https://www.toutiao.com/a6695518937334940174/

文/编辑 | 言有三
一直有同学希望我写写面试相关的东西,一直没写。我们不会开相关的板块,因为没有标准,容易引起争议,而且可能会加重大家的浮躁和焦虑。
不过关于面试,有三还是有一些话可以说的,下面分两部分道来。
假如我是老板或者诚心为公司招聘优秀人才的面试官,我会喜欢拥有以下特质的人。这里说的是招聘一个算法工程师,一个能够为公司创造收益的人,简单起见就不分社招校招。
1、忠诚度,这很重要。一个不忠诚的员工,能力再大,也不能要。所以如果看到一份简历满满当当的都是跳槽和实习简历,两个月换一个实习,半年换一份工作,除非你说出很充分客观的理由,否则我可能不会通过这份简历。
2、编码能力,这是一切的前提。前面说了,我们这里要招聘的是一个计算机视觉领域(CV)算法工程师,招进来是要干活的。公司不会招聘一个只会Matlab或者python都用不熟的人来做项目开发,做纯算法研究都不行,一个不能实现自己想法的牛人我还没见过。见过的牛人不仅算法好,编程能力也强大。
说起编程能力,有几点基本要求:
(1) linux得熟。
现在不是若干年前开源项目还不多的时代,大家还在Windows下面吭哧吭哧用Matlab和VS仿真,都9102年了,Linux都不熟,效率如何让老大放心。
(2) python得熟,c++得会。
如果连python这样简单的语言还用不熟,那真是无话可说。c/c++ 这是一门基础课吧,理工科的学校没开过应该很罕见,CV领域的工业界部署和算法优化都离不开C++。
(3) 编程习惯得好。
虽然说代码写的烂,不会真有同事拿gun突突突你,但是好的编程习惯不仅仅提高效率,而且看着也舒服,不会被别人鄙视。
这里说的习惯包括: 多写写类和函数封装,组织好项目目录结构,好好命名 等等。可以不会写多么牛逼炫酷的代码,但是要 保证代码具有良好的可拓展性,方便他人阅读移植 ,具体要求以后再说。
3、算法基础,这决定了潜力。没做过检测?没事,没做过分割?没事。边做边学,快速跟进就是了,这本就是公司开发的常态。
人的精力有限,没做过的多了去了。但是如果CNN的一些基础傻傻说不清楚,图像的基础概念一问三不知,这就有事了。因为你交给他一个项目,可能会犯一些低级错误而不自知,老大心里也慌,还要陪着检查和普及基础知识。
以上就是三个基本要求,每一家公司肯定都是这样要求的,我觉得如果通过了这三个考验,那至少就是一个可以培养的候选人,我会愿意给他机会进入下一轮的PK。
踏实(基础好),靠谱(稳定),能干活(能写代码),这3个基本前提比什么都重要,其他的都可以在项目学习。
接下来就该说说具体怎么办了,这就是我开 《AI修行之路》 这个专栏的原因了,如果你有耐心,不妨接着看下去,我们也是再重新回顾总结一下之前的文章,每一篇文章的开设都有充分的理由。
1、为什么要用Linux
在以前,你可能觉得Linux并非刚需,用着自己的Windows电脑,也不需要与人共享操作系统,硬件和磁盘。但是如果你们团队一起使用服务器,不可能不用Linux。
