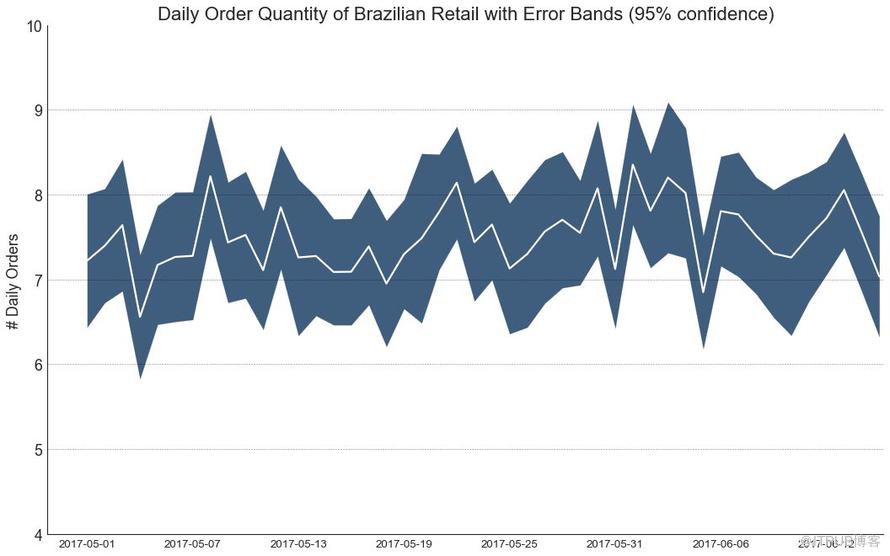
еӣҫ42-2
43 е Ҷз§Ҝйқўз§Ҝеӣҫ пјҲStacked Area Chartпјү
е Ҷз§Ҝйқўз§ҜеӣҫеҸҜд»Ҙзӣҙи§Ӯең°жҳҫзӨәеӨҡдёӘж—¶й—ҙеәҸеҲ—зҡ„иҙЎзҢ®зЁӢеәҰпјҢеӣ жӯӨеҫҲе®№жҳ“зӣёдә’жҜ”иҫғгҖӮ
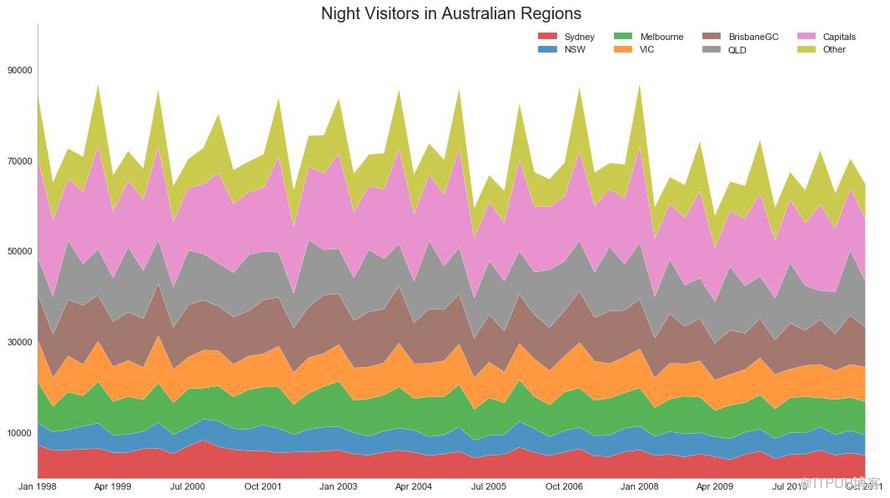
еӣҫ43
44 жңӘе Ҷз§Ҝзҡ„йқўз§Ҝеӣҫ пјҲArea Chart UnStackedпјү
жңӘе Ҷз§Ҝйқўз§Ҝеӣҫз”ЁдәҺеҸҜи§ҶеҢ–дёӨдёӘжҲ–жӣҙеӨҡдёӘзі»еҲ—зӣёеҜ№дәҺеҪјжӯӨзҡ„иҝӣеәҰпјҲиө·дјҸпјүгҖӮ еңЁдёӢйқўзҡ„еӣҫиЎЁдёӯпјҢжӮЁеҸҜд»Ҙжё…жҘҡең°зңӢеҲ°йҡҸзқҖеӨұдёҡдёӯдҪҚж•°жҢҒз»ӯж—¶й—ҙзҡ„еўһеҠ пјҢдёӘдәәеӮЁи“„зҺҮдјҡдёӢйҷҚгҖӮ жңӘе Ҷз§Ҝйқўз§ҜеӣҫиЎЁеҫҲеҘҪең°еұ•зӨәдәҶиҝҷз§ҚзҺ°иұЎгҖӮ
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/economics.csv")
# Prepare Data
x = df['date'].values.tolist()
y1 = df['psavert'].values.tolist()
y2 = df['uempmed'].values.tolist()
mycolors = ['tab:red', 'tab:blue', 'tab:green', 'tab:orange', 'tab:brown', 'tab:grey', 'tab:pink', 'tab:olive']
columns = ['psavert', 'uempmed']
# Draw Plot
fig, ax = plt.subplots(1, 1, figsize=(16,9), dpi= 80)
ax.fill_between(x, y1=y1, y2=0, label=columns[1], alpha=0.5, color=mycolors[1], linewidth=2)
ax.fill_between(x, y1=y2, y2=0, label=columns[0], alpha=0.5, color=mycolors[0], linewidth=2)
