Kubernetes存储架构及插件使用是怎样的,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
一、Kubernetes 存储体系架构
首先以一个 Volume 的挂载例子来作为引入。
如下图所示,左边的 YAML 模板定义了一个 StatefulSet 的一个应用,其中定义了一个名为 disk-pvc 的 volume,挂载到 Pod 内部的目录是 /data。disk-pvc 是一个 PVC 类型的数据卷,其中定义了一个 storageClassName。
因此这个模板是一个典型的动态存储的模板。右图是数据卷挂载的过程,主要分为 6 步:

第一步:用户创建一个包含 PVC的 Pod;
第二步:PV Controller 会不断观察 ApiServer,如果它发现一个 PVC 已经创建完毕但仍然是未绑定的状态,它就会试图把一个 PV 和 PVC 绑定;
PV Controller 首先会在集群内部找到一个适合的 PV 进行绑定,如果未找到相应的 PV,就调用 Volume Plugin 去做 Provision。Provision 就是从远端上一个具体的存储介质创建一个 Volume,并且在集群中创建一个 PV 对象,然后将此 PV 和 PVC 进行绑定;
第三步:通过 Scheduler 完成一个调度功能;
我们知道,当一个 Pod 运行的时候,需要选择一个 Node,这个节点的选择就是由 Scheduler 来完成的。Scheduler 进行调度的时候会有多个参考量,比如 Pod 内部所定义的 nodeSelector、nodeAffinity 这些定义以及 Volume 中所定义的一些标签等。
我们可以在数据卷中添加一些标签,这样使用这个 pv 的 Pod 就会由于标签的限制,被调度器调度到期望的节点上。
第四步:如果有一个 Pod 调度到某个节点之后,它所定义的 PV 还没有被挂载(Attach),此时 AD Controller 就会调用 VolumePlugin,把远端的 Volume 挂载到目标节点中的设备上(如:/dev/vdb);
第五步:当 Volum Manager 发现一个 Pod 调度到自己的节点上并且 Volume 已经完成了挂载,它就会执行 mount 操作,将本地设备(也就是刚才得到的 /dev/vdb)挂载到 Pod 在节点上的一个子目录中。同时它也可能会做一些像格式化、是否挂载到 GlobalPath 等这样的附加操作。
第六步:绑定操作,就是将已经挂载到本地的 Volume 映射到容器中。
接下来,我们一起看一下 Kubernetes 的存储架构。
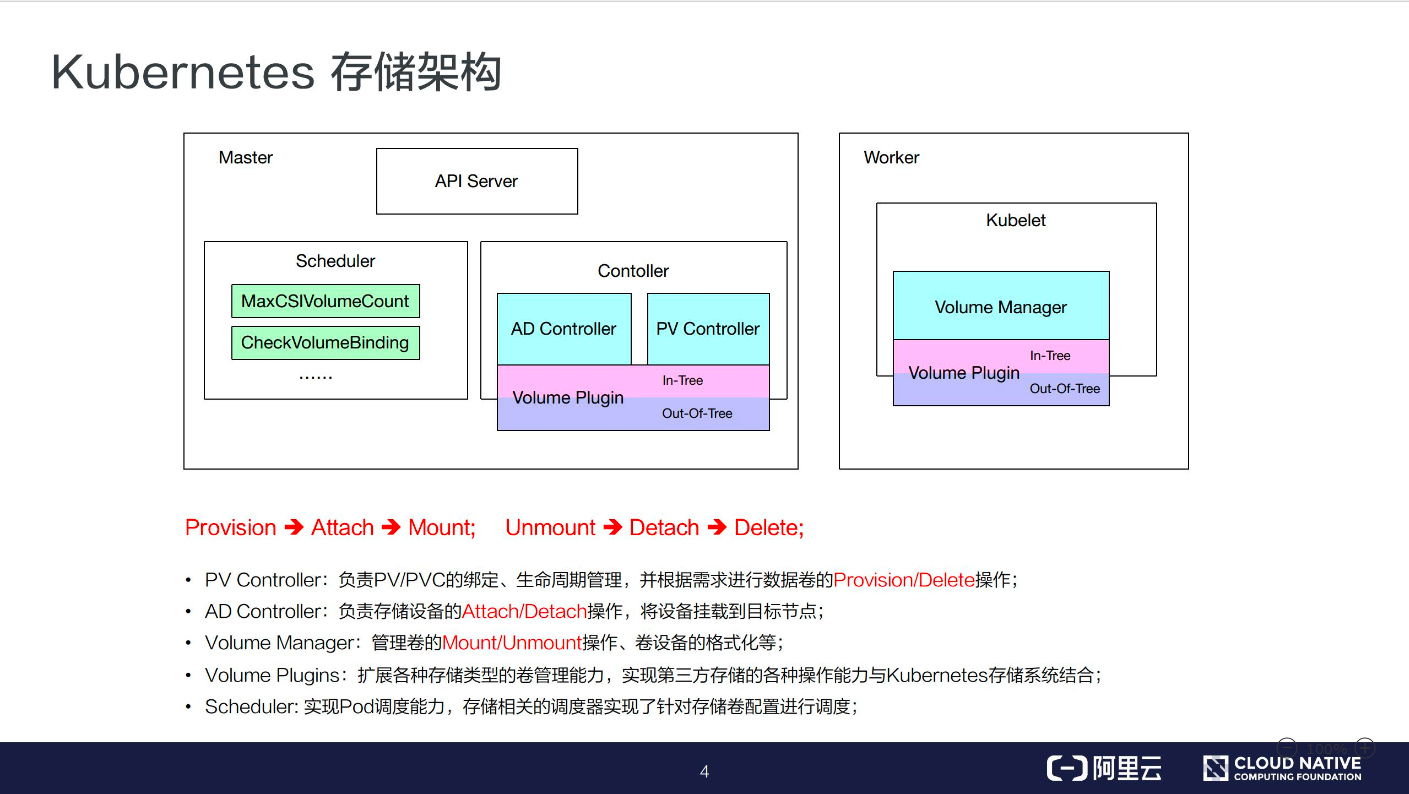
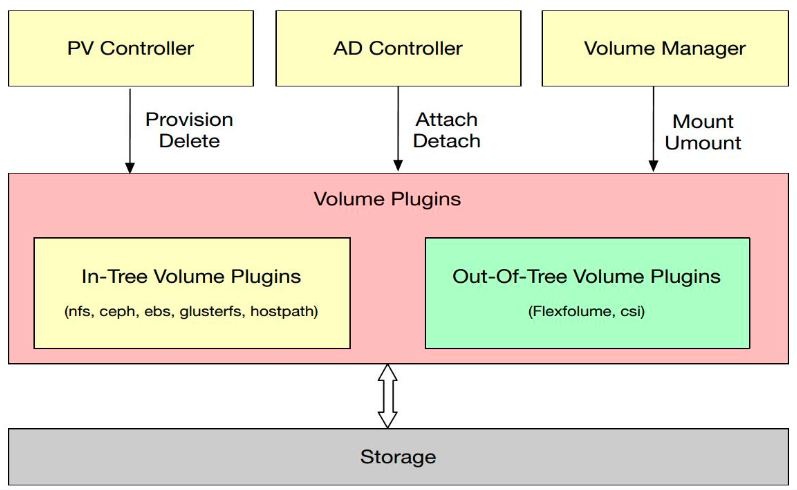
PV Controller: 负责 PV/PVC 的绑定、生命周期管理,并根据需求进行数据卷的 Provision/Delete 操作;
AD Controller:负责存储设备的 Attach/Detach 操作,将设备挂载到目标节点;
Volume Manager:管理卷的 Mount/Unmount 操作、卷设备的格式化以及挂载到一些公用目录上的操作;
Volume Plugins:它主要是对上面所有挂载功能的实现;
PV Controller、AD Controller、Volume Manager 主要是进行操作的调用,而具体操作则是由 Volume Plugins 实现的。
Scheduler:实现对 Pod 的调度能力,会根据一些存储相关的的定义去做一些存储相关的调度;
接下来,我们分别介绍上面这几部分的功能。
首先我们先来回顾一下几个基本概念:
Persistent Volume (PV): 持久化存储卷,详细定义了预挂载存储空间的各项参数;
例如,我们去挂载一个远端的 NAS 的时候,这个 NAS 的具体参数就要定义在 PV 中。一个 PV 是没有 NameSpace 限制的,它一般由 Admin 来创建与维护;
Persistent Volume Claim (PVC):持久化存储声明;
它是用户所使用的存储接口,对存储细节无感知,主要是定义一些基本存储的 Size、AccessMode 参数在里面,并且它是属于某个 NameSpace 内部的。
StorageClass:存储类;
一个动态存储卷会按照 StorageClass 所定义的模板来创建一个 PV,其中定义了创建模板所需要的一些参数和创建 PV 的一个 Provisioner(就是由谁去创建的)。
PV Controller 的主要任务就是完成 PV、PVC 的生命周期管理,比如创建、删除 PV 对象,负责 PV、PVC 的状态迁移;另一个任务就是绑定 PVC 与 PV 对象,一个 PVC 必须和一个 PV 绑定后才能被应用使用,它们是一一绑定的,一个 PV 只能被一个 PVC 绑定,反之亦然。
接下来,我们看一下一个 PV 的状态迁移图。
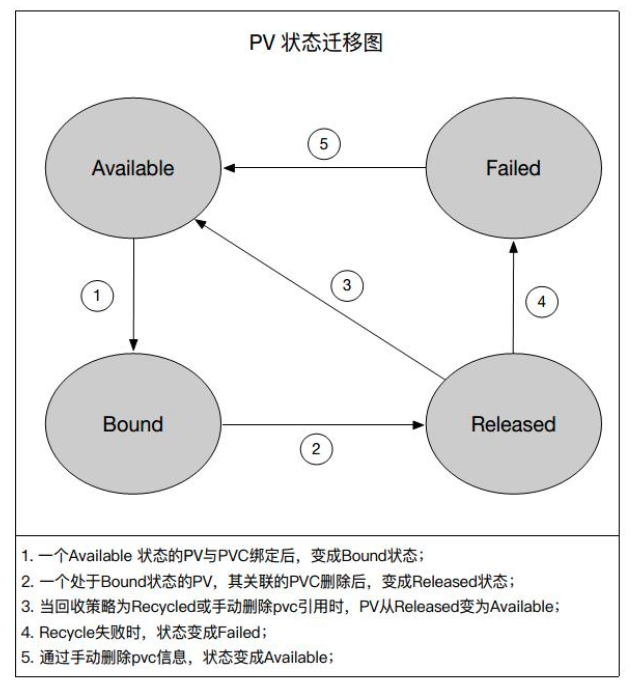
创建好一个 PV 以后,我们就处于一个 Available 的状态,当一个 PVC 和一个 PV 绑定的时候,这个 PV 就进入了 Bound 的状态,此时如果我们把 PVC 删掉,Bound 状态的 PV 就会进入 Released 的状态。
一个 Released 状态的 PV 会根据自己定义的 ReclaimPolicy 字段来决定自己是进入一个 Available 的状态还是进入一个 Deleted 的状态。如果 ReclaimPolicy 定义的是 “recycle” 类型,它会进入一个 Available 状态,如果转变失败,就会进入 Failed 的状态。