所以这是对还没有在Linux上面真正进行日常开发工作的小朋友说的,要正式进入AI行业发展,Linux是必备和唯一的操作系统,“软”兵器,我还没有听过哪家公司在Windows或者Mac上面训练模型的。
「AI白身境」深度学习从弃用windows开始
2、使用shell,vim,git提高开发效率
编程习惯,工作效率很重要,很重要!Linux下一个熟练的工程师,会比Windows下工作效率高很多,提高写代码效率可以从终端多任务管理,熟练使用shell命令,熟练使用vim等开发环境,熟练使用git命令等地方入手。
shell命令是Linux的操作基础 ,也是学习使用Linux的开始,而慢慢熟悉高级的shell命令在将来的工作中会带来很大的效率提升。
vim是Linux下最常用的编辑器,从小白到高手都可以使用,而它的 列编辑,查找替换,自动补全 等功能都是效率的保证,或许从visual studio等环境切换过来的同学刚开始会有些许不适应,但是时间久了就会越来越明白VIM的好。
git是程序员必备的素养 ,慢慢学会维护几个自己的代码库,等到将来出问题的时候就明白了。

「AI白身境」Linux干活三板斧,shell、vim和git
3、python基础和编程习惯
在机器学习领域,python可谓是一骑绝尘,学习python需要掌握好基础的语法包括函数,类设计,掌握大量的开源矩阵库Numpy等。
python简单吗?简单。真的简单吗?看看大神们写的项目吧。

「AI白身境」学AI必备的python基础
4、图像基础
深度学习有一个最大的问题,就是太好用了。导致什么图像基础和传统算法都不需要懂,也能项目做的风生水起。
但是如果没有好的图像基础,总有一天遇到CNN解决不了的问题,或者无法单独解决的问题,就不知所措了。很多的新技术都是从传统算法中获得灵感或者相互结合的,不懂图像基础,就仿佛埋了一颗定 时 炸 弹 ,一般没事,炸了就炸了。

「AI白身境」深度学习必备图像基础
5、OpenCV基础
如果说图像处理领域有什么库是绕不过去的,那一定是OpenCV,这一个开源计算机视觉库堪称最优秀的计算机视觉库,不仅可以学术和商业免费使用,而且跨平台,高性能。需要掌握的基础内容包括:如何部署,基本数据结构的熟悉与使用,基本模块的了解。

「AI白身境」搞计算机视觉必备的OpenCV入门基础
6、CMake编译
python是脚本语言,而当前大量的AI算法都部署在移动端嵌入式平台,需要使用c/c++/java语言,g++,CMake和Makefile正是Linux下编译C系代码的工具。
实际上一些python,matlab开源项目也需要预编译,更多的等到了工作岗位自然懂。
「AI白身境」只会用Python?g++,CMake和Makefile了解一下
7、爬虫基础
深度学习项目开发中最重要的是什么,当然是数据!实际的项目你经常没有足够多的数据,这个时候就需要自己去想办法获取了。
