grep名称来自于g/re/p(globally search a regular expression and print,以正规表示法进行全域查找以及打印),是一个最初用于Unix操作系统的命令行工具。在给出文件列表或标准输入后,grep会对匹配一个或多个正则表达式的文本进行搜索,并只输出匹配(或者不匹配)的行或文本。
| 命令名称:grep, egrep, fgrep 命令作用:print lines matching a pattern 命令用法:grep [OPTIONS] PATTERN [FILE...] grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...] 参数选项:-v 反向选取 -o 仅显示匹配的字符串,而非字符串所在的行 -i 忽略字符串大小写 -E 支持只用扩展正则表达式 -A n 显示匹配到字符串之后的n行 -B n 显示匹配到字符串之前的n行 -C n 显示匹配到字符串前后的n行 --color 高亮显示匹配到的字符串 |
常见字符集:
| [:space:] | 所以空白字符 |
| [:punct:] | 所以标点符号 |
| [:lower:] | 所有小写字母 |
| [:upper:] | 所以大写字母 |
| [:digit:] | 所有数字 |
| [:alnum:] | 所有大小写字母和数字 |
| [:alpha:] | 所有大小写字母 |
文件名通配:
| * | 任意长度的任意字符 |
| ? | 匹配任意单个字符 |
| [] | 匹配指定范围内的任意单个字符 |
| [^] | 匹配指定范围以外的任意单个字符 |
基本正则表达式:
| 字符匹配 | . | 匹配任意单个字符 |
| [] | 匹配指定范围内的任意单个字符 | |
| [^] | 匹配指定范围外的任意单个字符 | |
| 次数匹配 | * | 前面的字符可以出现任意次 |
| \? | 前面的字符出现0次或者1次 | |
| \{m\} | 前面的字符出现m次 | |
| \{m,n\} | 前面的字符出现n次~m次 | |
| \{m,\} | 前面的字符至少出现m次 | |
| \{0,n\} | 前面的字符至多出现n次 | |
| .* | 任意长度的任意字符 | |
| 位置锚定 | ^ | 行首锚定,写在模式的最左侧 |
| $ | 行尾锚定,写在模式的最右侧 | |
| ^$ | 匹配空行 | |
| \< | 词首锚定,出现于单词左侧 | |
| \> | 词尾锚定,出现于单词右侧 | |
| 分组 | \(\) | 匹配一个分组 |
| \1 | 引用第1个括号所匹配到的内容,而非模式本身 | |
| \2 | 引用第2个括号所匹配到的内容,而非模式本 身 |
扩展正则表达式:
| 字符匹配 | . | 匹配任意单个字符 |
| [] | 匹配指定范围内的任意单个字符 | |
| [^] | 匹配指定范围外的任意单个字符 | |
| 次数匹配 | * | 前面的字符可以出现任意次 |
| ? | 前面的字符出现0次或者1次 | |
| + | 前面的字符至少出现1次 | |
| {m} | 前面的字符出现m次 | |
| {m,n} | 前面的字符出现n次~m次 | |
| {m,} | 前面的字符至少出现m次 | |
| {0,n} | 前面的字符至多出现n次 | |
| 锚定 | ^ | 行首锚定,写在模式的最左侧 |
| $ | 行尾锚定,写在模式的最右侧 | |
| \<,\b | 词首锚定,出现于单词左侧 | |
| \>,\b | 词尾锚定,出现于单词右侧 | |
| ^$ | 匹配空行 | |
| 分组 | () | 匹配一个分组 |
| \1 | 引用第1个括号所匹配到的内容,而非模式本身 |
grep练习:
1、显示/proc/meminfo文件中以大写或小写S开头的行;
[root@DB2 ~]# grep -i '^s' /proc/meminfo
[root@DB2 ~]# grep -E '^(S|s)' /proc/meminfo
[root@DB2 ~]# grep '^[S|s]' /proc/meminfo
2、显示/etc/passwd文件中其默认shell为非/sbin/nologin的用户;
[root@DB2 ~]# grep -v "/sbin/nologin$" /etc/passwd | cut -d: -f1
3、显示/etc/passwd文件中其默认shell为/bin/bash并且ID号最大的用户;
[root@DB2 ~]# grep '/bin/bash' /etc/passwd | sort -t: -k3 -n | tail -1 | cut -d: -f1
4、找出/etc/passwd文件中的一位数或两位数;
[root@DB2 ~]# grep '\<[0-9][0-9]\?\>' /etc/passwd
[root@DB2 ~]# grep '\<[0-9][0-9]\{0,1\}\>' /etc/passwd
5、显示/boot/grub/grub.conf中以至少一个空白字符开头的行;
[root@DB2 ~]# grep '^[[:space:]]\{1,\}' /boot/grub/grub.conf
6、显示/etc/rc.d/rc.sysinit文件中,以#开头,后面跟至少一个空白字符,而后又有至少一个非空白字符的行;
[root@DB2 ~]# grep --color '^#[[:space:]]\{1,\}[^[:space:]]\{1,\}' /etc/rc.d/rc.sysinit
7、找出netstat -tan命令执行结果中以'LISTEN'结尾的行;
[root@DB2 ~]# netstat -tan | grep --color 'LISTEN[[:space:]]*$'
8、添加用户bash, testbash, basher, nologin(SHELL为/sbin/nologin),而找出当前系统上其用户名和默认shell相同的用户;
[root@DB2 ~]# grep --color '^\([[:alnum:]]\{1,\}\):.*\1$' /etc/passwd
9、扩展题:新建一个文本文件,假设有如下内容: He like his lover. He love his lover. He like his liker. He love his liker. 找出其中最后一个单词是由此前某单词加r构成的行。 cat <<EOF> 2.txt He like his lover. He love his lover. He like his liker. He love his liker. EOF [root@DB2 ~]# grep --color '\(l..e\).*\1r' 2.txt
|
练习:使用扩展的正则表达式
10、显示当前系统上root、bin或halt用户的默认shell; [root@Oracle ~]# grep -E "^(root|bin|halt):" /etc/passwd | cut -d: -f7 |
11、找出/etc/rc.d/init.d/functions文件中某单词后跟一组小括号“()”行; [root@Oracle ~]# grep -E -o "\<[[:alnum:]]+\>\(\)" /etc/rc.d/init.d/functions
|
12、使用echo命令输出一个路径,而后使用grep取出其基名;
echo "/etc/sysconfig/" | grep -o -E "[[:alnum:]]+/?"