相对而言,PVC 的状态迁移图就比较简单。
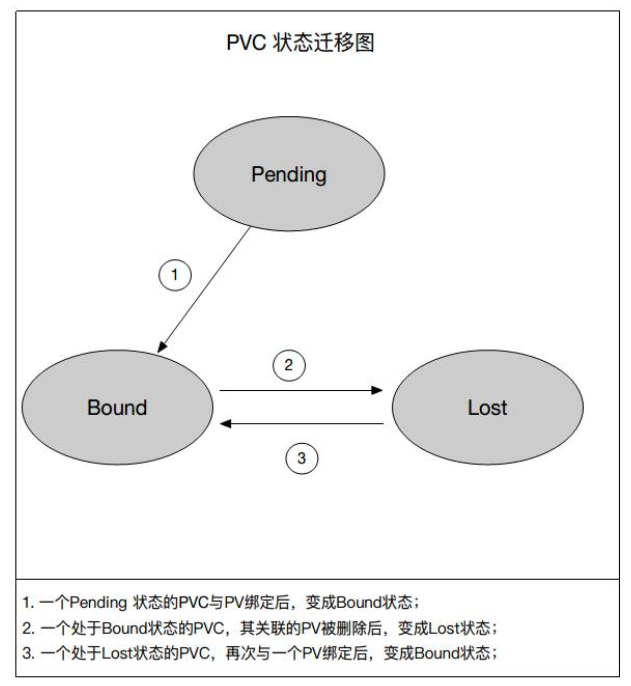
一个创建好的 PVC 会处于 Pending 状态,当一个 PVC 与 PV 绑定之后,PVC 就会进入 Bound 的状态,当一个 Bound 状态的 PVC 的 PV 被删掉之后,该 PVC 就会进入一个 Lost 的状态。对于一个 Lost 状态的 PVC,它的 PV 如果又被重新创建,并且重新与该 PVC 绑定之后,该 PVC 就会重新回到 Bound 状态。
下图是一个 PVC 去绑定 PV 时对 PV 筛选的一个流程图。就是说一个 PVC 去绑定一个 PV 的时候,应该选择一个什么样的 PV 进行绑定。
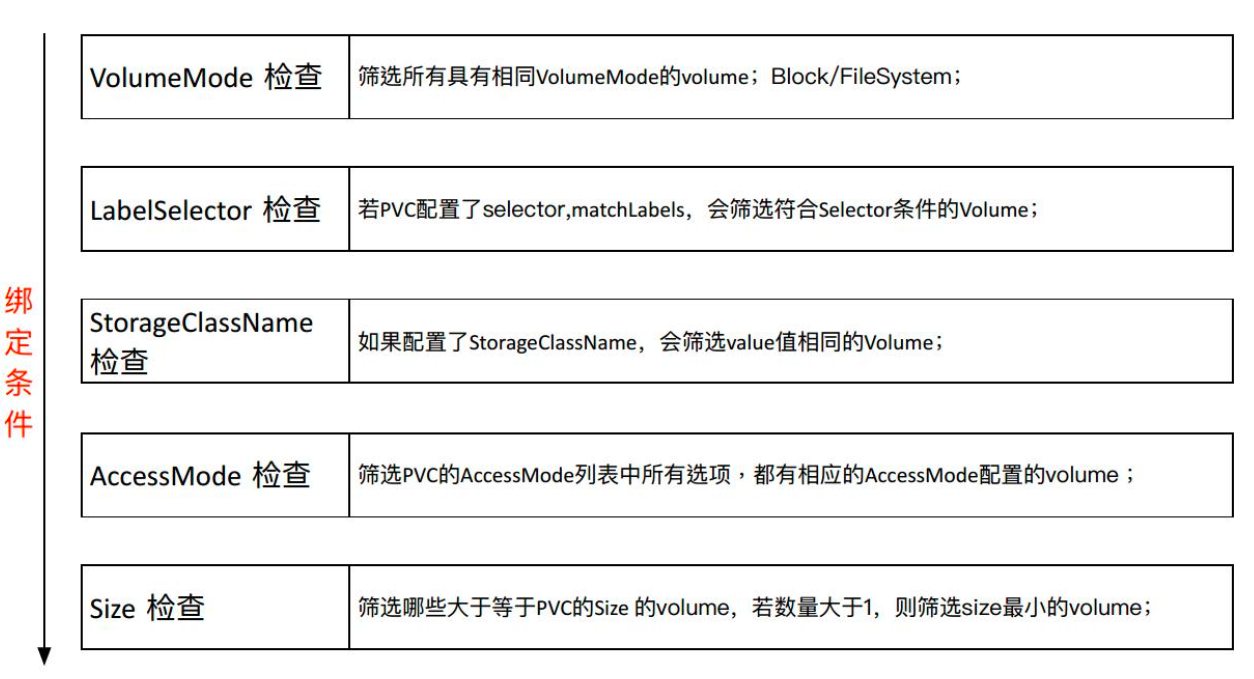
首先它会检查 VolumeMode 这个标签,PV 与 PVC 的 VolumeMode 标签必须相匹配。VolumeMode 主要定义的是我们这个数据卷是文件系统 (FileSystem) 类型还是一个块 (Block) 类型;
第二个部分是 LabelSelector。当 PVC 中定义了 LabelSelector 之后,我们就会选择那些有 Label 并且与 PVC 的 LabelSelector 相匹配的 PV 进行绑定;
第三个部分是 StorageClassName 的检查。如果 PVC 中定义了一个 StorageClassName,则必须有此相同类名的 PV 才可以被筛选中。
这里再具体解释一下 StorageClassName 这个标签,该标签的目的就是说,当一个 PVC 找不到相应的 PV 时,我们就会用该标签所指定的 StorageClass 去做一个动态创建 PV 的操作,同时它也是一个绑定条件,当存在一个满足该条件的 PV 时,就会直接使用现有的 PV,而不再去动态创建。
第四个部分是 AccessMode 检查。
AccessMode 就是平时我们在 PVC 中定义的如 “ReadWriteOnce”、”RearWriteMany” 这样的标签。该绑定条件就是要求 PVC 和 PV 必须有匹配的 AccessMode,即 PVC 所需求的 AccessMode 类型,PV 必须具有。
最后一个部分是 Size 的检查。
一个 PVC 的 Size 必须小于等于 PV 的 Size,这是因为 PVC 是一个声明的 Volume,实际的 Volume 必须要大于等于声明的 Volume,才能进行绑定。
接下来,我们看一个 PV Controller 的一个实现。
PV Controller 中主要有两个实现逻辑:一个是 ClaimWorker;一个是 VolumeWorker。
ClaimWorker 实现的是 PVC 的状态迁移。
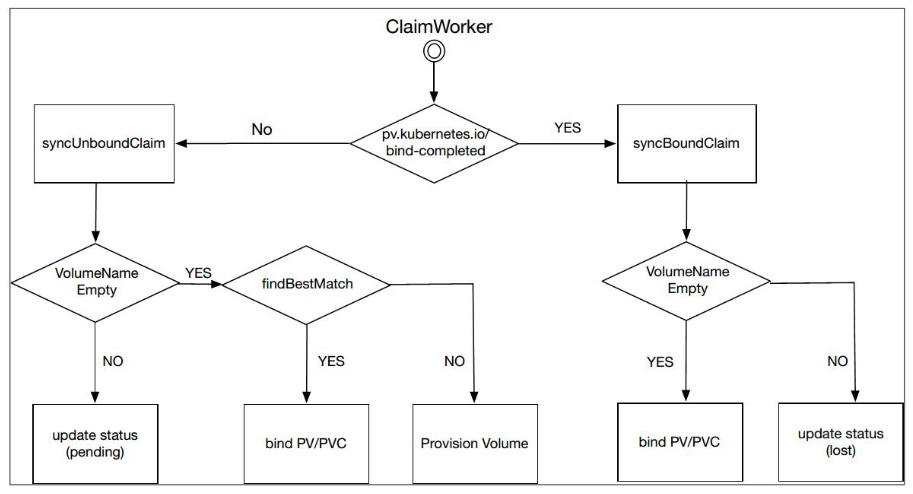
通过系统标签 “pv.kubernetes.io/bind-completed” 来标识一个 PVC 的状态。
如果该标签为 True,说明我们的 PVC 已经绑定完成,此时我们只需要去同步一些内部的状态;
如果该标签为 False,就说明我们的 PVC 处于未绑定状态。
这个时候就需要检查整个集群中的 PV 去进行筛选。通过 findBestMatch 就可以去筛选所有的 PV,也就是按照之前提到的五个绑定条件来进行筛选。如果筛选到 PV,就执行一个 Bound 操作,否则就去做一个 Provision 的操作,自己去创建一个 PV。
再看 VolumeWorker 的操作。它实现的则是 PV 的状态迁移。
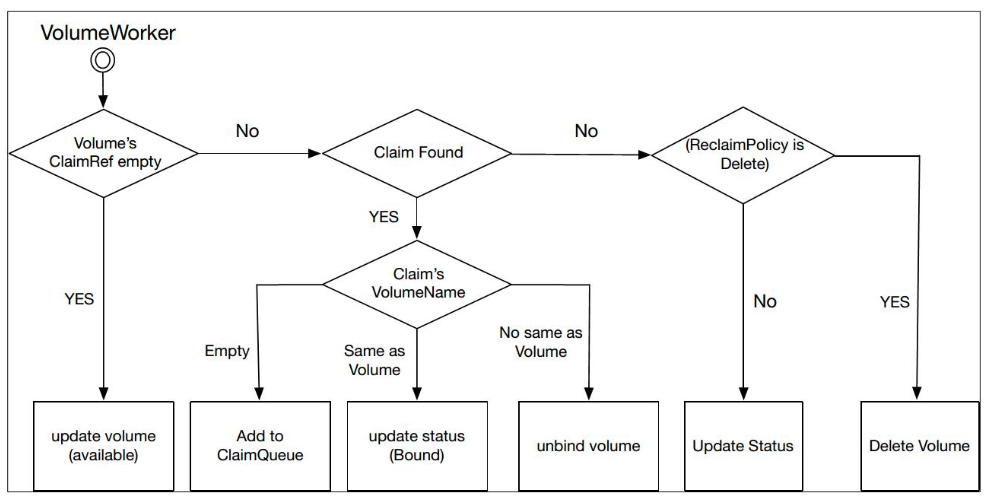
通过 PV 中的 ClaimRef 标签来进行判断,如果该标签为空,就说明该 PV 是一个 Available 的状态,此时只需要做一个同步就可以了;如果该标签非空,这个值是 PVC 的一个值,我们就会去集群中查找对应的 PVC。如果存在该 PVC,就说明该 PV 处于一个 Bound 的状态,此时会做一些相应的状态同步;如果找不到该 PVC,就说明该 PV 处于一个绑定过的状态,相应的 PVC 已经被删掉了,这时 PV 就处于一个 Released 的状态。此时再根据 ReclaimPolicy 是否是 Delete 来决定是删掉还是只做一些状态的同步。
以上就是 PV Controller 的简要实现逻辑。
AD Controller 是 Attach/Detach Controller 的一个简称。
它有两个核心对象,即 DesiredStateofWorld 和 ActualStateOfWorld。
DesiredStateofWorld 是集群中预期要达到的数据卷的挂载状态;
ActualStateOfWorld 则是集群内部实际存在的数据卷挂载状态。
它有两个核心逻辑,desiredStateOfWorldPopulator 和 Reconcile。
desiredStateOfWorldPopulator 主要是用来同步集群的一些数据以及 DSW、ASW 数据的更新,它会把集群里面,比如说我们创建一个新的 PVC、创建一个新的 Pod 的时候,我们会把这些数据的状态同步到 DSW 中;
Reconcile 则会根据 DSW 和 ASW 对象的状态做状态同步。它会把 ASW 状态变成 DSW 状态,在这个状态的转变过程中,它会去执行 Attach、Detach 等操作。
