前言
不知不觉,技术人生系列·我和数据中心的故事来到了第五期。小y又和大家见面了!
前几期主要发了一些TroubleShooting的案例分享,其实小y最擅长的是性能优化,所以从这期开始,小y会陆续的分享更多的数据库性能优化案例。
进入正题,如果您的日终跑批/清算/报表等程序时快时慢,或者从某一天以后就一直变慢,作为运维DBA或开发的您,会怎么下手?还有,除了解决问题外,你要如何解答领导最关心的一个问题,“为什么现在有问题,但是以前没有问题呢”!
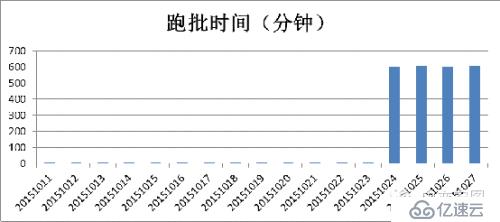
小y今天要和大家分享的就是这样一个性能问题的分析和解决过程。
你们的点赞和转发就是小y继续坚持分享的动力。
另外,前阵子有部分朋友问,小y所在的团队是否可以提供对外的第三方Oracle服务,答案是YES!
有兴趣的朋友可以加一下小y的个人微信,微信号是 shadow-huang-bj,希望可以交到更多的朋友,并帮助到更多有需要的人。
Part 1
问题来了
小y,有空么?一会一起看一个报表的性能问题。
有个SQL语句一周前开始,性能急剧恶化,执行时间从10分钟以内变成了10个小时以上。
刚在客户现场做完Oracle的培训,问题来的正是时候,刚好可以让客户感受下理论如何融入实战的魅力!小y的第一想法是SQL语句的执行计划发生了改变,通常从统计信息或者CBO对cardinality的估算情况中就可以快速找到线索,应该很快就可以查明原因并解决!
最后的事实证明,小y一开始想简单了。针对这个问题,客户通过并且重新收集统计信息或重启数据库均无法解决问题。幸运的是,小y及时调整回到了学院派模式,最终在一个小时内找到了问题的原因,问题的解决也就是顺其自然了。
环境介绍:
操作系统 Redhat 64 bit
数据库 Oracle 11.2.0.3 , 2节点RAC
Part 2
分析过程

小y对这条SQL进行了敏感信息处理和写法的简化处理,可以看到:
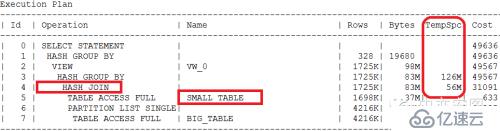
该SQL对两张表张进行join,然后group by
参与关联的两张表一张是80M的小表,另外一张是3.5G的较大一些的表。记录数分别是160万和800万
SQL语句用了hint,提示优化器表连接走hash join,单表访问路径小表走全表扫描。
这样的一条SQL,按照小y的经验,驱动表只要选择小表,那么整个HASH JOIN的执行时间基本等同于两张表的单表访问时间,两张表加起来不到4G,通常都可以在5分钟内完成。这和客户描述的以前的执行时间是相吻合的。
这里顺便说一下:
很多开发写hint往往写的不完整,例如这个hint只写了表连接方式,单表访问路径只写了一张表,表的连接顺序没有写,其实并没有完全固定死执行计划。
接下来,小y将查看执行计划是否发生变化,还有执行计划是否正确。

可以看到:
执行计划(oracle内部的算法)确实如hint一样
表连接方式走的是hash join
单表访问路径都是全表扫描(table access full)
表连接顺序是小表做驱动表(hash内存表)
这是一个完美、最优的执行计划。唯一的小缺点是优化器评估hash join和hash group by的步骤用到了一些临时表空间,不过这只是CBO的评估,不代表实际会发生。
对比了以前的执行计划,也是一样的。
既然执行计划没有问题,也没有发生改变,那么就需要将SQL的执行时间进行分解,看看时间到底消耗在了是CPU还是IO、集群、并发竞争等什么环节。
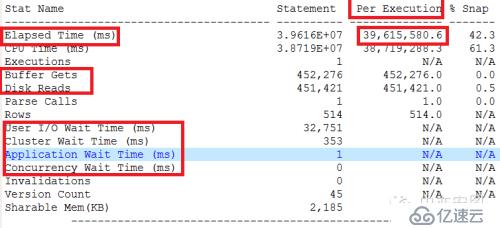
可以看到:
1、 每次执行时间39615秒,超过10个小时
2、 每次执行逻辑读只有45276个block(块)
3、 每次执行物理读451421个block(块)
4、 时间基本都消耗在CPU上,达到38719秒,超过10个小时,而在IO/集群/应用(锁)/并发环节消耗时间很小
到了这里,经验丰富的DBA应该可以发现,该CASE出现了一些奇怪的现象。
不过还是要照顾一下大家,先来回答一些朋友心里可能的问题。
2.4.1
是不是有什么异常等待事件
看到这里,也许有人会说:
是不是SQL语句执行过程中有什么异常的等待事件?
