这篇文章运用简单易懂的例子给大家介绍MySQL的整体架构是什么,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
MySQL 在整体架构上分为 Server 层和存储引擎层。其中 Server 层,包括连接器、查询缓存、分析器、优化器、执行器等,存储过程、触发器、视图和内置函数都在这层实现。数据引擎层负责数据的存储和提取,如 InnoDB、MyISAM、Memory 等引擎。在客户端连接到 Server 层后,Server 会调用数据引擎提供的接口,进行数据的变更。
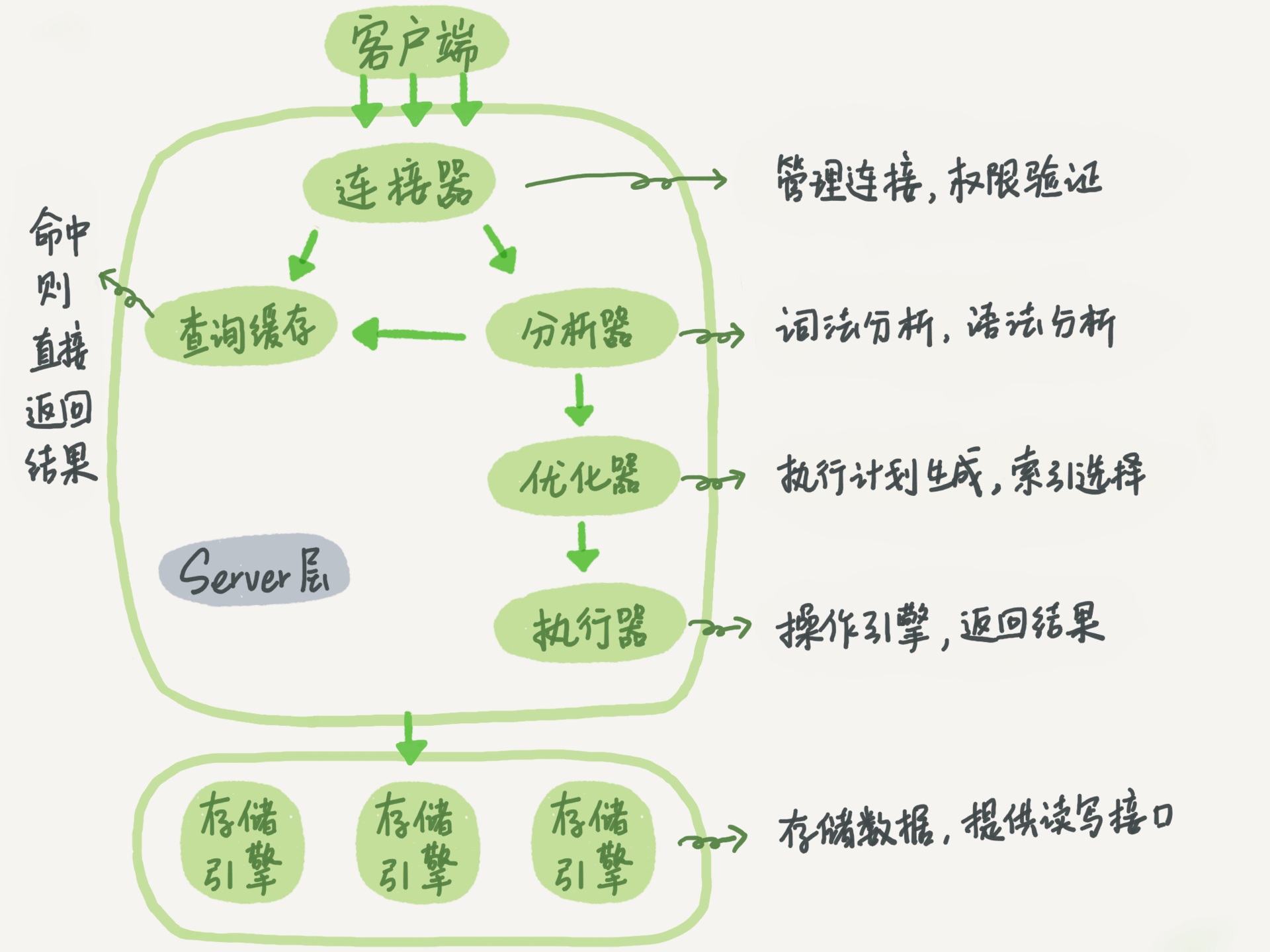
连接器
负责和客户端建立连接,获取用户权限以及维持和管理连接。
通过 show processlist; 来查询连接的状态。在用户建立连接后,即使管理员改变连接用户的权限,也不会影响到已连接的用户。默认连接时长为 8 小时,超过时间后将会被断开。
简单说下长连接:
优势:在连接时间内,客户端一直使用同一连接,避免多次连接的资源消耗。
劣势:在 MySQL 执行时,使用的内存被连接对象管理,由于长时间没有被释放,会导致系统内存溢出,被系统kill. 所以需要定期断开长连接,或执行大查询后,断开连接。MySQL 5.7 后,可以通过 mysql_rest_connection 初始化连接资源,不需要重连或者做权限验证。
查询缓存
当接受到查询请求时,会现在查询缓存中查询(key/value保存),是否执行过。没有的话,再走正常的执行流程。
但在实际情况下,查询缓存一般没有必要设置。因为在查询涉及到的表被更新时,缓存就会被清空。所以适用于静态表。在 MySQL8.0 后,查询缓存被废除。
分析器
词法分析:
如识别 select,表名,列名,判断其是否存在等。
语法分析:
判断语句是否符合 MySQL 语法。
优化器
确定索引的使用,join 表的连接顺序等,选择最优化的方案。
执行器
在具体执行语句前,会先进行权限的检查,通过后使用数据引擎提供的接口,进行查询。如果设置了慢查询,会在对应日志中看到 rows_examined 来表示扫描的行数。在一些场景下(索引),执行器调用一次,但在数据引擎中扫描了多行,所以引擎扫描的行数和 rows_examined 并不完全相同。
不预先检查权限的原因:如像触发器等情况,需要在执行器阶段才能确定权限,在优化器阶段无法验证。
使用 profiling 查看 SQL 执行过程
打开 profiling 分析语句执行过程:
mysql> select @@profiling; +-------------+ | @@profiling | +-------------+ | 0 | +-------------+ 1 row in set, 1 warning (0.00 sec)