下面这个表分别给出了 desiredStateOfWorld 以及 actualStateOfWorld 对象的一个具体例子。
desiredStateOfWorld 会对每一个 Worker 进行定义,包括 Worker 所包含的 Volume 以及一些试图挂载的信息;
actualStateOfWorl 会把所有的 Volume 进行一次定义,包括每一个 Volume 期望挂载到哪个节点上、挂载的状态是什么样子的等等。

下图是 AD Controller 实现的逻辑框图。
从中我们可以看到,AD Controller 中有很多 Informer,Informer 会把集群中的 Pod 状态、PV 状态、Node 状态、PVC 状态同步到本地。
在初始化的时候会调用 populateDesireStateofWorld 以及 populateActualStateofWorld 将 desireStateofWorld、actualStateofWorld 两个对象进行初始化。
在执行的时候,通过 desiredStateOfWorldPopulator 进行数据同步,即把集群中的数据状态同步到 desireStateofWorld 中。reconciler 则通过轮询的方式把 actualStateofWorld 和 desireStateofWorld 这两个对象进行数据同步,在同步的时候,会通过调用 Volume Plugin 进行 attach 和 detach 操作,同时它也会调用 nodeStatusUpdater 对 Node 的状态进行更新。
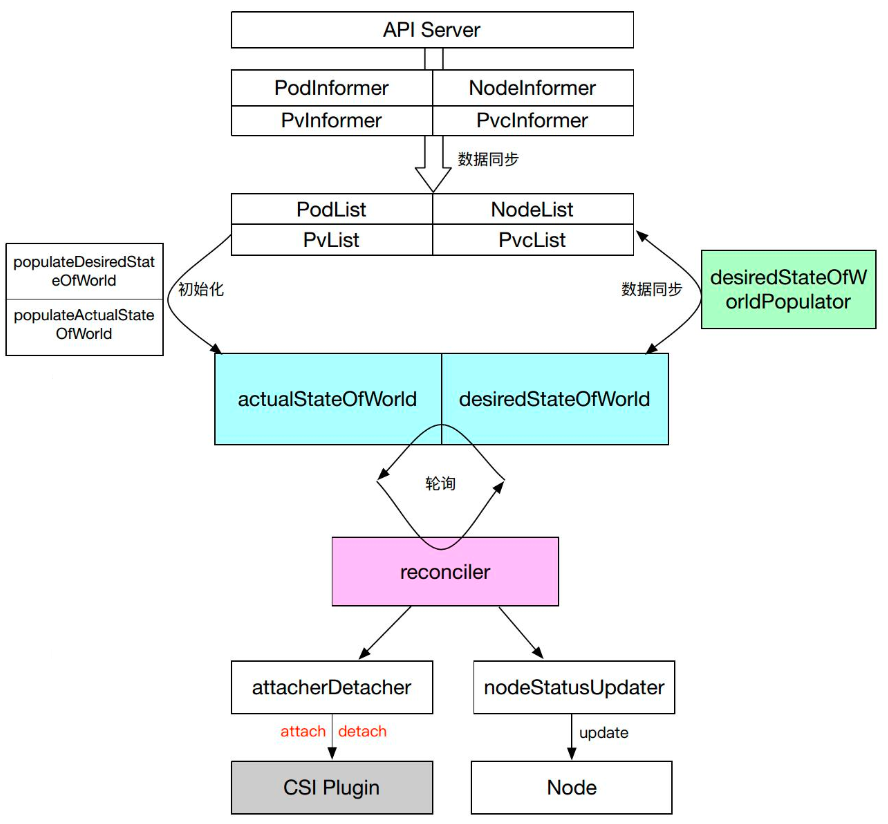
以上就是 AD Controller 的简要实现逻辑。
Volume Manager 实际上是 Kubelet 中一部分,是 Kubelet 中众多 Manager 的一个。它主要是用来做本节点 Volume 的 Attach/Detach/Mount/Unmount 操作。
它和 AD Controller 一样包含有 desireStateofWorld 以及 actualStateofWorld,同时还有一个 volumePluginManager 对象,主要进行节点上插件的管理。在核心逻辑上和 AD Controller 也类似,通过 desiredStateOfWorldPopulator 进行数据的同步以及通过 Reconciler 进行接口的调用。
这里我们需要讲一下 Attach/Detach 这两个操作:
之前我们提到 AD Controller 也会做 Attach/Detach 操作,所以到底是由谁来做呢?我们可以通过 “—enable-controller-attach-detach” 标签进行定义,如果它为 True,则由 AD Controller 来控制;若为 False,就由 Volume Manager 来做。
它是 Kubelet 的一个标签,只能定义某个节点的行为,所以如果假设一个有 10 个节点的集群,它有 5 个节点定义该标签为 False,说明这 5 个节点是由节点上的 Kubelet 来做挂载,而其它 5 个节点是由 AD Controller 来做挂载。
下图是 Volume Manager 实现逻辑图。
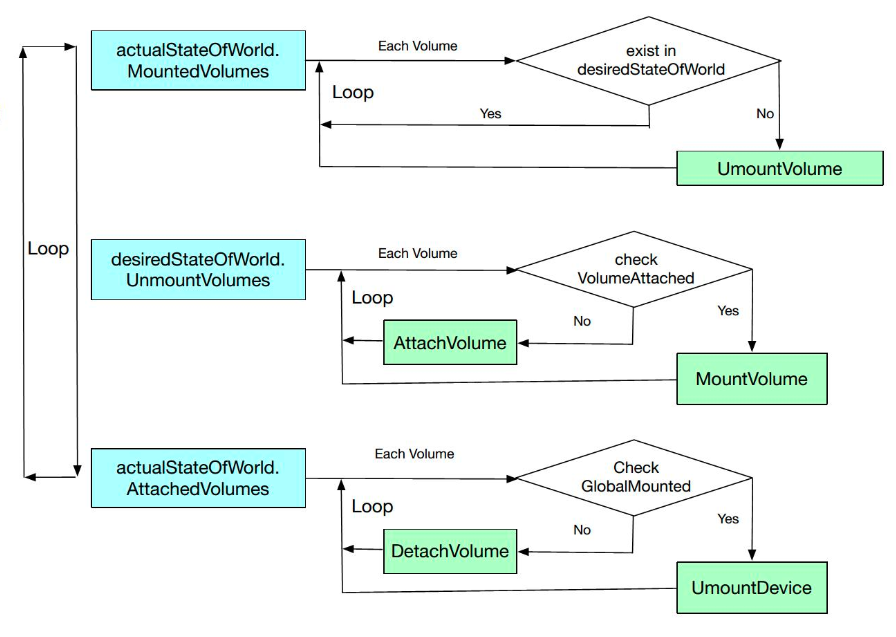
我们可以看到,最外层是一个循环,内部则是根据不同的对象,包括 desireStateofWorld, actualStateofWorld 的不同对象做一个轮询。
例如,对 actualStateofWorld 中的 MountedVolumes 对象做轮询,对其中的某一个 Volume,如果它同时存在于 desireStateofWorld,这就说明实际的和期望的 Volume 均是处于挂载状态,因此我们不会做任何处理。如果它不存在于 desireStateofWorld,说明期望状态中该 Volume 应该处于 Umounted 状态,就执行 UnmountVolume,将其状态转变为 desireStateofWorld 中相同的状态。
所以我们可以看到:实际上,该过程就是根据 desireStateofWorld 和 actualStateofWorld 的对比,再调用底层的接口来执行相应的操作,下面的 desireStateofWorld.UnmountVolumes 和 actualStateofWorld.AttachedVolumes 的操作也是同样的道理。
我们之前提到的 PV Controller、AD Controller 以及 Volume Manager 其实都是通过调用 Volume Plugin 提供的接口,比如 Provision、Delete、Attach、Detach 等去做一些 PV、PVC 的管理。而这些接口的具体实现逻辑是放在 VolumePlugin 中的
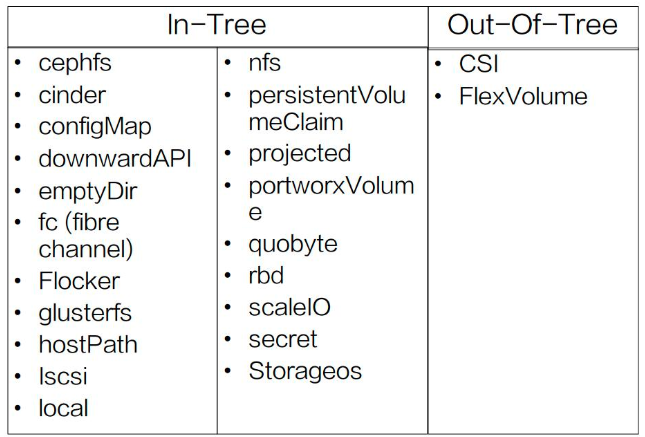
根据源码的位置可将 Volume Plugins 分为 In-Tree 和 Out-of-Tree 两类:
In-Tree 表示源码是放在 Kubernetes 内部的,和 Kubernetes 一起发布、管理与迭代,缺点及时迭代速度慢、灵活性差;
Out-of-Tree 类的 Volume Plugins 的代码独立于 Kubernetes,它是由存储商提供实现的,目前主要有 Flexvolume 和 CSI 两种实现机制,可以根据存储类型实现不同的存储插件。所以我们比较推崇 Out-of-Tree 这种实现逻辑。
