жЎҲдҫӢеү–жһҗпјҡеҲ©з”ЁLSTMж·ұеұӮзҘһз»ҸзҪ‘з»ңиҝӣиЎҢж—¶й—ҙеәҸеҲ—йў„жөӢ
жң¬ж–Үе°ҶйҮҚзӮ№д»Ӣз»ҚеҰӮдҪ•дҪҝз”ЁLSTMзҘһз»ҸзҪ‘з»ңжһ¶жһ„пјҢдҪҝз”ЁKerasе’ҢTensorflowжҸҗдҫӣж—¶й—ҙеәҸеҲ—йў„жөӢпјҢзү№еҲ«жҳҜеңЁиӮЎзҘЁеёӮеңәж•°жҚ®йӣҶдёҠпјҢд»ҘжҸҗдҫӣиӮЎзҘЁд»·ж јзҡ„еҠЁйҮҸжҢҮж ҮгҖӮ
иҝҷдёӘжЎҶжһ¶зҡ„д»Јз ҒеҸҜд»ҘеңЁдёӢйқўзҡ„GitHub repoдёӯжүҫеҲ°пјҲе®ғеҒҮи®ҫpythonзүҲжң¬3.5.xе’Ңrequirements.txtж–Ү件дёӯзҡ„йңҖжұӮзүҲжң¬гҖӮеҒҸзҰ»иҝҷдәӣзүҲжң¬еҸҜиғҪдјҡеҜјиҮҙй”ҷиҜҜпјүпјҡhttps://github.com/jaungiers/LSTM-Neural-Network-for-Time-Series-Prediction
д»Җд№ҲжҳҜLSTMзҘһз»Ҹе…ғпјҹ
й•ҝжңҹеӣ°жү°дј з»ҹзҘһз»ҸзҪ‘з»ңжһ¶жһ„зҡ„еҹәжң¬й—®йўҳд№ӢдёҖжҳҜпјҢеҰӮдҪ•иғҪеӨҹи§ЈйҮҠдҫқиө–дәҺдҝЎжҒҜе’ҢдёҠдёӢж–Үзҡ„иҫ“е…ҘеәҸеҲ—гҖӮиҜҘдҝЎжҒҜеҸҜд»ҘжҳҜеҸҘеӯҗдёӯзҡ„еүҚдёҖдёӘеҚ•иҜҚпјҢд»Ҙж–№дҫҝйҖҡиҝҮдёҠдёӢж–ҮжқҘйў„жөӢдёӢдёҖдёӘеҚ•иҜҚеҸҜиғҪжҳҜд»Җд№ҲпјҢжҲ–иҖ…е®ғд№ҹеҸҜд»ҘжҳҜеәҸеҲ—зҡ„ж—¶еәҸдҝЎжҒҜгҖӮ
з®ҖиҖҢиЁҖд№ӢпјҢдј з»ҹзҡ„зҘһз»ҸзҪ‘з»ңжҜҸж¬ЎйғҪдјҡйҮҮз”ЁзӢ¬з«Ӣзҡ„ж•°жҚ®еҗ‘йҮҸпјҢ并且没жңүеҶ…еӯҳжҰӮеҝөжқҘеё®еҠ©д»–们еӨ„зҗҶйңҖиҰҒеҶ…еӯҳзҡ„д»»еҠЎгҖӮ
ж—©жңҹе°қиҜ•и§ЈеҶіиҝҷдёӘй—®йўҳзҡ„ж–№жі•жҳҜеҜ№зҪ‘з»ңдёӯзҡ„зҘһз»Ҹе…ғдҪҝз”Ёз®ҖеҚ•зҡ„еҸҚйҰҲзұ»еһӢж–№жі•пјҢе…¶дёӯиҫ“еҮәиў«еҸҚйҰҲеҲ°иҫ“е…ҘдёӯпјҢд»ҘжҸҗдҫӣжңҖеҗҺзңӢеҲ°зҡ„иҫ“е…Ҙзҡ„дёҠдёӢж–ҮгҖӮиҝҷдәӣиў«з§°дёәйҖ’еҪ’зҘһз»ҸзҪ‘з»ңпјҲRNNпјүгҖӮиҷҪ然иҝҷдәӣRNNеңЁдёҖе®ҡзЁӢеәҰдёҠиө·дҪңз”ЁпјҢдҪҶе®ғ们жңүдёҖдёӘзӣёеҪ“еӨ§зҡ„зјәзӮ№пјҢеӣ жӯӨе®ғ们зҡ„дёҖдәӣйҮҚиҰҒз”ЁйҖ”йғҪдјҡеҜјиҮҙдә§з”ҹж¶ҲеӨұжўҜеәҰзҡ„й—®йўҳгҖӮжҲ‘们дёҚдјҡиҝӣдёҖжӯҘжү©еұ•и®Ёи®әе®ғпјҢиҖҢжҳҜиҜҙз”ұдәҺиҝҷдёӘй—®йўҳеҜјиҮҙRNNдёҚйҖӮеҗҲеӨ§еӨҡж•°зҺ°е®һй—®йўҳпјҢеӣ жӯӨпјҢжҲ‘们йңҖиҰҒжүҫеҲ°еҲ«зҡ„и§ЈеҶіеҠһжі•гҖӮ
иҝҷе°ұжҳҜй•ҝжңҹзҹӯжңҹи®°еҝҶпјҲLSTMпјүзҘһз»ҸзҪ‘з»ңиө·дҪңз”Ёзҡ„ең°ж–№гҖӮдёҺRNNзҘһз»Ҹе…ғдёҖж ·пјҢLSTMзҘһз»Ҹе…ғеңЁе…¶з®ЎйҒ“дёӯеҸҜд»ҘдҝқжҢҒи®°еҝҶпјҢд»Ҙе…Ғи®ёи§ЈеҶійЎәеәҸе’Ңж—¶й—ҙй—®йўҳпјҢиҖҢдёҚдјҡеҮәзҺ°еҪұе“Қе…¶жҖ§иғҪзҡ„ж¶ҲеӨұжўҜеәҰй—®йўҳгҖӮ
