MySQL 5.6дёӯзҡ„еӯ—з¬ҰйӣҶ
иҝҷзҜҮж–Үз« д»Ӣз»Қзҡ„жҳҜMySQL 5.6дёӯзҡ„еӯ—з¬ҰйӣҶпјҢеҹәжң¬жҳҜжҲ‘д»ҘеүҚеӯҰд№ MySQL 5.6жүӢеҶҢж—¶ж•ҙзҗҶиҖҢжқҘгҖӮ
жҰӮи®ә
еҹәзЎҖжҰӮеҝө
еӯ—з¬ҰйӣҶ(character set)жҳҜзј–з Ғе’Ңеӯ—з¬Ұз¬ҰеҸ·зҡ„жҳ е°„йӣҶеҗҲгҖӮжҺ’еәҸ规еҲҷ(collation)жҳҜз”ЁдәҺжҜ”иҫғеӯ—з¬ҰйӣҶдёӯеӯ—з¬Ұзҡ„规еҲҷйӣҶгҖӮ
зҺ°еңЁжҲ‘们иҮӘе®ҡд№үдёҖдёӘз®ҖеҚ•зҡ„еӯ—з¬ҰйӣҶcharacter setгҖӮеҒҮи®ҫжҲ‘们жңүдёҖдёӘд»…жңүеӣӣдёӘеӯ—жҜҚзҡ„еӯ—жҜҚиЎЁпјҡAгҖҒBгҖҒaгҖҒbгҖӮжҲ‘们з»ҷжҜҸдёӘеӯ—жҜҚдёҖдёӘж•°еӯ—пјҡA = 0пјҢB = 1пјҢa = 2пјҢb = 3гҖӮеӯ—жҜҚAжҳҜдёҖдёӘеӯ—з¬Ұз¬ҰеҸ·пјҢж•°еӯ—0жҳҜAзҡ„зј–з ҒпјҢиҝҷеӣӣдёӘеӯ—жҜҚе’Ңе®ғ们编з Ғзҡ„жҳ е°„е°ұжҳҜдёҖдёӘеӯ—з¬ҰйӣҶгҖӮ
еҒҮи®ҫжҲ‘们жғіиҰҒжҜ”иҫғдёӨдёӘеӯ—з¬ҰдёІзҡ„еҖјпјҡAе’ҢBгҖӮжңҖз®ҖеҚ•зҡ„еҠһжі•е°ұжҳҜжҹҘзңӢе®ғ们зҡ„зј–з ҒпјҡAзҡ„зј–з Ғдёә0пјҢBзҡ„зј–з Ғдёә1гҖӮеӣ дёә0е°ҸдәҺ1пјҢжҲ‘们иҜҙAе°ҸдәҺBгҖӮжҲ‘们жүҖеҒҡзҡ„е°ұжҳҜеә”з”ЁжҺ’еәҸ规еҲҷеҲ°еӯ—з¬ҰйӣҶгҖӮиҝҷдәӣ规еҲҷзҡ„йӣҶеҗҲ(еңЁиҜҘзӨәдҫӢдёӯеҸӘжңүдёҖжқЎи§„еҲҷ)е°ұжҳҜжҺ’еәҸ规еҲҷcollationпјҡжҜ”иҫғе®ғ们зҡ„зј–з ҒгҖӮеҪ“然пјҢзҺ°е®һдёӯзҡ„еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷиҰҒеӨҚжқӮең°еӨҡпјҢдҪҶеҹәжң¬зҗҶеҝөжҳҜдёҠйқўжүҖиҜҙзҡ„йӮЈж ·гҖӮ
repertoireжҳҜжҢҮдёҖдёӘеӯ—з¬ҰйӣҶдёӯеӯ—з¬Ұзҡ„йӣҶеҗҲгҖӮеӯ—з¬ҰдёІиЎЁиҫҫејҸйғҪжңүдёҖдёӘrepertoireеұһжҖ§пјҢиҝҷдёӘеұһжҖ§еҸҜд»ҘжңүдёӨдёӘеҖјпјҡ
ASCIIпјҡиЎЁиҫҫејҸеҸӘиғҪеҢ…еҗ«Unicodeзј–з ҒеңЁU+0000еҲ°U+007FиҢғеӣҙеҶ…зҡ„еӯ—з¬ҰгҖӮ
UNICODEпјҡиЎЁиҫҫејҸеҸҜд»ҘеҢ…еҗ«Unicodeзј–з ҒеңЁU+0000еҲ°U+10FFFFиҢғеӣҙеҶ…зҡ„еӯ—з¬ҰгҖӮиҝҷеҢ…жӢ¬йӮЈдәӣеңЁBasic Multilingual Plane(BMP)иҢғеӣҙеҶ…(U+0000 еҲ° U+FFFF)зҡ„еӯ—з¬ҰпјҢе’ҢеңЁBMPиҢғеӣҙеӨ–(U+01000 еҲ° U+10FFFF)зҡ„еўһиЎҘеӯ—з¬ҰгҖӮ
ASCIIиҢғеӣҙжҳҜUNICODEиҢғеӣҙзҡ„дёҖдёӘеӯҗйӣҶпјҢеӣ жӯӨпјҢдёҖдёӘASCII repertoireзҡ„еӯ—з¬ҰдёІеҸҜд»Ҙе®үе…Ёең°иҪ¬жҚўжҲҗUNICODE repertoireеӯ—з¬ҰдёІзҡ„еӯ—з¬ҰйӣҶ(жҲ–д»»дҪ•еҢ…еҗ«ASCIIиҢғеӣҙзҡ„еӯ—з¬ҰйӣҶ)пјҢиҖҢдёҚдјҡжңүд»»дҪ•й—®йўҳгҖӮд»ҺиҝҷйҮҢжҲ‘们еҸҜд»Ҙеҫ—еҲ°дёӨдёӘз»“и®әпјҡ
1гҖҒзү№е®ҡзҡ„еӯ—з¬ҰйӣҶжӢҘжңүзү№е®ҡиҢғеӣҙзҡ„repertoireпјҢиҝҷе°ұйҷҗе®ҡдәҶдҪҝз”ЁиҜҘеӯ—з¬ҰйӣҶзҡ„иЎЁ/еӯ—ж®өд№ҹе°ұеҸӘиғҪдҪҝз”Ёзү№е®ҡиҢғеӣҙзҡ„еӯ—з¬ҰпјҢи¶…еҮәиҢғеӣҙзҡ„еӯ—з¬Ұе°ҶдёҚдјҡиў«йӮЈдёӘеӯ—з¬ҰйӣҶжүҖж”ҜжҢҒгҖӮжҜ”еҰӮпјҢasciiеӯ—з¬ҰйӣҶзҡ„repertoireиҢғеӣҙе°ұжҳҜASCIIпјҢеӣ жӯӨпјҢиӢҘдҪҝз”ЁиҜҘеӯ—з¬ҰйӣҶпјҢе°ұеҸӘиғҪдҪҝз”ЁUnicodeзј–з ҒеңЁU+0000еҲ°U+007FиҢғеӣҙеҶ…зҡ„еӯ—з¬ҰгҖӮ
2гҖҒеӯ—з¬ҰеӯҗйӣҶзҡ„еӯ—з¬ҰйӣҶеҸҜд»Ҙе®үе…Ёең°иҪ¬жҚўжҲҗе®ғзҡ„и¶…йӣҶзҡ„еӯ—з¬ҰйӣҶпјҢиҖҢдёҚдјҡжңүд»»дҪ•й—®йўҳгҖӮиҝҷзӮ№еңЁдёҚеҗҢеӯ—з¬ҰйӣҶж··з”Ёж—¶еҫҲжңүз”ЁпјҢMySQLеҸҜд»Ҙе®ҢжҲҗиҮӘеҠЁиҪ¬жҚўгҖӮдҪҶжҳҜпјҢеҸҚиҝҮжқҘжҳҜдёҚиЎҢзҡ„гҖӮ
MySQLдёӯзҡ„зҡ„еёёи§Ғеӯ—з¬ҰйӣҶпјҡ
utf8еӯ—з¬ҰйӣҶпјҡжҳҜдёҖз§ҚUTF-8зј–з Ғзҡ„Unicodeеӯ—з¬ҰйӣҶпјҢжҜҸдёӘеӯ—з¬ҰеҚ з”Ё1еҲ°3дёӘеӯ—иҠӮгҖӮеҸӘиғҪиҰҶзӣ–BMPиҢғеӣҙеҶ…зҡ„еӯ—з¬ҰпјҢе…¶дёӯдёҚеҚ•еҚ•жңүиӢұж–Үеӯ—з¬ҰпјҢд№ҹеҢ…жӢ¬дёӯж–Үеӯ—з¬ҰзӯүгҖӮ