从位置上我们可以看到,Volume Plugins 实际上就是 PV Controller、AD Controller 以及 Volume Manager 所调用的一个库,分为 In-Tree 和 Out-of-Tree 两类 Plugins。它通过这些实现来调用远端的存储,比如说挂载一个 NAS 的操作 “mount -t nfs *“,该命令其实就是在 Volume Plugins 中实现的,它会去调用远程的一个存储挂载到本地。
从类型上来看,Volume Plugins 可以分为很多种。In-Tree 中就包含了 几十种常见的存储实现,但一些公司的自己定义私有类型,有自己的 API 和参数,公共存储插件是无法支持的,这时就需要 Out-of-Tree 类的存储实现,比如 CSI、FlexVolume。
Volume Plugins 的具体实现会放到后面去讲。这里主要看一下 Volume Plugins 的插件管理。
Kubernetes会在 PV Controller、AD Controller 以及 Volume Manager 中来做插件管理。通过 VolumePlguinMg 对象进行管理。主要包含 Plugins 和 Prober 两个数据结构。
Plugins 主要是用来保存 Plugins 列表的一个对象,而 Prober 是一个探针,用于发现新的 Plugin,比如 FlexVolume、CSI 是扩展的一种插件,它们是动态创建和生成的,所以一开始我们是无法预知的,因此需要一个探针来发现新的 Plugin。
下图是插件管理的整个过程。
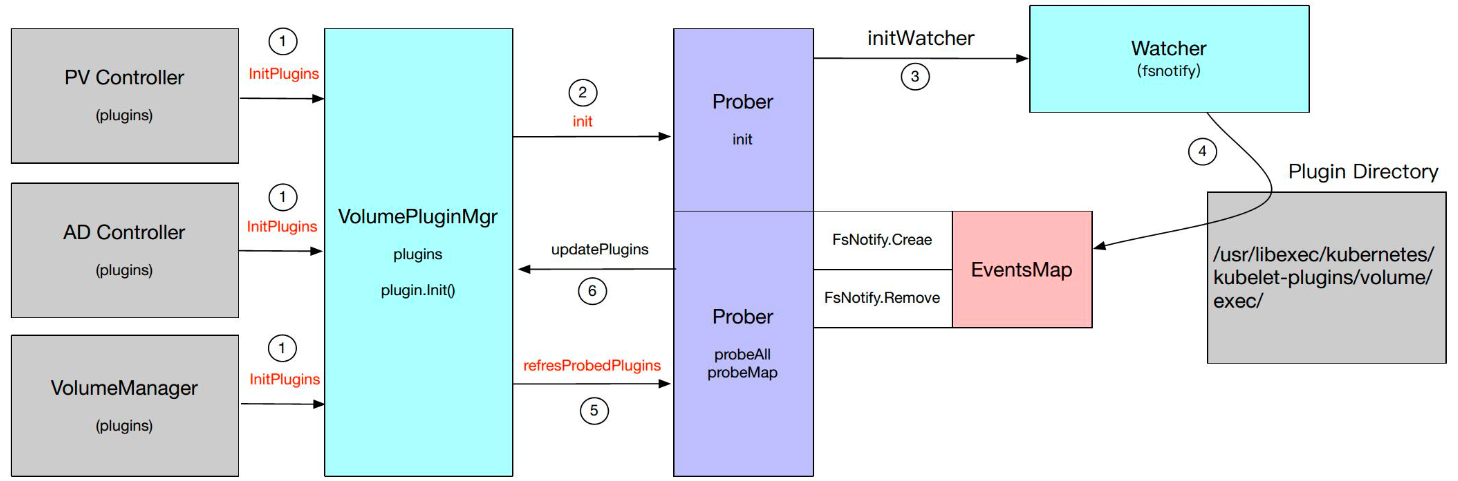
PV Controller、AD Controller 以及 Volume Manager 在启动的时候会执行一个 InitPlugins 方法来对 VolumePluginsMgr 做一些初始化。
它首先会将所有 In-Tree 的 Plugins 加入到我们的插件列表中。同时会调用 Prober 的 init 方法,该方法会首先调用一个 InitWatcher,它会时刻观察着某一个目录 (比如图中的 /usr/libexec/kubernetes/kubelet-plugins/volume/exec/),当这个目录每生成一个新文件的时候,也就是创建了一个新的 Plugins,此时就会生成一个新的 FsNotify.Create 事件,并将其加入到 EventsMap 中;同理,如果删除了一个文件,就生成一个 FsNotify.Remove 事件加入到 EventsMap 中。
当上层调用 refreshProbedPlugins 时,Prober 就会把这些事件进行一个更新,如果是 Create,就将其添加到插件列表;如果是 Remove,就从插件列表中删除一个插件。
以上就是 Volume Plugins 的插件管理机制。
我们之前说到 Pod 必须被调度到某个 Worker 上才能去运行。在调度 Pod 时,我们会使用不同的调度器来进行筛选,其中有一些与 Volume 相关的调度器。例如 VolumeZonePredicate、VolumeBindingPredicate、CSIMaxVolumLimitPredicate 等。
VolumeZonePredicate 会检查 PV 中的 Label,比如 failure-domain.beta.kubernetes.io/zone 标签,如果该标签定义了 zone 的信息,VolumeZonePredicate 就会做相应的判断,即必须符合相应的 zone 的节点才能被调度。
比如下图左侧的例子,定义了一个 label 的 zone 为 cn-shenzhen-a。右侧的 PV 则定义了一个 nodeAffinity,其中定义了 PV 所期望的节点的 Label,该 Label 是通过 VolumeBindingPredicate 进行筛选的。

存储卷具体调度信息的实现可以参考《 从零开始入门 K8s | 应用存储和持久化数据卷:存储快照与拓扑调度》,这里会有一个更加详细的介绍。
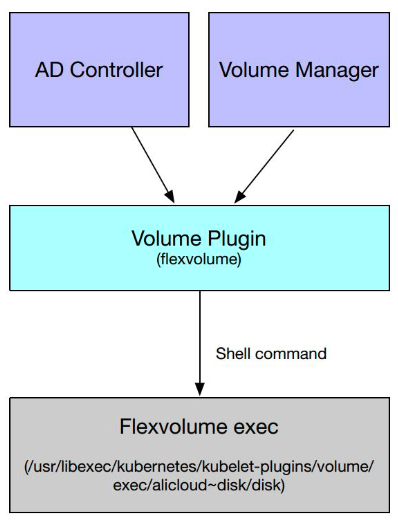
Flexvolume 是 Volume Plugins 的一个扩展,主要实现 Attach/Detach/Mount/Unmount 这些接口。我们知道这些功能本是由 Volume Plugins 实现的,但是对于某些存储类型,我们需要将其扩展到 Volume Plugins 以外,所以我们需要把接口的具体实现放到外面。
在下图中我们可以看到,Volume Plugins 其实包含了一部分 Flexvolume 的实现代码,但这部分代码其实只有一个 “Proxy”的功能。
比如当 AD Controller 调用插件的一个 Attach 时,它首先会调用 Volume Plugins 中 Flexvolume 的 Attach 接口,但这个接口只是把调用转到相应的 Flexvolume 的Out-Of-Tree实现上。
Flexvolume是可被 Kubelet 驱动的可执行文件,每一次调用相当于执行一次 shell 的 ls 这样的脚本,都是可执行文件的命令行调用,因此它不是一个常驻内存的守护进程。
Flexvolume 的 Stdout 作为 Kubelet 调用的返回结果,这个结果需要是 JSON 格式。
Flexvolume默认的存放地址为 “/usr/libexec/kubernetes/kubelet-plugins/volume/exec/alicloud~disk/disk”。
