|
一. 搭建 elasticsearch 1. 上传 jdk-8u181-linux-x64.tar.gz 和 elasticsearch-6.1.4.tar.gz 文件到系统任意目录, 安装 java 解压jdk-8u181-linux-x64.tar.gz文件 tar -zxvf jdk-8u181-linux-x64.tar.gz 编辑profile文件,添加jdk环境变量 vim /etc/profile 在最后添加 #JDK环境变量
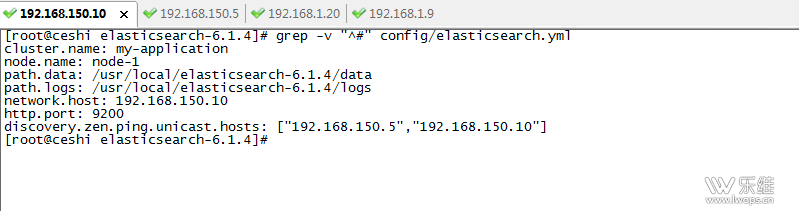
引用环境变量 source /etc/profile 直接执行java –version 确定java已可用 解压 elasticsearch-6.1.4.tar.gz 文件 tar –zxvf elasticsearch-6.1.4.tar.gz 编辑修改 elasticsearch 的配置文件 elasticsearch.yml vim elasticsearch-6.1.4/config/elasticsearch.yml 主要修改以下信息(数据存放目录以及日志存放目录需要添加执行权限,)
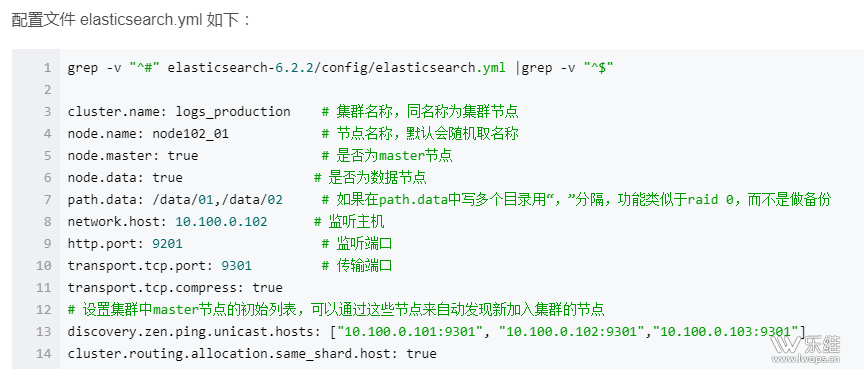
配置文件解析如下:
开启服务(可以使用 -d 后台启用) /usr/local/elasticsearch-6.1.4/bin/elasticsearch 乐维 Tips:在启动服务时,不能以 root 用户开启服务, elasticsearch 需要以其他用户开启服务; 1、 需要创建用户; 添加 es 用户 useradd es -m 设置 es 用户密码 passwd es 2、 需要修改elasticsearch-6.1.4目录、数据存放目录、日志存放目录的所属组和所属用户
3 、 ERROR:bootstrap checks failed : max file descriptors [4096] for elasticsearchprocess likely too low, increase to at least [65536] 原因:无法创建本地文件问题 , 用户最大可创建文件数太小 解决方案:
切换到 root 用户,编辑 limits.conf 配置文件, 添加类似如下内容: vi/etc/security/limits.conf 添加如下内容:
注: * 代表 Linux 所有用户名称 ( 比如 hadoop) 保存、退出、重新登录才可生效
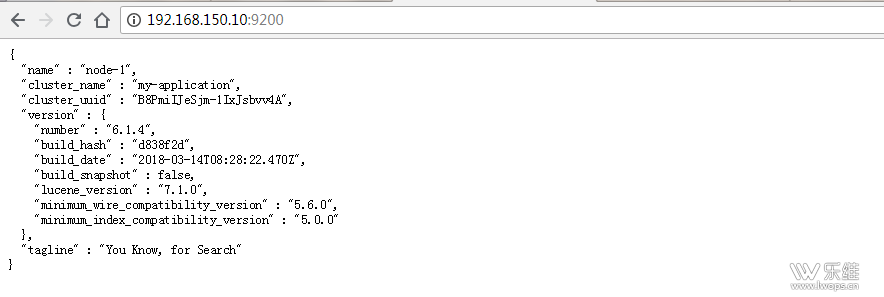
