Flink SQLжҖҺд№Ҳе®һзҺ°ж•°жҚ®жөҒзҡ„Join
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңFlink SQLжҖҺд№Ҳе®һзҺ°ж•°жҚ®жөҒзҡ„JoinвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁFlink SQLжҖҺд№Ҳе®һзҺ°ж•°жҚ®жөҒзҡ„Joinй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқFlink SQLжҖҺд№Ҳе®һзҺ°ж•°жҚ®жөҒзҡ„JoinвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
ж— и®әеңЁ OLAP иҝҳжҳҜ OLTP йўҶеҹҹпјҢJoin йғҪжҳҜдёҡеҠЎеёёдјҡж¶үеҸҠеҲ°дё”дјҳеҢ–规еҲҷжҜ”иҫғеӨҚжқӮзҡ„ SQL иҜӯеҸҘгҖӮеҜ№дәҺзҰ»зәҝи®Ўз®—иҖҢиЁҖпјҢз»ҸиҝҮж•°жҚ®еә“йўҶеҹҹеӨҡе№ҙзҡ„з§ҜзҙҜпјҢJoin иҜӯд№үд»ҘеҸҠе®һзҺ°е·Із»ҸеҚҒеҲҶжҲҗзҶҹпјҢ然иҖҢеҜ№дәҺиҝ‘е№ҙжқҘеҲҡе…ҙиө·зҡ„ Streaming SQL жқҘиҜҙ Join еҚҙеӨ„дәҺеҲҡиө·жӯҘзҡ„зҠ¶жҖҒгҖӮ
е…¶дёӯжңҖдёәе…ій”®зҡ„й—®йўҳеңЁдәҺ Join зҡ„е®һзҺ°дҫқиө–дәҺзј“еӯҳж•ҙдёӘж•°жҚ®йӣҶпјҢиҖҢ Streaming SQL Join зҡ„еҜ№иұЎеҚҙжҳҜж— йҷҗзҡ„ж•°жҚ®жөҒпјҢеҶ…еӯҳеҺӢеҠӣе’Ңи®Ўз®—ж•ҲзҺҮеңЁй•ҝжңҹиҝҗиЎҢжқҘиҜҙйғҪжҳҜдёҚеҸҜйҒҝе…Қзҡ„й—®йўҳгҖӮдёӢж–Үе°Ҷз»“еҗҲ SQL зҡ„еҸ‘еұ•и§Јжһҗ Flink SQL жҳҜеҰӮдҪ•и§ЈеҶіиҝҷдәӣй—®йўҳ并е®һзҺ°дёӨдёӘж•°жҚ®жөҒзҡ„ JoinгҖӮ
зҰ»зәҝ Batch SQL Join зҡ„е®һзҺ°
дј з»ҹзҡ„зҰ»зәҝ Batch SQL пјҲйқўеҗ‘жңүз•Ңж•°жҚ®йӣҶзҡ„ SQLпјүжңүдёүз§ҚеҹәзЎҖзҡ„е®һзҺ°ж–№ејҸпјҢеҲҶеҲ«жҳҜ Nested-loop JoinгҖҒSort-Merge Join е’Ң Hash JoinгҖӮ