互联网是一个什么资源都有的大宝库,学会使用好爬虫,你将可能成为时代里最有“资源”的人,这也很可能是项目成功的开始。
本文最后的一个实际项目就需要用到。

「AI白身境」学深度学习你不得不知的爬虫基础
8、数据可视化
爬取完数据之后就应该进行处理了,一个很常用的手段是数据可视化。在深度学习项目中,常需要的数据可视化操作包括原始图片数据的可视化,损失和精度的可视化等。
除了对数据可视化,我们还需要对模型进行可视化,方便调试和感知。
「AI白身境」深度学习中的数据可视化
9、数学基础
虽然对于大部分来说,做项目不需要多么强悍的数学基础,但是你会需要看懂别人论文,也会经常需要进行简单的推导和算法改进。
从线性代数,概率论与统计学到微积分和最优化,都是需要掌握的。不过数学的学习是一个非常漫长的过程,不要急于求成,也不是靠跟着视频或者书本就能完全学会的,重要的是用起来。
「AI白身境」入行AI需要什么数学基础:左手矩阵论,右手微积分
10、计算机视觉研究方向
学习和做项目都需要一个方向,在前面这些基础都掌握好了,就要好好了解一下计算机视觉的各大研究方向及其特点,方便自己选题和项目方案定型了。
从图像分类,分割,目标检测,跟踪,到图像滤波与降噪,增强,风格化,三维重建,图像检索,GANs,相信总有你喜欢或者项目涉及的。

「AI白身境」一文览尽计算机视觉研究方向
11、应用方向
学习最终是为了解决实际问题,AI已经渗入到了我们生活的方方面面。从自动驾驶汽车、图像美颜,到聊天机器人,金融支付等,因此好好了解下当前AI在各大领域的应用没错的,这次就不仅仅限于计算机视觉了。

https://dwz.cn/Gj18HPHd
12、认识学术大咖
要想真正融入行业圈子,紧跟技术发展,就必须要时刻了解大佬们的状态,他们就是行业发展的风向标。
不管是学术界还是工业界,不管是老师傅还是青年才俊,让我们一起见贤思齐吧。
我们开源了大佬研究方向的项目,欢迎follow。
https://github.com/longpeng2008/Awesome_DNN_Researchers
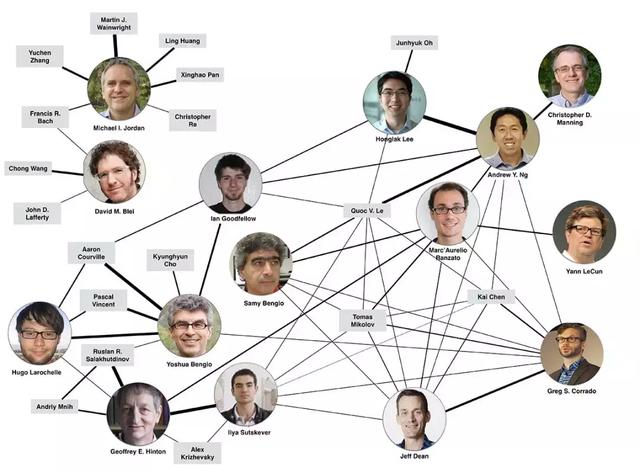
「AI白身境」究竟谁是paper之王,全球前10的计算机科学家
13、人工智能简史
基础打好了,接下来就是正式学习AI相关的知识,不管是在哪个课堂或者教材,都是让大家先了解先贤们。
从图灵与机器智能,冯诺伊曼与类脑计算引发的人工智能启蒙,到三次浪潮的曲折和技术的成长史,值得每一个从事该行业的人阅读。

「AI初识境」从3次人工智能潮起潮落说起
14、神经网络基础
深度学习研究问题的方法就是仿造大脑,根基是神经网络。从感受野,到MP模型,到感知机,到反向传播,要很熟悉全连接神经网络的劣势,卷积神经网络的特点,核心技术和优势,这是学习深度学习最重要的基础。
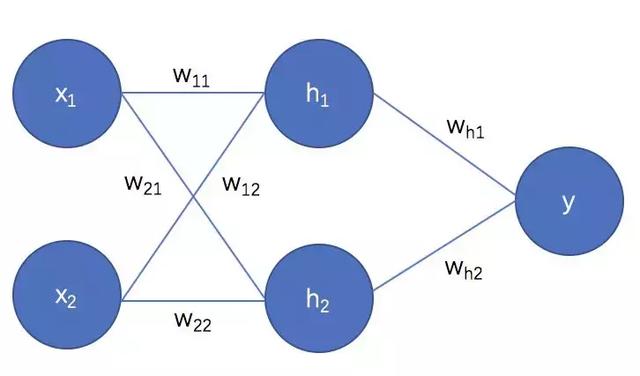
「AI初识境」从头理解神经网络-内行与外行的分水岭