4 、 max virtualmemory areas vm.max_map_count [65530] likely too low, increase to at least[262144] 原因:最大虚拟内存太小 解决方案:切换到 root 用户下,修改配置文件 sysctl.conf vi /etc/sysctl.conf 添加下面配置: vm.max_map_count=655360 并执行命令: sysctl -p 5 、 max number ofthreads [1024] for user [es] likely too low, increase to at least [2048] 原因:无法创建本地线程问题 , 用户最大可创建线程数太小 解决方案: 切换到 root 用户,进入 limits.d 目录下,修改 90-nproc.conf 配置文件。 vi /etc/security/limits.d/90-nproc.conf 修改 * soft nproc 1024 为 * soft nproc 2048 以 es 用户启动服务 (-d 可以后台启动 ) su es /usr/local/elasticsearch-6.1.4/bin/elasticsearch 开启防火墙端口 9200 TCP firewall-cmd --zone=public --add-port=9200/tcp–permanent 在 WEB 上输入 IP : 9200 测试是否可以正常访问使用
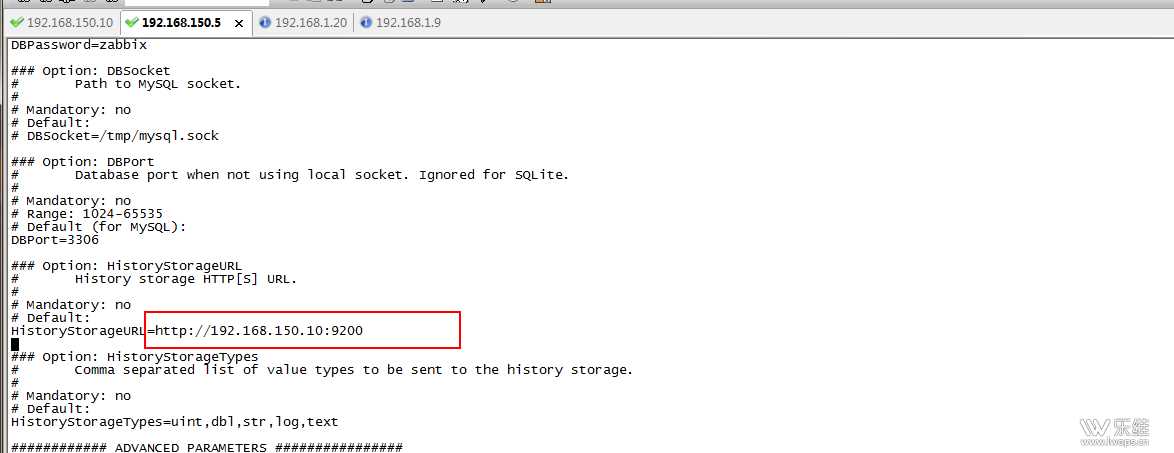
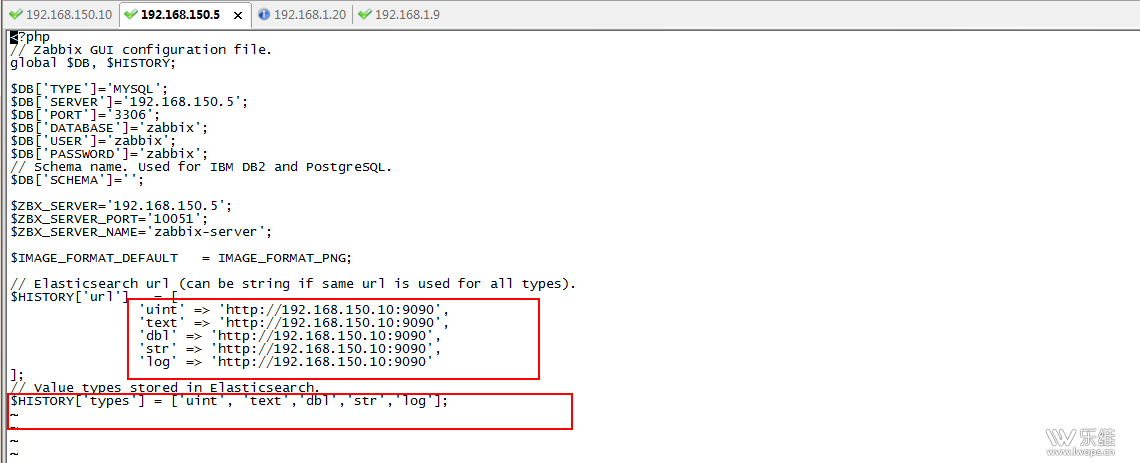
二. 与 zabbix 对接 需要修改 zabbix_server 的配置文件 修改 HistoryStorageURL=http://192.168.150.10:9200
修改 zabbix.conf.php 文件 vi/usr/local/nginx/html/zabbix/conf/zabbix.conf.php
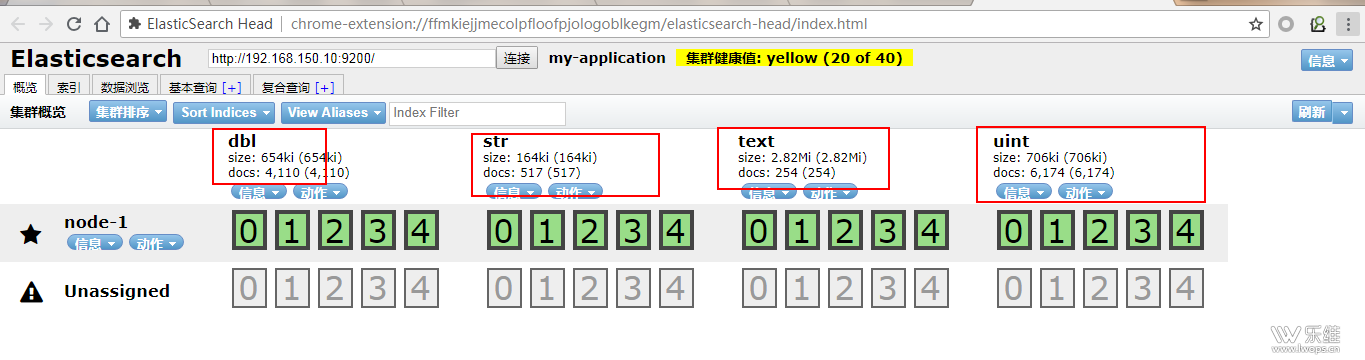
重启 zabbix_server 同步成功后
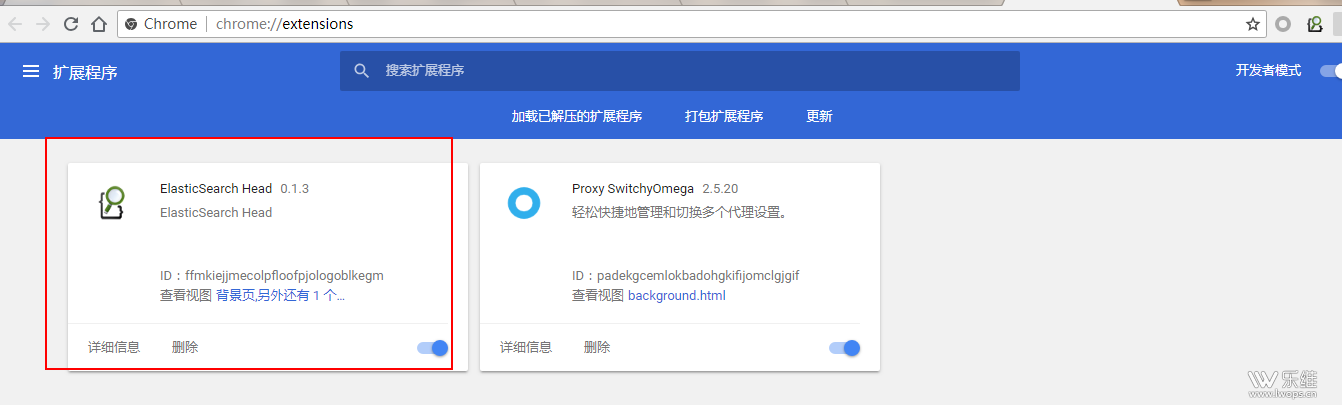
方法 1 、 ElasticSearch Head 可以直接在谷歌浏览器上进行安装 (推荐) 直接把文件拖到扩展程序进行添加
方法 2 、这里介绍一个 Elasticsearch 可视化的管理插件 elasticsearch-head ,可方便的查看,删除,管理数据 安装 elasticsearch-head 插件需要 nodejs 的支持 1. nodejs安装 2. head安装配置 请参考 https://blog.csdn.net/zoubf/article/details/79007908 三. Elasticsearch 常用命令 (由于没有自带的数据清理功能,需要手动编写脚本) 1 、 curl 命令的使用curl -X<VERB>'< PROTOCOL>://<HOST>:< PORT>/< PATH>?