Nested-loop Join жңҖдёәз®ҖеҚ•зӣҙжҺҘпјҢе°ҶдёӨдёӘж•°жҚ®йӣҶеҠ иҪҪеҲ°еҶ…еӯҳпјҢ并用еҶ…еөҢйҒҚеҺҶзҡ„ж–№ејҸжқҘйҖҗдёӘжҜ”иҫғдёӨдёӘж•°жҚ®йӣҶеҶ…зҡ„е…ғзҙ жҳҜеҗҰз¬ҰеҗҲ Join жқЎд»¶гҖӮNested-loop Join иҷҪ然时й—ҙж•ҲзҺҮд»ҘеҸҠз©әй—ҙж•ҲзҺҮйғҪжҳҜжңҖдҪҺзҡ„пјҢдҪҶиғңеңЁжҜ”иҫғзҒөжҙ»йҖӮз”ЁиҢғеӣҙе№ҝпјҢеӣ жӯӨе…¶еҸҳдҪ“ BNL еёёиў«дј з»ҹж•°жҚ®еә“з”ЁдҪңдёә Join зҡ„й»ҳи®ӨеҹәзЎҖйҖүйЎ№гҖӮ
Sort-Merge Join йЎҫеҗҚжҖқд№үпјҢеҲҶдёәдёӨдёӘ Sort е’Ң Merge йҳ¶ж®өгҖӮйҰ–е…Ҳе°ҶдёӨдёӘж•°жҚ®йӣҶиҝӣиЎҢеҲҶеҲ«жҺ’еәҸпјҢ然еҗҺеҜ№дёӨдёӘжңүеәҸж•°жҚ®йӣҶеҲҶеҲ«иҝӣиЎҢйҒҚеҺҶе’ҢеҢ№й…ҚпјҢзұ»дјјдәҺеҪ’并жҺ’еәҸзҡ„еҗҲ并гҖӮеҖјеҫ—жіЁж„Ҹзҡ„жҳҜпјҢSort-Merge еҸӘйҖӮз”ЁдәҺ Equi-JoinпјҲJoin жқЎд»¶еқҮдҪҝз”ЁзӯүдәҺдҪңдёәжҜ”иҫғз®—еӯҗпјүгҖӮSort-Merge Join иҰҒжұӮеҜ№дёӨдёӘж•°жҚ®йӣҶиҝӣиЎҢжҺ’еәҸпјҢжҲҗжң¬еҫҲй«ҳпјҢйҖҡеёёдҪңдёәиҫ“е…Ҙжң¬е°ұжҳҜжңүеәҸж•°жҚ®йӣҶзҡ„жғ…еҶөдёӢзҡ„дјҳеҢ–ж–№жЎҲгҖӮ
Hash Join еҗҢж ·еҲҶдёәдёӨдёӘйҳ¶ж®өпјҢйҰ–е…Ҳе°ҶдёҖдёӘж•°жҚ®йӣҶиҪ¬жҚўдёә Hash TableпјҢ然еҗҺйҒҚеҺҶеҸҰеӨ–дёҖдёӘж•°жҚ®йӣҶе…ғзҙ 并дёҺ Hash Table еҶ…зҡ„е…ғзҙ иҝӣиЎҢеҢ№й…ҚгҖӮ第дёҖйҳ¶ж®өе’Ң第дёҖдёӘж•°жҚ®йӣҶеҲҶеҲ«з§°дёә build йҳ¶ж®өе’Ң build tableпјҢ第дәҢдёӘйҳ¶ж®өе’Ң第дәҢдёӘж•°жҚ®йӣҶеҲҶеҲ«з§°дёә probe йҳ¶ж®өе’Ң probe