utf8mb4еӯ—з¬ҰйӣҶпјҡжҳҜдёҖз§ҚUTF-8зј–з Ғзҡ„Unicodeеӯ—з¬ҰйӣҶпјҢжҜҸдёӘеӯ—з¬ҰеҚ з”Ё1еҲ°4дёӘеӯ—иҠӮгҖӮеҸҜд»ҘиҰҶзӣ–BMPиҢғеӣҙеҶ…зҡ„еӯ—з¬Ұе’ҢеўһиЎҘеӯ—з¬ҰгҖӮBMPиҢғеӣҙеҶ…зҡ„еӯ—з¬Ұзј–з Ғе’Ңutf8еӯ—з¬ҰйӣҶдёӯзҡ„зј–з ҒжҳҜе®Ңе…ЁзӣёеҗҢзҡ„пјҢй•ҝеәҰд№ҹжҳҜе®Ңе…ЁдёҖж ·зҡ„пјҢжүҖд»Ҙutf8mb4еӯ—з¬ҰйӣҶеҸҜд»Ҙе…је®№utf8еӯ—з¬ҰйӣҶгҖӮ
е…ғж•°жҚ®зҡ„еӯ—з¬ҰйӣҶ
е…ғж•°жҚ®(Metadata)жҳҜ"е…ідәҺж•°жҚ®зҡ„ж•°жҚ®"гҖӮд»»дҪ•жҸҸиҝ°ж•°жҚ®еә“зҡ„дёңиҘҝ вҖ” дёҺж•°жҚ®еә“дёӯзҡ„еҶ…е®№зӣёеҜ№пјҢйғҪжҳҜе…ғж•°жҚ®гҖӮеӣ жӯӨпјҢеҲ—еҗҚгҖҒж•°жҚ®еә“еҗҚгҖҒз”ЁжҲ·еҗҚгҖҒзүҲжң¬еҗҚе’ҢSHOWе‘Ҫд»Өзҡ„еӨ§еӨҡж•°еӯ—з¬ҰдёІз»“жһңйғҪжҳҜе…ғж•°жҚ®гҖӮиҝҷеҜ№дәҺinformation_schemaеә“дёӯиЎЁзҡ„еҶ…е®№д№ҹеҗҢж ·жӯЈзЎ®пјҢеӣ дёәд»Һе®ҡд№үдёҠжқҘиҜҙпјҢйӮЈдәӣиЎЁеҢ…еҗ«е…ідәҺж•°жҚ®еә“еҜ№иұЎзҡ„дҝЎжҒҜгҖӮе…ғж•°жҚ®зҡ„е‘ҲзҺ°еҝ…йЎ»ж»Ўи¶іиҝҷдәӣиҰҒжұӮпјҡ
жүҖжңүзҡ„е…ғж•°жҚ®йғҪеҝ…йЎ»дҪҝз”ЁзӣёеҗҢзҡ„еӯ—з¬ҰйӣҶгҖӮеҗҰеҲҷпјҢеҜ№information_schemaеә“дёӯзҡ„иЎЁжү§иЎҢSHOWжҲ–SELECTе‘Ҫд»Өе°Ҷж— жі•жӯЈеёёиҝҗиЎҢпјҢеӣ дёәиҝҷдәӣж“ҚдҪңиҝ”еӣһзҡ„з»“жһңдёӯпјҢеҗҢдёҖеҲ—зҡ„дёҚеҗҢиЎҢе°ҶдјҡеңЁдёҚеҗҢзҡ„еӯ—з¬ҰйӣҶдёӯгҖӮ
е…ғж•°жҚ®еҝ…йЎ»еҢ…еҗ«жүҖжңүиҜӯиЁҖзҡ„жүҖжңүеӯ—з¬ҰгҖӮеҗҰеҲҷпјҢз”ЁжҲ·е°Ҷж— жі•дҪҝз”Ёе®ғ们иҮӘе·ұжң¬ең°зҡ„иҜӯиЁҖжқҘиў«иЎЁжҲ–еҲ—е‘ҪеҗҚгҖӮ
дёәдәҶж»Ўи¶ідёҠйқўзҡ„иҰҒжұӮпјҢMySQLе°Ҷе…ғж•°жҚ®еӯҳеӮЁеңЁUnicodeеӯ—з¬ҰйӣҶдёӯпјҢеҮҶзЎ®ең°иҜҙжҳҜUTF-8гҖӮеҸӘиҰҒдҪ дёҚдҪҝз”Ёж–№иЁҖжҲ–йқһжӢүдёҒеӯ—з¬ҰпјҢиҝҷдёҚдјҡжңүд»»дҪ•й—®йўҳгҖӮдҪҶеҰӮжһңдҪ дҪҝз”ЁдәҶпјҢдҪ еә”иҜҘж„ҸиҜҶеҲ°е…ғж•°жҚ®жҳҜUTF-8еӯ—з¬ҰйӣҶзҡ„гҖӮ
MySQLе°Ҷзі»з»ҹеҸҳйҮҸcharacter_set_systemзҡ„еҖји®ҫзҪ®дёәдёҺе…ғж•°жҚ®жүҖдҪҝз”Ёзҡ„еӯ—з¬ҰйӣҶзҡ„зӣёеҗҢпјҡ
mysql> SHOW VARIABLES LIKE 'character_set_system'; +-----------------------+----------+ | Variable_name | Value | +-----------------------+----------+ | character_set_system | utf8 | +-----------------------+---------+ |
е…ғж•°жҚ®зҡ„еӯҳеӮЁдҪҝз”ЁUnicode并дёҚж„Ҹе‘ізқҖпјҢжңҚеҠЎеҷЁиҝ”еӣһDESCRIBEеҮҪж•°зҡ„з»“жһңзҡ„еҲ—еҗҚж—¶й»ҳи®ӨдјҡдҪҝз”Ёcharacter_set_systemеҸҳйҮҸжүҖи®ҫзҪ®зҡ„еӯ—з¬ҰйӣҶгҖӮеҪ“дҪ дҪҝз”ЁSELECT column1 FROM tе‘Ҫд»Өж—¶пјҢжңҚеҠЎеҷЁиҝ”еӣһз»ҷе®ўжҲ·з«Ҝзҡ„column1иҝҷдёӘеҲ—еҗҚиҮӘиә«зҡ„еӯ—з¬ҰйӣҶпјҢжҳҜз”ұзі»з»ҹеҸҳйҮҸcharacter_set_resultsзҡ„еҖјеҶіе®ҡзҡ„пјҢй»ҳи®ӨеҖјжҳҜlatin1пјҡ
mysql> SHOW VARIABLES LIKE 'character_set_results'; +-----------------------+---------+ | Variable_name | Value | +-----------------------+---------+ | character_set_results | latin1 | +-----------------------+---------+ |
еҰӮжһңдҪ жғіиҰҒжңҚеҠЎеҷЁиҝ”еӣһе…ғж•°жҚ®з»ҷе®ўжҲ·з«Ҝж—¶дҪҝз”ЁдёҚеҗҢзҡ„еӯ—з¬ҰйӣҶпјҢе°ұдҪҝз”ЁSET NAMES'character_set' е‘Ҫд»ӨжқҘејәеҲ¶жңҚеҠЎеҷЁе°ҶеҪ“еүҚеӯ—з¬ҰйӣҶиҪ¬жҚўжҲҗжҢҮе®ҡзҡ„character_setпјҢиҜҘе‘Ҫд»ӨдјҡиҮӘеҠЁи®ҫзҪ®character_set_resultsзӯүзӣёе…ізҡ„зі»з»ҹеҸҳйҮҸпјҢд»…еҜ№еҪ“еүҚдјҡиҜқз”ҹж•ҲгҖӮеҰӮжһңcharacter_set_resultsиў«и®ҫдёәNULLпјҢжңҚеҠЎеҷЁиҝ”еӣһе…ғж•°жҚ®ж—¶е°ҶдёҚиҝӣиЎҢиҪ¬жҚўпјҢиҖҢдҪҝз”Ёе®ғеҺҹжң¬зҡ„еӯ—з¬ҰйӣҶ(еҚіеҸҳйҮҸcharacter_set_systemжүҖжҢҮзӨәзҡ„еӯ—з¬ҰйӣҶ)гҖӮ