# Decorations
ax.set_title('Personal Savings Rate vs Median Duration of Unemployment', fontsize=18)
ax.set(ylim=[0, 30])
ax.legend(loc='best', fontsize=12)
plt.xticks(x[::50], fontsize=10, horizontalalignment='center')
plt.yticks(np.arange(2.5, 30.0, 2.5), fontsize=10)
plt.xlim(-10, x[-1])
# Draw Tick lines
for y in np.arange(2.5, 30.0, 2.5):
plt.hlines(y, xmin=0, xmax=len(x), colors='black', alpha=0.3, linestyles="--", lw=0.5)
# Lighten borders
plt.gca().spines["top"].set_alpha(0)
plt.gca().spines["bottom"].set_alpha(.3)
plt.gca().spines["right"].set_alpha(0)
plt.gca().spines["left"].set_alpha(.3)
plt.show()
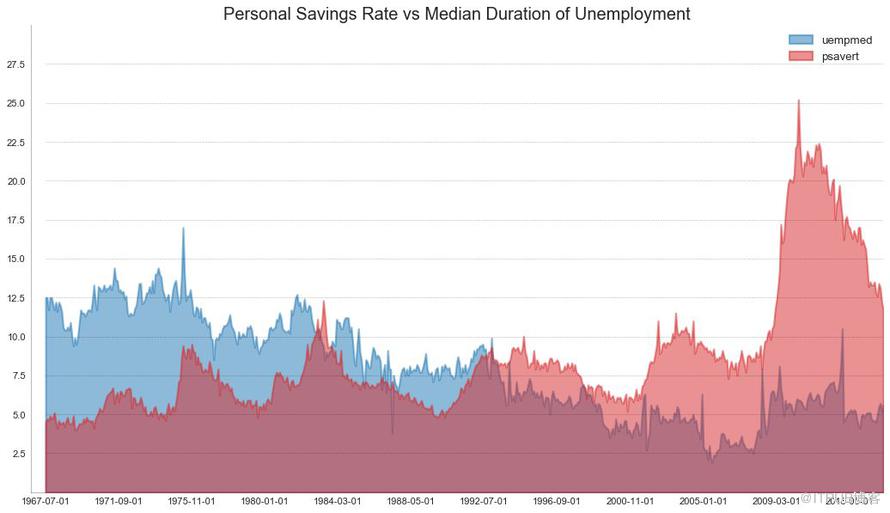
еӣҫ44
45 ж—ҘеҺҶзғӯеҠӣеӣҫ пјҲCalendar Heat Mapпјү
дёҺж—¶й—ҙеәҸеҲ—зӣёжҜ”пјҢж—ҘеҺҶең°еӣҫжҳҜеҸҜи§ҶеҢ–еҹәдәҺж—¶й—ҙзҡ„ж•°жҚ®зҡ„еӨҮйҖүе’ҢдёҚеӨӘдјҳйҖүзҡ„йҖүйЎ№гҖӮ иҷҪ然еҸҜд»ҘеңЁи§Ҷи§үдёҠеҗёеј•дәәпјҢдҪҶж•°еҖје№¶дёҚеҚҒеҲҶжҳҺжҳҫгҖӮ 然иҖҢпјҢе®ғеҸҜд»ҘеҫҲеҘҪең°жҸҸз»ҳжһҒз«ҜеҖје’ҢеҒҮж—Ҙж•ҲжһңгҖӮ
пјҲгҖҺPythonж•°жҚ®д№ӢйҒ“гҖҸжіЁпјҡйңҖиҰҒе®үиЈ… calmap еә“пјү
import matplotlib as mpl
# pip install calmap
# Pythonж•°жҚ®д№ӢйҒ“ еӨҮжіЁ
import calmap
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/yahoo.csv", parse_dates=['date'])
df.set_index('date', inplace=True)