tableгҖӮHash Join ж•ҲзҺҮиҫғй«ҳдҪҶеҜ№з©әй—ҙиҰҒжұӮиҫғеӨ§пјҢйҖҡеёёжҳҜдҪңдёә Join е…¶дёӯдёҖдёӘиЎЁдёәйҖӮеҗҲж”ҫе…ҘеҶ…еӯҳзҡ„е°ҸиЎЁзҡ„жғ…еҶөдёӢзҡ„дјҳеҢ–ж–№жЎҲгҖӮе’Ң Sort-Merge Join зұ»дјјпјҢHash Join д№ҹеҸӘйҖӮз”ЁдәҺ Equi-JoinгҖӮ
е®һж—¶ Streaming SQL Join
зӣёеҜ№дәҺзҰ»зәҝзҡ„ JoinпјҢе®һж—¶ Streaming SQLпјҲйқўеҗ‘ж— з•Ңж•°жҚ®йӣҶзҡ„ SQLпјүж— жі•зј“еӯҳжүҖжңүж•°жҚ®пјҢеӣ жӯӨ Sort-Merge Join иҰҒжұӮзҡ„еҜ№ж•°жҚ®йӣҶиҝӣиЎҢжҺ’еәҸеҹәжң¬жҳҜж— жі•еҒҡеҲ°зҡ„пјҢиҖҢ Nested-loop Join е’Ң Hash Join з»ҸиҝҮдёҖе®ҡзҡ„ж”№иүҜеҲҷеҸҜд»Ҙж»Ўи¶іе®һж—¶ SQL зҡ„иҰҒжұӮгҖӮ
жҲ‘们йҖҡиҝҮдҫӢеӯҗжқҘзңӢеҹәжң¬зҡ„ Nested Join еңЁе®һж—¶ Streaming SQL зҡ„еҹәзЎҖе®һзҺ°пјҲжЎҲдҫӢеҸҠеӣҫжқҘиҮӘ Piotr Nowojski еңЁ Flink Forward San Francisco зҡ„еҲҶдә«[2]пјүгҖӮ
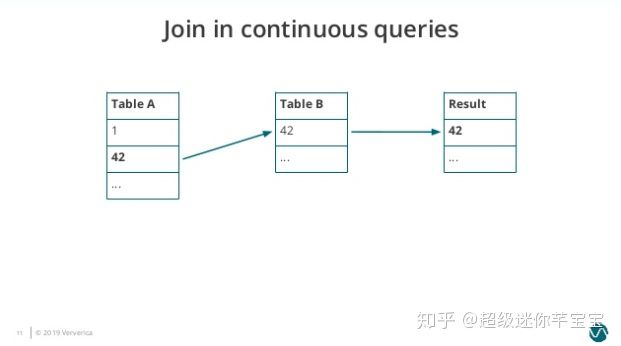
еӣҫ1. Join-in-continuous-query-1
Table A жңү 1гҖҒ42 дёӨдёӘе…ғзҙ пјҢTable B жңү 42 дёҖдёӘе…ғзҙ пјҢжүҖд»ҘжӯӨж—¶зҡ„ Join з»“жһңдјҡиҫ“еҮә 42гҖӮ
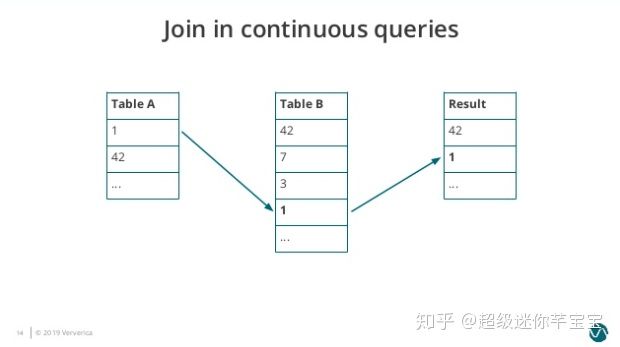
еӣҫ2. Join-in-continuous-query-2
жҺҘзқҖ Table B дҫқж¬ЎжҺҘеҸ—еҲ°дёүдёӘж–°зҡ„е…ғзҙ пјҢеҲҶеҲ«жҳҜ 7гҖҒ3гҖҒ1гҖӮеӣ дёә 1 еҢ№й…ҚеҲ° Table A зҡ„е…ғзҙ пјҢеӣ жӯӨз»“жһңиЎЁеҶҚиҫ“еҮәдёҖдёӘе…ғзҙ 1гҖӮ
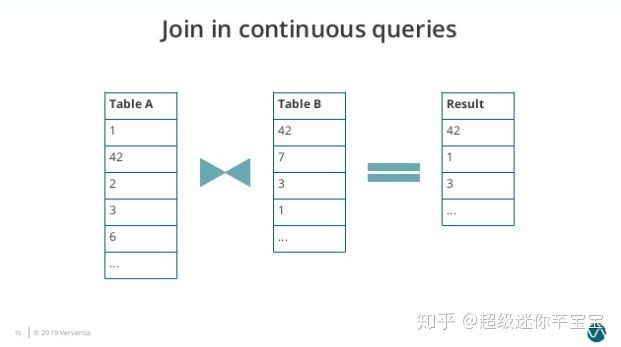
