文章来源:公众号:开源城邦,罗小波·沃趣科技高级数据库技术专家
没错,又是我(上次发"一不小心,我就上传了 279674 字的 MySQL 学习资料到 github 上了"那家伙,还一不小心上了5500+的阅读量,非常感谢大家捧场!),这次,我为大家带来《千金良方--MySQL 性能优化金字塔法则》的代码段加粗文本(字数31051+)、以及此书附赠的4个附录(字数148290+)
关于此书,也是我与另外两位同事(李春、董红禹)共同的处女作,在撰写过程中有不少心酸且有一些哭笑不得的小插曲。例如:由于经验不足,疏于和出版社的沟通,误将排版字数65W当做了统计字数65W,于是乎,我们写呀写,写到了45W统计字数,然后再也写不动了,才跟出版社联系,说无法凑足65W字怎么办?
随后,出版社的编辑反馈了2条关键信息:
我们稿酬是按照版税率结算,不是按照字数结算
出版社是按排版计数,不是按照统计计数
于是我们按照出版社的排版样式,一算,吓一大跳,总页数已经超过了1000页,综合评估一些因素之后,必须缩减到700页左右,于是,我们又陷入了需要缩减哪一部分内容的纠结中,经过一番纠结,我们决定将4个附录(附录ABCD)裁剪掉,做成电子版提供给大家免费下载,最后,就是大家看到的正文部分699页(印刷字数约108W字)
历时将近2年,我们几位作者原本都快没啥知觉了,但当我们第一次看到书的封面时(如下图),心里还是忍不住窃喜(我想,写过书的朋友,懂我在说啥的,就好比怀胎9个月,马上就要做父母了一样)

我们原计划将电子版的下载链接放进前言的末尾,不过,非常非常抱歉的是,由于前期我们检查疏忽,竟然遗漏了电子版的下载链接,导致很多朋友后来前来询问,并没有看到电子版附录的下载链接,甚至有些不明真相的朋友,直接吐槽说书中提到了那么多参数啥的,一丁点也不做介绍。不过,我们在本书第二次印刷时,将电子版的附录下载链接补充到了前言末尾。
我们也在"知数堂"圈内推送过一次电子版的PDF文件,我也单独在朋友圈推送过通过我的百度网盘提供的下载链接。但我想来想去,电子版PDF终究不方便快速查阅,于是,我们决定将4个附录将近15W统计字数的内容开源出来,供大家随时实地方便快速地查阅所需的内容。
另外,考虑到一些朋友前来咨询书中的代码段是否有提供下载,提到做实验的时候不方便(我猜可能想偷个小小的懒吧),所以我们决定将书中的加粗代码段和一些关键的配置代码段源码开源出来。还有,书中一些看起来不那么清晰的大图,我们也一并开源出来了。
还有!必须要感谢大家对本书的支持,现在,此书即将启动第三次印刷了!!好吧,我废话有点多了,下面开始进入本文的正题吧!
在"一不小心,我就上传了 279674 字的 MySQL 学习资料到 github 上了"一文中,我为大家介绍了通过搜索github的WIKI页面中的page的方法来快速查找所需的资料,但,很遗憾地告诉大家,本期为大家奉上的github资料库,不能用这个方法来快速查找资料了,因为,本期的内容,并不是所有的段落都创建了page,一些短小但繁多的段落我们直接放到了目录大纲中,因此,对于本期开源的文档资料库,其搜索的正确姿势顺序是:
首先,打开如下链接《千金良方--MySQL 性能优化金字塔法则》资料库:https://github.com/xiaoboluo768/qianjinliangfang
在这里,你可以看到类似如下图所示的界面

然后,往下拉一点,你就可以看到根目录了(蓝色字体是超链接,在这一页里,每一个红色方可标记处的链接背后,对应着一个子目录大纲,点击即可查看更多的内容)

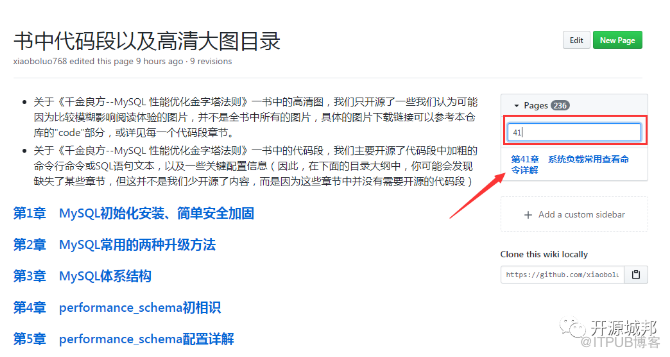
假设我们想要查看本书的代码段和高清大图,我们可以点击第一个蓝色字体"1. 书中代码段以及高清大图目录",等待几秒钟之后,跳转的界面类似图下图

