一、hive产生背景
Apache Hive数据仓库软件可以使用SQL方便地阅读、编写和管理分布在分布式存储中的大型数据集。结构可以投射到已经存储的数据上。提供了一个命令行工具和JDBC驱动程序来将用户连接到Hive。
• 由Facebook开源,最初用于解决海量结构化的日志数据统计问题
• MapReduce编程的不便性
• HDFS上的文件缺少Schema(字段名,字段类型等)
二、Hive是什么
• 构建在Hadoop之上的数据仓库
• Hive定义了一种类SQL查询语言:HQL(类似SQL但不完全相同)
• 通常用于进行离线数据处理(采用MapReduce)
• 底层支持多种不同的执行引擎(Hive on MapReduce、Hive on Tez、Hive on Spark)
• 支持多种不同的压缩格式、存储格式以及自定义函数(压缩:GZIP、LZO、Snappy、BZIP2.. ; 存储:TextFile、SequenceFile、RCFile、ORC、Parquet ; UDF:自定义函数)
到底什么是Hive,我们先看看Hive官网Wiki是如何介绍Hive的(https://cwiki.apache.org/confluence/display/Hive/Home):

Apache Hive Apache Hive™ 数据仓库软件为分布式存储的大数据集上的读、写、管理提供很大方便,同时还可以用SQL语法在大数据集上查询。
1、是一种易于对数据实现提取、转换、加载的工具(ETL)的工具。可以理解为数据清洗分析展现。 2、它有一种将大量格式化数据强加上结构的机制。 3、它可以分析处理直接存储在hdfs中的数据或者是别的数据存储系统中的数据,如hbase。 4、查询的执行经由mapreduce完成。 5、hive可以使用存储过程 6、通过Apache YARN和Apache Slider实现亚秒级的查询检索。
三、hive的安装
1.hive的单机安装(使用derby做元数据存储)
• 安装包准备
将hive安装包 apache-hive-1.2.1-bin.tar.gz 上传到虚拟机/bigdata/下