и®ёеӨҡе…ідәҺе®ғзҡ„з ”з©¶и®әж–Үе’Ңж–Үз« йғҪеҸҜд»ҘеңЁзҪ‘дёҠжүҫеҲ°пјҢе®ғ们еңЁж•°еӯҰз»ҶиҠӮдёҠи®Ёи®әдәҶLSTMз»Ҷиғһзҡ„е·ҘдҪңеҺҹзҗҶгҖӮ然иҖҢпјҢеңЁжң¬ж–ҮдёӯпјҢжҲ‘们дёҚдјҡи®Ёи®әLSTMзҡ„еӨҚжқӮе·ҘдҪңеҺҹзҗҶпјҢеӣ дёәжҲ‘们жӣҙе…іеҝғе®ғ们зҡ„дҪҝз”ЁгҖӮ
еҜ№дәҺдёҠдёӢж–ҮпјҢдёӢйқўжҳҜLSTMзҘһз»Ҹе…ғзҡ„е…ёеһӢеҶ…йғЁе·ҘдҪңеӣҫгҖӮе®ғз”ұиӢҘе№ІеұӮе’ҢйҖҗзӮ№ж“ҚдҪңз»„жҲҗпјҢиҝҷдәӣж“ҚдҪңе……еҪ“ж•°жҚ®иҫ“е…ҘгҖҒиҫ“еҮәзҡ„й—ЁпјҢдёәLSTMеҚ•е…ғзҠ¶жҖҒжҸҗдҫӣдҝЎжҒҜгҖӮиҝҷз§ҚеҚ•е…ғзҠ¶жҖҒжҳҜйҖҡиҝҮзҪ‘з»ңе’Ңиҫ“е…ҘдҝқжҢҒй•ҝжңҹи®°еҝҶе’ҢдёҠдёӢж–ҮгҖӮ
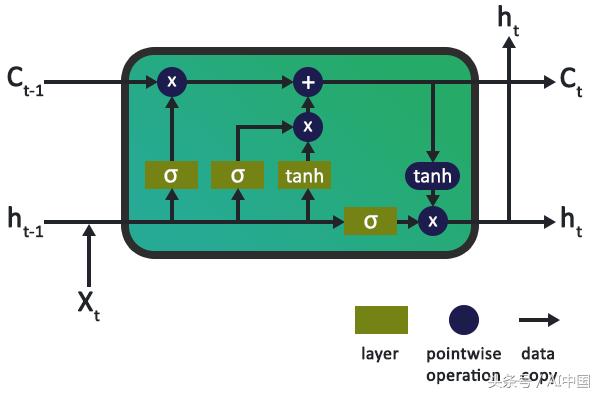
дёҖдёӘз®ҖеҚ•зҡ„жӯЈејҰжіўзӨәдҫӢ
дёәдәҶжј”зӨәLSTMзҘһз»ҸзҪ‘з»ңеңЁйў„жөӢж—¶й—ҙеәҸеҲ—дёӯзҡ„дҪҝз”ЁпјҢи®©жҲ‘们д»ҺжңҖеҹәжң¬зҡ„дәӢжғ…ејҖе§ӢпјҢжҲ‘们еҸҜд»ҘжғіеҲ°иҝҷжҳҜдёҖдёӘж—¶й—ҙеәҸеҲ—пјҡеҸҜйқ зҡ„жӯЈејҰжіўгҖӮи®©жҲ‘们еҲӣе»әжҲ‘们йңҖиҰҒзҡ„ж•°жҚ®пјҢд»ҘдҫҝдёәLSTMзҪ‘з»ңи®ӯз»ғжӯӨеҮҪж•°зҡ„и®ёеӨҡвҖңжҢҜиҚЎжЁЎеһӢвҖқгҖӮ
д»Јз Ғж•°жҚ®ж–Ү件еӨ№дёӯжҸҗдҫӣзҡ„ж•°жҚ®еҢ…еҗ«жҲ‘们еҲӣе»әзҡ„sinewave.csvж–Ү件пјҢиҜҘж–Ү件еҢ…еҗ«5001дёӘжӯЈејҰжіўж—¶й—ҙж®өпјҢе№…еәҰе’Ңйў‘зҺҮдёә1пјҲи§’йў‘зҺҮдёә6.28пјүпјҢж—¶й—ҙе·®еҖјдёә0.01гҖӮз»ҳеҲ¶ж—¶зҡ„з»“жһңеҰӮдёӢжүҖзӨәпјҡ

ж•°жҚ®йӣҶдёәжӯЈејҰжіў
зҺ°еңЁжҲ‘们жңүдәҶж•°жҚ®пјҢжҲ‘们е®һйҷ…дёҠжғіиҰҒе®һзҺ°д»Җд№Ҳпјҹз®ҖеҚ•зҡ„иҜҙпјҢжҲ‘们еҸӘжҳҜеёҢжңӣLSTMд»ҺжҲ‘们е°ҶжҸҗдҫӣзҡ„ж•°жҚ®зҡ„и®ҫе®ҡзӘ—еҸЈеӨ§е°ҸдёӯеӯҰд№ жӯЈејҰжіўпјҢ并且еёҢжңӣжҲ‘们еҸҜд»ҘиҰҒжұӮLSTMйў„жөӢиҜҘзі»еҲ—дёӯзҡ„第NжӯҘйӘӨпјҢ并且е®ғе°Ҷ继з»ӯиҫ“еҮәжӯЈејҰжіўгҖӮ
жҲ‘们е°ҶйҰ–е…ҲжҠҠCSVж–Ү件дёӯзҡ„ж•°жҚ®иҪ¬жҚўеҠ иҪҪеҲ°pandasж•°жҚ®её§пјҢ然еҗҺе°Ҷе…¶з”ЁдәҺиҫ“еҮәпјҢе®ғе°ҶдёәLSTMжҸҗдҫӣж•°жҚ®зҡ„numpyж•°з»„гҖӮ Keras LSTMеұӮзҡ„е·ҘдҪңж–№ејҸжҳҜйҮҮз”Ё3з»ҙпјҲNпјҢWпјҢFпјүзҡ„numpyж•°з»„пјҢе…¶дёӯNжҳҜи®ӯз»ғеәҸеҲ—зҡ„ж•°йҮҸпјҢWжҳҜеәҸеҲ—й•ҝеәҰпјҢFжҳҜжҜҸдёӘеәҸеҲ—зҡ„зү№еҫҒж•°гҖӮжҲ‘们йҖүжӢ©дҪҝз”Ё50зҡ„еәҸеҲ—й•ҝеәҰпјҲиҜ»еҸ–зӘ—еҸЈеӨ§е°ҸпјүжқҘе…Ғи®ёзҪ‘з»ңпјҢеӣ жӯӨеҸҜд»ҘеңЁжҜҸдёӘеәҸеҲ—дёӯзңӢеҲ°жӯЈејҰжіўзҡ„еҪўзҠ¶пјҢжңүеёҢжңӣиҮӘе·ұе»әз«ӢеҹәдәҺеәҸеҲ—зҡ„еәҸеҲ—жЁЎејҸгҖӮ