[root@Oracle ~]# echo "/etc/sysconfig/" | grep -o -E "[^/]+/?$" | cut -d/ -f1
sysconfig
[root@Oracle ~]# echo "/etc/sysconfig/" | grep -o -E "[[:alnum:]]+/?"
etc/sysconfig/
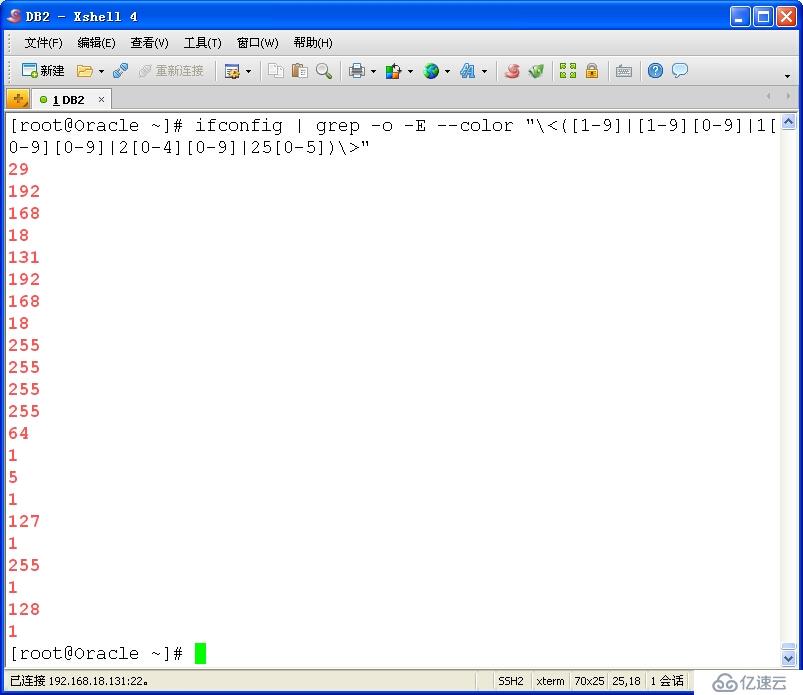
13、找出ifconfig命令结果中的1-255之间的数字; [root@Oracle ~]# ifconfig | grep -o -E --color "\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>"
|
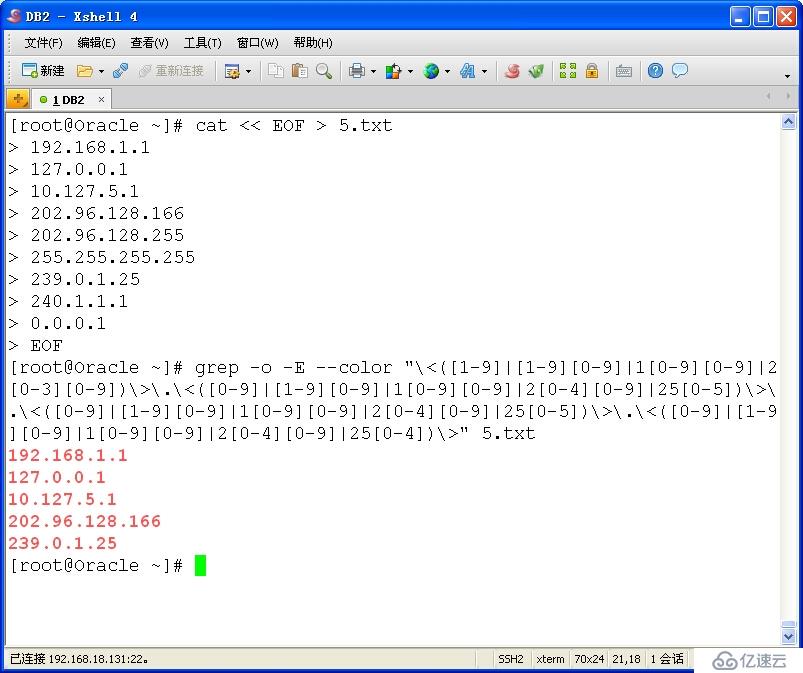
14、挑战题:写一个模式,能匹配合理的ipv4地址; cat << EOF > 5.txt 192.168.1.1 127.0.0.1 10.127.5.1 202.96.128.166 202.96.128.255 255.255.255.255 239.0.1.25 240.1.1.1 0.0.0.1 EOF [root@Oracle ~]# grep -o -E --color "\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-3][0-9])\>\.\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>\.\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>\.\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-4])\>" 5.txt
|
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务