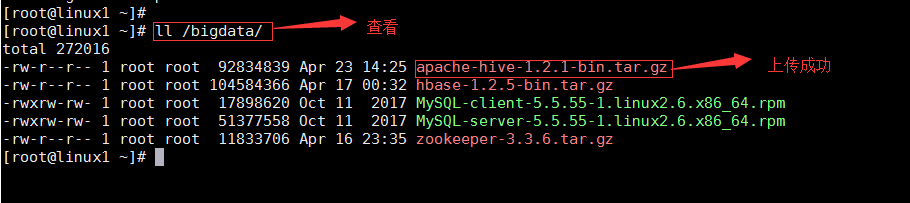
JDK安装包 jdk-8u151-x64.gz
集群的准备(linux1,linux2,linux3)
• hive的解压安装
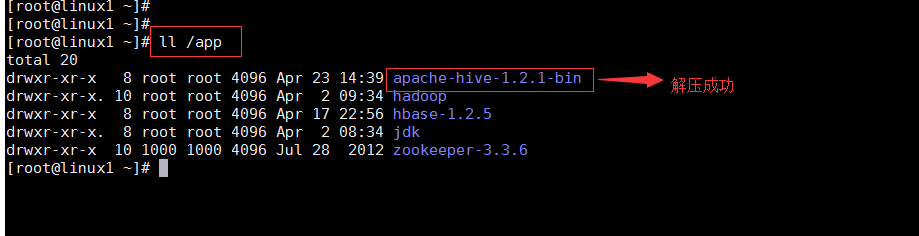
将上传的hive解压缩至虚拟机/app目录下
tar -zxvf /app/apache-hive-1.2.1-bin.tar.gz -C /app
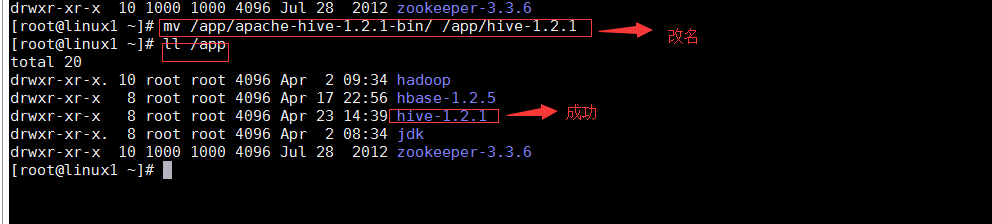
mv /app/apache-hive-1.2.1-bin/ /app/hive-1.2.1
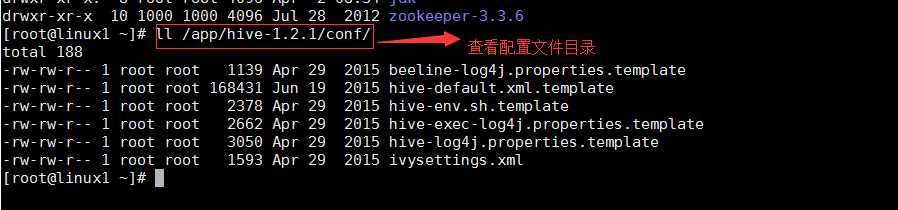
• 配置hive的配置文件
查看配置文件内容
拷贝配置文件hive-env.sh.template为hive-env.sh
cp /app/hive-1.2.1/conf/hive-env.sh.template /app/hive-1.2.1/conf/hive-env.sh
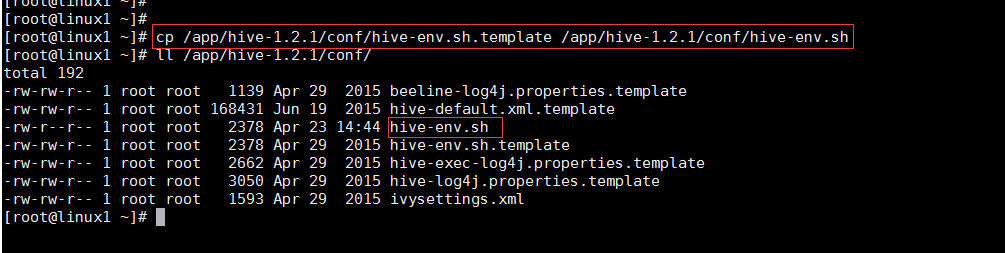
vim /app/hive-1.2.1/conf/hive-env.sh
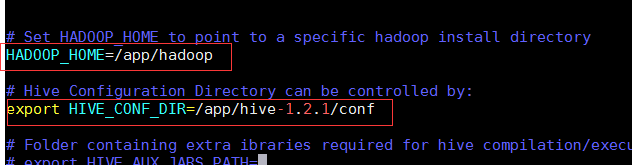
• 配置hive的环境变量
vim /etc/profile

source /etc/profile
which hive

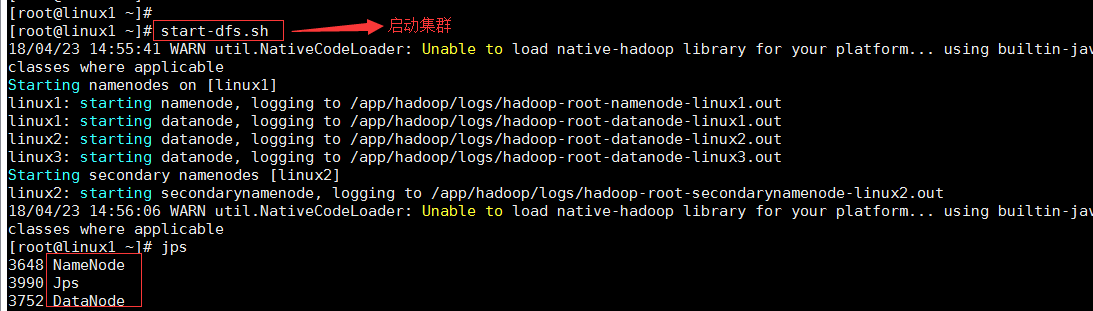
• 启动hadoop集群
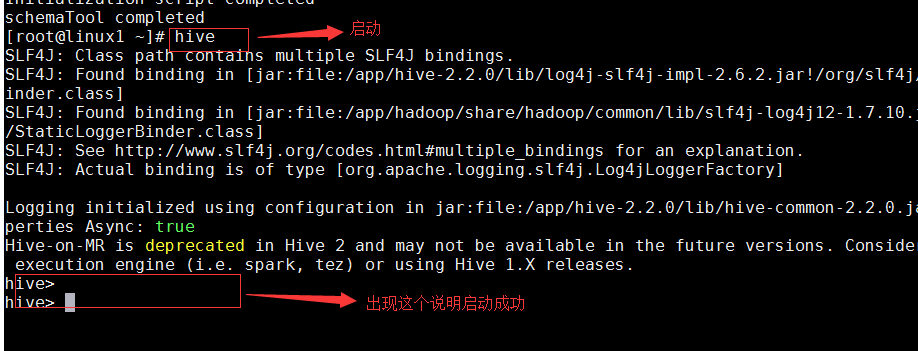
• 启动hive服务
hive
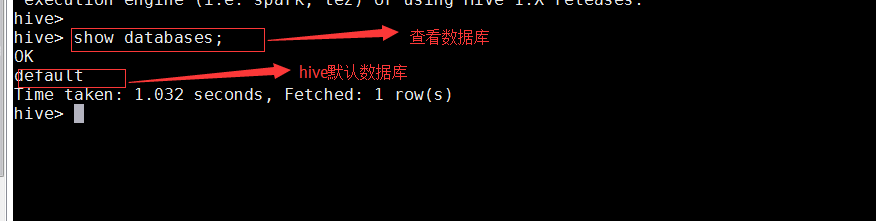
• 查看数据库
show databases;
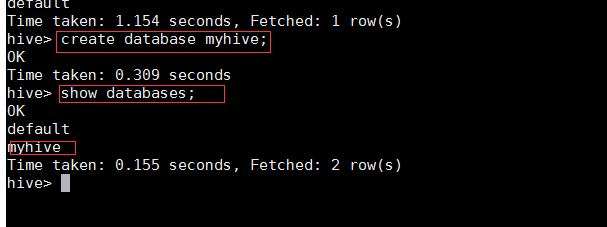