еәҸеҲ—жң¬иә«жҳҜж»‘еҠЁзӘ—еҸЈпјҢеӣ жӯӨжҜҸ次移еҠЁ1пјҢеҜјиҮҙдёҺе…ҲеүҚзӘ—еҸЈдёҚж–ӯйҮҚеҸ гҖӮеҪ“з»ҳеҲ¶ж—¶пјҢеәҸеҲ—й•ҝеәҰдёә50зҡ„е…ёеһӢи®ӯз»ғзӘ—еҸЈеҰӮдёӢжүҖзӨәпјҡ

Sinewaveж•°жҚ®йӣҶи®ӯз»ғзӘ—еҸЈ
дёәдәҶеҠ иҪҪиҝҷдәӣж•°жҚ®пјҢжҲ‘们еңЁд»Јз ҒдёӯеҲӣе»әдәҶдёҖдёӘDataLoaderзұ»пјҢдёәж•°жҚ®еҠ иҪҪеұӮжҸҗдҫӣжҠҪиұЎгҖӮжӮЁдјҡжіЁж„ҸеҲ°пјҢеңЁеҲқе§ӢеҢ–DataLoaderеҜ№иұЎж—¶пјҢдјҡдј е…Ҙж–Ү件еҗҚпјҢ 并确е®ҡз”ЁдәҺи®ӯз»ғдёҺжөӢиҜ•зҡ„ж•°жҚ®зҷҫеҲҶжҜ”зҡ„жӢҶеҲҶеҸҳйҮҸпјҢдё”е…Ғи®ёйҖүжӢ©дёҖеҲ—жҲ–еӨҡеҲ—ж•°жҚ®зҡ„еҲ—еҸҳйҮҸз”ЁдәҺеҚ•з»ҙжҲ–еӨҡз»ҙеҲҶжһҗгҖӮ
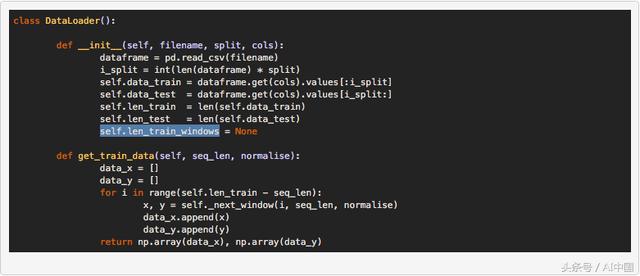
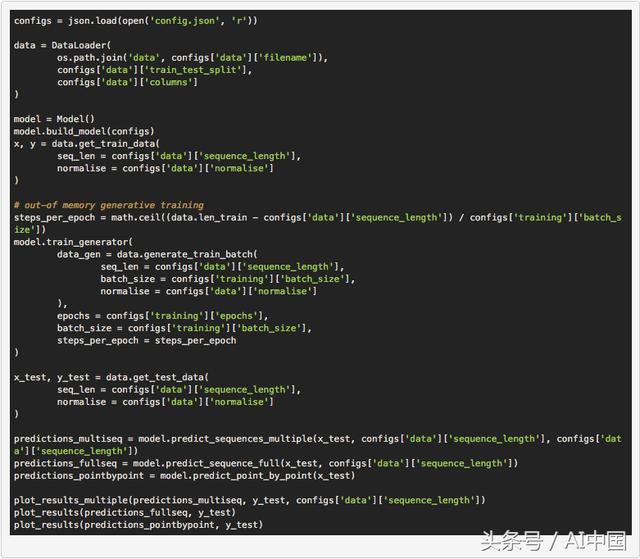
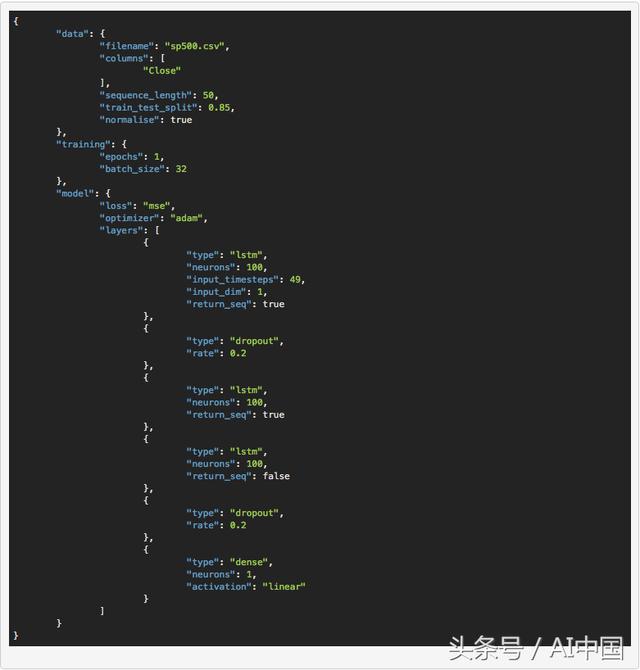
еңЁжҲ‘们жңүдёҖдёӘе…Ғи®ёжҲ‘们еҠ иҪҪж•°жҚ®зҡ„ж•°жҚ®еҜ№иұЎд№ӢеҗҺпјҢйңҖиҰҒжһ„е»әж·ұеәҰзҘһз»ҸзҪ‘з»ңжЁЎеһӢгҖӮеҗҢж ·пјҢеҜ№дәҺжҠҪиұЎпјҢжҲ‘们зҡ„д»Јз ҒжЎҶжһ¶дҪҝз”Ёзҡ„жҳҜжЁЎеһӢзұ»е’Ңconfig.jsonж–Ү件пјҢеңЁз»ҷе®ҡеӯҳеӮЁеңЁй…ҚзҪ®ж–Ү件дёӯзҡ„жүҖйңҖдҪ“зі»з»“жһ„е’Ңи¶…еҸӮж•°зҡ„жғ…еҶөдёӢпјҢиҪ»жқҫжһ„е»әжЁЎеһӢзҡ„е®һдҫӢгҖӮжһ„е»әжҲ‘们зҪ‘з»ңзҡ„дё»иҰҒеҠҹиғҪжҳҜbuild_modelпјҲпјүеҮҪж•°пјҢе®ғжҺҘ收з»ҸиҝҮи§Јжһҗзҡ„й…ҚзҪ®ж–Ү件гҖӮ
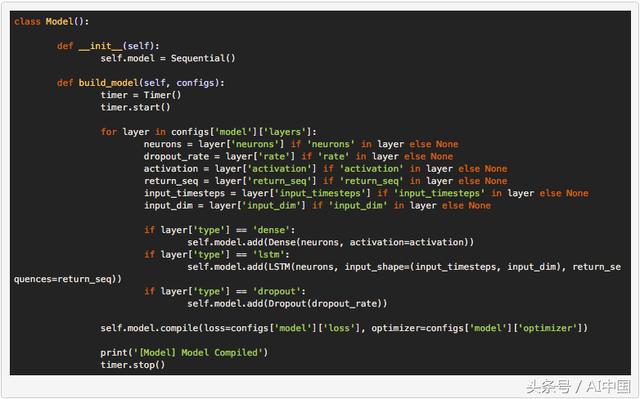
жӯӨеҠҹиғҪд»Јз ҒеҰӮдёӢжүҖзӨәпјҢеҸҜд»ҘиҪ»жқҫжү©еұ•пјҢд»Ҙдҫҝе°ҶжқҘеңЁжӣҙеӨҚжқӮзҡ„дҪ“зі»жһ¶жһ„дёҠдҪҝз”ЁгҖӮ
еҠ иҪҪж•°жҚ®е№¶е»әз«ӢжЁЎеһӢеҗҺпјҢжҲ‘们зҺ°еңЁеҸҜд»Ҙ继з»ӯдҪҝз”ЁжҲ‘们зҡ„и®ӯз»ғж•°жҚ®и®ӯз»ғжЁЎеһӢгҖӮдёәжӯӨпјҢжҲ‘们еҲӣе»әдәҶдёҖдёӘеҚ•зӢ¬зҡ„иҝҗиЎҢжЁЎеқ—пјҢе®ғе°ҶеҲ©з”ЁжҲ‘们зҡ„жЁЎеһӢе’ҢжЁЎеқ—жҠҪиұЎе°Ҷе®ғ们组еҗҲиө·жқҘиҝӣиЎҢи®ӯз»ғгҖҒиҫ“еҮәе’ҢеҸҜи§ҶеҢ–гҖӮ
дёӢйқўжҳҜи®ӯз»ғжҲ‘们模еһӢзҡ„дёҖиҲ¬иҝҗиЎҢзәҝзЁӢд»Јз Ғпјҡ

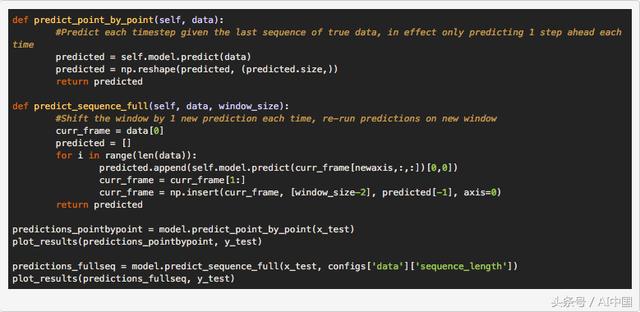
еҜ№дәҺиҫ“еҮәпјҢжҲ‘们е°ҶиҝҗиЎҢдёӨз§Қзұ»еһӢзҡ„йў„жөӢпјҡ第дёҖз§Қе°Ҷд»ҘйҖҗзӮ№ж–№ејҸиҝӣиЎҢйў„жөӢпјҢеҚіжҲ‘们жҜҸж¬Ўд»…йў„жөӢеҚ•дёӘзӮ№пјҢе°ҶжӯӨзӮ№з»ҳеҲ¶дёәйў„жөӢпјҢ然еҗҺжІҝзқҖдёӢдёҖдёӘзӘ—еҸЈиҝӣиЎҢйў„жөӢдҪҝз”Ёе®Ңж•ҙзҡ„жөӢиҜ•ж•°жҚ®е№¶еҶҚж¬Ўйў„жөӢдёӢдёҖдёӘзӮ№гҖӮ