# Plot
plt.figure(figsize=(16,10), dpi= 80)
calmap.calendarplot(df['2014']['VIX.Close'], fig_kws={'figsize': (16,10)}, yearlabel_kws={'color':'black', 'fontsize':14}, subplot_kws={'title':'Yahoo Stock Prices'})
plt.show()

еӣҫ45
46 еӯЈиҠӮеӣҫ пјҲSeasonal Plotпјү
еӯЈиҠӮеӣҫеҸҜз”ЁдәҺжҜ”иҫғдёҠдёҖеӯЈдёӯеҗҢдёҖеӨ©пјҲе№ҙ/жңҲ/е‘Ёзӯүпјүзҡ„ж—¶й—ҙеәҸеҲ—гҖӮ
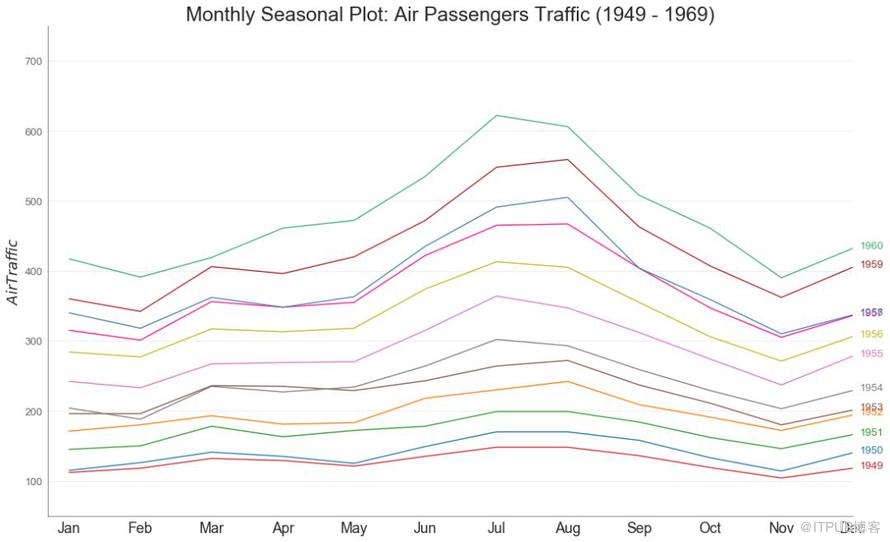
еӣҫ46
дёғгҖҒеҲҶз»„ пјҲGroupsпјү
47 ж ‘зҠ¶еӣҫ пјҲDendrogramпјү
ж ‘еҪўеӣҫеҹәдәҺз»ҷе®ҡзҡ„и·қзҰ»еәҰйҮҸе°Ҷзӣёдјјзҡ„зӮ№з»„еҗҲеңЁдёҖиө·пјҢ并еҹәдәҺзӮ№зҡ„зӣёдјјжҖ§е°Ҷе®ғ们组з»ҮеңЁж ‘зҠ¶й“ҫжҺҘдёӯгҖӮ
import scipy.cluster.hierarchy as shc
# Import Data
df = pd.read_csv('https://raw.githubusercontent.com/selva86/datasets/master/USArrests.csv')
# Plot
plt.figure(figsize=(16, 10), dpi= 80)
plt.title("USArrests Dendograms", fontsize=22)
dend = shc.dendrogram(shc.linkage(df[['Murder', 'Assault', 'UrbanPop', 'Rape']], method='ward'), labels=df.State.values, color_threshold=100)
plt.xticks(fontsize=12)
plt.show()
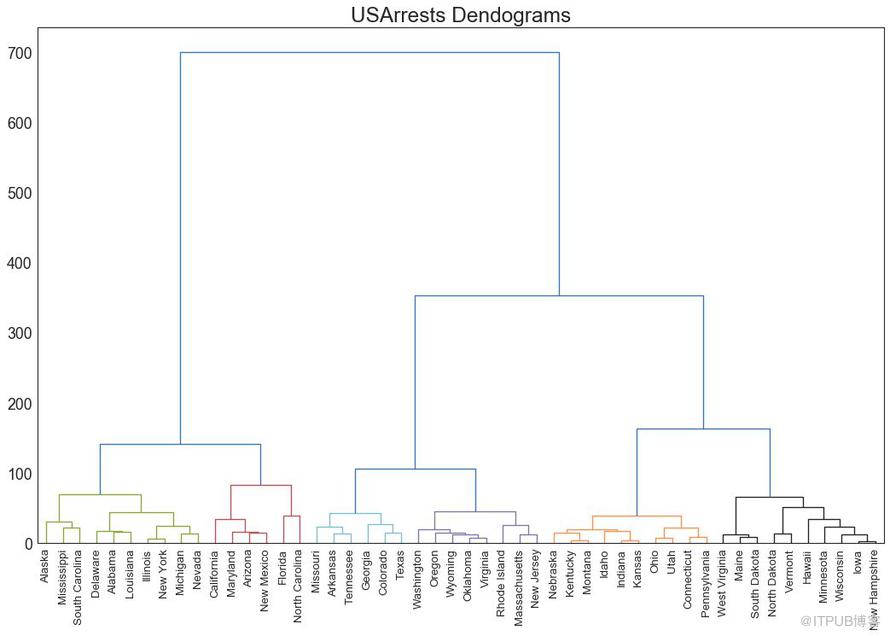
еӣҫ47
48 з°ҮзҠ¶еӣҫ пјҲCluster Plotпјү
