本文主要给大家介绍mysql执行计划定义及解读,文章内容都是笔者用心摘选和编辑的,mysql执行计划定义及解读具有一定的针对性,对大家的参考意义还是比较大的,下面跟笔者一起了解下主题内容吧。
首先我们先简单看一下执行计划是什么东西。
关联一下简单的订单和订单商品join得到的结果: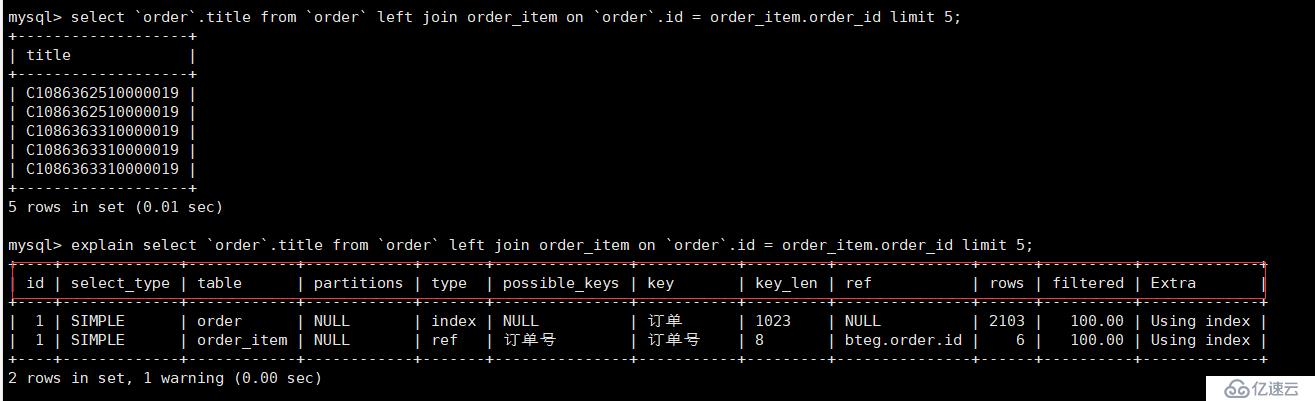
ok,执行计划表总共有12列,每一列的含义,我们一一道来。
1.id,表示每一个子句的操作顺序,id越大,优先级越高。
对于每一个平级查询,id是一致的,表示操作的优先级查询;
对于有子查询的sql,可以看到子查询的优先级是比外层查询要高的。也比较符合我们的主观意识,先查子表,才能查主表。
但是注意,并不是所有带有子查询语句的sql一定会是子查询,例如如下语句:
关于sql优化器的优化规则,我不再多讲解,一是本章的主要内容不是讲这方面的内容,二是我自己领悟的也不够。
2.select_type,查询类型
1)SIMPLE,简单查询,表示不包含子查询或者UNION子句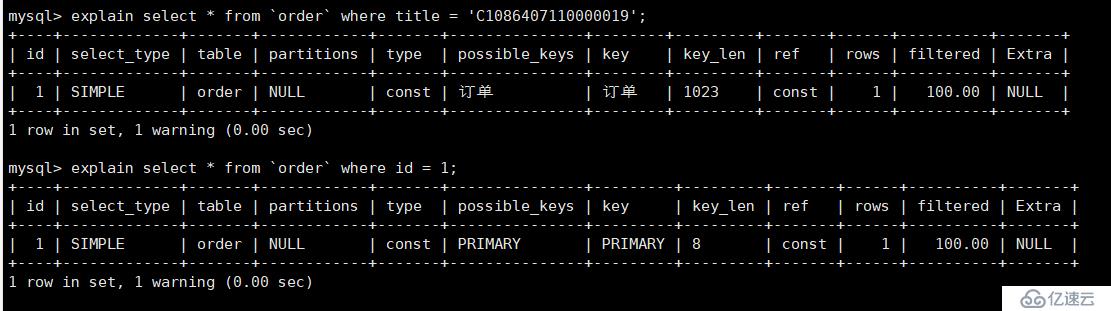
2)PRIMARY,表示查询语句包含子查询或者UNION子句,PRIMARY表示外层的语句
3)SUBQUEY,子查询语句
4)UNION union 位于union中第二个及其以后的子查询被标记为union
5)DERIVED 在from列表中包含的子查询被标记为derived(衍生)
6)DEPENDENT UNION UNION中的第二个或后面的SELECT语句,取决于外面的查询
7)UNION RESULT UNION的结果
6和7我本人并不是十分理解,不再加以展示
3.table,需要查询表,这个有可能是数据库表或临时表
4.partitions,匹配到的分区,出现于分表查询中的情况
5.type,访问类型,这个指标是sql查询优化中很重要的一个指标
常会出现的几个枚举值如下:
system:表中只有一行记录,相当于系统表
const:通过索引一次命中,匹配一行数据
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配,常用语主键或唯一索引扫描
ref:非唯一性索引扫描,返回匹配某个单独值的所有行,用于=、<或>操作符带索引的列
range:只检索给定范围的行,使用一个索引来选择行,一般用于between、<、>;
index:只遍历索引树;
all:全表扫描;
从上到下的执行效率是依次降低的,前5种情况都是理想的索引的情况。通常优化至少到range级别,最好能优化到ref。
列举一些例子:
system是const的一个特例,表中只有一行数据时使用
我在订单编号上建立了唯一索引,通过下图(呃呃,不知道为啥传不了图片了,直接粘结果吧)可以看出,当主键或者唯一索引位于where条件时,那么执行的类型为const
mysql> explain select * from `order` where title = 'C1086407110000019'; +----+-------------+-------+------------+-------+---------------+--------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+--------+---------+-------+------+----------+-------+ | 1 | SIMPLE | order | NULL | const | 订单 | 订单 | 1023 | const | 1 | 100.00 | NULL | +----+-------------+-------+------------+-------+---------------+--------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec) mysql> explain select * from `order` where id = 1; +----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | 1 | SIMPLE | order | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL | +----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec)
而eq_ref的区别为,eq_ref使用在关联查询上,如下:
mysql> explain select * from `order` left join order_item on `order`.id = order_item.order_id where `order`.id = 1; +----+-------------+------------+------------+-------+---------------+-----------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+------------+------------+-------+---------------+-----------+---------+-------+------+----------+-------+ | 1 | SIMPLE | order | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL | | 1 | SIMPLE | order_item | NULL | ref | 订单号 | 订单号 | 8 | const | 2 | 100.00 | NULL | +----+-------------+------------+------------+-------+---------------+-----------+---------+-------+------+----------+-------+ 2 rows in set, 1 warning (0.00 sec)
对于非唯一性索引,比如我们的订单中的用户id,当我们查询时,有可能会使用ref或者range结果如下:
mysql> explain select * from `order` where customer_id = 55029; +----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+ | 1 | SIMPLE | order | NULL | ref | customer_id | customer_id | 8 | const | 10 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec) mysql> explain select * from `order` where customer_id > 55029 and customer_id < 55129; +----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-----------------------+ | 1 | SIMPLE | order | NULL | range | customer_id | customer_id | 8 | NULL | 1 | 100.00 | Using index condition | +----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-----------------------+ 1 row in set, 1 warning (0.00 sec)
当然如果没有索引的字段,那么执行方式只能是ALL了。
但是值得注意的是,并不是有了索引就一定不会走索引的。如果字段的差异性太小,例如性别字段,即使建了索引,那么也不会走索引的。这里我举一个例子,我拿来做测试的所有订单表中只有一个卖家,这个字段上是有索引的,但是我们来查询一下:
mysql> explain select * from `order` where seller_id = 19; +----+-------------+-------+------------+------+------------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+------------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | order | NULL | ALL | 商家,seller_id | NULL | NULL | NULL | 2197 | 100.00 | Using where | +----+-------------+-------+------------+------+------------------+------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
发现实际上innodb并没有选择走索引,因为在这种情况下,走索引比不走索引的开销还要大。关于开销,Innodb是基于CBO进行判断的(更古老的判断方式是RBO,这些内容具体已经记得不是很清楚了,想要了解的需要再查找一些相关资料)。
上述几个值并不是全部的枚举值,例如还有fulltext、 index_merge、 unique_subquery等等,不过出现的频次没有什么上述的几个枚举值高而已。
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
看完以上关于mysql执行计划定义及解读,很多读者朋友肯定多少有一定的了解,如需获取更多的行业知识信息 ,可以持续关注我们的行业资讯栏目的。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





