这篇文章运用简单易懂的例子给大家介绍python 进程池pool的使用方法,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
和选用线程池来关系多线程类似,当程序中设置到多进程编程时,Python 提供了更好的管理多个进程的方式,就是使用进程池。
在利用 Python 进行系统管理的时候,特别是同时操作多个文件目录,或者远程控制多台主机,并行操作可以节约大量的时间。
当被操作对象数目不大时,可以直接利用 multiprocessing 中的 Process 动态生成多个进程,十几个还好,但如果是上百个,上千个目标,手动的去限制进程数量却又太过繁琐,此时可以发挥进程池的功效。
Pool可以提供指定数量的进程供用户调用,当有新的请求提交到 pool 中时,如果进程池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来它。
Python multiprocessing 模块提供了 Pool() 函数,专门用来创建一个进程池,该函数的语法格式如下:
multiprocessing.Pool( processes )
其中,processes 参数用于指定该进程池中包含的进程数。
如果进程是 None,则默认使用 os.cpu_count() 返回的数字(根据本地的 cpu 个数决定,processes 小于等于本地的 cpu 个数)。
请看下面的实例:
from multiprocessing import Pool
import os
import time
import random
def worker(msg):
t_start = time.time()
print("%s开始执行,进程号为%d" % (msg, os.getpid()))
# random.random()随机生成0~1之间的浮点数
time.sleep(random.random()*2)
t_stop = time.time()
print(msg, "执行完毕,耗时%0.2f" % (t_stop-t_start))
if __name__ == "__main__":
po = Pool(3) # 定义一个进程池,最大进程数3
for i in range(0, 8):
# Pool().apply_async(要调用的目标,(传递给目标的参数元祖,))
# 每次循环将会用空闲出来的子进程去调用目标
po.apply_async(worker, (i,))
print("----start----")
# 关闭进程池,关闭后po不再接收新的请求
po.close()
# 等待po中所有子进程执行完成,必须放在close语句之后
po.join()
print("-----end-----")运行结果:
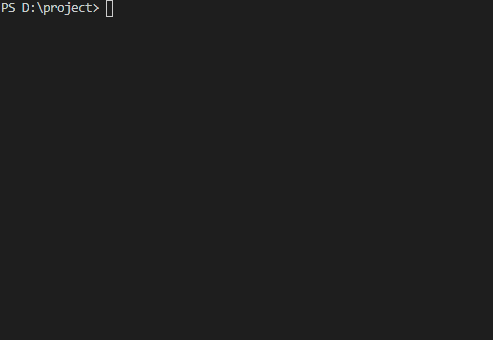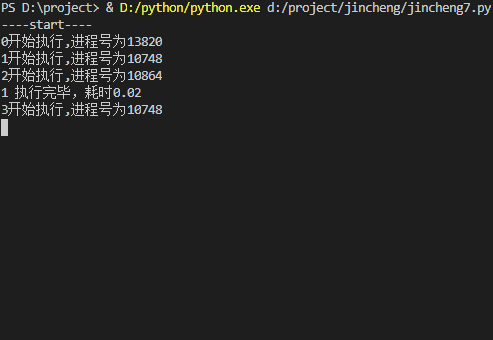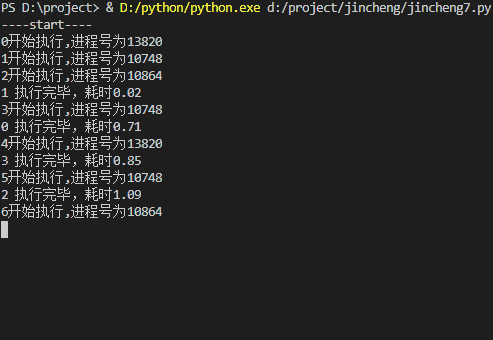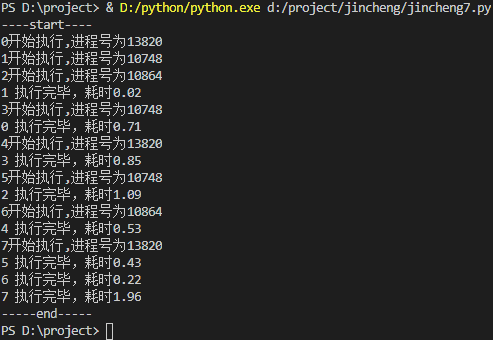
multiprocessing.Pool 常用方法说明
apply_async(func[, args[, kwds]]) :使用非阻塞方式调用 func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args 为传递给 func 的参数列表,kwds 为传递给 func 的关键字参数列表。
close():关闭 Pool,使其不再接受新的任务。
terminate():不管任务是否完成,立即终止。
join():主进程阻塞,等待子进程的退出, 必须在 close 或 terminate 之后使用。
进程池中的 Queue
如果要使用 Pool 创建进程,就需要使用 multiprocessing.Manager() 中的 Queue(),而不是 multiprocessing.Queue(),否则会得到一条如下的错误信息:
RuntimeError: Queue objects should only be shared between processes through inheritance.
下面的实例演示了进程池中的进程如何通信:
from multiprocessing import Manager, Pool
import os
import time
import random
def writer(q):
print("writer启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in "xiaoming":
q.put(i)
def reader(q):
print("reader启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in range(q.qsize()):
print("reader从Queue获取到消息:%s" % q.get(True))
if __name__ == "__main__":
print("(%s) start" % os.getpid())
# 使用Manager中的Queue
q = Manager().Queue()
po = Pool()
po.apply_async(writer, (q,))
# 先让上面的任务向Queue存入数据,然后再让下面的任务开始从中取数据
time.sleep(1)
po.apply_async(reader, (q,))
po.close()
po.join()
print("(%s) End" % os.getpid())运行结果:
(17528) start writer启动(2216),父进程为(17528) reader启动(2216),父进程为(17528) reader从Queue获取到消息:x reader从Queue获取到消息:i reader从Queue获取到消息:a reader从Queue获取到消息:o reader从Queue获取到消息:m reader从Queue获取到消息:i reader从Queue获取到消息:n reader从Queue获取到消息:g (17528) End
关于python 进程池pool的使用方法就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