• 创建数据库
create database myhive;
show databases;
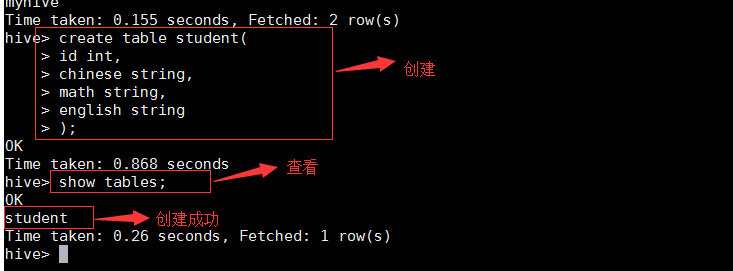
• 创建表
create table student(id int,chinese string,math string,English string);
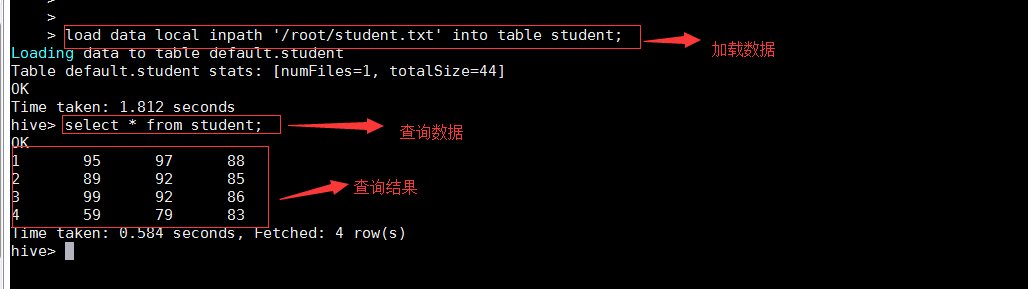
• 加载数据并查询
load data local inpath '/root/student.txt' into table student;
select * from student;
2.hive的独立安装模式(使用mysql做元数据存储)
• 安装MySQL服务器端和MySQL客户端,并启动mysql服务。
• 在linux1上为Hive建立相应的MySQL账户,并赋予足够的权限
create user 'hive' identified by '123456';
GRANT ALL PRIVILEGES ON *.* TO hive@'%' IDENTIFIED BY '123456' with grant option;
GRANT ALL PRIVILEGES ON *.* TO hive@'localhost' IDENTIFIED BY '123456' with grant option;
flush privileges
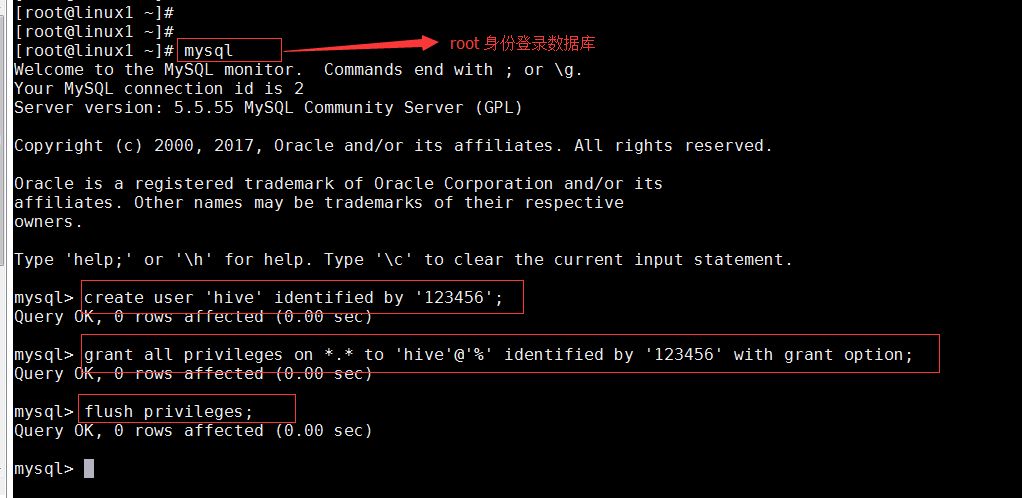
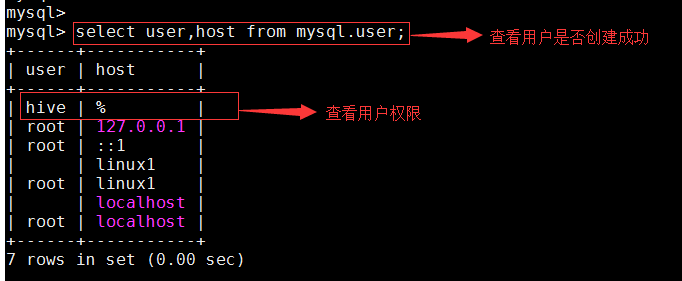
查看是否成功
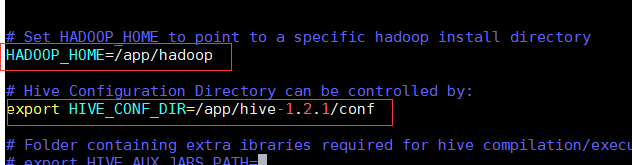
• 在内嵌模式下继续配置hive:hive-site.xml,hive-env.sh
配置hive-env.sh
配置hive-site.xml,拷贝/app/hive-1.2.1/conf下的hive-default.xml文件为hive-site.xml