在这里,目录列表我们直接使用了此书的章节名称来创建目录,同时,也使用了章节名称来创建page(这里可以看到,总共有236个page,不过,不全是代码段的内容,还包括4个附录的内容哈),我们也可以通过page搜索框来搜索,然后点击搜索结果页即可,类似如下
如果你的时间比较充裕,当然你也可以从第一章开始,逐个章节往后翻,与上一期我们介绍的MySQL 4个系统库的文档资料库一样,每一个page文末都配有上一篇和下一篇的跳转链接,你可以一直往后翻(可以翻完整个文档资料库,包括4个附录的内容)而不需要回到主页目录

然后,如果中途想要返回到目录大纲,可以直接点击WIKI标签,如下图所示

在这里,你可以点击其他几个蓝色超链接字体,进入其他的子目录大纲

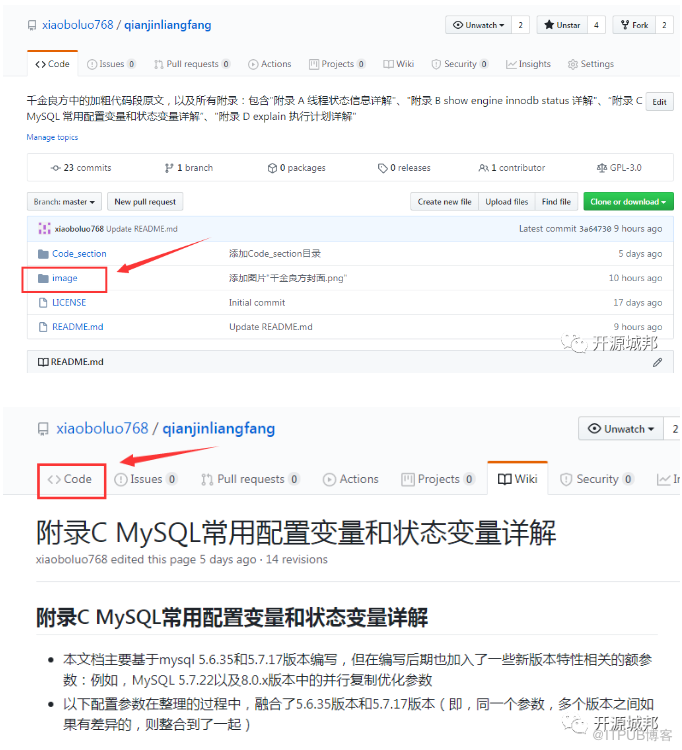
最后,此书的高清大图,我们寄存在了代码仓库中,点击"code"标签,然后点击image目录,即可查看

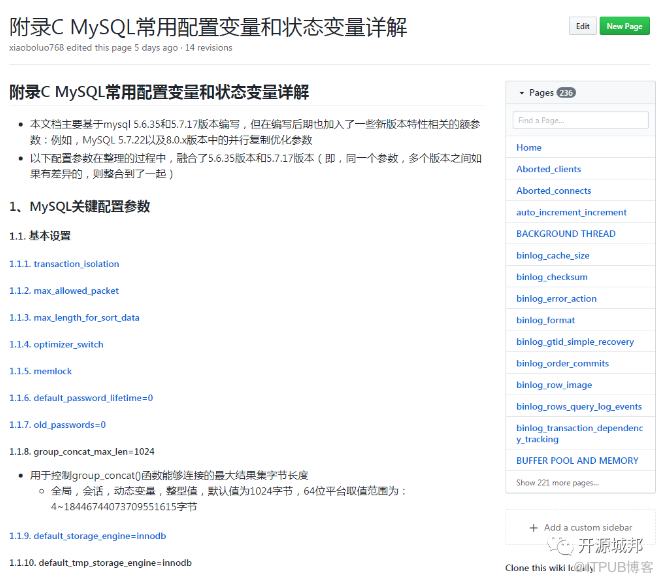
这里的图片名称,第一个数字代表书中的章节号,第二个数字代表该图片在每一个章节中的序列号。当然,为了尽可能方便大家查阅,我们也将这些突破直接插入到了每一个章节的代码段page中,类似如下图

至此,本期内容到这里就接近尾声了。同样,剩下的时间,就交给大家了,如果大家在"使用"期间有任何"体验"不佳的,仍然可以一如既往地随时吐槽,不过...,还是老规矩,吐槽归吐槽,别忘了正事儿,有哪里不对劲、怎么改进希望别忘了告诉我,谢谢大家!哦,对了,上一期我将本人的联系方式放到github中了,这一期我就直接放这里了,不过我只留QQ(309969177),因为我不常上QQ,所以才留QQ,所以才能定期看一下QQ,所以....所以....
话说
有家国产数据库公司叫万里开源,自主研发数据库及操作系统20余年,万里开源分布式数据库GreatDB,支撑了运营商海量数据的存储和处理,从2013年中国移动某省大数据平台第一次选用万里开源分布式集群数据库至今,万里开源已在电信行业多个业务场景中应用。未来,伴随着5G、物联网等技术的发展,国产化工作的进一步推进,万里开源的分布式数据库将会在更多的业务场景中替换国外数据库!
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/69977333/viewspace-2704336/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