首先答案是NO!
因为整个SQL的执行时间中,时间基本都消耗在CPU上,达到38719秒,超过10个小时,而在IO/集群/应用(锁)/并发环节消耗时间很小(加起来不到100秒)。如果SQL跑在CPU上,那么是不会有等待事件的线索的。时间分布如下图所示。
2.4.2
是不是hash join One-pass/Muti-pass导致慢
也许有人会说:
执行计划出现了temp表空间的使用,是不是hash join One-pass/Muti-pass导致SQL执行慢
答案是NO!
首先,执行计划中显示会用到temp表空间(hash join one-pass/muti-pass),这是CBO执行前的评估而已,实际执行很可能根本不会使用。
其次,如果真的使用temp表空间,并且成为整个SQL的瓶颈,则我们会看到很多的direct path read/write temp,由于这类等待事件算在IO类的等待事件里,那么整个SQL语句的执行事件就应该是IO占的最多而不是现在看到的时间都消耗在CPU上。
2.4.3
小y的疑惑
到这里,小y开始感觉到了这个case需要更专注来解决了!
执行时间基本都耗在CPU上,这通常意味着所需要的数据基本都在内存中。
一个常识是,如果所需要的BLOCK在内存中,那么 CPU每秒可以处理10万甚至几十万的逻辑读!
但具体到这条SQL, 10的小时的CPU时间,处理的逻辑读,才有45万!
45万的逻辑读刚好对应4G的大小,即两张表的大小之和。
目前确实有一些奇怪的地方,小y接下来需要:
和历史执行时间的分解进行比对
将这条SQL语句重新跑起来,获取更多的线索。
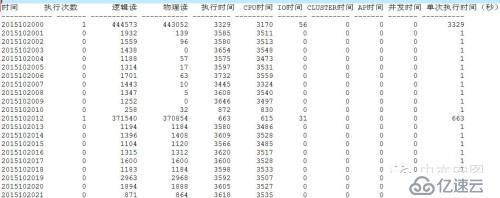
可以看到:
一开始的时候,每个小时还可以处理44万的逻辑读,但是后来就慢了起来
后来的绝大部分时间里,每个小时才处理1000-3000的逻辑读
执行时间确实都在CPU上!
可惜的是,由于AWR报告只保留7天,因此未能获取到原来的执行时间的分解的情况,也就没有办法做正常和异常时刻的比对。接下来,这是一个SELECT语句,可以直接跑起来重现问题,这样小y可以观察到更多的线索!
将这条SQL语句重新跑起来,然后开启其他窗口观察,一开始的1分钟内还算正常,先后读取小表和大表,IO差不多到每秒30M,然后IO就急剧的下降了,这个时候等待事件是ON CPU。
小y立马查看了SQL的执行进度,v$session_longops中表SMALL_TABLE已经扫描完成,但另外一张表BIG_TABLE全表扫描的进度进本停留在82%的位置!但细看还是涨的,只是涨的比较慢!如下图所示。
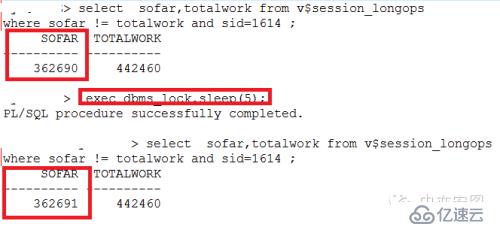
对BIG_TABLE的全表扫描,sofar基本上每5秒才涨1 !
按照这个速度,还需要(442460-362690)*5=40万秒,即10个小时以上!这和“历史执行情况比对和确认”章节是可以对上的!
这里提示一下,涨的慢和IO性能没关系,上面已经分析过了,时间都消耗在CPU上
接下来,读者朋友们,可以停一下,把上述现象总结一下,再思考个几分钟、
如果是您来接这个CASE,你会怎么继续往下查呢?
↓
↓
↓
↓
↓
↓
↓
↓
↓
不要走开后边还有.....