жҲ‘们иҰҒеҒҡзҡ„第дәҢдёӘйў„жөӢжҳҜйў„жөӢдёҖдёӘе®Ңж•ҙзҡ„еәҸеҲ—пјҢжҲ‘们еҸӘз”Ёи®ӯз»ғж•°жҚ®зҡ„第дёҖйғЁеҲҶеҲқе§ӢеҢ–дёҖж¬Ўи®ӯз»ғзӘ—еҸЈгҖӮ然еҗҺжЁЎеһӢйў„жөӢдёӢдёҖдёӘзӮ№пјҢжҲ‘们е°ұ移еҠЁзӘ—еҸЈпјҢе°ұеғҸйҖҗзӮ№ж–№жі•дёҖж ·гҖӮдёҚеҗҢд№ӢеӨ„еңЁдәҺжҲ‘们дҪҝз”ЁжҲ‘们еңЁе…ҲеүҚйў„жөӢдёӯйў„жөӢзҡ„ж•°жҚ®жқҘиҝӣиЎҢдёӢдёҖжӯҘйў„жөӢгҖӮеңЁз¬¬дәҢжӯҘдёӯпјҢиҝҷж„Ҹе‘ізқҖеҸӘжңүдёҖдёӘж•°жҚ®зӮ№пјҲжңҖеҗҺдёҖдёӘзӮ№пјүжқҘиҮӘе…ҲеүҚзҡ„йў„жөӢгҖӮеңЁз¬¬дёүдёӘйў„жөӢдёӯпјҢжңҖеҗҺдёӨдёӘж•°жҚ®зӮ№е°ҶжқҘиҮӘе…ҲеүҚзҡ„йў„жөӢпјҢдҫқжӯӨзұ»жҺЁгҖӮз»ҸиҝҮ50ж¬Ўйў„жөӢеҗҺпјҢжҲ‘们зҡ„жЁЎеһӢе°ҶйҡҸеҗҺж №жҚ®иҮӘе·ұзҡ„е…ҲеүҚйў„жөӢиҝӣиЎҢйў„жөӢгҖӮиҝҷдҪҝжҲ‘们еҸҜд»ҘдҪҝз”ЁиҜҘжЁЎеһӢйў„жөӢжңӘжқҘзҡ„и®ёеӨҡж—¶й—ҙжӯҘйӘӨпјҢдҪҶз”ұдәҺе®ғжҳҜеңЁйў„жөӢзҡ„еҹәзЎҖдёҠиҝӣиЎҢйў„жөӢпјҢиҝҷеҸҚиҝҮжқҘеҸҜд»ҘеҸҚиҝҮжқҘеҸҲеҸҜд»Ҙйў„жөӢпјҢе°ҶеўһеҠ йў„жөӢзҡ„й”ҷиҜҜзҺҮпјҢжҲ‘们дјҡйў„жөӢзҡ„жӣҙиҝңгҖӮ
дёӢйқўжҲ‘们еҸҜд»ҘзңӢеҲ°йҖҗзӮ№йў„жөӢе’Ңе®Ңж•ҙеәҸеҲ—йў„жөӢзҡ„д»Јз Ғе’Ңзӣёеә”зҡ„иҫ“еҮәгҖӮ

йҖҗзӮ№жӯЈејҰжіўйў„жөӢ
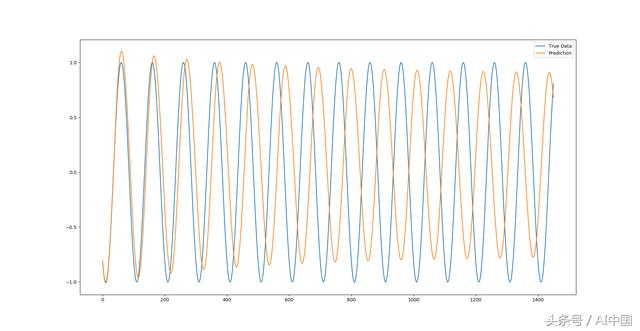
жӯЈејҰжіўе…ЁеәҸеҲ—йў„жөӢ
дҪңдёәеҸӮиҖғпјҢеҸҜд»ҘеңЁдёӢйқўзҡ„й…ҚзҪ®ж–Ү件дёӯзңӢеҲ°з”ЁдәҺжӯЈејҰжіўзӨәдҫӢзҡ„зҪ‘з»ңжһ¶жһ„е’Ңи¶…еҸӮж•°гҖӮ

еңЁзңҹе®һж•°жҚ®зҡ„еҸ еҠ дёӢжҲ‘们еҸҜд»ҘзңӢеҲ°пјҢеҸӘйңҖ1дёӘж—¶жңҹе’ҢзӣёеҪ“е°Ҹзҡ„и®ӯз»ғж•°жҚ®йӣҶпјҢLSTMж·ұеәҰзҘһз»ҸзҪ‘з»ңе°ұеҸҜд»ҘеҫҲеҘҪең°йў„жөӢжӯЈејҰеҮҪж•°гҖӮ
жӮЁеҸҜд»ҘзңӢеҲ°пјҢйҡҸзқҖжҲ‘们еҜ№жңӘжқҘи¶ҠжқҘи¶ҠеӨҡзҡ„йў„жөӢпјҢиҜҜе·®е№…еәҰдјҡйҡҸзқҖе…ҲеүҚйў„жөӢдёӯзҡ„иҜҜе·®еңЁз”ЁдәҺжңӘжқҘйў„жөӢж—¶иў«и¶ҠжқҘи¶ҠеӨҡең°ж”ҫеӨ§е№¶дё”еўһеҠ гҖӮеӣ жӯӨпјҢжҲ‘们зңӢеҲ°еңЁе®Ңж•ҙеәҸеҲ—зӨәдҫӢдёӯпјҢйў„жөӢи¶ҠиҝңпјҢжҲ‘们预жөӢйў„жөӢзҡ„йў‘зҺҮе’Ңе№…еәҰдёҺзңҹе®һж•°жҚ®зӣёжҜ”е°ұи¶ҠдёҚеҮҶзЎ®гҖӮ然иҖҢпјҢз”ұдәҺsinеҮҪж•°жҳҜдёҖдёӘйқһеёёз®ҖеҚ•зҡ„йӣ¶еҷӘеЈ°жҢҜиҚЎеҮҪж•°пјҢе®ғд»Қ然еҸҜд»ҘеңЁжІЎжңүиҝҮеәҰжӢҹеҗҲзҡ„жғ…еҶөдёӢеҫҲеҘҪең°йў„жөӢе®ғгҖӮиҝҷеҫҲйҮҚиҰҒпјҢеӣ дёәжҲ‘们еҸҜд»ҘйҖҡиҝҮеўһеҠ ж—¶жңҹе’ҢеҸ–еҮәdropout еұӮжқҘиҪ»жқҫең°иҝҮеәҰжӢҹеҗҲжЁЎеһӢгҖӮиҝҷдёӘи®ӯз»ғж•°жҚ®еҮ д№Һе®Ңе…ЁеҮҶзЎ®пјҢдёҺжөӢиҜ•ж•°жҚ®е…·жңүзӣёеҗҢзҡ„жЁЎејҸпјҢдҪҶеҜ№дәҺе…¶д»–зҺ°е®һдё–з•Ңзҡ„дҫӢеӯҗпјҢе°ҶжЁЎеһӢиҝҮеәҰжӢҹеҗҲеҲ°и®ӯз»ғж•°жҚ®дёҠдјҡеҜјиҮҙжөӢиҜ•зІҫеәҰзӣҙзәҝдёӢйҷҚпјҢеӣ дёәжЁЎеһӢдёҚдјҡдёҖжҰӮиҖҢи®әгҖӮ