еҸҰеӨ–пјҢе®ўжҲ·з«ҜзЁӢеәҸд№ҹеҸҜд»ҘеңЁжҺҘ收еҲ°жңҚеҠЎеҷЁиҝ”еӣһзҡ„ж•°жҚ®еҗҺжү§иЎҢеӯ—з¬ҰйӣҶиҪ¬жҚўгҖӮеңЁе®ўжҲ·з«Ҝжү§иЎҢеӯ—з¬ҰйӣҶиҪ¬жҚўж•ҲзҺҮжӣҙй«ҳпјҢдҪҶ并дёҚжҳҜжүҖжңүе®ўжҲ·з«ҜйғҪж”ҜжҢҒиҝҷдёӘеҠҹиғҪгҖӮ
д»ҺдёҠйқўзҡ„иҜҙжҳҺеҸҜд»ҘзңӢеҮәпјҢеӯ—з¬ҰйӣҶй—®йўҳдёҚеҚ•еҚ•еҪұе“Қж•°жҚ®еӯҳеӮЁпјҢиҝҳдјҡеҪұе“Қе®ўжҲ·з«ҜдёҺMySQLжңҚеҠЎеҷЁд№Ӣй—ҙзҡ„йҖҡдҝЎгҖӮеҰӮжһңдҪ жғіиҰҒи®©е®ўжҲ·з«ҜзЁӢеәҸдҪҝз”ЁдёҺй»ҳи®Өеӯ—з¬ҰйӣҶдёҚзӣёеҗҢзҡ„еӯ—з¬ҰйӣҶдёҺжңҚеҠЎеҷЁз«ҜйҖҡдҝЎпјҢдҪ йңҖиҰҒжҢҮжҳҺе“ӘдёҖдёӘгҖӮжҜ”еҰӮпјҢиҰҒдҪҝз”Ё utf8 еӯ—з¬ҰйӣҶпјҢжү§иЎҢе‘Ҫд»Өпјҡ
еҪ“然пјҢеӣ дёәиҝҳжІЎжңүеҶҚMySQLй…ҚзҪ®ж–Ү件дёӯи®ҫзҪ®зӣёе…іеҸҳйҮҸпјҢжүҖд»ҘиҝҷйҮҢзҡ„и®ҫзҪ®е№¶дёҚжҳҜжҢҒд№…зҡ„гҖӮд»…еңЁеҪ“еүҚдјҡиҜқдёӯз”ҹж•ҲгҖӮ
еӯҳеӮЁж•°жҚ®ж—¶зҡ„еӯ—з¬ҰйӣҶ
MySQLж”ҜжҢҒеңЁMySQLжңҚеҠЎеҷЁ(server)гҖҒж•°жҚ®еә“(database)гҖҒиЎЁ(table)е’ҢеҲ—(column)еӣӣдёӘзә§еҲ«жҢҮе®ҡжүҖдҪҝз”Ёзҡ„еӯ—з¬ҰйӣҶгҖӮMySQLж”ҜжҢҒеҜ№MyISAMгҖҒMEMORYе’ҢInnoDBеӯҳеӮЁеј•ж“Һй…ҚзҪ®еӯ—з¬ҰйӣҶгҖӮ
1гҖҒ MySQLжңҚеҠЎеҷЁжңүдёҖдёӘжңҚеҠЎеҷЁеӯ—з¬ҰйӣҶе’ҢжңҚеҠЎеҷЁжҺ’еәҸ规еҲҷпјҢеҲҶеҲ«з”ұеҸҳйҮҸcharacter_set_serverе’ҢеҸҳйҮҸcollation_serverжҺ§еҲ¶гҖӮдҪ еҸҜд»ҘеңЁMySQLй…ҚзҪ®ж–Ү件дёӯжҲ–MySQLеҗҜеҠЁйҖүйЎ№дёӯи®ҫзҪ®иҝҷдёӨдёӘйҖүйЎ№зҡ„еҖјпјҢд№ҹж”ҜжҢҒдҪҝз”Ёsetе‘Ҫд»ӨиҝӣиЎҢеҠЁжҖҒдҝ®ж”№пјҢжңүе…ЁеұҖеҖје’ҢдјҡиҜқеҖјдёӨз§ҚгҖӮcharacter_set_serverзҡ„й»ҳи®ӨеҖјжҳҜlatin1еӯ—з¬ҰйӣҶпјҢcollation_serverзҡ„й»ҳи®ӨеҖјжҳҜlatin1_swedish_ciжҺ’еәҸ规еҲҷгҖӮеҰӮжһңдҪ еҸӘжҢҮе®ҡдәҶеӯ—з¬ҰйӣҶпјҢиҖҢжІЎжңүжҢҮе®ҡжҺ’еәҸ规еҲҷпјҢйӮЈд№Ҳзі»з»ҹдјҡиҮӘеҠЁе°ҶжҺ’еәҸ规еҲҷи®ҫзҪ®дёәиҜҘеӯ—з¬ҰйӣҶзҡ„й»ҳи®ӨжҺ’еәҸ规еҲҷгҖӮжҜ”еҰӮпјҢеҰӮжһңдҪ е°Ҷcharacter_set_serverзҡ„еҖји®ҫзҪ®дёәutf8mb4еӯ—з¬ҰйӣҶиҖҢжІЎжңүи®ҫзҪ®collation_serverзҡ„еҖјпјҢйӮЈд№Ҳcollation_serverзҡ„еҖјдјҡиҮӘеҠЁеҸҳдёәutf8mb4_general_ciжҺ’еәҸ规еҲҷпјҢеӣ дёәutf8mb4_general_ciжҳҜutf8mb4еӯ—з¬ҰйӣҶзҡ„й»ҳи®ӨжҺ’еәҸ规еҲҷгҖӮ
[root@gw ~]# vim /usr/my.cnf [mysqld] character-set-server=utf8mb4 collation-server=utf8mb4_general_ci |
еңЁдҪҝз”ЁCREATE DATABASEе‘Ҫд»ӨеҲӣе»әж•°жҚ®еә“ж—¶еҰӮжһңжІЎжңүжҢҮе®ҡж•°жҚ®еә“еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷпјҢ йӮЈд№ҲжңҚеҠЎеҷЁз«Ҝеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷе°ұдјҡдҪңдёәй»ҳи®ӨеҖјпјҢе®ғ们зҡ„з”ЁйҖ”д»…еңЁдәҺиҝҷйҮҢгҖӮеӣ жӯӨеҸҜд»ҘиҜҙпјҢжңҚеҠЎеҷЁз«Ҝеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷжҳҜMySQLж•°жҚ®еә“дёӯж•°жҚ®(йҷӨе…ғж•°жҚ®еӨ–)зҡ„еҸҜиғҪзҡ„й»ҳи®ӨеҖјгҖӮ
2гҖҒ MySQLдёӯзҡ„жҜҸдёҖдёӘеә“йғҪжңүдёҖдёӘж•°жҚ®еә“еӯ—з¬ҰйӣҶе’Ңж•°жҚ®еә“жҺ’еәҸ规еҲҷгҖӮCREATE DATABASE е’Ң ALTER DATABASEиҜӯеҸҘйғҪжңүйҖүйЎ№еҸҜд»ҘжҢҮе®ҡж•°жҚ®еә“еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷпјҡ
CREATE DATABASE db_name [[DEFAULT] CHARACTER SET charset_name] [[DEFAULT] COLLATE collation_name] ALTER DATABASE db_name [[DEFAULT] CHARACTER SET charset_name] [[DEFAULT] COLLATE collation_name] |
MySQLжҢүз…§дёӢйқўзҡ„ж–№ејҸеҶіе®ҡж•°жҚ®еә“зҡ„еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷпјҡ
еҰӮжһңCHARACTER SETcharset_nameе’ҢCOLLATEcollation_nameйғҪжҢҮе®ҡдәҶпјҢйӮЈд№Ҳж•°жҚ®еә“еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷе°ұжҳҜжүҖжҢҮе®ҡзҡ„charset_nameе’Ңcollation_nameгҖӮ
еҰӮжһңеҸӘжҢҮе®ҡдәҶCHARACTER SETcharset_nameиҖҢжІЎжңүжҢҮе®ҡCOLLATEпјҢйӮЈд№Ҳж•°жҚ®еә“еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷе°ұжҳҜжүҖжҢҮе®ҡзҡ„charset_nameе’ҢиҜҘеӯ—з¬ҰйӣҶй»ҳи®Өзҡ„жҺ’еәҸ规еҲҷгҖӮ
еҰӮжһңеҸӘжҢҮе®ҡдәҶCOLLATEcollation_nameиҖҢжІЎжңүжҢҮе®ҡCHARACTER SETпјҢйӮЈд№Ҳж•°жҚ®еә“еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷе°ұжҳҜиҜҘcollation_nameзӣёе…іиҒ”зҡ„еӯ—з¬ҰйӣҶе’ҢжүҖжҢҮе®ҡзҡ„collation_nameгҖӮ
еҰӮжһңCHARACTER SETcharset_nameе’ҢCOLLATEcollation_nameйғҪжІЎжңүжҢҮе®ҡпјҢйӮЈд№Ҳж•°жҚ®еә“еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷе°ұдҪҝз”ЁMySQLжңҚеҠЎеҷЁеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷпјҲи§ҒдёҠдёҖе°ҸиҠӮпјүгҖӮ
ж•°жҚ®еә“й»ҳи®Өеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷеҸҜд»Ҙд»Һcharacter_set_database е’Ң collation_databaseиҝҷдёӨдёӘзі»з»ҹеҸҳйҮҸеҫ—зҹҘгҖӮиҰҒжҹҘзңӢжҢҮе®ҡж•°жҚ®еә“зҡ„й»ҳи®Өеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷпјҢдҪҝз”Ёе‘Ҫд»Өпјҡ
mysql> use db_name; mysql> SELECT @@character_set_database, @@collation_database; |
д№ҹеҸҜд»ҘдҪҝз”ЁдёӢйқўзҡ„е‘Ҫд»Өпјҡ
mysql> SELECT DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME FROM INFORMATION_SCHEMA.SCHEMATA WHERE SCHEMA_NAME = 'db_name'; |
ж•°жҚ®еә“еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷеҪұе“ҚжңҚеҠЎеҷЁиҝҗиЎҢзҡ„иҝҷдәӣж–№йқўпјҡ
еҜ№дәҺCREATE TABLEиҜӯеҸҘпјҢеҰӮжһңеҲӣе»әиЎЁж—¶жңӘжҳҫејҸжҢҮе®ҡеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷпјҢж•°жҚ®еә“еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷиў«з”ЁеҒҡиЎЁзҡ„й»ҳи®Өеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷгҖӮиҰҒиҰҶзӣ–иҜҘиЎҢдёәпјҢжҳҫејҸдҪҝз”ЁCHARACTER SET е’Ң COLLATEйҖүйЎ№гҖӮ
еҜ№дәҺдёҚеҢ…жӢ¬CHARACTER SETйҖүйЎ№зҡ„LOAD DATAиҜӯеҸҘпјҢжңҚеҠЎеҷЁдҪҝз”ЁеҸҳйҮҸcharacter_set_databaseжүҖжҢҮзӨәзҡ„еӯ—з¬ҰйӣҶжқҘи§Јжһҗж–Ү件дёӯзҡ„дҝЎжҒҜгҖӮиҰҒиҰҶзӣ–иҜҘиЎҢдёәпјҢжҳҫејҸдҪҝз”ЁCHARACTER SETйҖүйЎ№гҖӮ
еҜ№дәҺеӯҳеӮЁзҡ„зЁӢеәҸ(иҝҮзЁӢе’ҢеҮҪж•°)пјҢеңЁеҲӣе»әзЁӢеәҸж—¶еҰӮжһңеӯ—з¬Ұж•°жҚ®еҸӮж•°(character data parameters)зҡ„еЈ°жҳҺжңӘдҪҝз”ЁCHARACTER SET е’Ң COLLATEйҖүйЎ№пјҢйӮЈд№Ҳж•°жҚ®еә“еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷдјҡз”ЁеҒҡеӯ—з¬Ұж•°жҚ®еҸӮж•°зҡ„еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷгҖӮиҰҒиҰҶзӣ–иҜҘиЎҢдёәпјҢжҳҫејҸдҪҝз”ЁCHARACTER SET е’Ң COLLATEйҖүйЎ№гҖӮ
3гҖҒ жҜҸдёӘиЎЁйғҪжңүдёҖдёӘиЎЁеӯ—з¬ҰйӣҶе’ҢиЎЁжҺ’еәҸ规еҲҷгҖӮCREATE TABLE е’Ң ALTER TABLEиҜӯеҸҘйғҪжңүйҖүйЎ№еҸҜд»ҘжҢҮе®ҡиЎЁеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷпјҡ
CREATE TABLE tbl_name (column_list)
[[DEFAULT] CHARACTER SET charset_name] [COLLATE collation_name]] ALTER TABLE tbl_name
[[DEFAULT] CHARACTER SET charset_name] [COLLATE collation_name] |
зӨәдҫӢпјҡ
CREATE TABLE t1 ( ... ) CHARACTER SET latin1 COLLATE latin1_danish_ci; |
MySQLжҢүз…§дёӢйқўзҡ„ж–№ејҸеҶіе®ҡиЎЁзҡ„еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷпјҡ
еҰӮжһңCHARACTER SETcharset_nameе’ҢCOLLATEcollation_nameйғҪжҢҮе®ҡдәҶпјҢйӮЈд№ҲиЎЁеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷе°ұжҳҜжүҖжҢҮе®ҡзҡ„charset_nameе’Ңcollation_nameгҖӮ
еҰӮжһңеҸӘжҢҮе®ҡдәҶCHARACTER SETcharset_nameиҖҢжІЎжңүжҢҮе®ҡCOLLATEпјҢйӮЈд№ҲиЎЁеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷе°ұжҳҜжүҖжҢҮе®ҡзҡ„charset_nameе’ҢиҜҘеӯ—з¬ҰйӣҶй»ҳи®Өзҡ„жҺ’еәҸ规еҲҷгҖӮ
еҰӮжһңеҸӘжҢҮе®ҡдәҶCOLLATEcollation_nameиҖҢжІЎжңүжҢҮе®ҡCHARACTER SETпјҢйӮЈд№ҲиЎЁеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷе°ұжҳҜиҜҘcollation_nameзӣёе…іиҒ”зҡ„еӯ—з¬ҰйӣҶе’ҢжүҖжҢҮе®ҡзҡ„collation_nameгҖӮ
еҰӮжһңCHARACTER SETcharset_nameе’ҢCOLLATEcollation_nameйғҪжІЎжңүжҢҮе®ҡпјҢйӮЈд№ҲиЎЁеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷе°ұдҪҝз”Ёж•°жҚ®еә“еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷпјҲи§ҒдёҠдёҖе°ҸиҠӮпјүгҖӮ
иЎЁеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷиў«з”ЁдҪңеҲ—е®ҡд№үдёӯзҡ„й»ҳи®ӨеҖјпјҢеҰӮжһңеңЁеҚ•дёӘзҡ„еҲ—е®ҡд№үдёӯжІЎжңүжҢҮе®ҡеҲ—еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷгҖӮиЎЁеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷжҳҜMySQLзҡ„жү©еұ•пјҢ并дёҚжҳҜж ҮеҮҶSQLдёӯзҡ„дёңиҘҝгҖӮ
4гҖҒ жҜҸдёҖдёӘ"еӯ—з¬Ұ"еҲ—пјҲеҚіжҳҜпјҢCHARгҖҒVARCHARжҲ–TEXTзұ»еһӢзҡ„еҲ—пјүйғҪжңүдёҖдёӘеҲ—еӯ—з¬ҰйӣҶе’ҢеҲ—жҺ’еәҸ规еҲҷгҖӮCREATE TABLE е’Ң ALTER TABLEиҜӯеҸҘдёӯйғҪжңүйҖүйЎ№еҸҜд»ҘжҢҮе®ҡеҲ—еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷпјҡ
col_name {CHAR | VARCHAR | TEXT} (col_length) [CHARACTER SET charset_name] [COLLATE collation_name] |
ENUMе’ҢSETзұ»еһӢзҡ„еҲ—дёӯд№ҹжңүйҖүйЎ№пјҡ
col_name {ENUM | SET} (val_list) [CHARACTER SET charset_name] [COLLATE collation_name] |
зӨәдҫӢпјҡ
CREATE TABLE t1 ( col1 VARCHAR(5) CHARACTER SET latin1 COLLATE latin1_german1_ci ); ALTER TABLE t1 MODIFY col1 VARCHAR(5) CHARACTER SET latin1 COLLATE latin1_swedish_ci; |
MySQLжҢүз…§дёӢйқўзҡ„ж–№ејҸеҶіе®ҡеҲ—зҡ„еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷпјҡ
еҰӮжһңCHARACTER SETcharset_nameе’ҢCOLLATEcollation_nameйғҪжҢҮе®ҡдәҶпјҢйӮЈд№ҲеҲ—еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷе°ұжҳҜжүҖжҢҮе®ҡзҡ„charset_nameе’Ңcollation_nameгҖӮ
еҰӮжһңеҸӘжҢҮе®ҡдәҶCHARACTER SETcharset_nameиҖҢжІЎжңүжҢҮе®ҡCOLLATEпјҢйӮЈд№ҲеҲ—еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷе°ұжҳҜжүҖжҢҮе®ҡзҡ„charset_nameе’ҢиҜҘеӯ—з¬ҰйӣҶй»ҳи®Өзҡ„жҺ’еәҸ规еҲҷгҖӮ
еҰӮжһңеҸӘжҢҮе®ҡдәҶCOLLATEcollation_nameиҖҢжІЎжңүжҢҮе®ҡCHARACTER SETпјҢйӮЈд№ҲеҲ—еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷе°ұжҳҜиҜҘcollation_nameзӣёе…іиҒ”зҡ„еӯ—з¬ҰйӣҶе’ҢжүҖжҢҮе®ҡзҡ„collation_nameгҖӮ
еҰӮжһңCHARACTER SETcharset_nameе’ҢCOLLATEcollation_nameйғҪжІЎжңүжҢҮе®ҡпјҢйӮЈд№ҲеҲ—еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷе°ұдҪҝз”ЁиЎЁеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷпјҲи§ҒдёҠдёҖе°ҸиҠӮпјүгҖӮ
еӯ—з¬ҰдёІеӯ—йқўйҮҸзҡ„еӯ—з¬ҰйӣҶ
йҷӨдәҶеүҚйқўжүҖиҜҙзҡ„пјҢжҜҸдёҖдёӘеӯ—з¬ҰдёІеӯ—йқўйҮҸ(string literal)йғҪжңүдёҖдёӘеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷгҖӮеҜ№дәҺз®ҖеҚ•иҜӯеҸҘSELECT 'string'пјҢиҝҷйҮҢз”ЁеҲ°зҡ„stringжңүдёҖдёӘиҝһжҺҘй»ҳи®Өеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷ(connection default character set and collation)пјҢеҲҶеҲ«з”ұзі»з»ҹеҸҳйҮҸcharacter_set_connectionе’Ңcollation_connectionжҺ§еҲ¶гҖӮдёҖдёӘеӯ—з¬ҰдёІеӯ—йқўйҮҸеҸҜиғҪдјҡжңүдёҖдёӘеҸҜйҖүзҡ„еӯ—з¬ҰйӣҶintroducerе’ҢCOLLATEеӯҗеҸҘпјҢжқҘе°Ҷе®ғжҢҮе®ҡдёәдҪҝз”Ёзү№е®ҡеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷзҡ„еӯ—з¬ҰдёІпјҡ
[_charset_name]'string' [COLLATE collation_name] |
зӨәдҫӢпјҡ
SELECT 'abc'; SELECT _latin1'abc'; SELECT _binary'abc'; SELECT _utf8'abc' COLLATE utf8_danish_ci; |
_charset_nameиҝҷдёӘиЎЁиҫҫејҸзҡ„жӯЈејҸеҸ«жі•еҸ«еҒҡintroducerгҖӮе®ғе‘ҠиҜүи§ЈжһҗеҷЁпјҡе®ғеҗҺйқўжүҖжҺҘзҡ„еӯ—з¬ҰдёІдҪҝз”Ёеӯ—з¬ҰйӣҶcharset_nameгҖӮMySQLжҢүз…§дёӢйқўзҡ„ж–№ејҸеҶіе®ҡеӯ—з¬ҰдёІеӯ—йқўйҮҸзҡ„еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷпјҡ
еҰӮжһң_charset_nameе’ҢCOLLATEcollation_nameйғҪжҢҮе®ҡдәҶпјҢйӮЈд№Ҳеӯ—з¬ҰдёІеӯ—йқўйҮҸеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷе°ұжҳҜжүҖжҢҮе®ҡзҡ„charset_nameе’Ңcollation_nameгҖӮ
еҰӮжһңеҸӘжҢҮе®ҡдәҶ_charset_nameиҖҢжІЎжңүжҢҮе®ҡCOLLATEпјҢйӮЈд№Ҳеӯ—з¬ҰдёІеӯ—йқўйҮҸеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷе°ұжҳҜжүҖжҢҮе®ҡзҡ„charset_nameе’ҢиҜҘеӯ—з¬ҰйӣҶй»ҳи®Өзҡ„жҺ’еәҸ规еҲҷгҖӮ
еҰӮжһңеҸӘжҢҮе®ҡдәҶCOLLATEcollation_nameиҖҢжІЎжңүжҢҮе®ҡ_charset_nameпјҢйӮЈд№Ҳеӯ—з¬ҰдёІеӯ—йқўйҮҸеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷе°ұжҳҜзі»з»ҹеҸҳйҮҸcharacter_set_connectionжүҖжҢҮе®ҡзҡ„иҝһжҺҘй»ҳи®Өеӯ—з¬ҰйӣҶе’ҢжүҖжҢҮе®ҡзҡ„collation_nameгҖӮcollation_nameеҝ…йЎ»жҳҜиҝһжҺҘй»ҳи®Өеӯ—з¬ҰйӣҶзҡ„жҺ’еәҸ规еҲҷд№ӢдёҖгҖӮ
еҰӮжһң_charset_nameе’ҢCOLLATEcollation_nameйғҪжІЎжңүжҢҮе®ҡпјҢйӮЈд№Ҳеӯ—з¬ҰдёІеӯ—йқўйҮҸеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷе°ұдҪҝз”Ёзі»з»ҹеҸҳйҮҸcharacter_set_connectionе’Ңcollation_connectionжүҖжҢҮе®ҡзҡ„иҝһжҺҘй»ҳи®Өеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷгҖӮ
иҝһжҺҘзӣёе…ізҡ„еӯ—з¬ҰйӣҶ
жҜҸдёҖдёӘе®ўжҲ·з«ҜйғҪжңүдёҖдёӘиҝһжҺҘзӣёе…ізҡ„(connection-related)еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷгҖӮдёҖдёӘ"connection"е°ұжҳҜжҢҮеҪ“дҪ иҝһжҺҘеҲ°MySQLжңҚеҠЎеҷЁж—¶зҡ„иҝһжҺҘгҖӮе®ўжҲ·з«ҜеҸ‘йҖҒSQLиҜӯеҸҘпјҢжҜ”еҰӮжҹҘиҜўпјҢжҳҜйҖҡиҝҮеҲ°жңҚеҠЎеҷЁзҡ„иҝһжҺҘгҖӮжңҚеҠЎеҷЁиҝ”еӣһж•°жҚ®пјҢжҜ”еҰӮжҹҘиҜўз»“жһңжҲ–й”ҷиҜҜдҝЎжҒҜпјҢжҳҜйҖҡиҝҮеҲ°е®ўжҲ·з«Ҝзҡ„иҝһжҺҘгҖӮиҝҷеҜјиҮҙдәҶдёӢйқўеҮ дёӘдёҺе®ўжҲ·з«ҜиҝһжҺҘзӣёе…ізҡ„еӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷзҡ„й—®йўҳпјҡ
1гҖҒ еҪ“е®ғзҰ»ејҖе®ўжҲ·з«Ҝж—¶иҜӯеҸҘзҡ„еӯ—з¬ҰйӣҶжҳҜд»Җд№Ҳпјҹ
жңҚеҠЎеҷЁдјҡе°Ҷcharacter_set_clientзі»з»ҹеҸҳйҮҸзҡ„еҖјеҪ“еҒҡжҳҜе®ўжҲ·з«ҜжүҖеҸ‘йҖҒзҡ„SQLиҜӯеҸҘзҡ„еӯ—з¬ҰйӣҶгҖӮ
2гҖҒ жңҚеҠЎеҷЁеңЁжҺҘ收еҲ°SQLиҜӯеҸҘеҗҺпјҢдјҡе°Ҷе®ғиҪ¬жҚўжҲҗд»Җд№Ҳеӯ—з¬ҰйӣҶпјҹ
жңҚеҠЎеҷЁдјҡе°Ҷе®ўжҲ·з«ҜжүҖеҸ‘йҖҒзҡ„SQLиҜӯеҸҘзҡ„еӯ—з¬ҰйӣҶпјҢд»Һcharacter_set_clientиҪ¬жҚўжҲҗcharacter_set_connectionжүҖжҢҮеҗ‘зҡ„еӯ—з¬ҰйӣҶ(йҷӨдәҶйӮЈдәӣжңүintroducerзҡ„еӯ—з¬ҰдёІеӯ—йқўйҮҸ)гҖӮеӯ—з¬ҰдёІеӯ—йқўйҮҸзҡ„жҜ”иҫғеҲҷдҪҝз”Ёcollation_connectionжүҖжҢҮеҗ‘зҡ„жҺ’еәҸ规еҲҷгҖӮеҜ№дәҺйӮЈдәӣжңүеҲ—еҖјзҡ„еӯ—з¬ҰдёІзҡ„жҜ”иҫғпјҢеҲҷдёҺcollation_connectionжІЎд»Җд№Ҳе…ізі»пјҢеӣ дёәеҲ—жңүе®ғ们иҮӘе·ұзҡ„жҺ’еәҸ规еҲҷпјҢйӮЈдёӘжҺ’еәҸ规еҲҷзҡ„дјҳе…Ҳзә§жӣҙй«ҳгҖӮ
3гҖҒ жңҚеҠЎеҷЁеңЁе°ҶSQLжҹҘиҜўз»“жһңжҲ–й”ҷиҜҜдҝЎжҒҜеҸ‘йҖҒеӣһз»ҷе®ўжҲ·з«Ҝд№ӢеүҚдјҡе°Ҷе®ғ们иҪ¬жҚўжҲҗд»Җд№Ҳеӯ—з¬ҰйӣҶпјҹ
жңҚеҠЎеҷЁдјҡе°ҶSQLжҹҘиҜўз»“жһңзҡ„еӯ—з¬ҰйӣҶиҪ¬жҚўжҲҗзі»з»ҹеҸҳйҮҸcharacter_set_resultsжүҖжҢҮеҗ‘зҡ„еӯ—з¬ҰйӣҶгҖӮиҰҒиҪ¬жҚўзҡ„ж•°жҚ®еҢ…жӢ¬еҲ—еҖје’Ңе…ғж•°жҚ®(жҜ”еҰӮеҲ—еҗҚе’Ңй”ҷиҜҜдҝЎжҒҜ)гҖӮ
жңүдёӨдёӘе‘Ҫд»ӨеҸҜд»Ҙз»ҹдёҖи®ҫзҪ®иҝһжҺҘзӣёе…ізҡ„еӯ—з¬ҰйӣҶпјҡ
1гҖҒ SET NAMESе‘Ҫд»Ө
SET NAMESе‘Ҫд»Өе‘ҠиҜүMySQLжңҚеҠЎеҷЁпјҢе®ўжҲ·з«ҜдҪҝз”Ёзҡ„жҳҜд»Җд№Ҳеӯ—з¬ҰйӣҶдёҺе®ғдәӨдә’зҡ„гҖӮSET NAMESе‘Ҫд»Өи®ҫзҪ®зҡ„еҖјеҸӘдјҡеҜ№еҪ“еүҚдјҡиҜқз”ҹж•ҲгҖӮиҜӯжі•ж јејҸпјҡ
SET NAMES 'charset_name' [COLLATE 'collation_name'] |
дёҖжқЎ SET NAMES 'charset_name' иҜӯеҸҘ(COLLATE 'collation_name'жҳҜеҸҜйҖүзҡ„)е®һйҷ…дёҠзӯүеҗҢдәҺдёӢйқўзҡ„дёүжқЎиҜӯеҸҘпјҡ
SET character_set_client = charset_name; SET character_set_results = charset_name; SET character_set_connection = charset_name; // иҝҷ第дёүжқЎиҜӯеҸҘд№ҹйҡҗеҗ«дәҶе°ҶеҸҳйҮҸcollation_connectionи®ҫзҪ®дёәcharset_nameеӯ—з¬ҰйӣҶй»ҳи®Өзҡ„жҺ’еәҸ规еҲҷ |
2гҖҒ SET CHARACTER SETе‘Ҫд»Ө
SET CHARACTER SETе‘Ҫд»Өзұ»дјјдәҺSET NAMESпјҢдҪҶе°Ҷcharacter_set_connectionе’Ңcollation_connectionи®ҫзҪ®дёәcharacter_set_databaseе’Ңcollation_databaseгҖӮиҜӯжі•ж јејҸпјҡ
SET CHARACTER SET charset_name; |
дёҖжқЎ SET CHARACTER SET charset_name е‘Ҫд»Өе®һйҷ…дёҠзӯүеҗҢдәҺдёӢйқўзҡ„дёүжқЎиҜӯеҸҘпјҡ
SET character_set_client = charset_name; SET character_set_results = charset_name; SET collation_connection = @@collation_database; // иҝҷ第дёүжқЎиҜӯеҸҘд№ҹйҡҗеҗ«дәҶжү§иЎҢе‘Ҫд»ӨSET character_set_connection = @@character_set_database; |
еҜ№дәҺMySQLе®ўжҲ·з«ҜзЁӢеәҸmysqlгҖҒmysqladminгҖҒmysqlcheckгҖҒmysqlimportе’ҢmysqlshowпјҢе®ғ们жҳҜжҢүз…§дёӢйқўзҡ„规еҲҷжқҘеҶіе®ҡдёҺMySQLжңҚеҠЎеҷЁз«ҜйҖҡдҝЎж—¶жүҖдҪҝз”Ёзҡ„еӯ—з¬ҰйӣҶзҡ„пјҡ
1гҖҒ еңЁзјәе°‘е…¶е®ғдҝЎжҒҜзҡ„жғ…еҶөдёӢпјҢе®ғ们дјҡдҪҝз”Ёйў„и®ҫзҡ„й»ҳи®Өеӯ—з¬ҰйӣҶ(йҖҡеёёжҳҜlatin1)жқҘдёҺMySQLжңҚеҠЎеҷЁз«ҜйҖҡдҝЎгҖӮиҝҷдёӘйў„и®ҫзҡ„й»ҳи®Өеӯ—з¬ҰйӣҶд№ҹеҸҜд»ҘеңЁMySQLй…ҚзҪ®ж–Ү件дёӯдҪҝз”ЁдёӢйқўйҖүйЎ№жҢҮе®ҡпјҡ
[root@gw ~]# vim /usr/my.cnf [client] default-character-set=utf8mb4 |
2гҖҒ зЁӢеәҸеҸҜд»ҘиҮӘеҠЁжЈҖжөӢиҰҒдҪҝз”Ёе“ӘдёҖдёӘеӯ—з¬ҰйӣҶпјҢеҹәдәҺж“ҚдҪңзі»з»ҹи®ҫзҪ®пјҢжҜ”еҰӮLANGжҲ–LC_ALLзҺҜеўғеҸҳйҮҸзҡ„еҖјгҖӮжҜ”еҰӮпјҢеҰӮжһңж“ҚдҪңзі»з»ҹдёӯLANGзҺҜеўғеҸҳйҮҸзҡ„еҖјдёәru_RU.KOI8-RпјҢдјҡдҪҝеҫ—иҝҷдәӣе®ўжҲ·з«ҜзЁӢеәҸеҸҳжҲҗдҪҝз”Ёkoi8rеӯ—з¬ҰйӣҶгҖӮиҝҷдёҖзӮ№дјҡжҜ”第1зӮ№дјҳе…ҲгҖӮ
3гҖҒ иҝҷдәӣзЁӢеәҸж”ҜжҢҒдҪҝз”ЁйҖүйЎ№ --default-character-set жқҘи®©з”ЁжҲ·жҳҫејҸжҢҮе®ҡеӯ—з¬ҰйӣҶпјҢд»ҘиҰҶзӣ–зЁӢеәҸиҮӘеҠЁеҶіе®ҡзҡ„еӯ—з¬ҰйӣҶгҖӮиҝҷдёҖзӮ№дјҡжҜ”第1гҖҒ2зӮ№йғҪдјҳе…ҲгҖӮ
еҰӮжһңдҪ жғіиҰҒжңҚеҠЎеҷЁеңЁиҝ”еӣһSQLжҹҘиҜўз»“жһңжҲ–й”ҷиҜҜдҝЎжҒҜз»ҷе®ўжҲ·з«Ҝж—¶дёҚжү§иЎҢеӯ—з¬ҰйӣҶиҪ¬жҚўпјҢеҸҜд»Ҙе°Ҷcharacter_set_resultsеҸҳйҮҸи®ҫдёәNULLжҲ–binaryпјҡ
SET character_set_results = NULL; |
жҹҘзңӢеӯ—з¬ҰйӣҶ
иҰҒжҳҫзӨәMySQLдёӯжүҖж”ҜжҢҒзҡ„жүҖжңүеӯ—з¬ҰйӣҶпјҢеҸҜд»ҘжҹҘзңӢinformation_schema.character_setsиЎЁжҲ–дҪҝз”Ёshow character setе‘Ҫд»ӨпјҢеҗҺйқўеҸҜд»ҘеҠ дёҠ LIKE жҲ– WHEREеӯҗеҸҘиҝӣиЎҢиҝҮж»Өпјҡ
mysql> SHOW CHARACTER SET; mysql> select * from information_schema.character_sets; |
дёҖдёӘз»ҷе®ҡзҡ„еӯ—з¬ҰйӣҶиҮіе°‘дјҡжңүдёҖдёӘжҺ’еәҸ规еҲҷгҖӮеӨ§еӨҡж•°зҡ„еӯ—з¬ҰйӣҶж”ҜжҢҒеӨҡдёӘжҺ’еәҸ规еҲҷпјҢе…¶дёӯдёҖдёӘжҳҜй»ҳи®Өзҡ„гҖӮиҰҒжҳҫзӨәеӯ—з¬ҰйӣҶжүҖж”ҜжҢҒзҡ„жүҖжңүжҺ’еәҸ规еҲҷпјҢеҸҜд»ҘжҹҘзңӢinformation_schema.collationsиЎЁжҲ–дҪҝз”Ёshow collationе‘Ҫд»ӨпјҢеҗҺйқўеҸҜд»ҘеҠ дёҠ LIKE жҲ– WHEREеӯҗеҸҘиҝӣиЎҢиҝҮж»Өпјҡ
mysql> SHOW COLLATION; mysql> select * from information_schema.collations; |
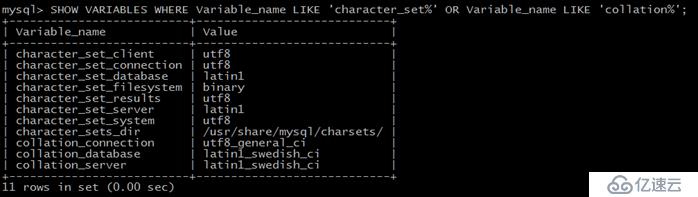
еҰӮжһңиҰҒдҪҝз”ЁжүҖжңүи·ҹеӯ—з¬ҰйӣҶе’ҢжҺ’еәҸ规еҲҷзӣёе…ізҡ„зі»з»ҹеҸҳйҮҸпјҢеҸҜд»ҘдҪҝз”Ёе‘Ҫд»Өпјҡ
mysql> SHOW VARIABLES WHERE Variable_name LIKE 'character_set%' OR Variable_name LIKE 'collation%'; |
жү§иЎҢеҗҺпјҢеҸҜд»ҘзңӢеҲ°жңүдёӢйқўиҝҷдәӣеҸҳйҮҸпјҡ