这期内容当中小编将会给大家带来有关如何进行MapReduce数据序列化读写概念的浅析,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
MapReduce为处理简单数据格式(如日志文件)提供了简明的文档支持,但MapReduce已经从日志文件发展到更复杂的数据序列化格式(如文本,XML和JSON)处理,本章的目标是记录如何使用常见的数据序列化格式,以及检查更结构化的序列化格式,并比较它们与MapReduce的适用性。下面主要介绍了MapReduce处理以不同格式(如XML和JSON)存储数据的方法,为更深入了解Avro和Parquet等这类适合大数据和Hadoop的数据格式铺平了道路。
数据序列化 - 使用文本及其他方法
如果希望使用无处不在的XML和JSON数据序列化格式,这些格式在大多数编程语言中都可直接工作,有多种工具可用于编组、解组和验证。但是,在MapReduce中使用XML和JSON面临两大挑战。首先,MapReduce需要能够支持读写特定数据序列化格式的类,如果想使用自定义文件格式,那么很可能没有相应的类支持正在使用的序列化格式;其次,MapReduce的强大之处在于能够并行读取输入数据,如果输入文件很大(数百兆字节甚至更多),读取序列化格式的类能够将较大文件拆分以便多个任务可以并行读取,这一点至关重要。
XML和JSON格式
MapReduce中的数据序列化支持是读取和写入MapReduce数据输入和输出类属性,让我们首先概述MapReduce如何支持数据输入和输出。
3.1 了解MapReduce中的输入和输出
你的数据可能位于许多FTP服务器后面的XML文件、中央Web服务器上的文本日志文件或HDFS中的Lucene索引。MapReduce如何跨多种存储机制读取和写入这些不同的序列化结构?
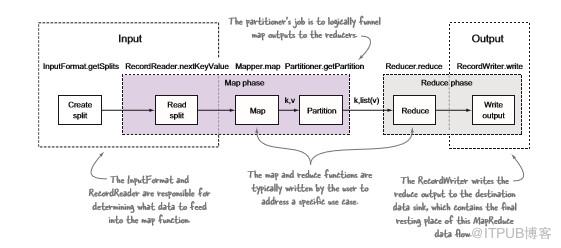
图3.1 MapReduce中的输入和输出actor
图3.1显示了通过MapReduce的数据流,并确定了负责流的各部分参与者。在输入端,我们可以看到某些工作(创建拆分)在map阶段以外执行,而其他工作则作为map阶段的一部分执行(读取拆分),所有输出工作都在reduce阶段(写输出)执行。
图3.2 显示了仅使用map作业的相同流程,在仅map作业中,MapReduce框架仍使用OutputFormat和RecordWriter类将输出直接写入数据接收器。让我们来看看数据流并讨论各角色的责任,我们还将查看内置TextInputFormat和TextOutputFormat类中的相关代码,以更好地理解这些概念,TextInputFormat和TextOutputFormat类读取和写入面向行的文本文件。
3.1.1数据输入支持
MapReduce中数据输入的两个类是InputFormat和RecordReader,查询InputFormat类以确定应如何为map任务分区输入数据,并且RecordReader执行从输入读取数据。
INPUTFORMAT
MapReduce中的每个作业都必须根据InputFormat抽象类中指定的规则定义其输入。InputFormat实现者必须完成三步:描述map输入键和值类型信息;指定输入数据应该如何分区;指示应该从源读取数据的RecordReader实例。
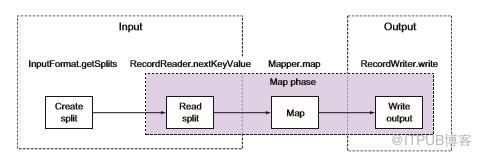
图3.2没有Reducer的MapReduce输入和输出actor
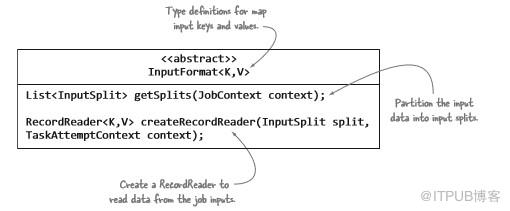
图3.3带注释的InputFormat类及其三个规则
可以说,最重要的规则是确定如何划分输入数据。在MapReduce命名法中,这些划分称为输入拆分。输入拆分直接影响map并行效率,因为每个拆分由单个map任务处理。 使用无法在单个数据源(例如文件)上创建多个输入拆分的InputFormat将导致map阶段进行缓慢,因为将会按顺序处理该文件。
TextInputFormat类提供了InputFormat类的createRecordReader方法实现,但它将输入拆分的计算委托给其父类FileInputFormat。以下代码显示了TextInputFormat类的相关部分:

确定输入拆分的FileInputFormat代码稍微复杂,以下示例显示了代码的简化形式,以描述getSplits方法的主要元素:

以下代码显示了如何指定用于MapReduce作业的InputFormat:
job.setInputFormatClass(TextInputFormat.class);
RECORDREADER
我们将在map任务中创建和使用RecordReader类,以从输入拆分中读取数据,并以 key/value形式提供每个记录供mapper使用。通常为每个输入拆分创建一个任务,每个任务都有一个RecordReader,负责读取该输入拆分的数据。

图3.4 带注释的RecordReader类及其抽象方法
如前所示,TextInputFormat类创建一个LineRecordReader以从输入拆分中读取记录。LineRecordReader直接扩展RecordReader类,并使用LineReader类从输入拆分中读取行。LineRecordReader使用文件中的字节偏移量作为map key,并使用行的内容作为map value。 以下示例显示了LineRecordReader的简化版本:

因为LineReader类很简单,所以我们将跳过该代码。下一步是查看MapReduce如何支持数据输出。
3.1.2 数据输出
MapReduce使用与输入类似的过程来支持输出数据。必须存在两个类:OutputFormat和RecordWriter。OutputFormat执行数据接收器属性的一些基本验证,RecordWriter将每个reducer输出写入数据接收器。
OUTPUTFORMAT
与InputFormat类非常相似,OutputFormat类(如图3.5所示)定义了实现必须满足的条件:检查与作业输出相关的信息;提供RecordWriter并指定输出提交者;允许写入并在任务完成时保持“permanent”。
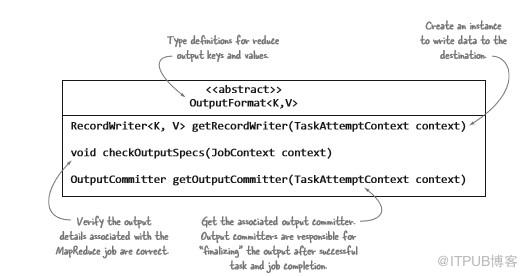
图3.5 带注释的OutputFormat类
就像TextInputFormat一样,TextOutputFormat还扩展了一个基类FileOutputFormat,负责复杂的数据流操作,例如输出提交。接下来,我们来看看TextOutputFormat执行工作流程,以下代码显示了如何指定用于MapReduce作业的OutputFormat:
job.setOutputFormatClass(TextOutputFormat.class);
RECORDWRITER
我们将使用RecordWriter将reducer输出写入目标数据接收器。这是一个简单的类,如图3.6所示。

TextOutputFormat返回一个LineRecordWriter对象,它是TextOutputFormat的内部类,用于执行对文件写入,以下示例显示了该类的简化版本:

在map端,InputFormat可确定执行了多少个map任务;在reducer端,任务的数量完全基于客户端设置的mapred.reduce.tasks值(如果没有设置, 该值会从mapred-site.xml中获取,如果站点文件中不存在,则从mapred-default.xml获取)。
上述就是小编为大家分享的如何进行MapReduce数据序列化读写概念的浅析了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