еңЁдёӢдёҖжӯҘдёӯпјҢжҲ‘们е°Ҷе°қиҜ•еңЁжӯӨзұ»зңҹе®һж•°жҚ®дёҠдҪҝз”ЁиҜҘжЁЎеһӢжқҘжҹҘзңӢж•ҲжһңгҖӮ
дёҚйӮЈд№Ҳз®ҖеҚ•зҡ„иӮЎзҘЁеёӮеңә
жҲ‘们еңЁзІҫзЎ®зҡ„йҖҗзӮ№еҹәзЎҖдёҠйў„жөӢдәҶеҮ зҷҫдёӘжӯЈејҰжіўзҡ„жӯҘй•ҝгҖӮеӣ жӯӨпјҢжҲ‘们зҺ°еңЁеҸҜд»ҘеңЁиӮЎеёӮж—¶й—ҙеәҸеҲ—дёӯеҒҡеҗҢж ·зҡ„дәӢжғ…并з«ӢеҚіиҺ·еҲ©пјҢеҜ№еҗ—пјҹдёҚе№ёзҡ„жҳҜпјҢеңЁзҺ°е®һдё–з•ҢдёӯпјҢиҝҷ并дёҚжҳҜйӮЈд№Ҳз®ҖеҚ•гҖӮ
дёҺжӯЈејҰжіўдёҚеҗҢпјҢиӮЎзҘЁеёӮеңәж—¶й—ҙеәҸеҲ—дёҚжҳҜеҸҜд»Ҙжҳ е°„зҡ„д»»дҪ•зү№е®ҡйқҷжҖҒеҮҪж•°гҖӮжҸҸиҝ°иӮЎзҘЁеёӮеңәж—¶й—ҙеәҸеҲ—иҝҗеҠЁзҡ„жңҖдҪіеұһжҖ§жҳҜйҡҸжңәжёёиө°гҖӮдҪңдёәйҡҸжңәиҝҮзЁӢпјҢзңҹжӯЈзҡ„йҡҸжңәжёёиө°жІЎжңүеҸҜйў„жөӢзҡ„жЁЎејҸпјҢеӣ жӯӨе°қиҜ•еҜ№е…¶иҝӣиЎҢе»әжЁЎе°ҶжҜ«ж— ж„Ҹд№үгҖӮе№ёиҝҗзҡ„жҳҜпјҢи®ёеӨҡж–№йқўйғҪеңЁжҢҒз»ӯдәүи®әиҜҙиӮЎзҘЁеёӮеңәдёҚжҳҜдёҖдёӘзәҜзІ№зҡ„йҡҸжңәиҝҮзЁӢпјҢиҝҷдҪҝжҲ‘们еҸҜд»ҘзҗҶи§Јж—¶й—ҙеәҸеҲ—еҸҜиғҪжңүжҹҗз§Қйҡҗи—ҸжЁЎејҸгҖӮжӯЈжҳҜиҝҷдәӣйҡҗи—Ҹзҡ„жЁЎејҸпјҢLSTMж·ұеәҰзҪ‘з»ңжҲҗдёәйў„жөӢзҡ„дё»иҰҒеҖҷйҖүиҖ…гҖӮ
жӯӨзӨәдҫӢе°ҶдҪҝз”Ёзҡ„ж•°жҚ®жҳҜж•°жҚ®ж–Ү件еӨ№дёӯзҡ„sp500.csvж–Ү件гҖӮжӯӨж–Ү件еҢ…еҗ«2000е№ҙ1жңҲиҮі2018е№ҙ9жңҲзҡ„ж ҮеҮҶжҷ®е°”500иӮЎзҘЁжҢҮж•°зҡ„ејҖзӣҳд»·гҖҒжңҖй«ҳд»·гҖҒжңҖдҪҺд»·гҖҒ收зӣҳд»·д»ҘеҸҠжҜҸж—ҘдәӨжҳ“йҮҸгҖӮ
еңЁз¬¬дёҖдёӘдҫӢеӯҗдёӯпјҢжҲ‘们е°Ҷд»…дҪҝ用收зӣҳд»·еҲӣе»әеҚ•з»ҙжЁЎеһӢгҖӮи°ғж•ҙconfig.jsonж–Ү件д»ҘеҸҚжҳ ж–°ж•°жҚ®пјҢжҲ‘们е°ҶдҝқжҢҒеӨ§йғЁеҲҶеҸӮж•°зӣёеҗҢгҖӮ然иҖҢпјҢйңҖиҰҒеҒҡеҮәзҡ„дёҖдёӘж”№еҸҳжҳҜпјҢдёҺеҸӘжңү-1еҲ°+1д№Ӣй—ҙзҡ„ж•°еҖјиҢғеӣҙзҡ„жӯЈејҰжіўдёҚеҗҢпјҢ收зӣҳд»·жҳҜиӮЎзҘЁеёӮеңәдёҚж–ӯеҸҳеҢ–зҡ„з»қеҜ№д»·ж јгҖӮиҝҷж„Ҹе‘ізқҖеҰӮжһңжҲ‘们иҜ•еӣҫеңЁдёҚеҜ№е…¶иҝӣиЎҢж ҮеҮҶеҢ–зҡ„жғ…еҶөдёӢи®ӯз»ғжЁЎеһӢпјҢе®ғе°ұж°ёиҝңдёҚдјҡ收ж•ӣгҖӮ