mysql> set profiling=1; Query OK, 0 rows affected, 1 warning (0.00 sec)
执行查询语句:
mysql> SELECT * FROM s limit 10; +------+--------+-----+-----+ | s_id | s_name | age | sex | +------+--------+-----+-----+ | 1 | z | 12 | 1 | | 2 | s | 14 | 0 | | 3 | c | 14 | 1 | +------+--------+-----+-----+ 3 rows in set (0.00 sec)
获取 profiles;
mysql> show profiles; +----------+------------+--------------------------+ | Query_ID | Duration | Query | +----------+------------+--------------------------+ | 1 | 0.00046600 | SELECT * FROM s limit 10 | +----------+------------+--------------------------+ mysql> show profile; +----------------------+----------+ | Status | Duration | +----------------------+----------+ | starting | 0.000069 | | checking permissions | 0.000008 | 权限检查 | Opening tables | 0.000018 | 打开表 | init | 0.000019 | 初始化 | System lock | 0.000010 | 锁系统 | optimizing | 0.000004 | 优化查询 | statistics | 0.000013 | | preparing | 0.000094 | 准备 | executing | 0.000016 | 执行 | Sending data | 0.000120 | | end | 0.000010 | | query end | 0.000015 | | closing tables | 0.000014 | | freeing items | 0.000032 | | cleaning up | 0.000026 | +----------------------+----------+ 15 rows in set, 1 warning (0.00 sec)
查询具体的语句:
mysql> show profile for query 1; +----------------------+----------+ | Status | Duration | +----------------------+----------+ | starting | 0.000069 | | checking permissions | 0.000008 | | Opening tables | 0.000018 | | init | 0.000019 | | System lock | 0.000010 | | optimizing | 0.000004 | | statistics | 0.000013 | | preparing | 0.000094 | | executing | 0.000016 | | Sending data | 0.000120 | | end | 0.000010 | | query end | 0.000015 | | closing tables | 0.000014 | | freeing items | 0.000032 | | cleaning up | 0.000026 | +----------------------+----------+ 15 rows in set, 1 warning (0.00 sec)
MySQL 日志模块
如前面所说,MySQL 整体分为 Server 层和数据引擎层,而每层也对应了自己的日志文件。如果选用的是 InnoDB 引擎,对应的是 redo log 文件。Server 层则对应了 binlog 文件。至于为什么存在了两种日志系统,咱们往下看。
redo log
redo log 是 InnoDB 特有日志,为什么要引入 redo log 呢,想象这样一个场景,MySQL 为了保证持久性是需要把数据写入磁盘文件的。我们知道,在写入磁盘时,会进行文件的 IO,查找操作,如果每次更新操作都这样的话,整体的效率就会特别低,根本没法使用。
既然直接写入磁盘不行,解决方法就是先写进内存,在系统空闲时再更新到磁盘就可以了。但光更新内存不行,假如系统出现异常宕机和重启,内存中没有被写入磁盘的数据就会被丢掉,数据的一致性就出现问题了。这时 redo log 就发挥了作用,在更新操作发生时,InnoDb 会先写入 redo log 日志(记录了数据发生了怎么样的改变),然后更新内存,最后在适当的时间再写入磁盘,一般是找系统空闲的时间做。先写日志,在写磁盘的操作,就是常说到的 WAL (Write-Ahead- Logging)技术。
redo log 的出现,除了在效率上有了很大的改善,还保证了 MySQL 具有了 crash-safe 的能力,在发生异常情况下,不会丢失数据。
在具体实现上 redo log 的大小是固定的,可配置一组为 4 个文件,每个文件 1GB,更新时对四个文件进行循环写入。
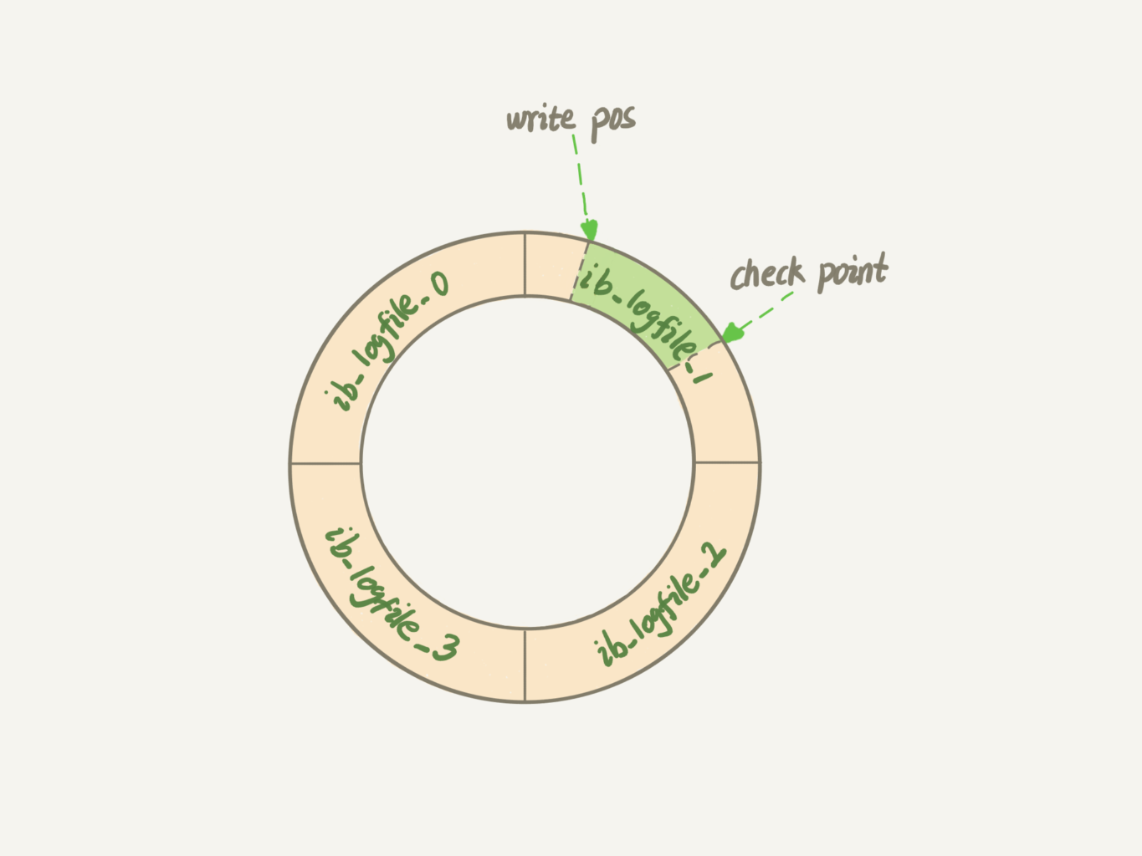