cp /app/hive-1.2.1/conf/hive-default.xml.template /app/hive-1.2.1/conf/hive-site.xml
vim /app/hive-1.2.1/conf/hive-site.xml
• 拷贝数据驱动jar包到指定目录/app/hive-1.2.1/lib/下。没有驱动包会报错
• 使用命令行的方式启动hive服务,然后查看数据库,创建数据库名为heihei,查看集群web页面
查看集群web页面,可以看见在hdfs上生成了对应heihei数据库的文件目录
• 使用beeline访问hive
exit命令退出刚才的hive服务,在linux1上修改hadoop 配置文件 etc/hadoop/core-site.xml,加入如下配置项, 通过httpfs接口匿名的方式登录到hdfs文件系统。然后重新启动集群。
<property>
<name> hadoop.proxyuser.root.hosts </name>
<value> * </value>
</property>
<property>
<name> hadoop.proxyuser.root.groups </name>
<value> * </value>
</property>
使用命令hive --service hiveserver2 & 后台启动hive服务
hive --service hiveserver2 &
克隆窗口作为客户端连接,执行beeline脚本
连接服务端,这种方式使用了thrift服务,10000为默认的连接端口号
!connect jdbc:hive2://linux1:10000
验证连接的是不是我们刚才用命令行方式访问的hive服务
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/69916964/viewspace-2653699/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



