我们知道,在sql语句解析的过程中,有一个过程叫优化。Oracle中有一个叫优化器的组件,专门来处理sql的优化。在考虑查询条件和对象引用的许多相关因素后,优化器能确定出执行SQL语句最有效的方式来。对于任何SQL语句,优化器优化的结果,可以极大地影响执行时间。
Oracle优化器的优化方法有两种:
CBO 基于成本的优化法则
RBO 基于规则的优化法则
初始化参数optimizer_mode控制着优化器优化的行为
SQL> show parameter optimizer_mode NAME TYPE VALUE ------------------------------------ --------------------------------- ------------------------------ optimizer_mode string ALL_ROWS
optimizer_mode有如下五个取值
CHOOSE 使用CBO还是RBO,基于统计信息是否存在,如果有统计系统则使用CBO,否则使用RBO。
ALL_ROWS 基于CBO,采用尽快返回所有结果的一种最优执行计划。
FIRST_ROWS_n 基于CBO,尽快的返回前n行数据,n的取值为1,10,100,1000
FIRST_ROWS 基于CBO和试探法相结合的方法,查找一种可以最快返回前面少数行的方法;这个参数主要用于向 后兼容。
RULE 采用基于CBO的优化法则。
Oracle 11g的版本只有中间三个参数有效,并且不推荐使用FIRST_ROWS .
我们看看优化器对查询的影响
SQL> alter system set optimizer_mode=all_rows;
System altered.
SQL> conn scott/tiger
Connected.
SQL> set autot traceonly exp
SQL> select * from emp,dept where emp.deptno=dept.deptno;
Execution Plan
----------------------------------------------------------
Plan hash value: 844388907
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 812 | 6 (17)| 00:00:01 |
| 1 | MERGE JOIN | | 14 | 812 | 6 (17)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| DEPT | 4 | 80 | 2 (0)| 00:00:01 |
| 3 | INDEX FULL SCAN | PK_DEPT | 4 | | 1 (0)| 00:00:01 |
|* 4 | SORT JOIN | | 14 | 532 | 4 (25)| 00:00:01 |
| 5 | TABLE ACCESS FULL | EMP | 14 | 532 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("EMP"."DEPTNO"="DEPT"."DEPTNO")
filter("EMP"."DEPTNO"="DEPT"."DEPTNO")修改优化器模式后
SQL> alter session set optimizer_mode=first_rows_1;
Session altered.
SQL> select * from emp,dept where emp.deptno=dept.deptno;
Execution Plan
----------------------------------------------------------
Plan hash value: 3625962092
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 58 | 3 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 1 | 58 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL | EMP | 1 | 38 | 2 (0)| 00:00:01 |
|* 4 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 |
| 5 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 20 | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("EMP"."DEPTNO"="DEPT"."DEPTNO")CBO有如下三个组件构成
Query Transformer
Estimator
Plan Generator
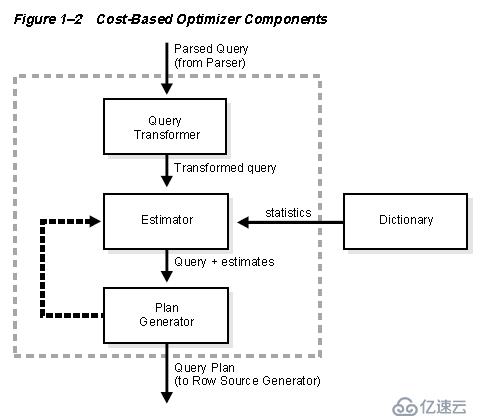
一、Query Transformer
输入部分是已经被解析器解析过的sql。
查询转换包括如下技术:
View Merging(视图合并)
查询涉及到的每个视图被parser展开,并且分离成一个一个的查询块。查询块本质上代表了视图的定义。将其与查询剩余部分合并成一个总的执行计划,转换后的语句基本上不包含视图了。我们来举例说明
假设有这样一个视图
CREATE VIEW employees_50_vw AS SELECT employee_id, last_name, job_id, salary, commission_pct, department_id FROM employees WHERE department_id = 50;
进行如下查询
SELECT employee_id FROM employees_50_vw WHERE employee_id > 150;
优化器转换后,查询变为
SELECT employee_id FROM employees WHERE department_id = 50 AND employee_id > 150;
Predicate Pushing(谓词推进)
将谓词从内部查询块推进到一个不可合并的查询块中,这样可以使得谓词条件更早的被选择,更早的过滤掉不需要的数据行,提高效率,同样可以使用这种方式允许某些索引的使用。