15、了解领域的突破
既然学深度学习,就必须要了解深度学习的重要进展。
在前深度学习时代,视觉机制的发现,第一个卷积神经网络Neocognitron的提出,反向传播算法的流行,促进了LeNet5和MNIST数据集的诞生。
随着新理论的成熟,大数据的积累,GPU的普世,以卷积神经网络为代表的技术在图像分类,目标检测等基础领域取得重大突破,随着AlphaGo的成功同时在业内和业外人士的心目中种下了深度学习/人工智能技术的种子,从此焕发勃勃生机。
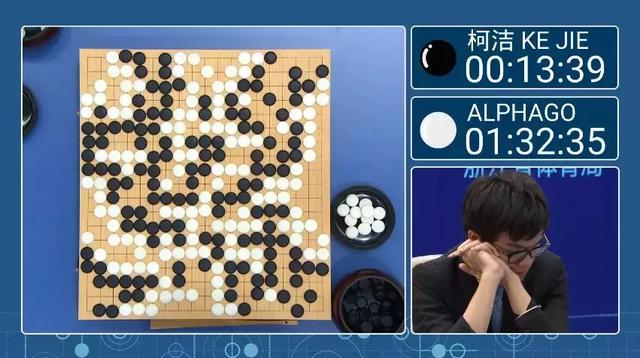
「AI初识境」近20年深度学习在图像领域的重要进展节点
16、激活函数
深度学习的机制模仿于人脑,人脑的细胞接受刺激从而产生活动需要一定的阈值,这便是激活函数根本性的由来。
激活函数肩负着网络非线性表达能力的提升,从早期平滑的sigmoid和tanh激活函数,到后来的ReLU和各类ReLU的变种(LReLU,PReLU,RReLU,ELU,SELU,GELU等等),Maxout,研究者一直试图让网络拥有更好的表达能力。
随着技术的发展,利用增强学习等算法从函数池中学习新的激活函数如swish等,成为了当下的研究主流,激活函数也走上了数据驱动的道路。
激活机制看似简单,实则不易,大家一定多跟进了解了解。
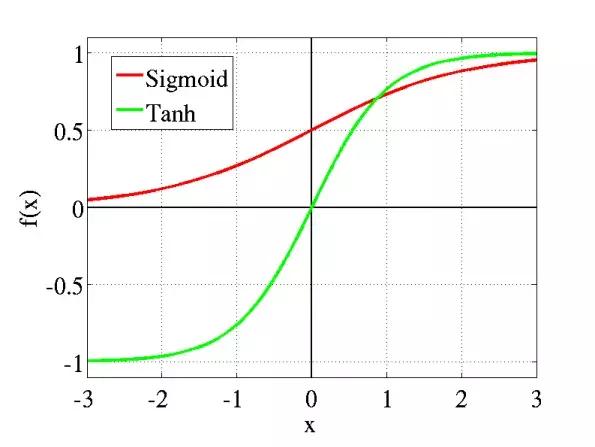
「AI初识境」激活函数:从人工设计到自动搜索
17、参数初始化
参数初始化,一个看似很简单的问题,却实实在在地困住了神经网络的优化很久,2006年Hinton等人在science期刊上发表了论文“Reducing the dimensionality of data with neural networks”,揭开了新的训练深层神经网络算法的序幕,仍旧被认为是当前第三次人工智能热潮的纪元。
从全零初始化和随机初始化,到标准初始化,Xavier初始化,He初始化,时至今日上千层网络的训练都已经成为了现实,初始化似乎已经不再是那么重要的课题了,但是谁说就没有思考的空间了呢。
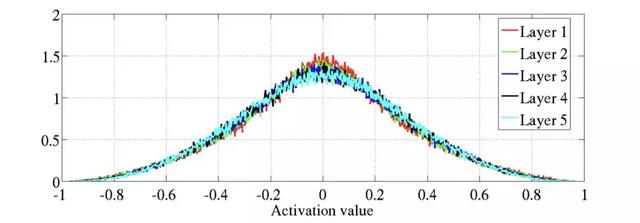
「AI初识境」什么是深度学习成功的开始?参数初始化
18、归一化
我们总是希望所研究的统计问题能够满足固定的分布,而且这样也的确会降低问题的难度。
在深度学习中,因为网络的层数非常多,如果数据分布在某一层开始有明显的偏移,随着网络的加深这一问题会加剧,进而导致模型优化的难度增加。
归一化便是致力于解决这个问题,从数据到权重,从限定在同一样本的一个特征通道到不同样本的所有通道,各类归一化方法以简单的方式,优雅地解决了深度学习模型训练容易陷入局部解的难题,顺带提升训练速度提高泛化能力,这是一定要掌握的理论和工程技巧。
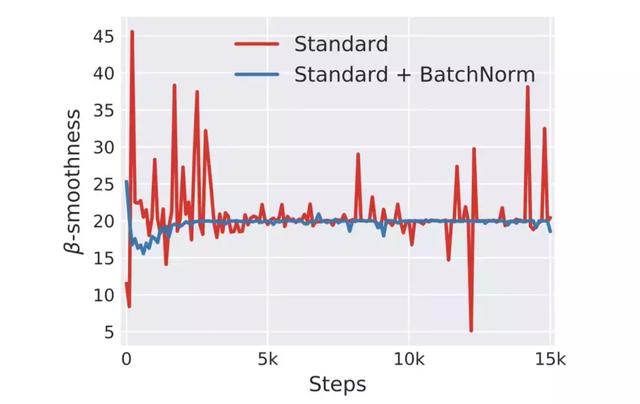
「AI初识境」深度学习模型中的Normalization,你懂了多少?