еӣҫ3. Join-in-continuous-query-3
йҡҸеҗҺ Table A еҮәзҺ°ж–°зҡ„иҫ“е…Ҙ 2гҖҒ3гҖҒ6пјҢ3 еҢ№й…ҚеҲ° Table B зҡ„е…ғзҙ пјҢеӣ жӯӨеҶҚиҫ“еҮә 3 еҲ°з»“жһңиЎЁгҖӮ
еҸҜд»ҘзңӢеҲ°еңЁ Nested-Loop Join дёӯжҲ‘们йңҖиҰҒдҝқеӯҳдёӨдёӘиҫ“е…ҘиЎЁзҡ„еҶ…е®№пјҢиҖҢйҡҸзқҖж—¶й—ҙзҡ„еўһй•ҝ Table A е’Ң Table B йңҖиҰҒдҝқеӯҳзҡ„еҺҶеҸІж•°жҚ®ж— жӯўеўғең°еўһй•ҝпјҢеҜјиҮҙеҫҲдёҚеҗҲзҗҶзҡ„еҶ…еӯҳзЈҒзӣҳиө„жәҗеҚ з”ЁпјҢиҖҢдё”еҚ•дёӘе…ғзҙ зҡ„еҢ№й…Қж•ҲзҺҮд№ҹдјҡи¶ҠжқҘи¶ҠдҪҺгҖӮзұ»дјјзҡ„й—®йўҳд№ҹеӯҳеңЁдәҺ Hash Join дёӯгҖӮ
йӮЈд№ҲжңүжІЎжңүеҸҜиғҪи®ҫзҪ®дёҖдёӘзј“еӯҳеү”йҷӨзӯ–з•ҘпјҢе°ҶдёҚеҝ…иҰҒзҡ„еҺҶеҸІж•°жҚ®еҸҠж—¶жё…зҗҶе‘ўпјҹзӯ”жЎҲжҳҜиӮҜе®ҡзҡ„пјҢе…ій”®еңЁдәҺзј“еӯҳеү”йҷӨзӯ–з•ҘеҰӮдҪ•е®һзҺ°пјҢиҝҷд№ҹжҳҜ Flink SQL жҸҗдҫӣзҡ„дёүз§Қ Join зҡ„дё»иҰҒеҢәеҲ«гҖӮ
Flink SQL зҡ„ Join
Regular Join жҳҜжңҖдёәеҹәзЎҖзҡ„жІЎжңүзј“еӯҳеү”йҷӨзӯ–з•Ҙзҡ„ JoinгҖӮRegular Join дёӯдёӨдёӘиЎЁзҡ„иҫ“е…Ҙе’Ңжӣҙж–°йғҪдјҡеҜ№е…ЁеұҖеҸҜи§ҒпјҢеҪұе“Қд№ӢеҗҺжүҖжңүзҡ„ Join з»“жһңгҖӮдёҫдҫӢпјҢеңЁдёҖдёӘеҰӮдёӢзҡ„ Join жҹҘиҜўйҮҢпјҢOrders иЎЁзҡ„ж–°зәӘеҪ•дјҡе’Ң Product иЎЁжүҖжңүеҺҶеҸІзәӘеҪ•д»ҘеҸҠжңӘжқҘзҡ„зәӘеҪ•иҝӣиЎҢеҢ№й…ҚгҖӮ
SELECT * FROM Orders
INNER JOIN Product
ON Orders.productId = Product.id