下面是一个命令格式和调用的实例。

Flexvolum 包含以下接口:
init: 主要做一些初始化的操作,比如部署插件、更新插件的时候做 init 操作,返回的时候会返回刚才我们所说的 DriveCapabilities 类型的数据结构,用来说明我们的 Flexvolume 插件有哪些功能;
GetVolumeName: 返回插件名;
Attach: 挂载功能的实现。根据 —enable-controller-attach-detach 标签来决定是由 AD Controller 还是 Kubelet 来发起挂载操作;
WaitforAttach: Attach 经常是异步操作,因此需要等待挂载完成,才能需要进行下面的操作;
MountDevice:它是 mount 的一部分。这里我们将 mount 分为 MountDevice 和 SetUp 两部分,MountDevice 主要做一些简单的预处理工作,比如将设备格式化、挂载到 GlobalMount 目录中等;
GetPath:获取每个 Pod 对应的本地挂载目录;
Setup:使用 Bind 方式将 GlobalPath 中的设备挂载到 Pod 的本地目录;
TearDown、UnmountDevice、Detach 实现的是上面一些借口的逆过程;
ExpandVolumeDevice:扩容存储卷,由 Expand Controller 发起调用;
NodeExpand: 扩容文件系统,由 Kubelet 发起调用。
上面这些接口不一定需要全部实现,如果某个接口没有实现的话,可以将返回结果定义成:
{
"status": "Not supported",
"message": "error message"
}告诉调用者没有实现这个接口。此外,Volume Plugins 中的 Flexvolume 接口除了作为一个 Proxy 外,它也提供了一些默认实现,比如 Mount 操作。所以如果你的 Flexvolume 中没有定义该接口,该默认实现就会被调用。
在定义 PV 时可以通过 secretRef 字段来定义一些 secret 的功能。比如挂载时所需的用户名和密码,就可以通过 secretRef 传入。
从挂载流程和卸载流程两个方向来分析 Flexvolume 的挂载过程。
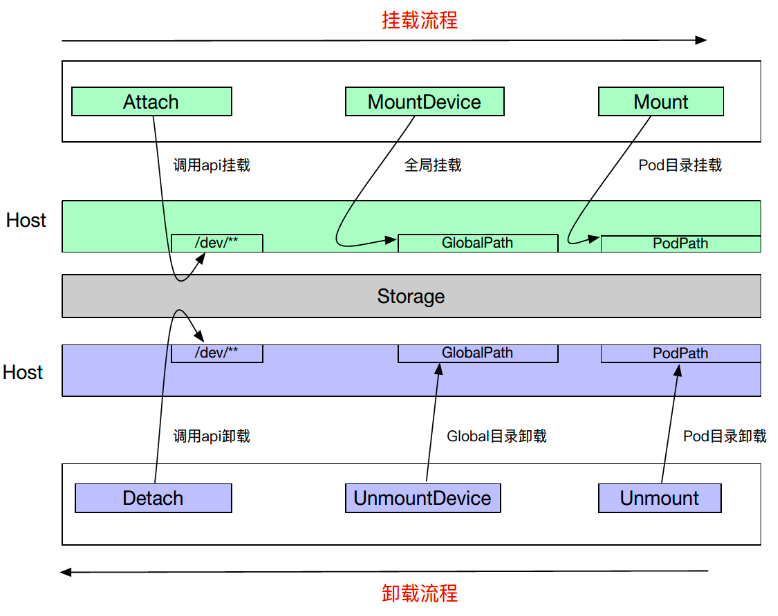
我们首先看 Attach 操作,它调用了一个远端的 API 把我们的 Storage 挂载到目标节点中的某个设备上去。然后通过 MountDevice 将本地设备挂载到 GlobalPath 中,同时也会做一些格式化这样的操作。Mount 操作(SetUp),它会把 GlobalPath 挂载 PodPath 中,PodPath 就是 Pod 启动时所映射的一个目录。
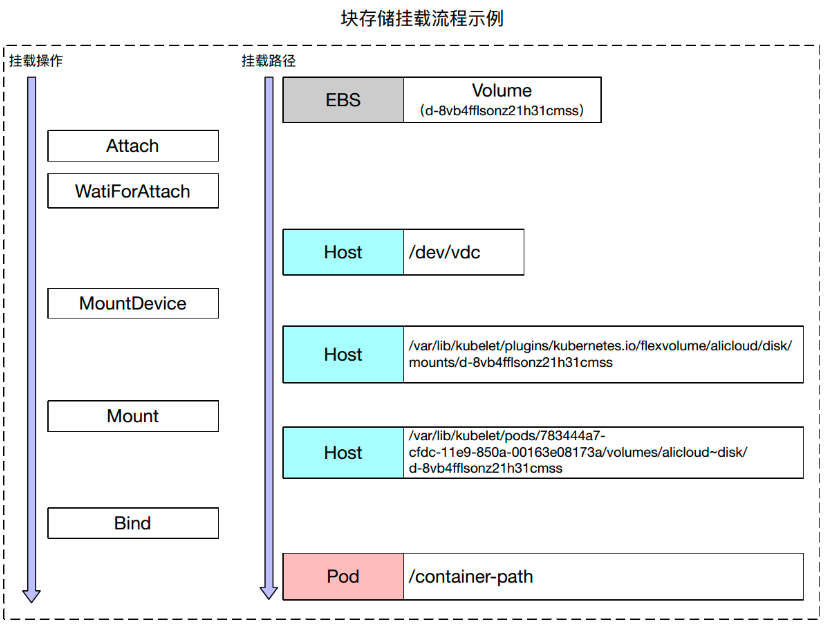
下图给出了一个例子,比如我们一个云盘,其 Volume ID 为 d-8vb4fflsonz21h41cmss,在执行完 Attach 和 WaitForAttach 操作之后,就会将其挂载到目标节点上的 /dec/vdc 设备中。执行 MountDevice 之后,就会把上述设备格式化,挂载到一个本地的 GlobalPath 中。而执行完 Mount 之后,就会将 GlobalPath 映射到 Pod 相关的一个子目录中。最后执行 Bind 操作,将我们的本地目录映射到容器中。这样完成一次挂载过程。
卸载流程就是一个逆过程。上述过程描述的是一个块设备的挂载过程,对于文件存储类型,就无需 Attach、MountDevice操作,只需要 Mount 操作,因此文件系统的 Flexvolume 实现较为简单,只需要 Mount 和 Unmount 过程即可。
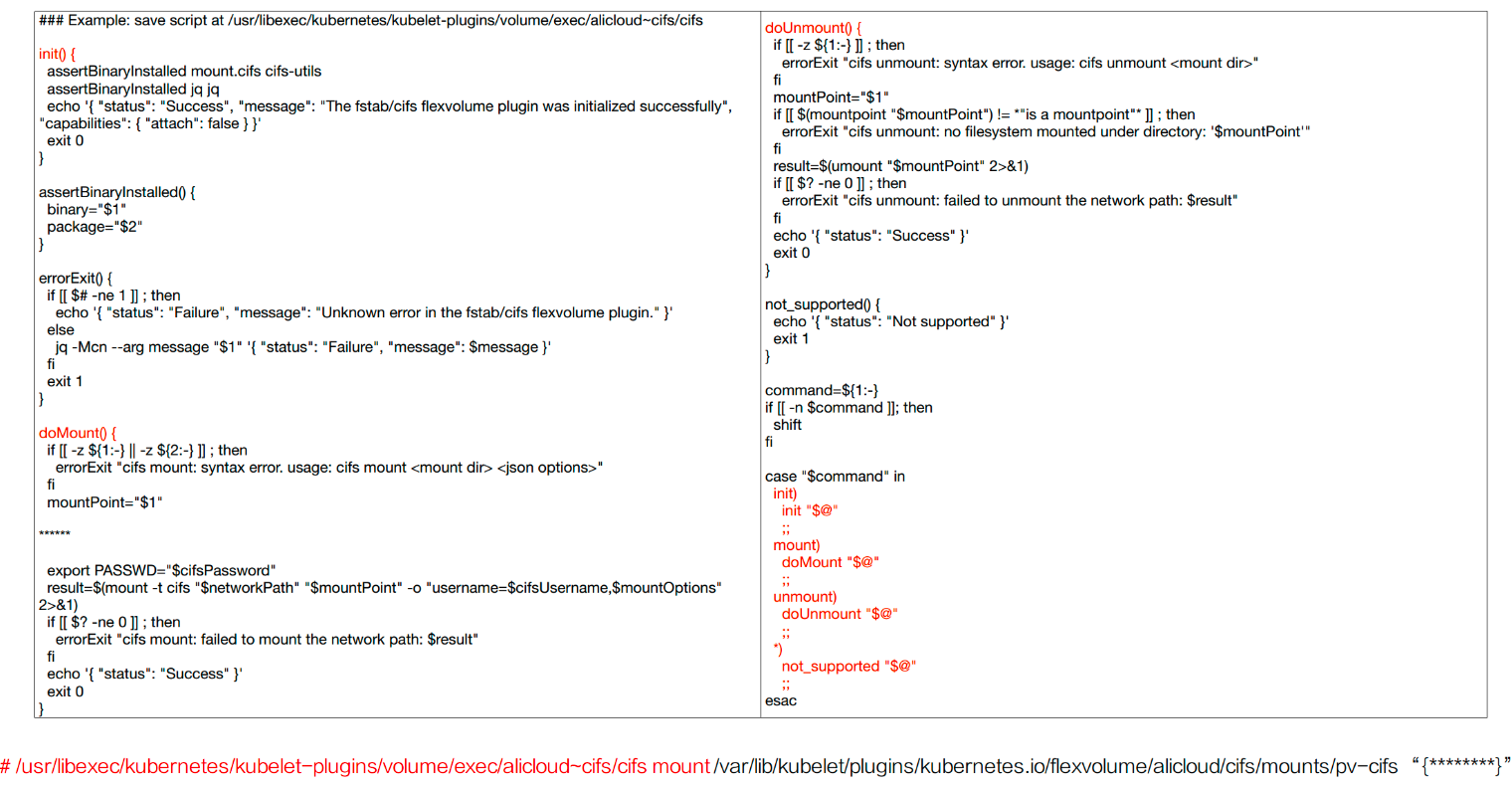
其中主要实现的是 init()、doMount()、doUnmount() 方法。在执行该脚本的时候对传入的参数进行判断来决定执行哪一个命令。
在 Github 上还有很多 Flexvolume 的示例,大家可以自行参考查阅。阿里云提供了一个
Flexvolume 的实现,有兴趣的可以参考一下。
下图给出了一个 Flexvolume 类型的 PV 模板。它和其它模板实际上没有什么区别,只不过类型被定义为 flexVolume 类型。flexVolume 中定义了 driver、fsType、options。
driver 定义的是我们实现的某种驱动,比如图中的是 aliclound/disk,也可以是 aliclound/nas 等;
fsType 定义的是文件系统类型,比如 “ext4”;
options 包含了一些具体的参数,比如定义云盘的 id 等。
我们也可以像其它类型一样,通过 selector 中的 matchLabels 定义一些筛选条件。同样也可以定义一些相应的调度信息,比如定义 zone 为 cn-shenzhen-a。

下面是一个具体的运行结果。在 Pod 内部我们挂载了一个云盘,其所在本地设备为 /dev/vdb。通过 mount | grep disk 我们可以看到相应的挂载目录,首先它会将 /dev/vdb 挂载到 GlobalPath 中;其次会将 GlobalPath 通过 mount 命令挂载到一个 Pod 所定义的本地子目录中去;最后会把该本地子目录映射到 /data 上。

和 Flexvolume 类似,CSI 也是为第三方存储提供数据卷实现的抽象接口。
有了 Flexvolume,为何还要 CSI 呢?