з°ҮзҠ¶еӣҫ пјҲCluster PlotпјүеҸҜз”ЁдәҺеҲ’еҲҶеұһдәҺеҗҢдёҖзҫӨйӣҶзҡ„зӮ№гҖӮ дёӢйқўжҳҜж №жҚ®USArrestsж•°жҚ®йӣҶе°ҶзҫҺеӣҪеҗ„е·һеҲҶдёә5з»„зҡ„д»ЈиЎЁжҖ§зӨәдҫӢгҖӮ жӯӨеӣҫдҪҝз”ЁвҖңи°ӢжқҖвҖқе’ҢвҖңж”»еҮ»вҖқеҲ—дҪңдёәXе’ҢYиҪҙгҖӮ жҲ–иҖ…пјҢжӮЁеҸҜд»Ҙе°Ҷ第дёҖдёӘеҲ°дё»иҰҒ组件用дҪңXиҪҙе’ҢYиҪҙгҖӮ
from sklearn.cluster import AgglomerativeClustering
from scipy.spatial import ConvexHull
# Import Data
df = pd.read_csv('https://raw.githubusercontent.com/selva86/datasets/master/USArrests.csv')
# Agglomerative Clustering
cluster = AgglomerativeClustering(n_clusters=5, affinity='euclidean', linkage='ward')
cluster.fit_predict(df[['Murder', 'Assault', 'UrbanPop', 'Rape']])
# Plot
plt.figure(figsize=(14, 10), dpi= 80)
plt.scatter(df.iloc[:,0], df.iloc[:,1], c=cluster.labels_, cmap='tab10')
# Encircle
def encircle(x,y, ax=None, **kw):
if not ax: ax=plt.gca()
p = np.c_[x,y]
hull = ConvexHull(p)
poly = plt.Polygon(p[hull.vertices,:], **kw)
ax.add_patch(poly)
# Draw polygon surrounding vertices
encircle(df.loc[cluster.labels_ == 0, 'Murder'], df.loc[cluster.labels_ == 0, 'Assault'], ec="k", fc="gold", alpha=0.2, linewidth=0)
encircle(df.loc[cluster.labels_ == 1, 'Murder'], df.loc[cluster.labels_ == 1, 'Assault'], ec="k", fc="tab:blue", alpha=0.2, linewidth=0)
encircle(df.loc[cluster.labels_ == 2, 'Murder'], df.loc[cluster.labels_ == 2, 'Assault'], ec="k", fc="tab:red", alpha=0.2, linewidth=0)