еӣ дёәеҺҶеҸІж•°жҚ®дёҚдјҡиў«жё…зҗҶпјҢжүҖд»Ҙ Regular Join е…Ғи®ёеҜ№иҫ“е…ҘиЎЁиҝӣиЎҢд»»ж„Ҹз§Қзұ»зҡ„жӣҙж–°ж“ҚдҪңпјҲinsertгҖҒupdateгҖҒdeleteпјүгҖӮ然иҖҢеӣ дёәиө„жәҗй—®йўҳ Regular Join йҖҡеёёжҳҜдёҚеҸҜжҢҒз»ӯзҡ„пјҢдёҖиҲ¬еҸӘз”ЁеҒҡжңүз•Ңж•°жҚ®жөҒзҡ„ JoinгҖӮ
Time-Windowed Join еҲ©з”ЁзӘ—еҸЈз»ҷдёӨдёӘиҫ“е…ҘиЎЁи®ҫе®ҡдёҖдёӘ Join зҡ„ж—¶й—ҙз•ҢйҷҗпјҢи¶…еҮәж—¶й—ҙиҢғеӣҙзҡ„ж•°жҚ®еҲҷеҜ№ JOIN дёҚеҸҜи§Ғ并еҸҜд»Ҙиў«жё…зҗҶжҺүгҖӮеҖјеҫ—жіЁж„Ҹзҡ„жҳҜпјҢиҝҷйҮҢж¶үеҸҠеҲ°зҡ„дёҖдёӘй—®йўҳжҳҜж—¶й—ҙзҡ„иҜӯд№үпјҢж—¶й—ҙеҸҜд»ҘжҢҮи®Ўз®—еҸ‘з”ҹзҡ„зі»з»ҹж—¶й—ҙпјҲеҚі Processing TimeпјүпјҢд№ҹеҸҜд»ҘжҢҮд»Һж•°жҚ®жң¬иә«зҡ„ж—¶й—ҙеӯ—ж®өжҸҗеҸ–зҡ„ Event TimeгҖӮеҰӮжһңжҳҜ Processing TimeпјҢFlink ж №жҚ®зі»з»ҹж—¶й—ҙиҮӘеҠЁеҲ’еҲҶ Join зҡ„ж—¶й—ҙзӘ—еҸЈе№¶е®ҡж—¶жё…зҗҶж•°жҚ®пјӣеҰӮжһңжҳҜ Event TimeпјҢFlink еҲҶй…Қ Event Time зӘ—еҸЈе№¶дҫқжҚ® Watermark жқҘжё…зҗҶж•°жҚ®гҖӮ
д»Ҙжӣҙеёёз”Ёзҡ„ Event Time Windowed Join дёәдҫӢпјҢдёҖдёӘе°Ҷ Orders и®ўеҚ•иЎЁе’Ң Shipments иҝҗиҫ“еҚ•иЎЁдҫқжҚ®и®ўеҚ•ж—¶й—ҙе’Ңиҝҗиҫ“ж—¶й—ҙ Join зҡ„жҹҘиҜўеҰӮдёӢ:
SELECT *
FROM
Orders o,
Shipments s
WHERE
o.id = s.orderId AND
s.shiptime BETWEEN o.ordertime AND o.ordertime + INTERVAL '4' HOUR
иҝҷдёӘжҹҘиҜўдјҡдёә Orders иЎЁи®ҫзҪ®дәҶ o.ordertime > s.shiptime- INTERVAL вҖҳ4вҖҷ HOUR зҡ„ж—¶й—ҙдёӢз•ҢпјҲеӣҫ4пјүгҖӮ