Flexvolume 只是给 kubernetes 这一个编排系统来使用的,而 CSI 可以满足不同编排系统的需求,比如 Mesos,Swarm。
其次 CSI 是容器化部署,可以减少环境依赖,增强安全性,丰富插件的功能。我们知道,Flexvolume 是在 host 空间一个二进制文件,执行 Flexvolum 时相当于执行了本地的一个 shell 命令,这使得我们在安装 Flexvolume 的时候需要同时安装某些依赖,而这些依赖可能会对客户的应用产生一些影响。因此在安全性上、环境依赖上,就会有一个不好的影响。
同时对于丰富插件功能这一点,我们在 Kubernetes 生态中实现 operator 的时候,经常会通过 RBAC 这种方式去调用 Kubernetes 的一些接口来实现某些功能,而这些功能必须要在容器内部实现,因此像 Flexvolume 这种环境,由于它是 host 空间中的二进制程序,就没法实现这些功能。而 CSI 这种容器化部署的方式,可以通过 RBAC 的方式来实现这些功能。
CSI 主要包含两个部分:CSI Controller Server 与 CSI Node Server。
Controller Server 是控制端的功能,主要实现创建、删除、挂载、卸载等功能;
Node Server 主要实现的是节点上的 mount、Unmount 功能。
下图给出了 CSI 接口通信的描述。CSI Controller Server 和 External CSI SideCar 是通过 Unix Socket 来进行通信的,CSI Node Server 和 Kubelet 也是通过 Unix Socket 来通信,之后我们会讲一下 External CSI SiderCar 的具体概念。
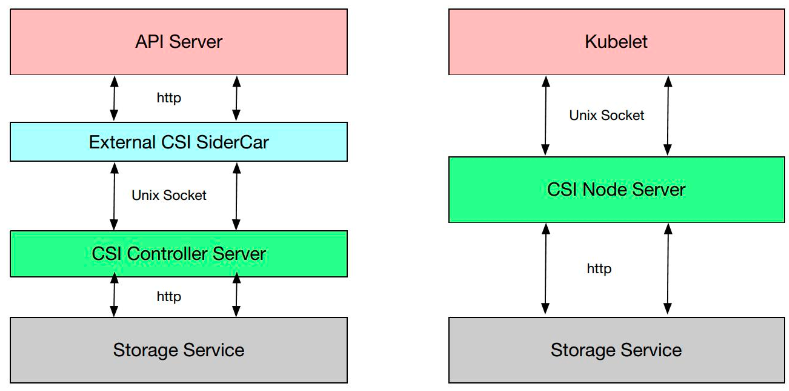
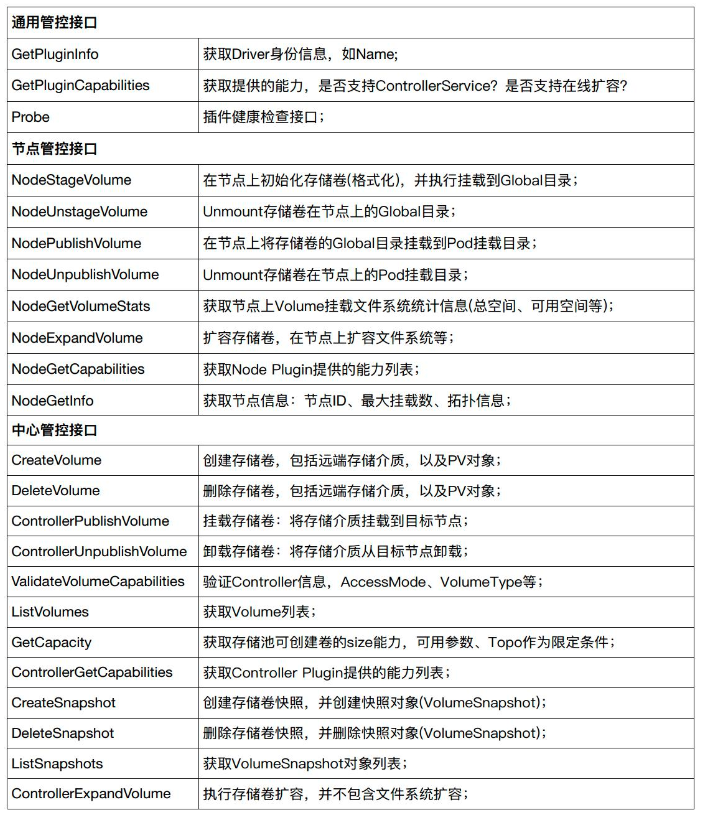
下图给出了 CSI 的接口。主要分为三类:通用管控接口、节点管控接口、中心管控接口。
通用管控接口主要返回 CSI 的一些通用信息,像插件的名字、Driver 的身份信息、插件所提供的能力等;
节点管控接口的 NodeStageVolume 和 NodeUnstageVolume 就相当于 Flexvolume 中的 MountDevice 和 UnmountDevice。NodePublishVolume 和 NodeUnpublishVolume 就相当于 SetUp 和 TearDown 接口;
中心管控接口的 CreateVolume 和 DeleteVolume 就是我们的 Provision 和 Delete 存储卷的一个接口,ControllerPublishVolume 和 ControllerUnPublishVolume 则分别是 Attach 和 Detach 的接口。
CSI 是通过 CRD 的形式实现的,所以 CSI 引入了这么几个对象类型:VolumeAttachment、CSINode、CSIDriver 以及 CSI Controller Server 与 CSI Node Server 的一个实现。
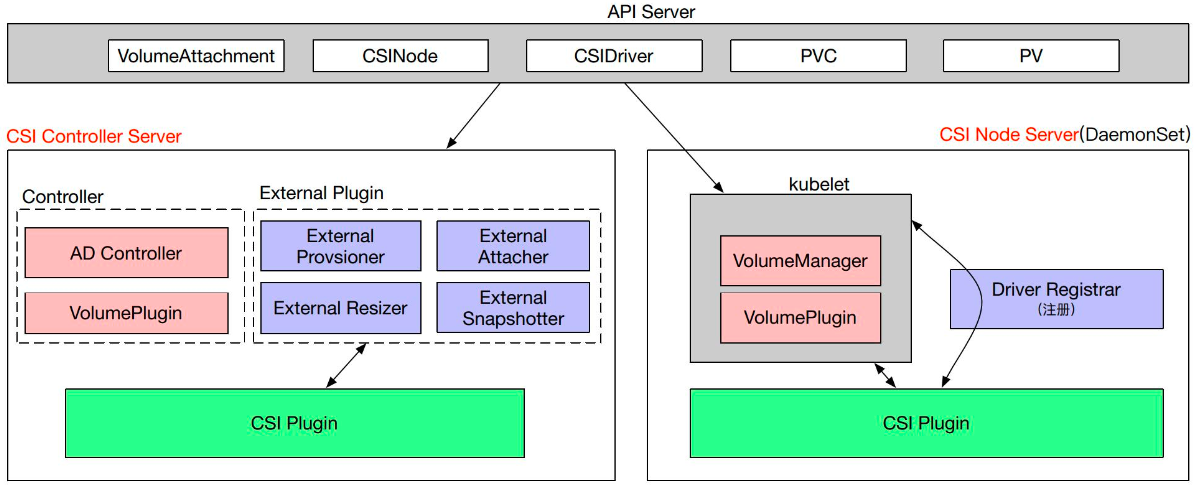
在 CSI Controller Server 中,有传统的类似 Kubernetes 中的 AD Controller 和 Volume Plugins,VolumeAttachment 对象就是由它们所创建的。
此外,还包含多个 External Plugin组件,每个组件和 CSI Plugin 组合的时候会完成某种功能。比如:
External Provisioner 和 Controller Server 组合的时候就会完成数据卷的创建与删除功能;
External Attacher 和 Controller Server 组合起来可以执行数据卷的挂载和操作;
External Resizer 和 Controller Server 组合起来可以执行数据卷的扩容操作;
External Snapshotter 和 Controller Server 组合则可以完成快照的创建和删除。
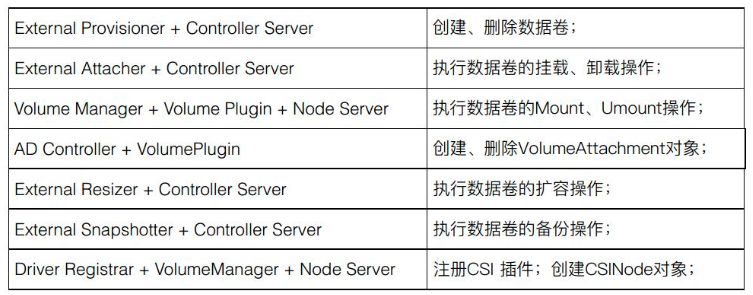
CSI Node Server 中主要包含 Kubelet 组件,包括 VolumeManager 和 VolumePlugin,它们会去调用 CSI Plugin 去做 mount 和 unmount 操作;另外一个组件 Driver Registrar 主要实现的是 CSI Plugin 注册的功能。
以上就是 CSI 的整个拓扑结构,接下来我们将分别介绍不同的对象和组件。
我们将介绍 3 种对象:VolumeAttachment,CSIDriver,CSINode。
VolumeAttachment 描述一个 Volume 卷在一个 Pod 使用中挂载、卸载的相关信息。例如,对一个卷在某个节点上的挂载,我们通过 VolumeAttachment 对该挂载进行跟踪。AD Controller 创建一个 VolumeAttachment,而 External-attacher 则通过观察该 VolumeAttachment,根据其状态来进行挂载和卸载操作。
下图就是一个 VolumeAttachment 的例子,其类别 (kind) 为 VolumeAttachment,spec 中指定了 attacher 为 ossplugin.csi.alibabacloud.com,即指定挂载是由谁操作的;指定了 nodeName 为 cn-zhangjiakou.192.168.1.53,即该挂载是发生在哪个节点上的;指定了 source 为 persistentVolumeName 为 oss-csi-pv,即指定了哪一个数据卷进行挂载和卸载。
status 中 attached 指示了挂载的状态,如果是 False, External-attacher 就会执行一个挂载操作。

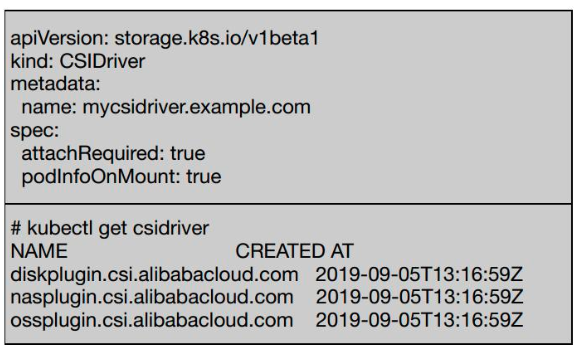
第二个对象是 CSIDriver,它描述了集群中所部署的 CSI Plugin 列表,需要管理员根据插件类型进行创建。
例如下图中创建了一些 CSI Driver,通过
kuberctl get csidriver 我们可以看到集群里面创建的 3 种类型的 CSI Driver:一个是云盘;一个是 NAS;一个是 OSS。
在 CSI Driver 中,我们定义了它的名字,在 spec 中还定义了 attachRequired 和 podInfoOnMount 两个标签。
attachRequired 定义一个 Plugin 是否支持 Attach 功能,主要是为了对块存储和文件存储做区分。比如文件存储不需要 Attach 操作,因此我们将该标签定义为 False;
podInfoOnMount 则是定义 Kubernetes 在调用 Mount 接口时是否带上 Pod 信息。
第三个对象是 CSINode,它是集群中的节点信息,由 node-driver-registrar 在启动时创建。它的作用是每一个新的 CSI Plugin 注册后,都会在 CSINode 列表里添加一个 CSINode 信息。
例如下图,定义了 CSINode 列表,每一个 CSINode 都有一个具体的信息(左侧的 YAML)。以 一 cn-zhangjiakou.192.168.1.49 为例,它包含一个云盘的 CSI Driver,还包含一个 NAS 的 CSI Driver。每个 Driver 都有自己的 nodeID 和它的拓扑信息 topologyKeys。如果没有拓扑信息,可以将 topologyKeys 设置为 “null”。也就是说,假如有一个有 10 个节点的集群,我们可以只定义一部分节点拥有 CSINode。

Node-Driver-Registrar 主要实现了 CSI Plugin 注册的一个机制。我们来看一下下图中的流程图。
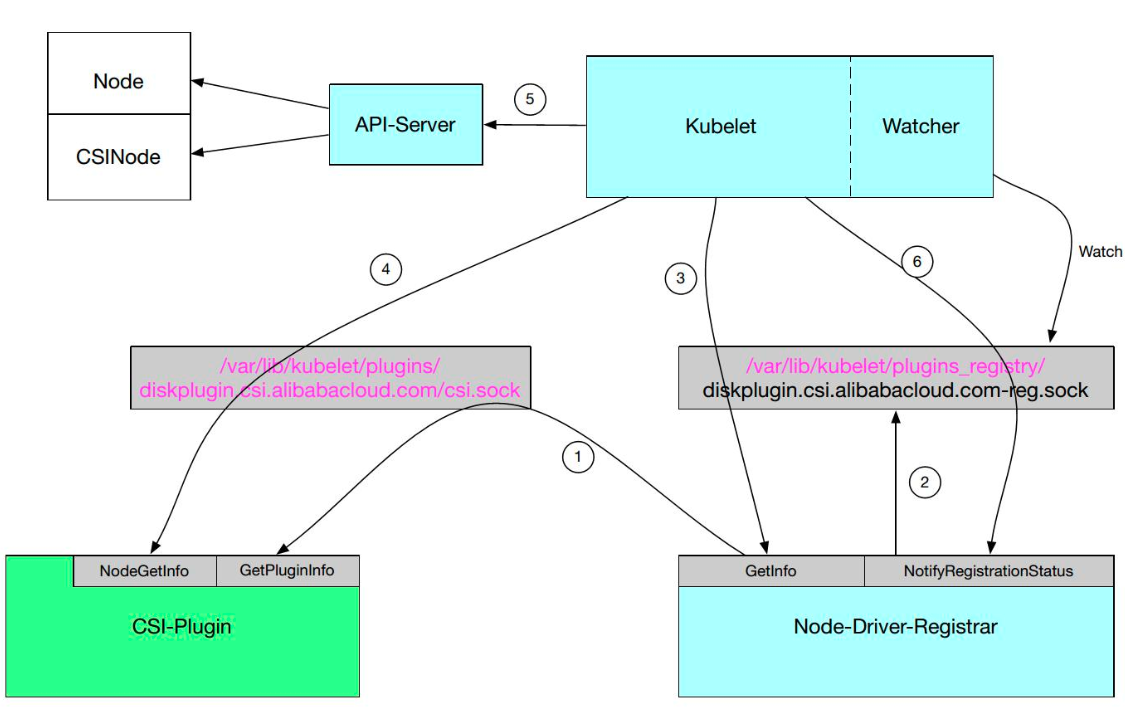
第 1 步,在启动的时候有一个约定,比如说在 /var/lib/kuberlet/plugins_registry 这个目录每新加一个文件,就相当于每新加了一个 Plugin;
启动 Node-Driver-Registrar,它首先会向 CSI-Plugin 发起一个接口调用 GetPluginInfo,这个接口会返回 CSI 所监听的地址以及 CSI-Plugin 的一个 Driver name;
第 2 步,Node-Driver-Registrar 会监听 GetInfo 和 NotifyRegistrationStatus 两个接口;
第 3 步,会在
/var/lib/kuberlet/plugins_registry 这个目录下启动一个 Socket,生成一个 Socket 文件 ,例如:”diskplugin.csi.alibabacloud.com-reg.sock”,此时 Kubelet 通过 Watcher 发现这个 Socket 后,它会通过该 Socket 向 Node-Driver-Registrar 的 GetInfo 接口进行调用。GetInfo 会把刚才我们所获得的的 CSI-Plugin 的信息返回给 Kubelet,该信息包含了 CSI-Plugin 的监听地址以及它的 Driver name;
第 4 步,Kubelet 通过得到的监听地址对 CSI-Plugin 的 NodeGetInfo 接口进行调用;
第 5 步,调用成功之后,Kubelet 会去更新一些状态信息,比如节点的 Annotations、Labels、status.allocatable 等信息,同时会创建一个 CSINode 对象;
第 6 步,通过对 Node-Driver-Registrar 的 NotifyRegistrationStatus 接口的调用告诉它我们已经把 CSI-Plugin 注册成功了。
通过以上 6 步就实现了 CSI Plugin 注册机制。
External-Attacher 主要是通过 CSI Plugin 的接口来实现数据卷的挂载与卸载功能。它通过观察 VolumeAttachment 对象来实现状态的判断。VolumeAttachment 对象则是通过 AD Controller 来调用 Volume Plugin 中的 CSI Attacher 来创建的。CSI Attacher 是一个 In-Tree 类,也就是说这部分是 Kubernetes 完成的。
当 VolumeAttachment 的状态是 False 时,External-Attacher 就去调用底层的一个 Attach 功能;若期望值为 False,就通过底层的 ControllerPublishVolume 接口实现 Detach 功能。同时,External-Attacher 也会同步一些 PV 的信息在里面。
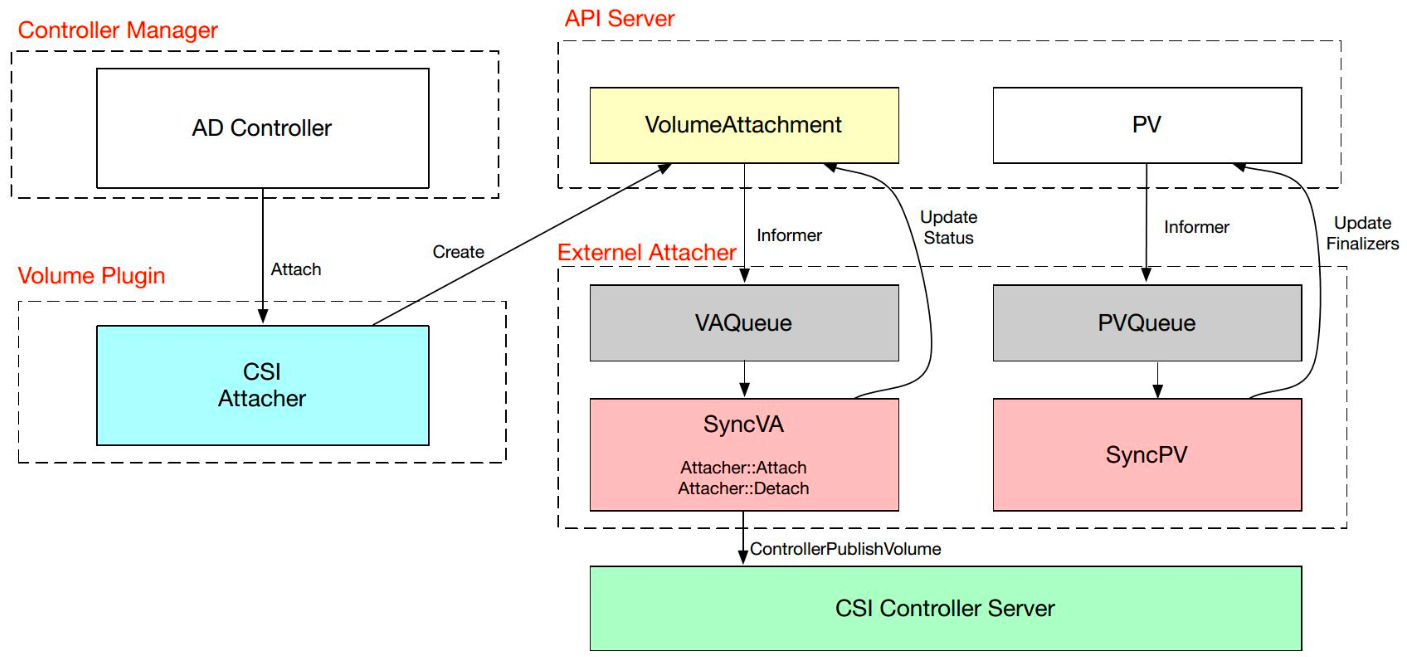