既然SQL执行是在CPU上,那么就不会有什么等待事件的线索留出来,既然在CPU上,那么必然要去看call stack,这是小y多年养成的习惯了。
通过oradebug short_stack,间隔几秒抓取了三次。如下图所示:
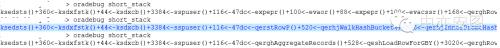
到了这里,小y已经做完了所有的检查。
是时候出去抽一根烟了,需要把所有发现的线索在脑子里过一次。
幸运的是,一根烟后,小y终于把所有问题都想明白了,所有看到的现象都可以说清楚了,还有领导最关心的一个问题—“为什么现在有问题,但是以前没有问题呢”!,小y也有了答案。
建议朋友们,读到这里也可以先停一下,思考个几分钟,看看自己是否已经找到了问题原因。
到这里已经找到答案的朋友,可以发小y发一份简历,说明你有不错的思考能力和经验!欢迎你加入中亦科技Oracle服务团队!简历请发 51994106@qq.com
在出门抽烟的这一小会功夫里,小y不断思考着几个问题。
为什么每个小时才处理几千个逻辑读呢?
SQL执行时间都消耗在CPU上,都在做什么呢?
为什么以前不出,现在出呢?
下图的这个函数qerhjWalkHashBucket,将所有问题都彻底解释清楚了! qerhjWalkHashBucket就表示在做hash join的过程中需要遍历hash bucket中的数据。

因此,小y重新缕了一下Hash Join原理,例如两张表A和B表的整表关联
SELECT * FROM A,B
WHERE A.ID=B.ID
ORACLE内部的执行过程,可以简化为:
SCAN A(扫描A表)
HASH(A.ID),打散到各个桶(BUCKET)中,呆在pga hash area中等待别人来匹配
SCAN B(扫描B表)
HASH(B.ID)
到相应的Bucket中,比较表关联字段的值是否相同,返回或丢弃
HASH的目的是为了打算数据到各个桶中。每个算法都有优缺点。
那么HASH JOIN有什么缺点呢?
我们是否命中了该缺点呢?!
很显然,当驱动表在内存中里的其中一个桶里 (bucket)的数据很多的时候,那么被驱动表的一个值到该桶里比较起来就很需要遍历更多的数据,这个时候就类似于nest loop了。那么一个值的比对就需要很久了!
被驱动表一个BLOCK可以存储几十到几百条记录,而一条记录需要到一个记录很多的桶里去比较很久,被驱动表一个BLOCK有很多条记录,自然就出现了每个小时只能处理几千个逻辑读的情况了!也就观察到了v$session_longops.sofar涨的很慢的情况了!
同时,关联字段大量比较的过程是很消耗CPU的 (当驱动表读进PGA里后就呆在PGA内存中了)
那么为什么以前不出呢? 那是因为以前驱动表的关联字段的数据分布是均匀的!而自从某一天以后,表关联字段的分布开始不均匀了!
发出SQL,验证如下:
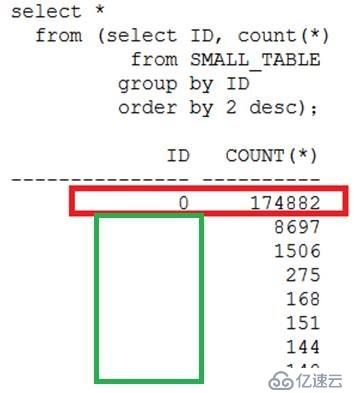
可以看到,驱动表small_table中id=0的记录数达到17万条,意味着一个bucket的数据至少达到17万条,这与hash join打散数据到各个bucket,通常一个bucket的数据不超过5条的想法和设计初衷是相违背的!
至此,所有问题得到了圆满的解答!
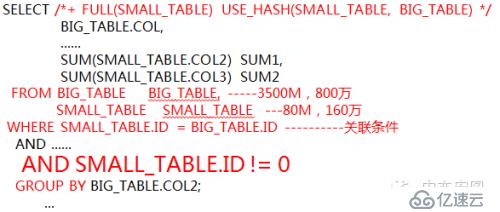
在SQL语句中加入small_table.id != 0的过滤条件,small_table的数据从160万减少到143万,变化不大的情况下,执行上述SQL,执行时间在3分钟左右就完成了!
这就验证了hash join不适合驱动表表关联字段分布不均匀的一个缺点 !
知道原因了,那么解决方案就多种多样了!
hash join不适合驱动表表关联字段分布不均匀的情况,因此解决方案有多种
1) 采用use_merge的hint而非use_hash,无法修改程序的情况可以通过sql profile指定执行计划。这里两张表都不大,排序合并连接也很快。
2) 对驱动表small_table.id=0的数据进行调查、确认和处理,为什么会在某一天突然出现大量id=0的数据,是否可以删除
……
可以看到:
掌握原理是必须的
什么样的架构、算法和存储结构决定了他可以做什么样的事情,不可以做什么样的事情
但你思考过他的缺点是什么么?以前没有的话,小y建议尝试,让你有更多收获
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