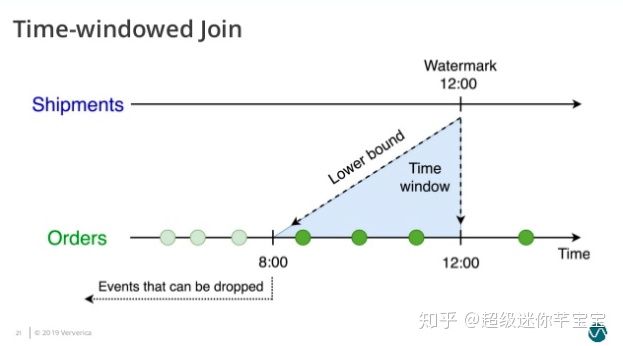
еӣҫ4. Time-Windowed Join зҡ„ж—¶й—ҙдёӢз•Ң - Orders иЎЁ
并дёә Shipmenets иЎЁи®ҫзҪ®дәҶ s.shiptime >= o.ordertime зҡ„ж—¶й—ҙдёӢз•ҢпјҲеӣҫ5пјүгҖӮ
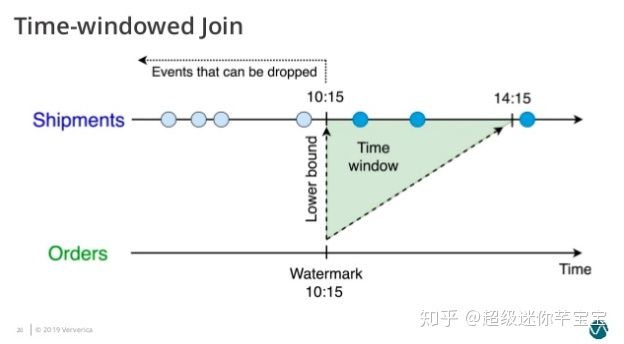
еӣҫ5. Time-Windowed Join зҡ„ж—¶й—ҙдёӢз•Ң - Shipment иЎЁ
еӣ жӯӨдёӨдёӘиҫ“е…ҘиЎЁйғҪеҸӘйңҖиҰҒзј“еӯҳеңЁж—¶й—ҙдёӢз•Ңд»ҘдёҠзҡ„ж•°жҚ®пјҢе°Ҷз©әй—ҙеҚ з”Ёз»ҙжҢҒеңЁеҗҲзҗҶзҡ„иҢғеӣҙгҖӮ
дёҚиҝҮиҷҪ然еә•еұӮе®һзҺ°дёҠжІЎжңүй—®йўҳпјҢдҪҶеҰӮдҪ•йҖҡиҝҮ SQL иҜӯжі•е®ҡд№үж—¶й—ҙд»ҚжҳҜйҡҫзӮ№гҖӮе°Ҫз®ЎеңЁе®һж—¶и®Ўз®—йўҶеҹҹ Event TimeгҖҒProcessing TimeгҖҒWatermark иҝҷдәӣжҰӮеҝөе·Із»ҸжҲҗдёәдёҡз•Ңе…ұиҜҶпјҢдҪҶеңЁ SQL йўҶеҹҹеҜ№ж—¶й—ҙж•°жҚ®зұ»еһӢзҡ„ж”ҜжҢҒд»ҚжҜ”иҫғејұ[4]гҖӮеӣ жӯӨпјҢе®ҡд№ү Watermark е’Ңж—¶й—ҙиҜӯд№үйғҪйңҖиҰҒйҖҡиҝҮзј–зЁӢ API зҡ„ж–№ејҸе®ҢжҲҗпјҢжҜ”еҰӮд»Һ DataStream иҪ¬жҚўиҮі Table пјҢдёҚиғҪеҚ•зәҜйқ SQL е®ҢжҲҗгҖӮиҝҷж–№йқўзҡ„ж”ҜжҢҒ Flink зӨҫеҢәи®ЎеҲ’йҖҡиҝҮжӢ“еұ• SQL ж–№иЁҖжқҘе®ҢжҲҗпјҢж„ҹе…ҙи¶Јзҡ„иҜ»иҖ…еҸҜд»ҘйҖҡиҝҮ FLIP-66[7] жқҘиҝҪиёӘиҝӣеәҰгҖӮ
иҷҪ然 Timed-Windowed Join и§ЈеҶідәҶиө„жәҗй—®йўҳпјҢдҪҶд№ҹйҷҗеҲ¶дәҶдҪҝз”ЁеңәжҷҜ: Join дёӨдёӘиҫ“е…ҘжөҒйғҪеҝ…йЎ»жңүж—¶й—ҙдёӢз•ҢпјҢи¶…иҝҮд№ӢеҗҺеҲҷдёҚеҸҜи®ҝй—®гҖӮиҝҷеҜ№дәҺеҫҲеӨҡ Join з»ҙиЎЁзҡ„дёҡеҠЎжқҘиҜҙжҳҜдёҚйҖӮз”Ёзҡ„пјҢеӣ дёәеҫҲеӨҡжғ…еҶөдёӢз»ҙ表并没жңүж—¶й—ҙз•ҢйҷҗгҖӮй’ҲеҜ№иҝҷдёӘй—®йўҳпјҢFlink жҸҗдҫӣдәҶ Temporal Table Join жқҘж»Ўи¶із”ЁжҲ·йңҖжұӮгҖӮ