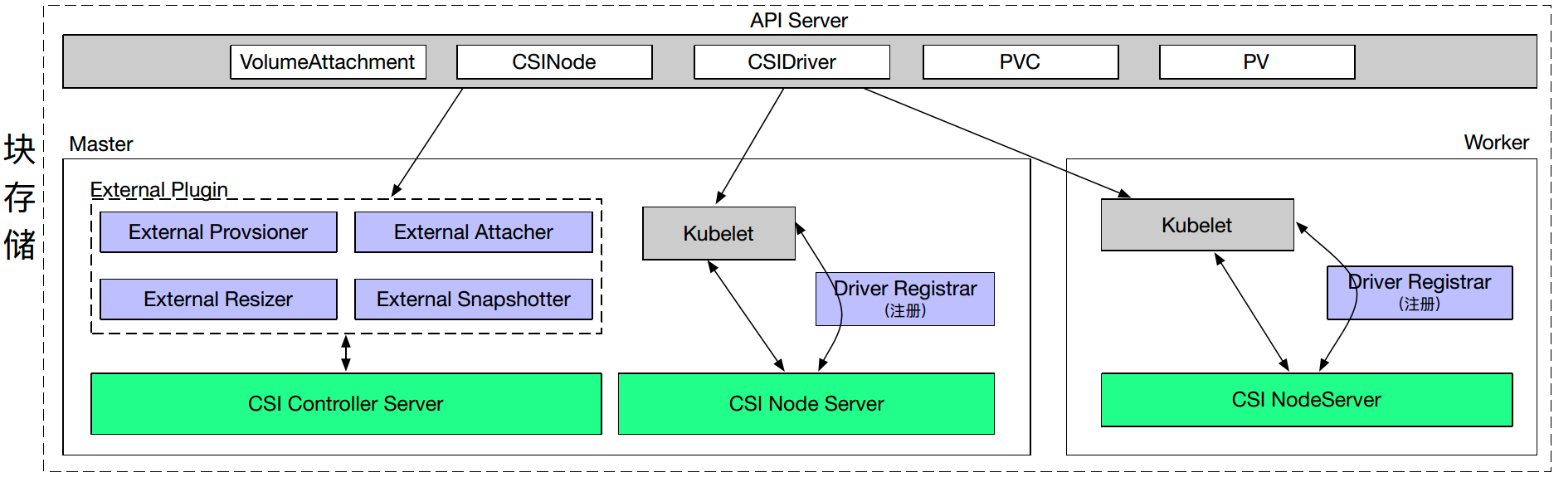
我们现在来看一下块存储的部署情况。
之前提到 CSI 的 Controller 分为两部分,一个是 Controller Server Pod,一个是 Node Server Pod。
我们只需要部署一个 Controller Server,如果是多备份的,可以部署两个。Controller Server 主要是通过多个外部插件来实现的,比如说一个 Pod 中可以定义多个 External 的 Container 和一个包含 CSI Controller Server 的 Container,这时候不同的 External 组件会和 Controller Server 组成不同的功能。
而 Node Server Pod 是个 DaemonSet,它会在每个节点上进行注册。Kubelet 会直接通过 Socket 的方式直接和 CSI Node Server 进行通信、调用 Attach/Detach/Mount/Unmount 等。
Driver Registrar 只是做一个注册的功能,会在每个节点上进行部署。
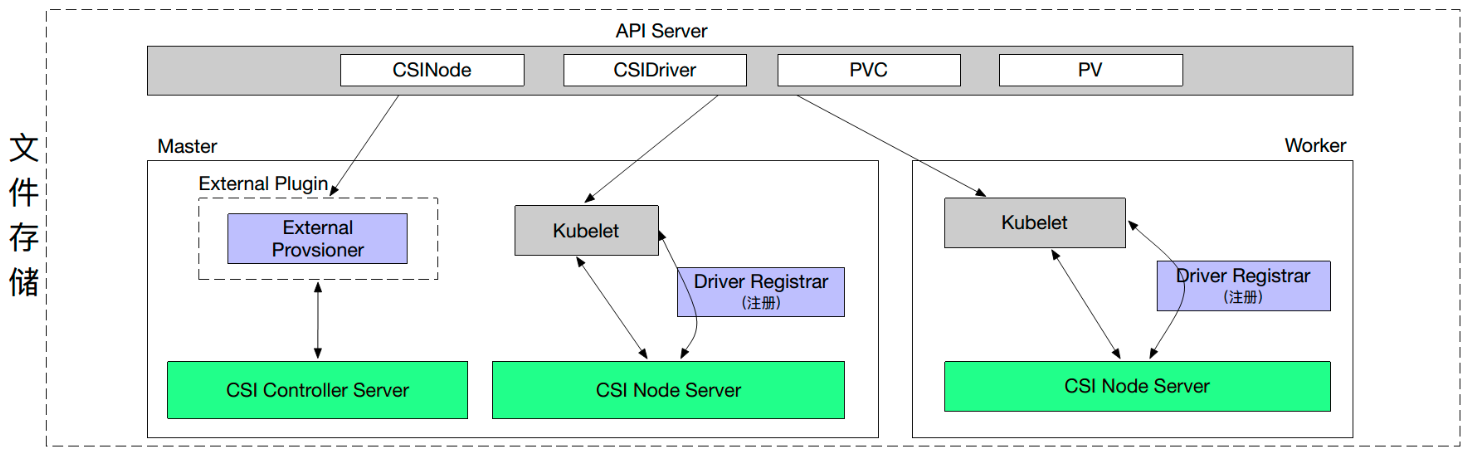
文件存储和块存储的部署情况是类似的。只不过它会把 Attacher 去掉,也没有 VolumeAttachment 对象。
和 Flexvolume 一样,我们看一下它的定义模板。
可以看到,它和其它的定义并没什么区别。主要的区别在于类型为 CSI,里面会定义 driver,volumeHandle,volumeAttribute,nodeAffinity 等。
driver 就是定义是由哪一个插件来去实现挂载;
volumeHandle 主要是指示 PV 的唯一标签;
volumeAttribute 用于附加参数,比如 PV 如果定义的是 OSS,那么就可以在 volumeAttribute 定义 bucket、访问的地址等信息在里面;
nodeAffinity 则可以定义一些调度信息。与 Flexvolume 类似,还可以通过 selector 和 Label 定义一些绑定条件。
中间的图给出了一个动态调度的例子,它和其它类型的动态调度是一样的。只不过在定义 provisioner 的时候指定了一个 CSI 的 provisioner。
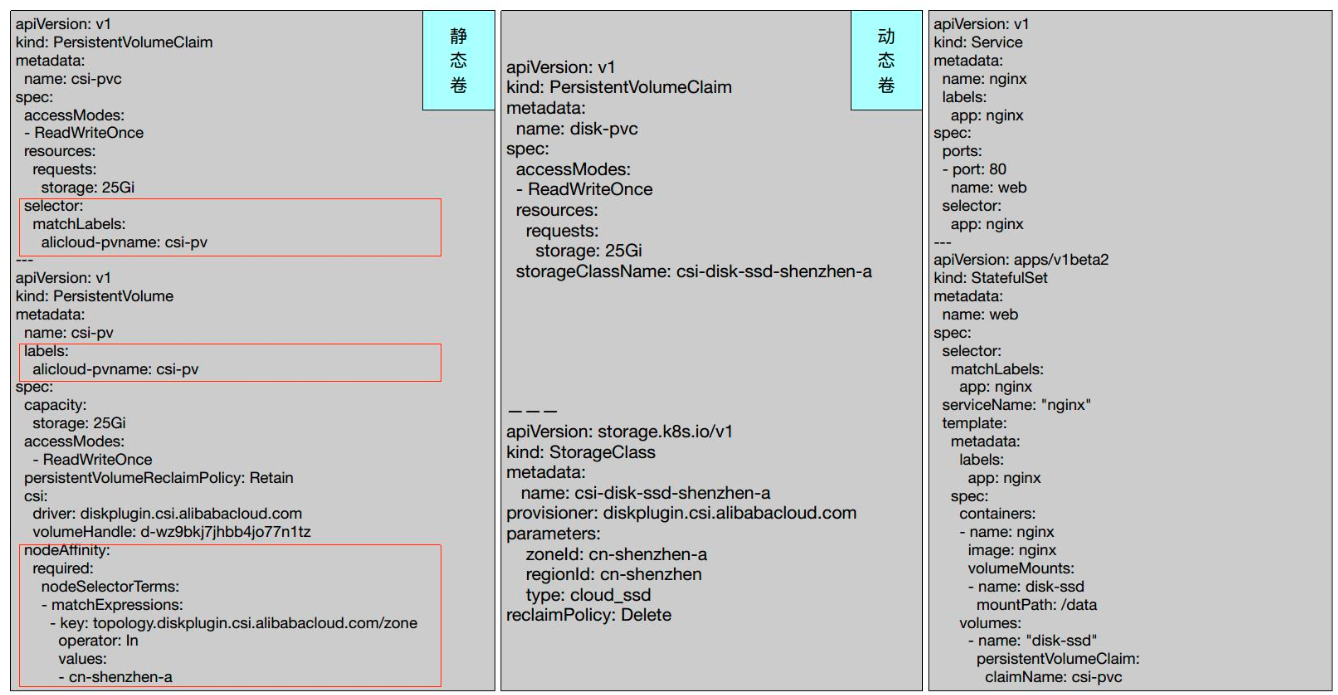
下面给出了一个具体的挂载例子。
Pod 启动之后,我们可以看到 Pod 已经把一个 /dev/vdb 挂载到 /data 上了。同理,它有一个 GlobalPath 和一个 PodPath 的集群在里面。我们可以把一个 /dev/vdb 挂载到一个 GlobalPath 里面,它就是一个 CSI 的一个 PV 在本节点上唯一确定的目录。一个 PodPath 就是一个 Pod 所确定的一个本地节点的目录,它会把 Pod 所对应的目录映射到我们的容器中去。

除了挂载、卸载之外,CSI 化提供了一些附加的功能。例如,在定义模板的时候往往需要一些用户名和密码信息,此时我们就可通过 Secret 来进行定义。之前我们所讲的 Flexvolume 也支持这个功能,只不过 CSI 可以根据不同的阶段定义不同的 Secret 类型,比如挂载阶段的 Secret、Mount 阶段的 Secret、Provision 阶段的 Secret。
Topology 是一个拓扑感知的功能。当我们定义一个数据卷的时候,集群中并不是所有节点都能满足该数据卷的需求,比如我们需要挂载不同的 zone 的信息在里面,这就是一个拓扑感知的功能。这部分在第 10 讲已有详细的介绍,大家可以进行参考。
Block Volume 就是 volumeMode 的一个定义,它可以定义成 Block 类型,也可以定义成文件系统类型,CSI 支持 Block 类型的 Volume,就是说挂载到 Pod 内部时,它是一个块设备,而不是一个目录。
Skip Attach 和 PodInfo On Mount 是刚才我们所讲过的 CSI Driver 中的两个功能。


CSI 还是一个比较新的实现方式。近期也有了很多更新,比如 ExpandCSIVolumes 可以实现文件系统扩容的功能;VolumeSnapshotDataSource 可以实现数据卷的快照功能;VolumePVCDataSource 实现的是可以定义 PVC 的数据源;我们以前在使用 CSI 的时候只能通过 PVC、PV 的方式定义,而不能直接在 Pod 里面定义 Volume,CSIInlineVolume 则可以让我们可以直接在 Volume 中定义一些 CSI 的驱动。
阿里云在 GitHub 上开源了 CSI 的实现,大家有兴趣的可以看一下,做一些参考。
主要介绍了 Kubernetes 集群中存储卷相关的知识,主要有以下三点内容:
第一部分讲述了 Kubernetes 存储架构,主要包括存储卷概念、挂载流程、系统组件等相关知识;
第二部分讲述了 Flexvolume 插件的实现原理、部署架构、使用示例等;
第三部分讲述了 CSI 插件的实现原理、资源对象、功能组件、使用示例等;
看完上述内容,你们掌握Kubernetes存储架构及插件使用是怎样的的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/69953029/viewspace-2675103/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