19、池化
大脑学习知识靠抽象,从图像中抽象知识是一个“从大到小”过滤提炼信息的过程。从视觉机制中来的pooling即池化,正是对信息进行抽象的过程。
池化增加了网络对于平移的不变性,提升了网络的泛化能力,大家已经习惯了使用均值池化mean pooling和最大池化(max pooling),虽然可以用带步长的卷积进行替代。
尽管池化究竟起到了多大的作用开始被研究者怀疑,但是池化机制仍然是网络中必备的结构,所以你一定要熟悉它,而且基于数据驱动的池化机制值得研究。
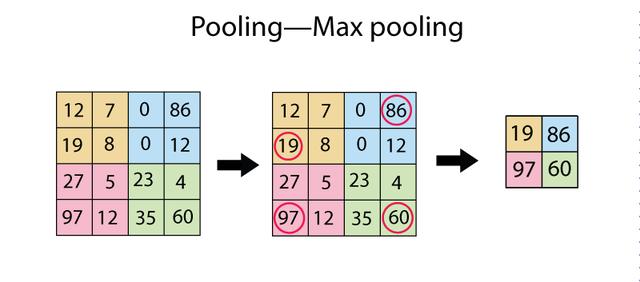
「AI初识境」被Hinton,DeepMind和斯坦福嫌弃的池化到底是什么?
20、最优化
模型的学习需要通过优化方法才能具体实现。深度学习模型的优化是一个非凸优化问题,尽管一阶二阶方法都可以拿来解决它,但是当前随机梯度下降SGD及其各类变种仍然是首选。
从SGD开始,有的致力于提高它的优化速度如Momentum动量法和Nesterov accelerated gradient法,有的致力于让不同的参数拥有不同的学习率如Adagrad,Adadelta与Rmsprop法,有的希望大家从调参中解脱如Adam方法及其变种,有的致力于让收敛过程更加稳定如Adafactor方法和Adabound方法。
没有一个方法是完美的,训练的时候总归要试试。