дёәдәҶи§ЈеҶіиҝҷдёӘй—®йўҳпјҢжҲ‘们е°ҶйҮҮз”ЁжҜҸдёӘnеӨ§е°Ҹзҡ„и®ӯз»ғ/жөӢиҜ•ж•°жҚ®зӘ—еҸЈпјҢ并еҜ№жҜҸдёӘзӘ—еҸЈиҝӣиЎҢж ҮеҮҶеҢ–д»ҘеҸҚжҳ д»ҺиҜҘзӘ—еҸЈејҖе§Ӣзҡ„зҷҫеҲҶжҜ”еҸҳеҢ–пјҲеӣ жӯӨзӮ№i = 0еӨ„зҡ„ж•°жҚ®е°Ҷе§Ӣз»Ҳдёә0пјүгҖӮжҲ‘们е°ҶдҪҝз”Ёд»ҘдёӢзӯүејҸиҝӣиЎҢеҪ’дёҖеҢ–пјҢ然еҗҺеңЁйў„жөӢиҝҮзЁӢз»“жқҹж—¶иҝӣиЎҢеҺ»ж ҮеҮҶеҢ–пјҢд»ҘиҺ·еҫ—зҺ°е®һдё–з•Ңж•°йҮҸзҡ„йў„жөӢпјҡ
n =д»·ж јеҸҳеҢ–зҡ„ж ҮеҮҶеҢ–еҲ—иЎЁ[зӘ—еҸЈ]
p =и°ғж•ҙеҗҺзҡ„жҜҸж—ҘеӣһжҠҘд»·ж јзҡ„еҺҹе§Ӣжё…еҚ•[зӘ—еҸЈ]
жӯЈеёёеҢ–пјҡ
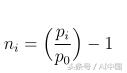
еҸҚ规иҢғеҢ–пјҡ
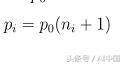
жҲ‘们已е°Ҷnormalise_windowsпјҲпјүеҮҪж•°ж·»еҠ еҲ°DataLoaderзұ»д»Ҙжү§иЎҢжӯӨиҪ¬жҚўпјҢ并且й…ҚзҪ®ж–Ү件дёӯеҢ…еҗ«еёғ尔规иҢғеҢ–ж Үеҝ—пјҢиЎЁзӨәиҝҷдәӣзӘ—еҸЈзҡ„规иҢғеҢ–гҖӮ
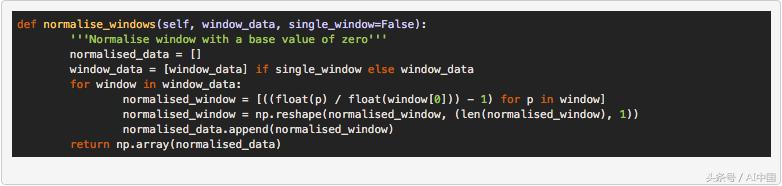
йҡҸзқҖзӘ—еҸЈзҡ„ж ҮеҮҶеҢ–пјҢжҲ‘们зҺ°еңЁеҸҜд»ҘиҝҗиЎҢжЁЎеһӢпјҢе°ұеғҸжҲ‘们й’ҲеҜ№жӯЈејҰжіўж•°жҚ®иҝҗиЎҢжЁЎеһӢдёҖж ·гҖӮдҪҶжҳҜпјҢжҲ‘们еңЁиҝҗиЎҢиҝҷдәӣж•°жҚ®ж—¶еҒҡдәҶдёҖдёӘйҮҚиҰҒзҡ„ж”№еҸҳпјҢиҖҢдёҚжҳҜдҪҝз”ЁжҲ‘们жЎҶжһ¶зҡ„model.trainпјҲпјүж–№жі•пјҢеҸӘжҳҜдҪҝз”ЁжҲ‘们еҲӣе»әзҡ„model.train_generatorпјҲпјүж–№жі•гҖӮжҲ‘们иҝҷж ·еҒҡжҳҜеӣ дёәжҲ‘们еҸ‘зҺ°еңЁе°қиҜ•и®ӯз»ғеӨ§еһӢж•°жҚ®йӣҶж—¶еҫҲе®№жҳ“иҖ—е°ҪеҶ…еӯҳпјҢеӣ дёәmodel.trainпјҲпјүеҮҪж•°е°Ҷе®Ңж•ҙж•°жҚ®йӣҶеҠ иҪҪеҲ°еҶ…еӯҳдёӯпјҢ然еҗҺе°Ҷ规иҢғеҢ–еә”з”ЁдәҺеҶ…еӯҳдёӯзҡ„жҜҸдёӘзӘ—еҸЈпјҢе®№жҳ“еҜјиҮҙеҶ…еӯҳжәўеҮәгҖӮеӣ жӯӨпјҢжҲ‘们дҪҝз”ЁдәҶKerasзҡ„fit_generatorпјҲпјүеҮҪж•°пјҢе…Ғи®ёдҪҝз”Ёpythonз”ҹжҲҗеҷЁеҠЁжҖҒи®ӯз»ғж•°жҚ®йӣҶжқҘз»ҳеҲ¶ж•°жҚ®пјҢиҝҷж„Ҹе‘ізқҖеҶ…еӯҳеҲ©з”ЁзҺҮе°ҶеӨ§еӨ§йҷҚдҪҺгҖӮдёӢйқўзҡ„д»Јз ҒиҜҰз»ҶиҜҙжҳҺдәҶз”ЁдәҺиҝҗиЎҢдёүз§Қзұ»еһӢйў„жөӢзҡ„ж–°иҝҗиЎҢзәҝзЁӢпјҲйҖҗзӮ№пјҢе®Ңж•ҙеәҸеҲ—е’ҢеӨҡеәҸеҲ—пјүгҖӮ
еҰӮдёҠжүҖиҝ°пјҢеңЁеҚ•дёӘйҖҗзӮ№йў„жөӢдёҠиҝҗиЎҢж•°жҚ®еҸҜд»ҘйқһеёёжҺҘиҝ‘еҢ№й…Қиҝ”еӣһзҡ„еҶ…е®№гҖӮдҪҶиҝҷжңүзӮ№ж¬әйӘ—жҖ§гҖӮз»ҸиҝҮд»”з»ҶжЈҖжҹҘпјҢдјҡеҸ‘зҺ°йў„жөӢзәҝз”ұеҘҮејӮзҡ„йў„жөӢзӮ№з»„жҲҗпјҢиҝҷдәӣйў„жөӢзӮ№еңЁе®ғ们еҗҺйқўе…·жңүж•ҙдёӘе…ҲеүҚзҡ„зңҹе®һеҺҶеҸІзӘ—еҸЈгҖӮеӣ жӯӨпјҢзҪ‘з»ңдёҚйңҖиҰҒдәҶи§Јж—¶й—ҙеәҸеҲ—жң¬иә«пјҢйҷӨдәҶдёӢдёҖдёӘзӮ№еҫҲеҸҜиғҪдёҚдјҡзҰ»жңҖеҗҺдёҖзӮ№еӨӘиҝңгҖӮеӣ жӯӨпјҢеҚідҪҝе®ғеҫ—еҲ°й”ҷиҜҜзӮ№зҡ„йў„жөӢпјҢдёӢдёҖдёӘйў„жөӢд№ҹе°ҶиҖғиҷ‘зңҹе®һзҡ„еҺҶеҸІе№¶еҝҪз•ҘдёҚжӯЈзЎ®зҡ„йў„жөӢпјҢ然еҗҺеҶҚж¬Ўе…Ғи®ёдә§з”ҹй”ҷиҜҜгҖӮ
