这篇文章主要为大家分析了大数据交叉报表性能优化实例分析的相关知识点,内容详细易懂,操作细节合理,具有一定参考价值。如果感兴趣的话,不妨跟着跟随小编一起来看看,下面跟着小编一起深入学习“大数据交叉报表性能优化实例分析”的知识吧。
OS:win7
Cpu:8 核
集算报表:1120 安装版
Jvm:1G
数据库:oracle11g
有一个交叉汇总报表,其实格式很简单,行列各一个统计维度。但后台业务表的数据有 175 万条,且还要与其他表(大概在 7w 条左右)做 join,如果由 sql 来处理,可以想象到会慢到什么程度,关键受各种条件影响,能否查出数据都是问题。
注:ACCORECEIVE 表 175w 条数据
目前,测试 birt 需 5 分钟,借助各种中间表与视图。报表友商无法出表。
要求:能做出该报表在 web 展现,且重要的是速度要快,另外,数据(目前大概是 5 年数据)是实时增加的。
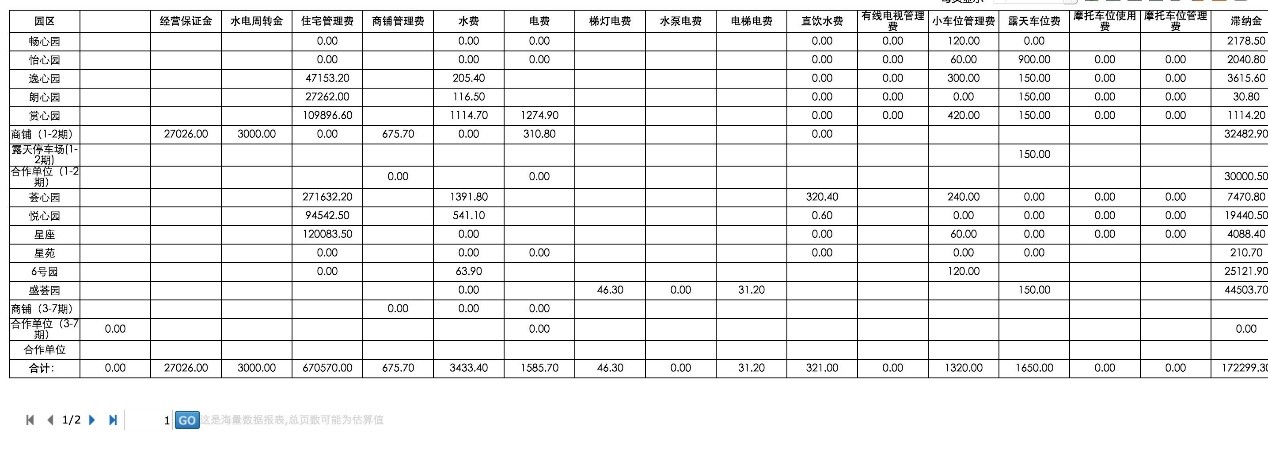
客户报表格式及目前所用 sql:
报表格式:
Sql:
select LOCATIONS.loupan loupan,
LOCATIONS.LPORDERNUM,
nvl(ACCORECEIVE.RECEIVABLEAMOUNT, 0) yingshou,
chargeproct.Description CHARPNAME,
chargeproct.ordernum chordernum
from ACCORECEIVE,V\_LOCATION\_LP\_LG\_DY LOCATIONS,chargeproct
where ACCORECEIVE.Org\_Id = LOCATIONS.Org\_Id
and ACCORECEIVE.Sub\_Org\_Id = LOCATIONS.Sub\_Org\_Id
and ACCORECEIVE.Fk_Locationid = LOCATIONS.Locationid
and ACCORECEIVE.Fk_Chargeproctid = chargeproct.chargeproctid(+)
and ACCORECEIVE.Wf_Status not in('作废')常规模式下,大数据要出交叉报表几乎很难,这里受 sql 效率慢、jvm 等的影响,一次如果把所有数据全部取出则必然极大可能内存溢出。另外,大数据表再有 join,即便能取,那取数速度上肯定也无法保证(sql join 的效率低),上面 sql 中能体现出所有问题。
解决方案:
1、为避免一次性取数内存溢出,可采用集算器游标 cursor 取数; –cursor
2、去除不需要字段及 join 字段。分析后发现,客户实际不需要 org_id、sub_org_id 的关联;
3、取数后可根据客户所出报表对应做数据处理,这里可 groups 处理一次分组汇总;–替代报表表达式 group
4、为摆脱 sql join 效率低问题,可将 join 放在集算器内处理,这里 ACCORECEIVE 与 V_LOCATION_LP_LG_DY 表(query 即可,数据不大)分开取数; –switch 连接
注:集算器中测试了两表 sql 中 join,时间大概需 5 分钟。
5、结合客户报表格式及所用的数据库表,可将上面 sql 中 chargeproct 表放到报表 sql 取数,因其仅体现显示值作用,且仅几十条数据。
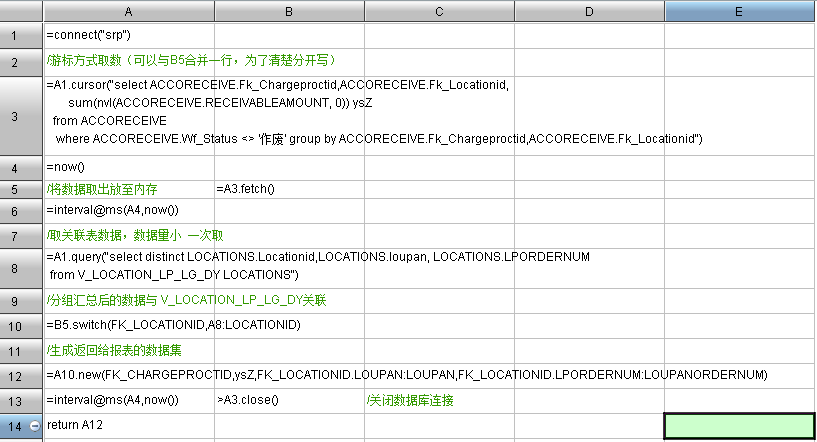
集算脚本:
注:代码有每一步的作用说明
关于“大数据交叉报表性能优化实例分析”就介绍到这了,更多相关内容可以搜索亿速云以前的文章,希望能够帮助大家答疑解惑,请多多支持亿速云网站!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