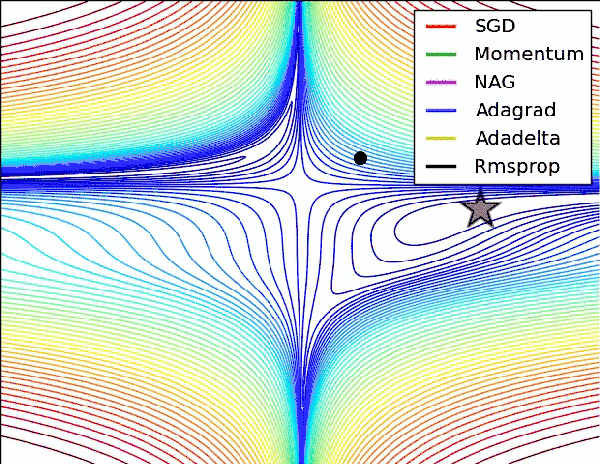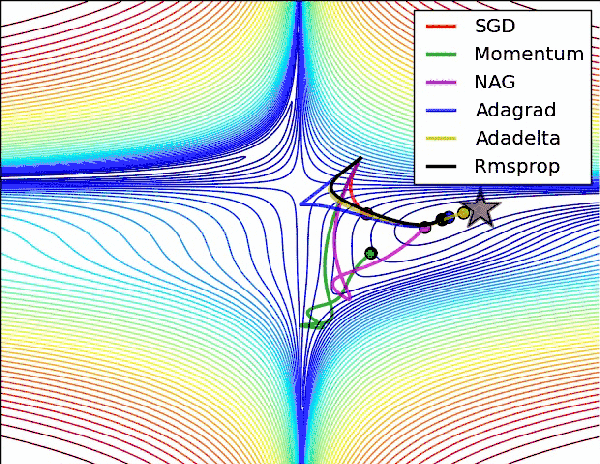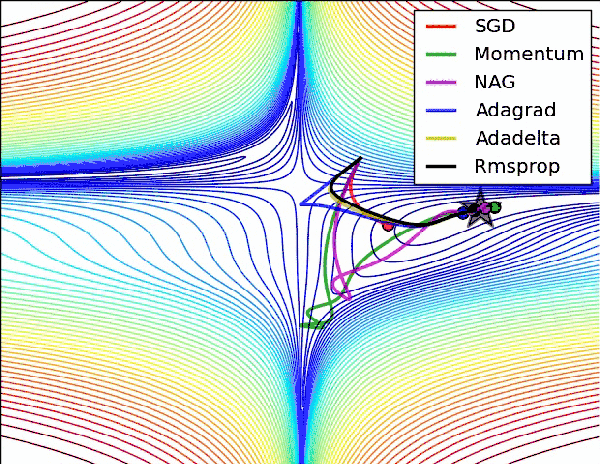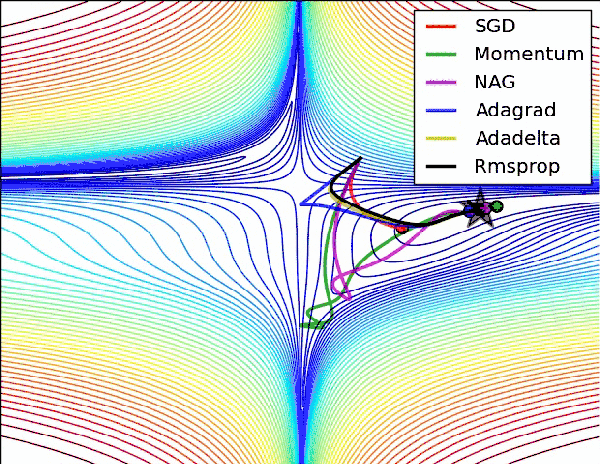
「AI初识境」为了围剿SGD大家这些年想过的那十几招
21、泛化能力
如果一个模型只能在训练集上起作用,那是没有用的。
因此我们总是希望模型不仅仅是对于已知的数据(训练集)性能表现良好,对于未知的数据(测试集)也表现良好,即具有良好的泛化能力,通过添加正则项来实现。
从直接提供正则化约束的参数正则化方法如L1/L2正则化,工程上的技巧如训练提前终止和模型集成,以及隐式的正则化方法如数据增强等,研究人员在这方面投入的精力非常多,大家一定要时刻关注。
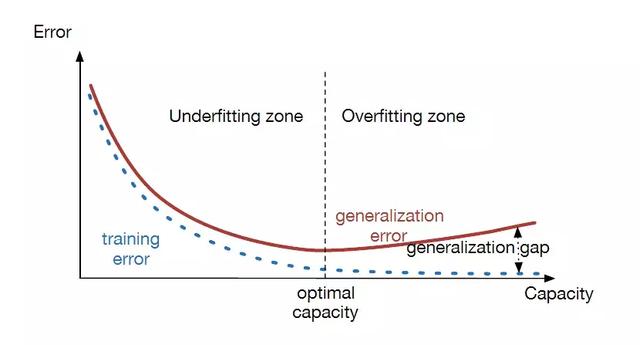
「AI初识境」如何增加深度学习模型的泛化能力
22、模型评估
口说无凭,用数据说话才是研究者们进行PK的正确姿态。计算机视觉的任务何其多,从分类,回归,质量评估到生成模型,我们当然需要掌握科学的评估方法。
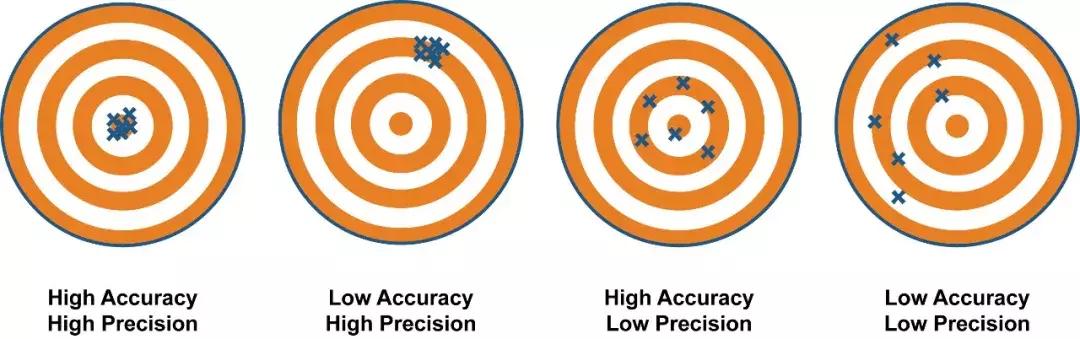
「AI初识境」深度学习模型评估,从图像分类到生成模型
23、损失目标
模型的学习需要指导,这正是损失函数的责任,它往往对模型最终表现如何影响巨大。
这一篇文章就重点总结分类问题,回归问题,生成对抗网络中使用的损失目标,为大家设计更好的优化目标奠定理论基础。