иҷҪ然иҝҷеҜ№дәҺдёӢдёҖдёӘд»·ж јзӮ№зҡ„зІҫзЎ®йў„жөӢиҖҢиЁҖжңҖеҲқеҗ¬иө·жқҘ并дёҚд№җи§ӮпјҢдҪҶе®ғзЎ®е®һжңүдёҖдәӣйҮҚиҰҒзҡ„з”ЁйҖ”гҖӮиҷҪ然е®ғдёҚзҹҘйҒ“зЎ®еҲҮзҡ„дёӢдёҖдёӘд»·ж јжҳҜеӨҡе°‘пјҢдҪҶе®ғзЎ®е®һиғҪеӨҹеҮҶзЎ®ең°иЎЁзӨәдёӢдёҖдёӘд»·ж јзҡ„иҢғеӣҙгҖӮ
жӯӨдҝЎжҒҜеҸҜз”ЁдәҺиҜёеҰӮжіўеҠЁзҺҮйў„жөӢзӯүеә”з”ЁпјҲиғҪеӨҹйў„жөӢеёӮеңәдёӯй«ҳжҲ–дҪҺжіўеҠЁзҡ„ж—¶ж®өеҜ№зү№е®ҡдәӨжҳ“зӯ–з•ҘйқһеёёжңүеҲ©пјүпјҢжҲ–иҝңзҰ»дәӨжҳ“иҝҷд№ҹеҸҜз”ЁдҪңиүҜеҘҪжҢҮж Үз”ЁдәҺејӮеёёжЈҖжөӢгҖӮеҸҜд»ҘйҖҡиҝҮйў„жөӢдёӢдёҖдёӘзӮ№пјҢ然еҗҺе°Ҷе…¶дёҺзңҹе®һж•°жҚ®иҝӣиЎҢжҜ”иҫғжқҘе®һзҺ°ејӮеёёжЈҖжөӢпјҢ并且еҰӮжһңзңҹе®һж•°жҚ®еҖјдёҺйў„жөӢзӮ№жҳҫи‘—дёҚеҗҢпјҢеҲҷеҸҜд»Ҙй’ҲеҜ№иҜҘж•°жҚ®зӮ№ж ҮеҮәејӮеёёж Үи®°гҖӮ
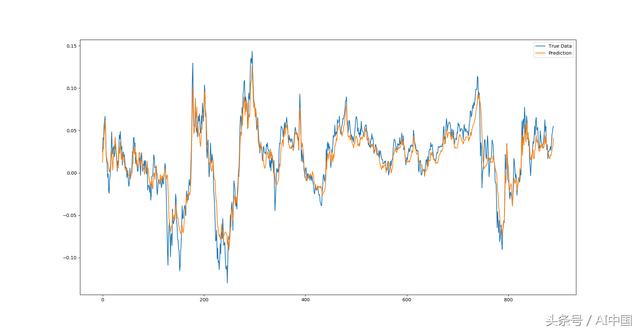
ж ҮеҮҶжҷ®е°”500жҢҮж•°йҖҗзӮ№йў„жөӢ
继з»ӯиҝӣиЎҢе®Ңж•ҙзҡ„еәҸеҲ—йў„жөӢпјҢдјјд№Һиҝҷиў«иҜҒжҳҺжҳҜеҜ№иҝҷз§Қзұ»еһӢзҡ„ж—¶й—ҙеәҸеҲ—жңҖдёҚжңүз”Ёзҡ„йў„жөӢпјҲиҮіе°‘дҪҝз”Ёиҝҷдәӣи¶…еҸӮж•°и®ӯз»ғиҝҷдёӘжЁЎеһӢпјүгҖӮжҲ‘们еҸҜд»ҘзңӢеҲ°йў„жөӢејҖе§Ӣж—¶зҡ„иҪ»еҫ®зў°ж’һпјҢе…¶дёӯжЁЎеһӢйҒөеҫӘжҹҗз§Қзұ»еһӢзҡ„еҠЁйҮҸпјҢдҪҶжҳҜеҫҲеҝ«жҲ‘们еҸҜд»ҘзңӢеҲ°жЁЎеһӢзЎ®е®ҡжңҖдҪіжЁЎејҸжҳҜ收ж•ӣеҲ°ж—¶й—ҙеәҸеҲ—зҡ„жҹҗдёӘеқҮиЎЎгҖӮеңЁиҝҷдёӘйҳ¶ж®өпјҢиҝҷеҸҜиғҪзңӢиө·жқҘ并没жңүжҸҗдҫӣеӨӘеӨҡд»·еҖјпјҢдҪҶжҳҜеқҮеҖјеӣһеҪ’дәӨжҳ“иҖ…еҸҜиғҪдјҡеңЁйӮЈйҮҢе®Јз§°пјҢиҜҘжЁЎеһӢеҸӘжҳҜжүҫеҲ°д»·ж јеәҸеҲ—еңЁжіўеҠЁзҺҮиў«ж¶ҲйҷӨж—¶е°ҶжҒўеӨҚзҡ„е№іеқҮеҖјгҖӮ
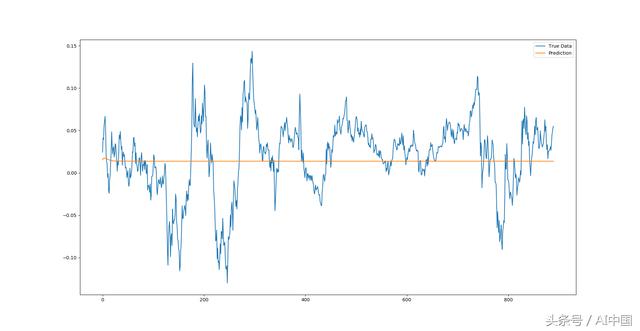
ж ҮеҮҶжҷ®е°”500жҢҮж•°е…ЁеәҸеҲ—йў„жөӢ
жңҖеҗҺпјҢжҲ‘们еҜ№иҜҘжЁЎеһӢиҝӣиЎҢдәҶ第дёүз§Қйў„жөӢпјҢжҲ‘е°Ҷе…¶з§°дёәеӨҡеәҸеҲ—йў„жөӢгҖӮиҝҷжҳҜе®Ңж•ҙеәҸеҲ—йў„жөӢзҡ„ж··еҗҲпјҢеӣ дёәе®ғд»Қ然дҪҝз”ЁжөӢиҜ•ж•°жҚ®еҲқе§ӢеҢ–жөӢиҜ•зӘ—еҸЈпјҢйў„жөӢдёӢдёҖдёӘзӮ№пјҢ然еҗҺдҪҝз”ЁдёӢдёҖдёӘзӮ№еҲӣе»әдёҖдёӘж–°зӘ—еҸЈгҖӮдҪҶжҳҜпјҢдёҖж—Ұе®ғеҲ°иҫҫиҫ“е…ҘзӘ—еҸЈе®Ңе…Ёз”ұиҝҮеҺ»йў„жөӢз»„жҲҗзҡ„зӮ№пјҢе®ғе°ұдјҡеҒңжӯўпјҢеҗ‘еүҚ移еҠЁдёҖдёӘе®Ңж•ҙзҡ„зӘ—еҸЈй•ҝеәҰпјҢз”Ёзңҹе®һзҡ„жөӢиҜ•ж•°жҚ®йҮҚзҪ®зӘ—еҸЈпјҢ然еҗҺеҶҚж¬ЎеҗҜеҠЁиҜҘиҝҮзЁӢгҖӮе®һиҙЁдёҠпјҢиҝҷдёәжөӢиҜ•ж•°жҚ®жҸҗдҫӣдәҶеӨҡдёӘи¶ӢеҠҝзәҝйў„жөӢпјҢд»ҘдҫҝиғҪеӨҹеҲҶжһҗжЁЎеһӢиҺ·еҫ—жңӘжқҘеҠЁйҮҸи¶ӢеҠҝзҡ„зЁӢеәҰгҖӮ