Temporal Table Join зұ»дјјдәҺ Hash JoinпјҢе°Ҷиҫ“е…ҘеҲҶдёә Build Table е’Ң Probe TableгҖӮеүҚиҖ…дёҖиҲ¬жҳҜзә¬еәҰиЎЁзҡ„ changelogпјҢеҗҺиҖ…дёҖиҲ¬жҳҜдёҡеҠЎж•°жҚ®жөҒпјҢе…ёеһӢжғ…еҶөдёӢеҗҺиҖ…зҡ„ж•°жҚ®йҮҸеә”иҜҘиҝңеӨ§дәҺеүҚиҖ…гҖӮеңЁ Temporal Table Join дёӯпјҢBuild Table жҳҜдёҖдёӘеҹәдәҺ append-only ж•°жҚ®жөҒзҡ„еёҰж—¶й—ҙзүҲжң¬зҡ„и§ҶеӣҫпјҢжүҖд»ҘеҸҲз§°дёә Temporal TableгҖӮTemporal Table иҰҒжұӮе®ҡд№үдёҖдёӘдё»й”®е’Ңз”ЁдәҺзүҲжң¬еҢ–зҡ„еӯ—ж®өпјҲйҖҡеёёе°ұжҳҜ Event Time ж—¶й—ҙеӯ—ж®өпјүпјҢд»ҘеҸҚжҳ и®°еҪ•еңЁдёҚеҗҢж—¶й—ҙзҡ„еҶ…е®№гҖӮ
жҜ”еҰӮе…ёеһӢзҡ„дёҖдёӘдҫӢеӯҗжҳҜеҜ№е•Ҷдёҡи®ўеҚ•йҮ‘йўқиҝӣиЎҢжұҮзҺҮиҪ¬жҚўгҖӮеҒҮи®ҫжңүдёҖдёӘ Orders жөҒи®°еҪ•и®ўеҚ•йҮ‘йўқпјҢйңҖиҰҒе’Ң RatesHistory жұҮзҺҮжөҒиҝӣиЎҢ JoinгҖӮRatesHistory д»ЈиЎЁдёҚеҗҢиҙ§еёҒиҪ¬дёәж—Ҙе…ғзҡ„жұҮзҺҮпјҢжҜҸеҪ“жұҮзҺҮжңүеҸҳеҢ–ж—¶е°ұдјҡжңүдёҖжқЎжӣҙж–°и®°еҪ•гҖӮдёӨдёӘиЎЁеңЁжҹҗдёҖж—¶й—ҙиҠӮзӮ№еҶ…е®№еҰӮдёӢ:
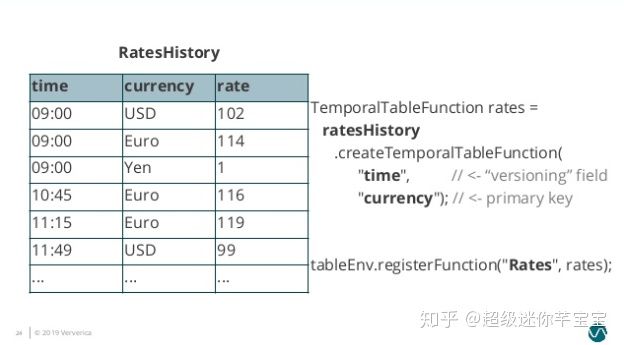
еӣҫ6. Temporal Table Join Example]
жҲ‘们е°Ҷ RatesHistory жіЁеҶҢдёәдёҖдёӘеҗҚдёә Rates зҡ„ Temporal TableпјҢи®ҫе®ҡдё»й”®дёә currencyпјҢзүҲжң¬еӯ—ж®өдёә timeгҖӮ