encircle(df.loc[cluster.labels_ == 3, 'Murder'], df.loc[cluster.labels_ == 3, 'Assault'], ec="k", fc="tab:green", alpha=0.2, linewidth=0)
encircle(df.loc[cluster.labels_ == 4, 'Murder'], df.loc[cluster.labels_ == 4, 'Assault'], ec="k", fc="tab:orange", alpha=0.2, linewidth=0)
# Decorations
plt.xlabel('Murder'); plt.xticks(fontsize=12)
plt.ylabel('Assault'); plt.yticks(fontsize=12)
plt.title('Agglomerative Clustering of USArrests (5 Groups)', fontsize=22)
plt.show()
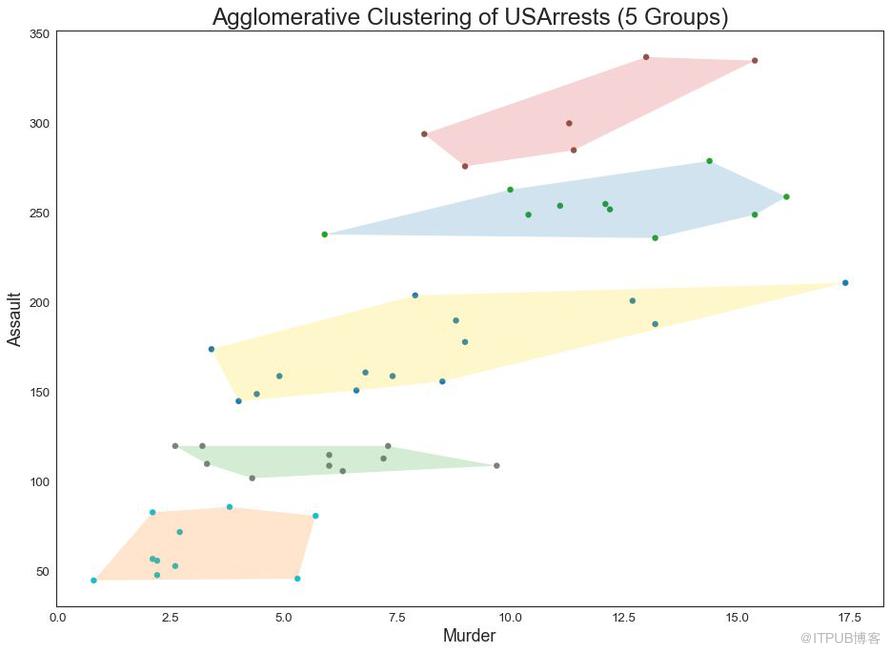
еӣҫ48
49 е®үеҫ·йІҒж–ҜжӣІзәҝ пјҲAndrews Curveпјү
е®үеҫ·йІҒж–ҜжӣІзәҝжңүеҠ©дәҺеҸҜи§ҶеҢ–жҳҜеҗҰеӯҳеңЁеҹәдәҺз»ҷе®ҡеҲҶз»„зҡ„ж•°еӯ—зү№еҫҒзҡ„еӣәжңүеҲҶз»„гҖӮ еҰӮжһңиҰҒзҙ пјҲж•°жҚ®йӣҶдёӯзҡ„еҲ—пјүж— жі•еҢәеҲҶз»„пјҲcylпјүпјҢйӮЈд№Ҳиҝҷдәӣзәҝе°ҶдёҚдјҡеҫҲеҘҪең°йҡ”зҰ»пјҢеҰӮдёӢжүҖзӨәгҖӮ
from pandas.plotting import andrews_curves
# Import
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")
df.drop(['cars', 'carname'], axis=1, inplace=True)
# Plot
plt.figure(figsize=(12,9), dpi= 80)
andrews_curves(df, 'cyl', colormap='Set1')
# Lighten borders
plt.gca().spines["top"].set_alpha(0)
plt.gca().spines["bottom"].set_alpha(.3)