ж ҮеҮҶжҷ®е°”500жҢҮж•°еӨҡеәҸеҲ—йў„жөӢ
жҲ‘们еҸҜд»Ҙд»ҺеӨҡеәҸеҲ—йў„жөӢдёӯзңӢеҮәпјҢзҪ‘з»ңдјјд№ҺжӯЈзЎ®ең°йў„жөӢдәҶз»қеӨ§еӨҡж•°ж—¶й—ҙеәҸеҲ—зҡ„и¶ӢеҠҝпјҲе’Ңи¶ӢеҠҝе№…еәҰпјүгҖӮиҷҪ然дёҚе®ҢзҫҺпјҢдҪҶе®ғзЎ®е®һиЎЁжҳҺдәҶLSTMж·ұеәҰзҘһз»ҸзҪ‘з»ңеңЁйЎәеәҸе’Ңж—¶й—ҙеәҸеҲ—й—®йўҳдёӯзҡ„жңүз”ЁжҖ§гҖӮйҖҡиҝҮд»”з»Ҷзҡ„и¶…еҸӮж•°и°ғж•ҙпјҢиӮҜе®ҡеҸҜд»Ҙе®һзҺ°жӣҙй«ҳзҡ„еҮҶзЎ®жҖ§гҖӮ
з»“и®ә
иҷҪ然жң¬ж–Үзҡ„зӣ®зҡ„жҳҜеңЁе®һи·өдёӯз»ҷеҮәLSTMж·ұеәҰзҘһз»ҸзҪ‘з»ңзҡ„дёҖдёӘе·ҘдҪңе®һдҫӢпјҢдҪҶе®ғеҸӘжҳҜи§ҰеҸҠдәҶе®ғ们еңЁйЎәеәҸе’Ңж—¶й—ҙй—®йўҳдёӯзҡ„жҪңеҠӣе’Ңеә”з”Ёзҡ„иЎЁйқўгҖӮ
еңЁж’°еҶҷжң¬ж–Үж—¶пјҢLSTMе·ІжҲҗеҠҹеә”з”ЁдәҺдј—еӨҡзҺ°е®һй—®йўҳдёӯпјҢд»ҺжӯӨеӨ„жүҖиҝ°зҡ„з»Ҹе…ёж—¶й—ҙеәҸеҲ—й—®йўҳеҲ°ж–Үжң¬иҮӘеҠЁзә жӯЈгҖҒејӮеёёжЈҖжөӢе’Ңж¬әиҜҲжЈҖжөӢпјҢд»ҘеҸҠејҖеҸ‘иҮӘеҠЁй©ҫ驶жұҪиҪҰжҠҖжңҜзҡ„ж ёеҝғгҖӮ
зӣ®еүҚдҪҝз”ЁдёҠиҝ°LSTMеӯҳеңЁдёҖдәӣеұҖйҷҗжҖ§пјҢзү№еҲ«жҳҜеңЁдҪҝз”ЁйҮ‘иһҚж—¶й—ҙеәҸеҲ—ж—¶пјҢиҜҘзі»еҲ—жң¬иә«е…·жңүеҫҲйҡҫе»әжЁЎзҡ„йқһе№ізЁізү№жҖ§пјҲе°Ҫз®ЎеңЁдҪҝз”ЁиҙқеҸ¶ж–Ҝж·ұеәҰзҘһз»ҸзҪ‘з»ңж–№жі•ж–№йқўеҸ–еҫ—дәҶиҝӣеұ•пјүи§ЈеҶіж—¶й—ҙеәҸеҲ—зҡ„йқһе№ізЁіжҖ§й—®йўҳгҖӮеҗҢж ·еҜ№дәҺдёҖдәӣеә”з”ЁпјҢиҝҳеҸ‘зҺ°еҹәдәҺжіЁж„ҸеҠӣзҡ„зҘһз»ҸзҪ‘з»ңжңәеҲ¶зҡ„ж–°иҝӣеұ•е·Із»Ҹи¶…иҝҮLSTMпјҲ并且LSTMдёҺиҝҷдәӣеҹәдәҺжіЁж„ҸеҠӣзҡ„жңәеҲ¶зӣёз»“еҗҲд№ҹдјҳдәҺе…¶иҮӘиә«пјүгҖӮ
然иҖҢпјҢжҲӘиҮізӣ®еүҚпјҢLSTMеңЁжӣҙз»Ҹе…ёзҡ„з»ҹи®Ўж—¶й—ҙеәҸеҲ—ж–№жі•дёҠжҸҗдҫӣдәҶжҳҫи‘—зҡ„иҝӣжӯҘпјҢиғҪеӨҹйқһзәҝжҖ§ең°е»әжЁЎе…ізі»пјҢ并且иғҪеӨҹд»ҘйқһзәҝжҖ§ж–№ејҸеӨ„зҗҶе…·жңүеӨҡдёӘз»ҙеәҰзҡ„ж•°жҚ®гҖӮ
жҲ‘们ејҖеҸ‘зҡ„жЎҶжһ¶зҡ„е®Ңж•ҙжәҗд»Јз ҒеҸҜд»ҘеңЁд»ҘдёӢGitHubйЎөйқўдёҠзҡ„MITи®ёеҸҜиҜҒдёӢжүҫеҲ°пјҡhttpsпјҡ //github.com/jaungiers/LSTM-Neural-Network-for-Time-Series-Prediction