<QUERY_STRING>'-d '<BODY>'VERB HTTP 方法: GET, POST, PUT, HEAD, DELETE PROTOCOL http 或者 https 协议(只有在 Elasticsearch 前面有 https 代理的时候可用) HOST Elasticsearch 集群中的任何一个节点的主机名 PORT Elasticsearch HTTP 服务所在的端口,默认为 9200 PATH API 路径,资源路径(例如 _count 将返回集群中文档的数量) QUERY_STRING 一些可选的查询请求参数,例如 ?pretty 参数将返回易读的 JSON 数据 BODY 一个 JSON 格式的请求主体(如果请求需要的话) 具体详细方法,请参考 https://www.linuxidc.com/Linux/2016-10/136548.htm 添加索引( zabbix 为数据库名) curl -XPUT'http://192.168.1.20:9090/zabbix?pretty' 创建成功后,默认会分配五个主分片(创建后不可更改,通过算法将数据存放在这五个分片中的一个,增删改都是针对主分片的)和一个复制分片(可修改,每个主分片都对应一个复制分片),这两个默认值都可以在配置文件中修改,也可以在创建的时候指定,如 curl -XPUT 'http://192.168.1.20:9090/zabbix?pretty'-d '{ "settings": { "number_of_shards" : 2, #2个主分片 "number_of_replicas" : 0 #0个复制分片 } }'
查看索引 curl -XGET'http://192.168.1.20:9090/zabbix?pretty' 查询方式; 例如:
查询所有文档
curl -XGET 'http://localhost:9200/test/article/_search?pretty' -d ' { "query": { "match_all": {} } }'#返回 { # 用时 毫秒 "took" : 4 , "timed_out" : false , #分片信息 "_shards" : { "total" : 5 , "successful" : 5 , "failed" : }, "hits" : { #文档数 "total" : 3 , "max_score" : 1.0 , "hits" : [ { "_index" : "test" , "_type" : "article" , "_id" : "AVf_6fM1vEkwGPLuUJqp" , "_score" : 1.0 , "_source" : { "id" : 2 , "subject" : "第二篇文章标题" , "content" : "第二篇文章内容" , "author" : "jam" } }, { "_index" : "test" , "_type" : "article" , "_id" : "4" , "_score" : 1.0 , "_source" : { "id" : 4 , "subject" : "第四篇文章标题" , "content" : "第四篇文章内容-更新后" , "author" : "tomi" } }, { "_index" : "test" , "_type" : "article" , "_id" : "3" , "_score" : 1.0 , "_source" : { "id" : 3 , "subject" : "第三篇文章标题" , "content" : "第三篇文章内容" , "author" : "jam" } } } 查询作者是名字包含“jam” 的文档,返回id 是2和3 的文档 curl -XGET 'http://localhost:9200/test/article/_search?pretty' -d ' { " query ": { " match ": { " author ": " jam " } } }' 查询文章内容包含“更新” 的文档,返回id 是4 的文档 curl -XGET 'http://localhost:9200/test/article/_search?pretty' -d ' { " query ": { " match ": { " content ": " 更新 " } } }' 查询全部索引 curl -XGET 'http://192.168.150.10:9200/_cat/indices/?v' 删除所有数据包括自行添加的索引 curl -XDELETE 'http://192.168.150.10:9200/*' 2、 Elasticsearch 清理数据 由于 Elasticsearch 没有自带的数据删除配置,所以需要脚本进行清理数据 1 )删除索引是会立即释放空间的,不存在所谓的“标记”逻辑。 2 )删除文档的时候,是将新文档写入,同时将旧文档标记为已删除。磁盘空间是否释放取决于新旧文档是否在同一个segment file里面,因此ES后台的segment merge在 合并segment file的过程中有可能触发旧文档的物理删除 。 但因为一个shard可能会有上百个segment file,还是有很大几率新旧文档存在于不同的segment里而无法物理删除。想要手动释放空间,只能是定期做一下force merge,并且将max_num_segments设置为1 。
删除文档
释放空间
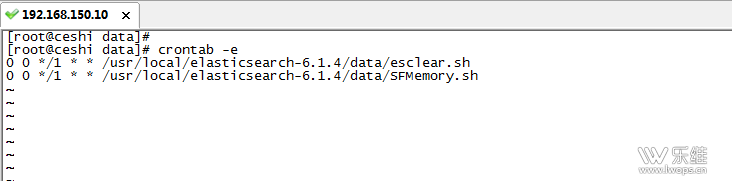
配置计划任务
jdk-8u181-linux-x64.tar.gz、elasticsearch-6.1.4.tar.gz文件下载 密码:x6I7
原文地址 教你搭建elasticsearch与实现zabbix对接 http://www.lwops.cn/forum.php?mod=viewthread&tid=70 (出处: 乐维_一站式运维监控管理平台)
|
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。