假设有如下视图
CREATE VIEW all_employees_vw AS ( SELECT employee_id, last_name, job_id, commission_pct, department_id FROM employees ) UNION ( SELECT employee_id, last_name, job_id, commission_pct, department_id FROM contract_workers );
我们发出这样的查询
SELECT last_name FROM all_employees_vw WHERE department_id = 50;
转换后
SELECT last_name FROM ( SELECT employee_id, last_name, job_id, commission_pct, department_id FROM employees WHERE department_id=50 UNION SELECT employee_id, last_name, job_id, commission_pct, department_id FROM contract_workers WHERE department_id=50 );
Subquery Unnesting(子查询解嵌套)
最典型的就是子查询转变为表连接了,它和视图合并的主要区别就在于它的子查询位于where子句,由转换器进行解嵌套的检测。
假设有这样的一个查询
SELECT * FROM sales WHERE cust_id IN ( SELECT cust_id FROM customers );
查询转换后
SELECT sales.* FROM sales, customers WHERE sales.cust_id = customers.cust_id;
Query Rewrite with Materialized Views
假设建立一个物化视图
CREATE MATERIALIZED VIEW cal_month_sales_mv ENABLE QUERY REWRITE AS SELECT t.calendar_month_desc, SUM(s.amount_sold) AS dollars FROM sales s, times t WHERE s.time_id = t.time_id GROUP BY t.calendar_month_desc;
执行如下查询
SELECT t.calendar_month_desc, SUM(s.amount_sold) FROM sales s, times t WHERE s.time_id = t.time_id GROUP BY t.calendar_month_desc;
查询转换后
SELECT calendar_month, dollars FROM cal_month_sales_mv;
二、Estimator
Estimator决定了一个给定的执行计划的总成本。估计量生成三种不同类型的措施,以实现这一目标:
Selectivity
这里的第一个度量值——选择性,表示sql命中的行数与行集的比值。所谓行集可以是表、视图,或者是一个连接或GROUP BY操作的中间结果。选择性与查询中的谓词有关,比如last_name=’Smith’,或者一个联合谓词last_name=’Smith’ and job_type=’Clerk’。一个谓词充当着一个过滤器的角色,在行集中过滤了一定量的行,谓词的选择性是一个比值,它表示一个行集经过谓词的过滤后剩下的行占原有行集的比例。其值在0.0和1.0之间,0.0表示在行集中没有行被选择;1.0表示行集中的所有行都被选择了。如果没有可用的统计信息,评估器为选择性赋予一个内部的缺省值,这个内部缺省值随着谓词的不同而不同。例如:等式谓词(last_name=’Smith’)的内部缺省值低于范围谓词(last_name>’Smith’),评估器会假定等式谓词返回的行数小于范围谓词。当存在可用的统计信息,评估器将使用统计信息来估算选择性。例如:对于一个等式谓词(last_name=’Smith’),选择性的值是distinct last_name的倒数即:(1/count(distinct last_name))。但是如果在last_name字段上存在直方图(histogram),则选择性值为:coun(last_name)where last_name=’Smith’ / count(last_name)where last_name is not null。可见在数据倾斜的字段上应用直方图能够帮助CBO进行准确的选择性评估
Cardinality
基数就是行集中行的数量。基数分为:
基础基数(Base cardinality):就是基表中的行数。基础基数在表分析期间获得。如果表没有可用的统计信息,则评估器利用表中区(extents)的数量来估算基础基数。
有效基数(Effective cardinality):就是从基表中选择的行数。有效基数与具体的谓词和字段有关。有效基数是根据基础基数和作用于该表的所有谓词的选择性得出的,如果没有谓词作用于该表,则有效基数就等于基础基数。
连接基数(Join cardinality):就是两个行集在连接之后产生的行数。连接就是由两个行集产生的笛卡尔积,再由连接谓词过滤结果。因此,连接基数是两个行集基数与连接谓词选择性的乘积。
Distinct基数(Distinct cardinality):就是一个行集的字段distinct之后的行数。一个
行集的distinct基数是基于字段中的数据的。例如:一个拥有100行的行集,如果一个字段distinct之后还剩下20行,则distinct基数就为20。
Group基数(Group cardinality):就是一个行集在应用GROUP BY之后产生行的数量。Group基数依赖于每个组中字段的distinct基数和行集的行数。
Cost
成本是用来描述工作单元或资源使用的。CBO是用磁盘I/O、CPU和内存的使用情况来作为工作单元的,因此CBO使用的成本可以描述为,在一次操作的执行过程中所用的磁盘I/O数量以及CPU和内存的总使用量。
三、Plan Generator
主要功能是把给定的query生成各种可能的计划,并且挑出成本最低的一个。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