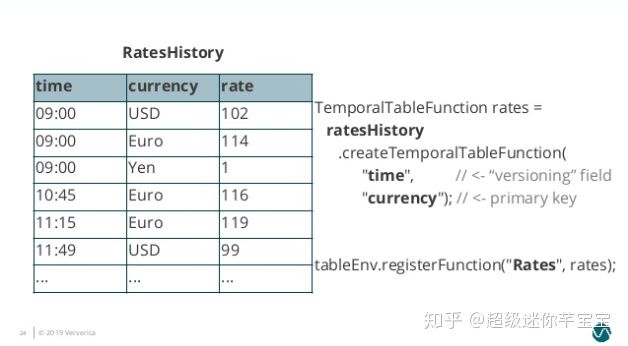
еӣҫ7. Temporal Table Registration]
жӯӨеҗҺз»ҷ Rates жҢҮе®ҡж—¶й—ҙзүҲжң¬пјҢRates еҲҷдјҡеҹәдәҺ RatesHistory жқҘи®Ўз®—з¬ҰеҗҲж—¶й—ҙзүҲжң¬зҡ„жұҮзҺҮиҪ¬жҚўеҶ…е®№гҖӮ
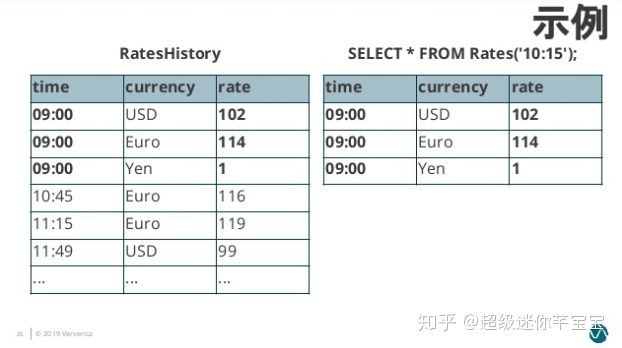
еӣҫ8. Temporal Table Content]
еңЁ Rates зҡ„её®еҠ©дёӢпјҢжҲ‘们еҸҜд»Ҙе°ҶдёҡеҠЎйҖ»иҫ‘з”Ёд»ҘдёӢзҡ„жҹҘиҜўжқҘиЎЁиҫҫ:
SELECT
o.amount * r.rate
FROM
Orders o,
LATERAL Table(Rates(o.time)) r
WHERE
o.currency = r.currency
еҖјеҫ—жіЁж„Ҹзҡ„жҳҜпјҢдёҚеҗҢдәҺеңЁ Regular Join е’Ң Time-Windowed Join дёӯдёӨдёӘиЎЁжҳҜе№ізӯүзҡ„пјҢд»»ж„ҸдёҖдёӘиЎЁзҡ„ж–°и®°еҪ•йғҪеҸҜд»ҘдёҺеҸҰдёҖиЎЁзҡ„еҺҶеҸІи®°еҪ•иҝӣиЎҢеҢ№й…ҚпјҢеңЁ Temporal Table Join дёӯпјҢTemoparal Table зҡ„жӣҙж–°еҜ№еҸҰдёҖиЎЁеңЁиҜҘж—¶й—ҙиҠӮзӮ№д»ҘеүҚзҡ„и®°еҪ•жҳҜдёҚеҸҜи§Ғзҡ„гҖӮиҝҷж„Ҹе‘ізқҖжҲ‘们еҸӘйңҖиҰҒдҝқеӯҳ Build Side зҡ„и®°еҪ•зӣҙеҲ° Watermark и¶…иҝҮи®°еҪ•зҡ„зүҲжң¬еӯ—ж®өгҖӮеӣ дёә Probe Side зҡ„иҫ“е…ҘзҗҶи®әдёҠдёҚдјҡеҶҚжңүж—©дәҺ Watermark зҡ„и®°еҪ•пјҢиҝҷдәӣзүҲжң¬зҡ„ж•°жҚ®еҸҜд»Ҙе®үе…Ёең°иў«жё…зҗҶжҺүгҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңFlink SQLжҖҺд№Ҳе®һзҺ°ж•°жҚ®жөҒзҡ„JoinвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