write pos 记录当前写入的位置,写完就后移,当第写入第 4 个文件的末尾时,从第 0 号位置重新写入。
check point 表示当前可以擦除的位置,当数据更新到磁盘时,check point 就向后移动。
write pos 和 check point 之间的位置,就是可以记录更新操作的空间。当 write pos 追上 check point ,不在能执行新的操作,先让 check point 去写入一些数据。
可以将 innodb_flush_log_at_trx_commit 设置成 1,开启 redo log 持久化的能力。
binlog
binlog 则是 Server 层的日志,主要用于归档,在备份,主备同步,恢复数据时发挥作用,常见的日志格式有 row, mixed, statement 三种。具体的使用方法可以参见 Binlog 恢复日志这篇。
可以通过 sync_binlog=1 开启 binlog 写入磁盘。
这里对 binlog 和 redo 进行下区分:
两阶段提交
下面执行器和 InnoDB 执行 Update 时内部流程:
以更新 update T set c=c+1 where ID=2; 语句为例:
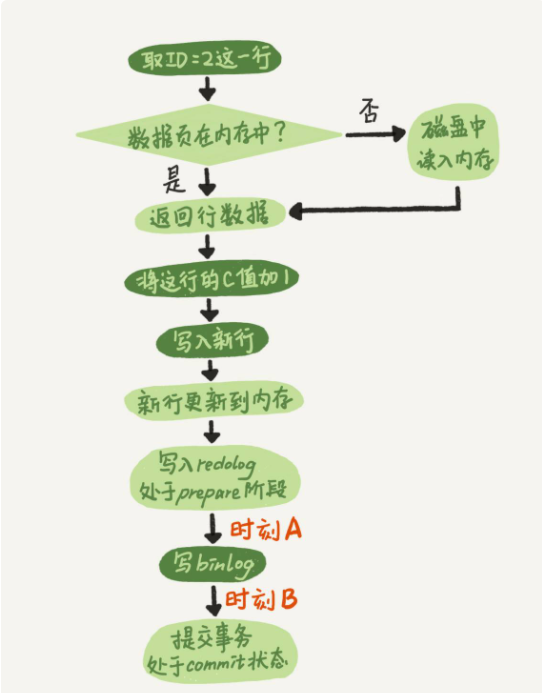
浅色为执行器执行,深色为引擎执行。
在更新内存后,将写入 redo log 拆分了成两个步骤:prepare 和 commit,就是常说的两阶段提交。用于保证当有意外情况发生时,数据的一致性。
这里假设下,如果不采用两阶段提交会发生什么?
再分析下两阶段提交的过程:
1.在写 redo log prepare 阶段奔溃,时刻 A 的位置。重启后,发现 redo log 没写入,回滚此次事务。
2.如果在写 binlog 时奔溃,重启后,发现 binlog 未被写入,回滚操作。
3.binlog 写完,但在提交 redo log 的 commit 状态时发生 crash
完整,提交事务
不完整,回滚事务。
如何判断 binlog 是否完整?
如何将 redo log 和 binlog 关联表示同一个操作?
结构中有一个共同的数据字段,XID. 在崩溃恢复时,会按顺序扫描 redo log:
数据写入后,最终落盘和 redo log 有无关系?
redo log buffer 和 redo log 的关系?
在一个事务的更新过程中,存在多个 SQL 语句,所以是要写多次日志的。
但在写的过程中,生产的日志要先保存起来,但在 commit 前,不能直接写到 redo log 中。
所以通过内存中 redo log buffer 先存 redo log 的日志。在 commit 时,将 buffer 中的内容写入 redo log.
关于MySQL的整体架构是什么就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