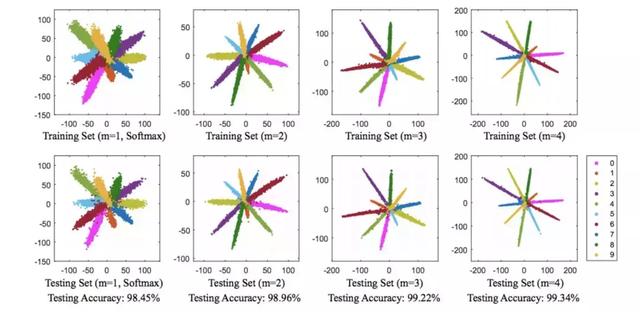
「AI初识境」深度学习中常用的损失函数有哪些?
24、如何开始训练你的模型
磨刀不误砍柴工,当我们开始训练自己的模型的时候,总归要想清楚一些事儿再动手。
第一步知道你要做的任务是一个什么任务,找到竞争对手做好预期,想好你需要什么样的数据。第二步确定好框架,基准模型,准备好数据。然后才是第三步开始训练,从输入输出,数据的预处理到维持正确地训练姿势。
这是我总结出来的经验,想必总是有点用的。

「AI初识境」给深度学习新手做项目的10个建议
25、认真做一个项目
到了最后,相信大家都拥有了基本技能了,那我们就来开始一个真正的项目吧,实现形色识花App的部分功能。

在这里不会教大家如何完成,因为这个项目一点都不简单,是个很难的分类项目,不是给一个现有的数据集和一个模型就能解决的,至少有以下问题需要考虑,每一个都有很多工程细节需要解决。
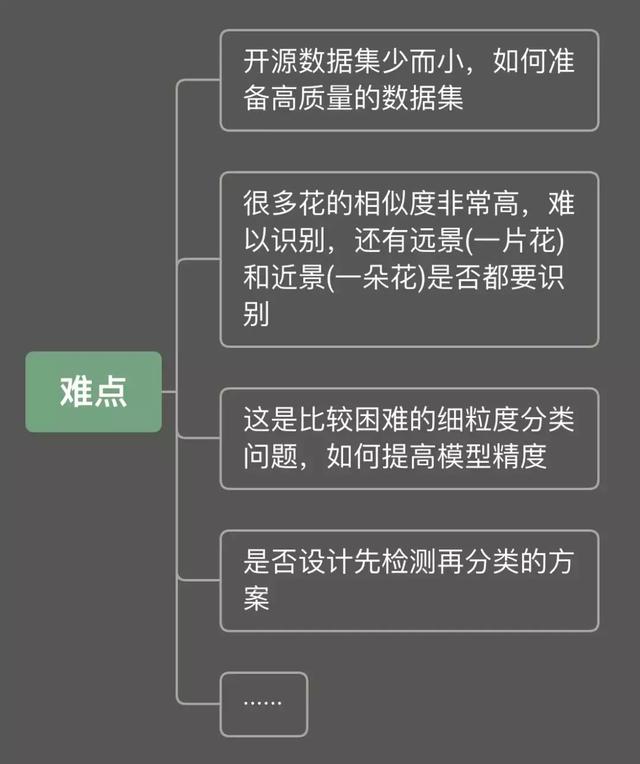
如果你能独立将这个任务的整个流程完成,识别20种包含远近景的花,做到95%的精度,那么我相信你完全有能力去应聘计算机视觉算法工程师了。
如果在框架上有什么问题,可以参考我们开源的12个主流的开源框架在各类任务中的使用git项目。
https://github.com/longpeng2008/yousan.ai
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