plt.gca().spines["right"].set_alpha(0)
plt.gca().spines["left"].set_alpha(.3)
plt.title('Andrews Curves of mtcars', fontsize=22)
plt.xlim(-3,3)
plt.grid(alpha=0.3)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()
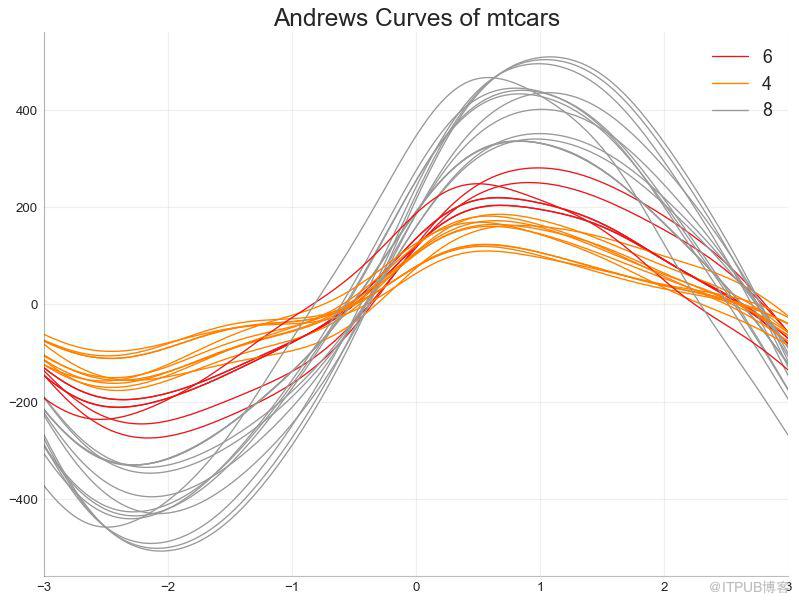
еӣҫ49
50 е№іиЎҢеқҗж Ү пјҲParallel Coordinatesпјү
е№іиЎҢеқҗж ҮжңүеҠ©дәҺеҸҜи§ҶеҢ–зү№еҫҒжҳҜеҗҰжңүеҠ©дәҺжңүж•Ҳең°йҡ”зҰ»з»„гҖӮ еҰӮжһңе®һзҺ°йҡ”зҰ»пјҢеҲҷиҜҘзү№еҫҒеҸҜиғҪеңЁйў„жөӢиҜҘз»„ж—¶йқһеёёжңүз”ЁгҖӮ
from pandas.plotting import parallel_coordinates
# Import Data
df_final = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/diamonds_filter.csv")
# Plot
plt.figure(figsize=(12,9), dpi= 80)
parallel_coordinates(df_final, 'cut', colormap='Dark2')
# Lighten borders
plt.gca().spines["top"].set_alpha(0)
plt.gca().spines["bottom"].set_alpha(.3)
plt.gca().spines["right"].set_alpha(0)
plt.gca().spines["left"].set_alpha(.3)
plt.title('Parallel Coordinated of Diamonds', fontsize=22)
plt.grid(alpha=0.3)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()
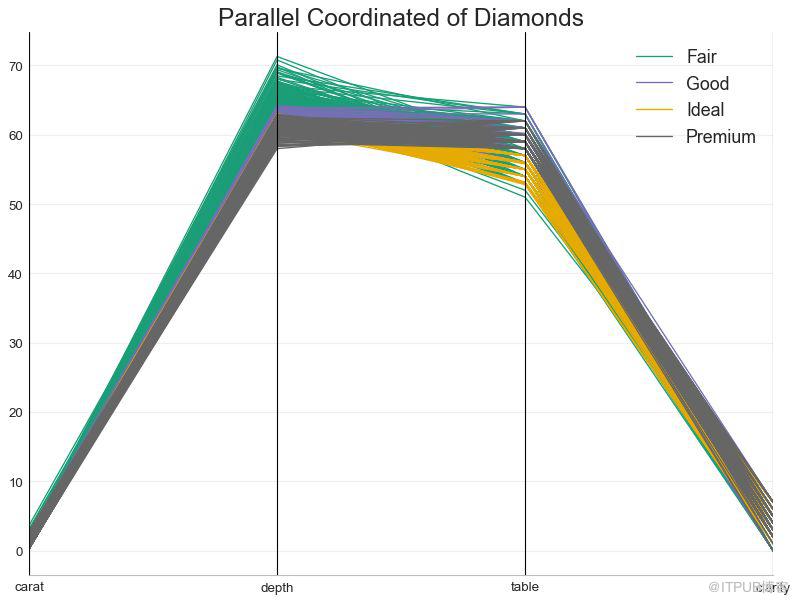
еӣҫ50
д»ҘдёҠжҳҜвҖңMatplotlibеҸҜи§ҶеҢ–жңҖжңүд»·еҖјзҡ„еӣҫиЎЁжңүе“ӘдәӣвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ





